在现代计算机中,存储器系统的结构可以用一个存储器层次(Memory Hierarchy)模型来刻画。

越位于高层的存储设备越接近CPU,他们的容量越小,但是对其中数据的访问速度越快;而位于底层的存储设备正好相反,容量更大,速度更慢。
一般意义上的缓存
不同层次间数据的传输
不难理解为了提高CPU对数据操作的速度,应该尽量让数据处于较高的阶层。而在从低层提取数据时,往往是按块(chunk)提取的,也就是说往往会提取包含此时所需要数据的一大块数据,并把这块数据放到上一层,再从这上一层中提取那一块数据,当然,这次提取的也是一块数据,但是这一块比较小。
你可能会好奇为什么不只提取那一段有效的数据而提取一大块呢?有这么几个原因:1.提取一整块数据而不是单独的数据有利于减少数据在总线上传输的次数,提高效率。2.根据局部性原理(locality),当前数据周围的数据可能CPU在执行完当前操作后马上就会用到,先提前提到上一层往往能提高效率。3.充分利用上一层资源很重要啊,留着不用还能生更多存储器宝宝吗?
上一层的存储器暂时存放了下一层的数据,这就是缓存(cache)的概念。因此从上面的存储器阶层我们不难发现,本地磁盘(local disks)可以作为远程二级存储介质(remote secondary storage)的缓存;主存(main memory)可以作为本地磁盘(local disks)的缓存;三级缓存(L3 cache)可以作为主存(main memory)的缓存等等。
命中与不命中
当CPU要从一个存储设备中获取数据时,会先看看它上一层的存储设备中有没有所要的数据。这不难理解,因为CPU曾经把一大块的数据提到它的上一层存储设备中。当CPU在上一层存储设备中找到所要的数据时,很幸运,这就是一次访问命中(hit),这次命中为CPU省了不少访问下一层存储设备的时间。当然CPU不总是这么走运,很可能在这一层存储设备中没有所需要的数据,这就是一次不命中(miss)。不命中带来的访问下层存储器会导致很长的时间惩罚。
缓存管理
之前说过不同层次间数据是以块为单位移动的,访问数据时也存在命中与不命中问题,这些麻烦的事情都是由谁来管理的呢?不同的层次的管理机制不同,寄存器的缓存逻辑由编译器管理;L1~L3缓存由硬件管理,作为硬盘缓存的主存由操作系统和硬件一同管理。
高速缓存
细心的读者可能发现了,有三个家伙的名字里就有缓存,分别是L1 cache, L2 cache, L3 cache。这些存储介质在跑的飞起的CPU和慢吞吞的主存中起到纽带的作用,他们被叫做高速缓存。我们先从简单情况开始,即只有L1的情况。即CPU从主存获取数据,L1缓存作为主存的缓存。
高速缓存的通用结构
CPU通过地址总线向存储器传输所需数据所在的地址。假设地址长度有m位,我们可以像下图这样把这个地址分成三部分。
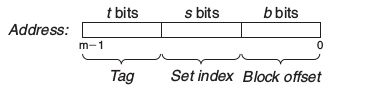
你也许会问为什么取地址中间几位来作为缓存的组数而不是最高几位或最低几位呢?看了下面一小节再回答这个问题。
下面来讨论几种具体的缓存的实现
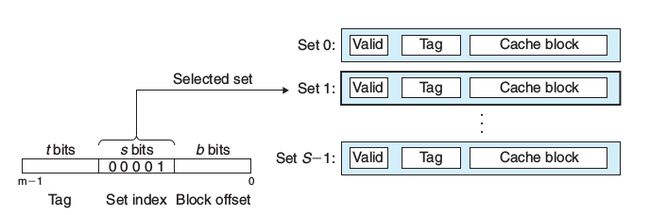
直接映射高速缓存(Direct-Mapped Caches)
当E = 1时,就形成了这种缓存结构。它的特点是每组只有一行,这样子的话0x00|000|xxx和0x01|000|xxx都会映射到第0组的唯一那行,所以当第一次把0x00|000|xxx数据加载到缓存的第0行第0组上,第二次要访问0x01|000|xxx的数据,就出现了一个不命中,这是就需要用0x01|000|xxx的数据替换原数据。
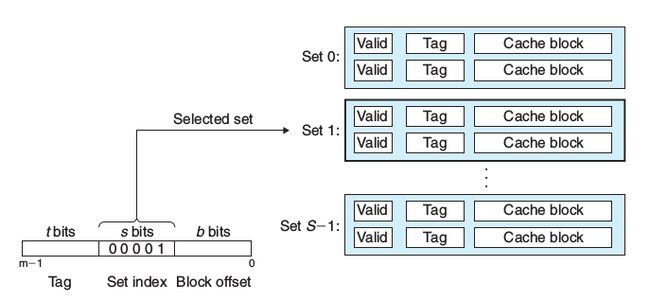
组相联高速缓存(Set Associative Caches)
当1 < E < C/B时,这里C是缓存容量,成为组相联高速缓存。与直接映射高速缓存相比,增加的行可以提高命中率,但是对于不命中的处理相对就复杂了,一般来说如果有有效位表明这一行没被写给的行,就写道这一行,否则写到这些行里最后用到的那一行里。
全相联高速缓存(Fully Associative Caches)
此时E = C/B,也就是E * B = C,而C = S * B * E(你有推导出这个公式吗?),所以S = 1,也就是只有1组。
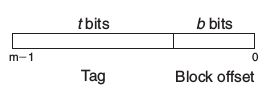
此时地址被简单地分成了两部分,标志位和块偏移位。对不命中的处理和组相联高速缓存相似。
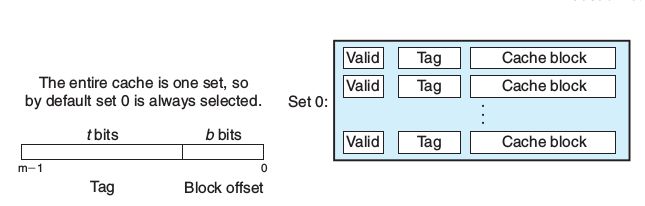
现在让我们回到之前的问题。
根据局部性原理,地址接近的内存单元很可能被访问的时间也很接近,所以如果用最低几位,相邻的地址空间映射到了不同的组不利于局部性发挥作用,因为他们本可以映射到同一组,CPU访问时可以直接命中。如果用最高几位每一组的行数就会很多,会降低查找缓存的效率。
缓存的力量
假设要从主存中取一段数据到CPU,每次从L1缓存中取数据所需的时间为tc,每次从主存中取数据的时间为tm,总命中率为h。
那么这次取数行为所需总时间的数学期望Ex(t)1= n * (h * tc + (1 - h) * (tc + tm))
如果没有缓存机制,所需总时间的数学期望Ex(t)2 = n * (tc + tm)
通常tc为几个时钟周期而tm为几十到几百个时钟周期。Ex(t)1/Ex(t)2 = 1-h + (h * tc) / (tc + tm)约等于1-h,当命中率为0.5时,速度几乎提高了一倍!