Abstract
Variational Autoencoders (VAEs)是一个latent variable models,目的是为了学习训练数据复杂的分布。然后模型最后的输出质量十分依赖inference model.
Adverarial Variation Bayes (AVB),是一个用任意的Inference model 来训练VAES的技术。我们通过建立一个辅助的判别模型,来重新审视maximum-likelihood问题。就好像两个竞争对手。所以AVB本质上是结合了VAEs和GANs。在nonparametric limit我们的方法产生了一个exact maximum-likelihood来给生成模型的参数。与此同时,还产生了exact posterior distribution over the latent variables given an observation.
Introduction
Generative models
主要是非监督学习,试图对训练数据有很好的了解一以便可以产生新的数据。

GANs
当GAN用于学习一个自然图片的表达式的时候,通常会产生一些可视化sharper results。在BiGANs中,在GAN的基础上加入了inference model。然而,它被观察到重建结果往往只是模糊的类似于输入,通常是在语义上,而不是在术语上的像素值。
VAEs
好在他可以产生generative model and an inference model.一些文章表明他可以带来更好的log-likelihoods。不足之处就是他的inference model往往捕捉不到真正的后验分布posterior distribution。
之前也有一些工作试图结合GANs和VAEs。但是,他们的出发点并不是maximumlikelihood point of view。所以do not lead to maximum-likelihood assignments。比如Adversarial Autoencoders (AAEs)。
Adversarial Autoencoders (AAEs)
Kullback-Leibler正则项出现在训练目标函数中。而在VAEs中被替换为an adversarial loss。在latent variables,这有利于the aggregated posterior to be close to the prior。除此之外AAEs并不最大化maximum-likelihood的下界。
AVB
除了生成模型的部分,AVB还提出了一个新方法for performing Variational Bayes (VB) with neural samplers.
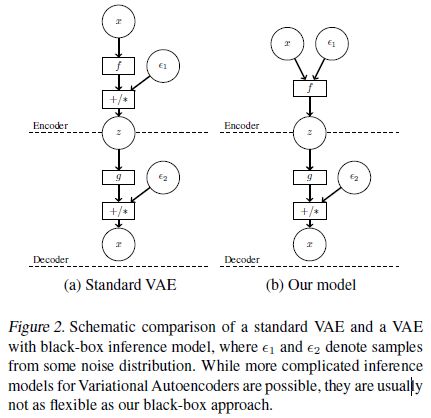
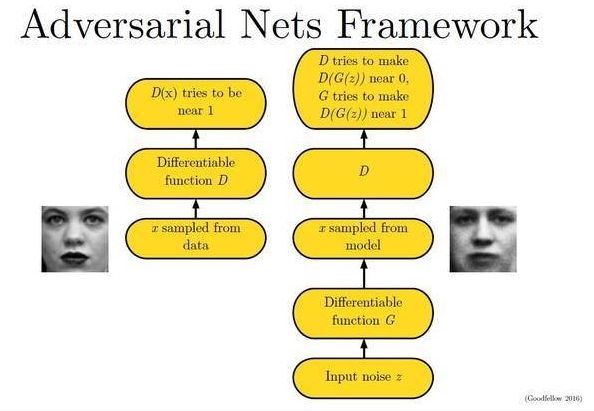
由上图所示,我们用AVB来训练神经网络来to sample from a nontrival unnormalized probability density. 这一步,需要精确估计the posterior distribution of a probabilistic model。
本文的贡献:
1.在VAE的基础上,使用adversarial training.可以任意的使用复杂的inference model。
2.有理论基础,在nonparametric limit中,可以重构true posterior distribution和true maximum-likelihood assignment for the parameters of the generative model.
3.我们的经验证明,我们的模型能够学习丰富的后验分布,并证明该模型能够为复杂的数据集生成引人注目的样本。
2.背景
变分自编码器(Variational Autoencoder, VAE)通俗教程 – 邓范鑫
上面链接里面的文章很好,建议阅读
VAE
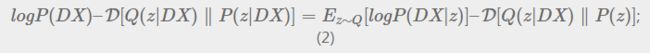
右边第一项:Ez∼Q[logP(X|z)]就是针对面对真实的z的分布情况(依赖Q(z|X),由X->z的映射关系决定),算出来的X的分布,类似于根据z重建X的过程。
右边第二项:D[Q(z|X)∥P(z)]就是让根据X重建的z与真实的z尽量趋近,由于P(z)是明确的N(0, I),而Q(z|X)是也是正态分布,其实就是要让Q(z|X)趋近与标准正态分布。
现在我们对这个公式的理解更加深入了。接下来,我们要进行实现的工作


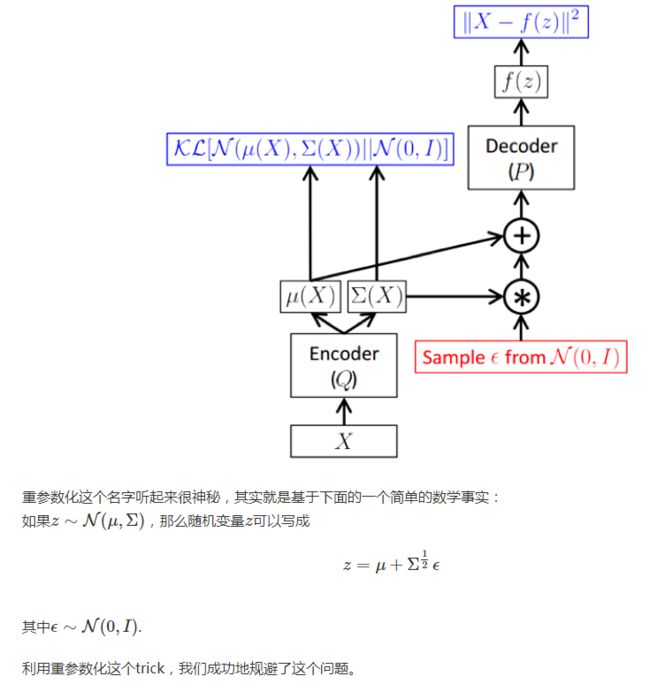
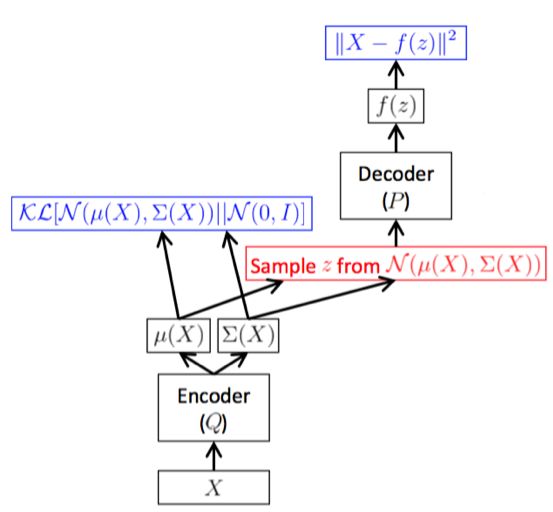
总结起来,整个训练框架就是在对样本x进行编解码。q是将样本x编码为隐变量z,而p又将隐含变量z解码成f(z),进而最小化重构误差。训练的目的是学习出编码器的映射函数和解码器的映射函数,所以训练过程实际上是在进行变分推断,即寻找出某一个函数来优化目标。因此取名为变分编码器VAE(Variational Auto-encoder).
关注具体实现的读者可能会发现在“解码器Decoder到μ(x)和Σ(x)”这个阶段从技术上没办法进行梯度反传。的确如此,上图只是作为帮助大家理解的示意图,而真正实现过程中,我们需要利用重参数化这个trick,如下图所示。
GAN
GAN学习指南:从原理入门到制作生成Demo,总共分几步?
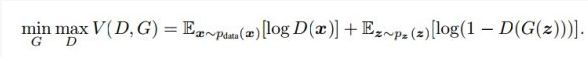
简单分析一下这个公式:
整个式子由两项构成。x表示真实图片,z表示输入G网络的噪声,而G(z)表示G网络生成的图片。
D(x)表示D网络判断真实图片是否真实的概率(因为x就是真实的,所以对于D来说,这个值越接近1越好)。而D(G(z))是D网络判断G生成的图片的是否真实的概率。
G的目的:上面提到过,D(G(z))是D网络判断G生成的图片是否真实的概率,G应该希望自己生成的图片“越接近真实越好”。也就是说,G希望D(G(z))尽可能得大,这时V(D, G)会变小。因此我们看到式子的最前面的记号是min_G。
D的目的:D的能力越强,D(x)应该越大,D(G(x))应该越小。这时V(D,G)会变大。因此式子对于D来说是求最大(max_D)

这里红框圈出的部分是我们要额外注意的。第一步我们训练D,D是希望V(G, D)越大越好,所以是加上梯度(ascending)。第二步训练G时,V(G, D)越小越好,所以是减去梯度(descending)。整个训练过程交替进行。
首先明确一些名词:

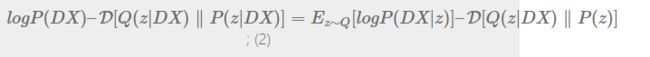


our goal is to optimize the marginal log-likelihood

(2.3)等于(2.4)
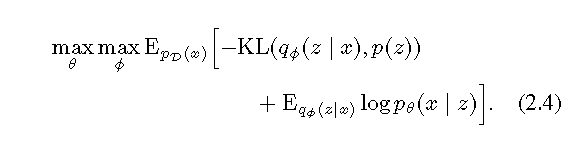
关键影响优化因素是inference model q(z|x)假设服从高斯分布。
因为这个inference model q(z|x)对于x而言是十分灵活的,而对于z潜在变量是十分限制的,这个因素也限制了生成模型的效果。
3.Method
然后在对抗变分贝叶斯模型中(AVB)中 ,我们可以避免使用inference model q(z|x)这个显示的表达式,我们使用黑箱模型。并且我们用对抗式的训练来得到

3.1推导
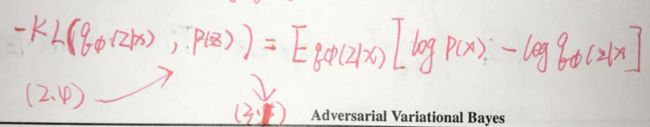
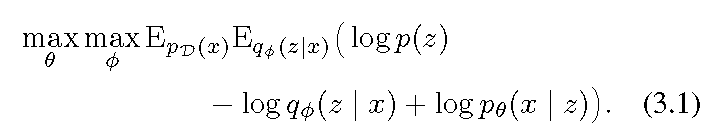
我们将q(z|x)变成黑箱模型,所以在VAE中的重参数的技巧将不再奏效。
我们方法就是将要绕开这个,我们
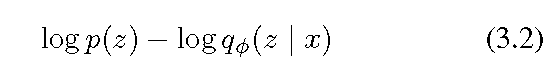
将上式看成判别模型T(x,z)。判别模型的目的就是区分(x,z)对儿是来自p(x)p(z),还是来自我们当前的inference model p(x)q(z|x)。
p(x)p(z)是真实的真值 p(x)q(z|x)模型得到。
p(z)真实存在数据背后的分布,但是我们无法得到,但是我们尽量去用q(z|x)去逼近p(z)。

nonparametric limit:
To simplify the theoretical analysis, we assume that the model T(x; z) is flexible enough to represent any function of the two variables x and z。


seita是很容易由p(x|z)梯度下降来得到。fai很复杂,因为隐藏在T(x,z)中。
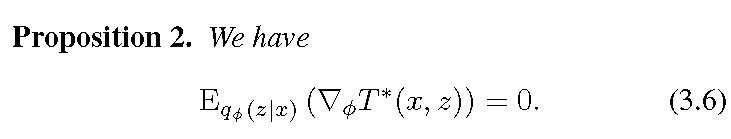
说明fai并不一定要出现在T中。
再加上重参数的技巧
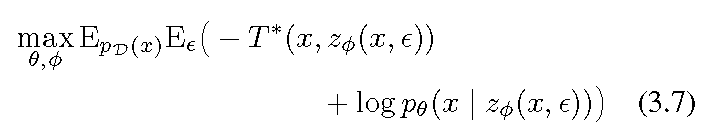
3.2. Algorithm
as a two-player game
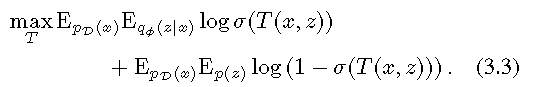
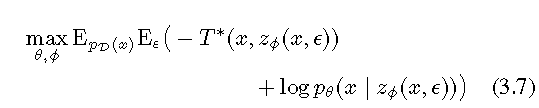
纳什均衡,Nash equilibrium,又称为非合作博弈均衡,是博弈论的一个重要术语,以约翰·纳什命名。纳什均衡是一种策略组合,使得同一时间内每个参与人的策略是对其他参与人策略的最优反应。
We therefore regard the optimization problems in (3.3) and (3.7) as a two-player game. Propositions 1 and 2 show that any Nash-equilibrium of this game yields a stationary point of the objective in (2.4).
在VAE中有一个和GAN一样的问题,就是在优化一个参数,而固定其他参数的时候,网络容易崩塌到一个确定的点。因此关键是保持判别T网络的最优性而优化。
3.3. Theoretical results


4.Adaptive Contrast
由于nonparametric limit 我们的模型可以取得好的结果。实际上,T(x,z)很难接近目标函数。因为AVB的判别模型很难计算
然而,logistic regression 对于likelihood-ratio estimation有很好的结果,当两个密度很接近的时候。
为了提升估计的效果,我们提出了一个an auxiliary conditional probability distribution
r(z|x)服从高斯分布,他的均值和方差可以和q(z|x)相互匹配。
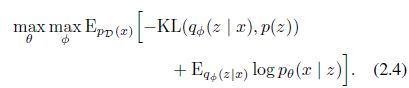
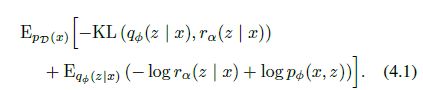
第二项用梯度下降,