一、XML介绍
XML 指可扩展标记语言(EXtensible Markup Language),也是一种标记语言,很类似 HTML.它的设计宗旨是传输数据,而非显示数据它;标签没有被预定义,需要自行定义标签。
XML 被设计为具有自我描述性,是 W3C 的推荐标准,在电子计算机中,标记指计算机所能理解的信息符号,通过此种标记,计算机之间可以处理包含各种的信息比如文章等。它可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。它非常适合万维网传输,提供统一的方法来描述和交换独立于应用程序或供应商的结构化数据。是Internet环境中跨平台的、依赖于内容的技术,也是当今处理分布式结构信息的有效工具。早在1998年,W3C就发布了XML1.0规范,使用它来简化Internet的文档信息传输。
xml的作用:
XML 是各种应用程序之间进行数据传输的最常用的工具,并且在信息存储和描述领域变得越来越流行。简单的说,我们在开发中使用XML主要有以下两方面应用:
a. XML做为数据交换的载体,用于数据的存储与传输
b. XML做为配置文件
应用场景:
- 配置文件
HelloMyServlet
cn.itcast.HelloMyServlet
HelloMyServlet
/hello
- 存放数据
张三
李四
二、XML语法
书写规范
xml必须有根元素(只有一个)
xml标签必须有关闭标签
xml标签对大小写敏感
xml的属性值须加引号
特殊字符必须转义
xml中的标签名不能有空格
空格/回车/制表符在xml中都是文本节点
xml必须正确地嵌套
我们将符合上述书写规则的XML叫做格式良好的XML文档。xml组成部分
Everyday Italian
Giada De Laurentiis
2005
30.00
Harry Potter
J K. Rowling
2005
29.99
Learning XML
Erik T. Ray
2003
39.95
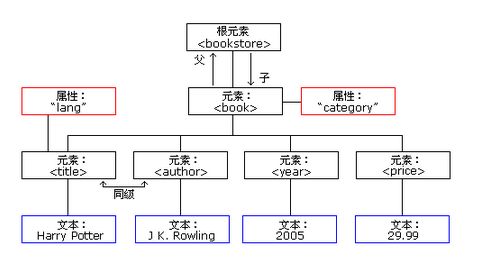
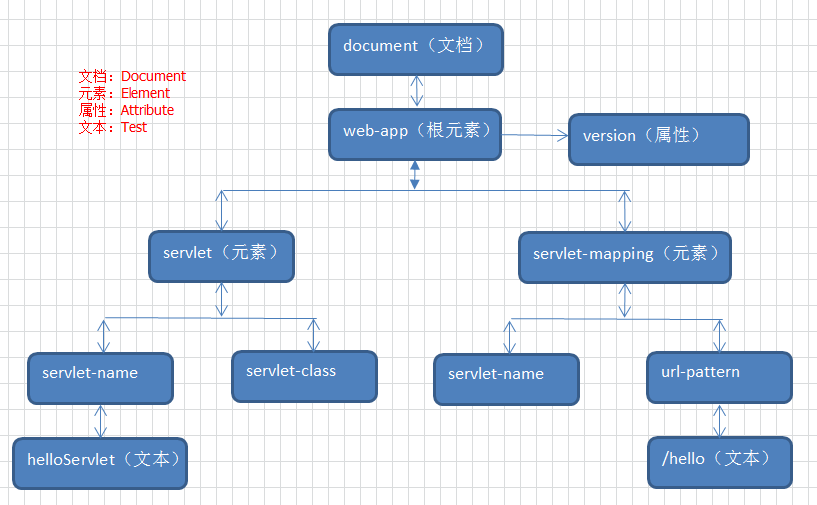
对于一个xml文件,首先必须要有根元素,该元素是所有其它元素的父元素。而在xml中所有元素形成了一棵树。父,子及同胞等术语描述了元素之间的关系。所有的元素都可以拥有子元素。相同层级上的子元素成为同胞。
所有元素都可以拥有文本内容和属性。
Root 根元素
Element 元素
Attribute 属性
Text 文本
在开发中,我们将上述内容也统称为Node(节点)。
接下来,我们就分析一下,对于一个xml文档它的主要组成部分有哪些?
-
XML文档声明
- 文档声明必须为结束;
- 文档声明必须从文档的0行0列位置开始;
- 文档声明只有三个属性:
a) versioin:指定XML文档版本。必须属性,因为我们不会选择1.1,只会选择1.0;
b) encoding:指定当前文档的编码。可选属性,默认值是utf-8;
c) standalone:指定文档独立性。可选属性,默认值为yes,表示当前文档是独立文档。如果为no表示当前文档不是独立的文档,会依赖外部文件。
-
元素
- 元素是XML文档中最重要的组成部分,
- 普通元素的结构开始标签、元素体、结束标签组成。例如:
大家好 - 元素体:元素体可以是元素,也可以是文本,例如:你好
- 空元素:空元素只有开始标签,而没有结束标签,但元素必须自己闭合,例如:
- 元素命名:
a) 区分大小写
b) 不能使用空格,不能使用冒号:
c) 不建议以XML、xml、Xml开头 - 良好的XML文档,必须有一个根元素。
-
属性
- 属性是元素的一部分,它必须出现在元素的开始标签中
- 属性的定义格式:属性名=属性值,其中属性值必须使用单引或双引
- 一个元素可以有0~N个属性,但一个元素中不能出现同名属性
- 属性名不能使用空格、冒号等特殊字符,且必须以字母开头
注释
XML的注释与HTML相同,即以“”结束。注释内容会被XML解析器忽略!-
转义字符
XML中的转义字符与HTML一样。
因为很多符号已经被XML文档结构所使用,所以在元素体或属性值中想使用这些符号就必须使用转义字符,例如:“<”、“>”、“’”、“””、“&”。
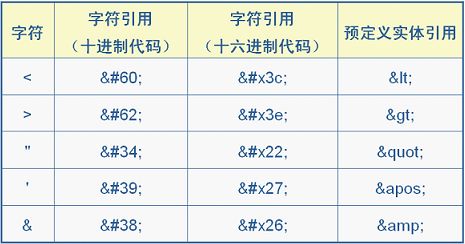 转义字符.png
转义字符.png
- CDATA区
当大量的转义字符出现在xml文档中时,会使xml文档的可读性大幅度降低。这时如果使用CDATA段就会好一些。
在CDATA段中出现的“<”、“>”、“””、“’”、“&”,都无需使用转义字符。这可以提高xml文档的可读性。
在CDATA段中不能包含“]]>”,即CDATA段的结束定界符。
三、DTD约束
DTD(Document Type Definition),文档类型定义,用来约束XML文档。规定XML文档中元素的名称,子元素的名称及顺序,元素的属性等。
开发中,我们很少自己编写DTD约束文档,通常情况我们都是通过框架提供的DTD约束文档,编写对应的XML文档。常见框架使用DTD约束有:struts2、hibernate等。
DTD示例:
案例实现:通过提供的DTD“web-app_2_3.dtd”编写XML
-
步骤1:创建web.xml文档,并将“web-app_2_3.dtd”拷贝相同目录下。
 image.png
image.png -
步骤2:从DTD文档开始处,拷贝需要的“文档声明”
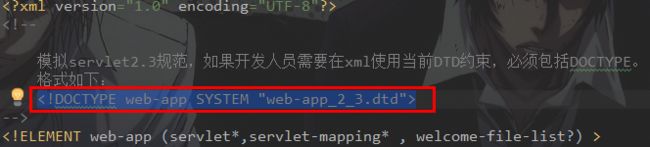 image.png
image.png
 image.png
image.png 步骤3:完成xml内容编写
DTD语法
- 文档声明
- 内部DTD,在XML文档内部嵌入DTD,只对当前XML有效。
- 外部DTD—本地DTD,DTD文档在本地系统上,公司内部自己项目使用。
- 外部DTD—公共DTD,DTD文档在网络上,一般都有框架提供。
-
元素声明
定义元素语法:
元素名:自定义
元素描述包括:符号和数据类型
常见符号:? * + () | ,
常见类型:#PCDATA 表示内容是文档,不能是子标签
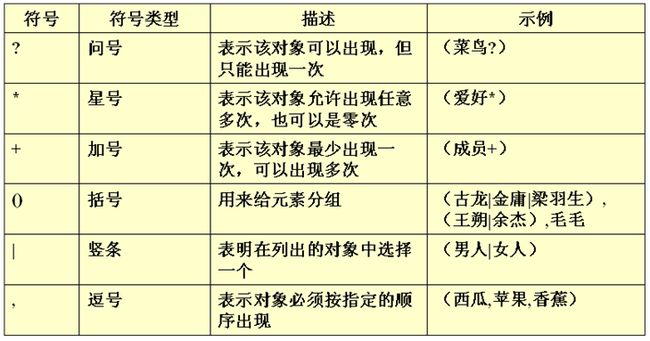 元素描述.png
元素描述.png
web-app 包括3个标签,且必须顺序出现。
servlet子标签个数任意
servlet-mapping 子标签个数任意
welcome-file-list 子标签最多只能出现一次
servlet 有3个子标签,且必须顺序出现
servlet-name,必须有,且只能出现一次
description,可选一次
servlet-class 和 jsp-file 二选一,且只能出现一次
servlet-name 的标签体必须是文本
welcome-file-list 至少有一个子标签welcome-file
- 属性声明
属性的语法:
元素名:属性必须是给元素添加,所有必须先确定元素名
属性名:自定义
属性类型:ID、CDATA、枚举 …
ID : ID类型的属性用来标识元素的唯一性
CDATA:文本类型
枚举:(e1 | e2 | ...) 多选一
约束:
#REQUIRED:说明属性是必须的;
#IMPLIED:说明属性是可选的;
给web-app元素添加 version属性,属性值必须是文本,且可选。
和 都符号约束
四、Schema约束
Schema是新的XML文档约束;
Schema要比DTD强大很多,是DTD 替代者;
Schema本身也是XML文档,但Schema文档的扩展名为xsd,而不是xml。
Schema 功能更强大,数据类型更完善
Schema 支持名称空间
Schema与dtd区别:
XML从SGML中继承了DTD,并用它来定义内容的模型,验证和组织元素。同时,它也有很多局限:
• DTD不遵守XML语法;
• DTD不可扩展;
• DTD不支持名称空间的应用;
• DTD没有提供强大的数据类型支持,只能表示很简单的数据类型。
Schema完全克服了这些弱点,使得基于Web的应用系统交换XML数据更为容易。下面是它所展现的一些新特性:
• Schema完全基于XML语法,不需要再学习特殊的语法;
• Schema能用处理XML文档的工具处理,而不需要特殊的工具;
• Schema大大扩充了数据类型,支持boolean、numbers、dates and times、URIs、integers、decimal numbers和real numbers等;
• Schema支持原型,也就是元素的继承。如:我们定义了一个“联系人”数据类型,然后可以根据它产生“朋友联系人”和“客户联系”两种数据类型;
• Schema支持属性组。我们一般声明一些公共属性,然后可以应用于所有的元素,属性组允许把元素、属性关系放于外部定义、组合;
• 开放性。原来的DTD只能有一个DTD应用于一个XML文档,现在可以有多个Schema运用于一个XML文档。
与DTD一样,要求可以通过schema约束文档编写xml文档。常见框架使用schema的有:Spring等
实例:通过提供“web-app_2_5.xsd”编写xml文档
- web-app_2_5.xsd
- 案例实现
-
步骤1:创建web.xml,并将“web-app_2_5.xsd”拷贝到同级目录
 image.png
image.png -
步骤2:从xsd文档中拷贝需要的“命名空间”
 image.png
image.png
 image.png
image.png 完成xml内容编写
命名空间(语法)
如果一个XML文档中使用多个Schema文件,而这些Schema文件中定义了相同名称的元素时就会出现名字冲突。这就像一个Java文件中使用了import java.util.和import java.sql.时,在使用Date类时,那么就不明确Date是哪个包下的Date了。
总之名称空间就是用来处理元素和属性的名称冲突问题,与Java中的包是同一用途。如果每个元素和属性都有自己的名称空间,那么就不会出现名字冲突问题,就像是每个类都有自己所在的包一样,那么类名就不会出现冲突。
约束文档和XML关系
当W3C提出Schema约束规范时,就提供“官方约束文档”。我们通过官方文档,必须“自定义schema 约束文档”,开发中“自定义文档”由框架编写者提供。我们提供“自定义文档”限定,编写出自己的xml文档。
声明命名空间
默认命名空间:
显式命名空间:
实例:web-app_2_5.xsd
表示自定义schema约束文档引用官方文档作为显示命名空间。如果要使用官方提供的元素或属性,必须使用xsd前缀(自定义,此处表示官方文档,所以使用xsd)
实例:web.xml
表示 xml 文档引用“自定义约束文档”作为默认命名空间
因为使用默认命名空间,直接使用 自定义约束:web-app_2_5.xsd
-
xml文档:web.xml
xsi:schemaLocation=http://www.example.org/web-app_2_5 web-app_2_5.xsdxmlns:xsi=”…” 固定写法
表示是一个schema实例文档,就是被schema文档约束的xml文档。
xsi:schemaLocation=”名称 路径 名称 路径 名称 路径 …”
表示用于确定当前xml文档使用到的schema文档的位置。“名称 路径”是成对出现,与xmlns引用命名空间对应。
五、dom4j解析
当将数据存储在XML后,我们就希望通过程序获得XML的内容。如果我们使用Java基础所学习的IO知识是可以完成的,不过你需要非常繁琐的操作才可以完成,且开发中会遇到不同问题(只读、读写)。人们为不同问题提供不同的解析方式,并提交对应的解析器,方便开发人员操作XML。
1. 解析方式和解析器
开发中比较常见的解析方式有三种,如下:
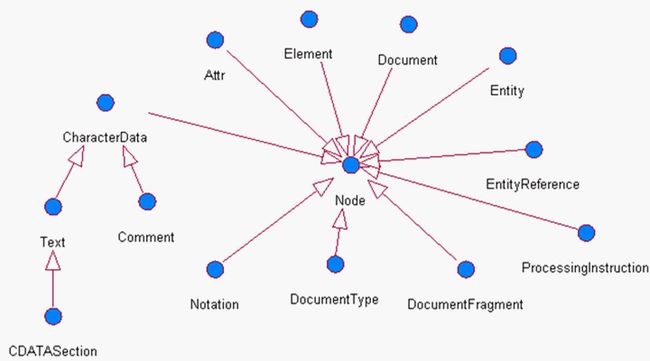
- DOM:(Document Object Model, 即文档对象模型) 是 W3C 组织推荐的解析XML 的一种方式。要求解析器把整个XML文档装载到内存,并解析成一个Document对象。
a) 优点:元素与元素之间保留结构关系,故可以进行增删改查操作。
b) 缺点:XML文档过大,可能出现内存溢出显现。 - SAX:(Simple API for XML) 不是官方标准,但它是 XML 社区事实上的标准,几乎所有的 XML 解析器都支持它。是一种速度更快,更有效的方法。它逐行扫描文档,一边扫描一边解析。并以事件驱动的方式进行具体解析,每执行一行,都将触发对应的事件。
a) 优点:处理速度快,可以处理大文件
b) 缺点:只能读,逐行后将释放资源。 - PULL:Android内置的XML解析方式,类似SAX。(了解)
-
解析器:就是根据不同的解析方式提供的具体实现。有的解析器操作过于繁琐,为了方便开发人员,有提供易于操作的解析开发包。
 解析器.png
解析器.png 常见的解析开发包:
JAXP:sun公司提供支持DOM和SAX开发包
JDom:dom4j兄弟
jsoup:一种处理HTML特定解析开发包
dom4j:比较常用的解析开发包,hibernate底层采用。-
DOM和SAX区别
- DOM
支持回写
会将整个XML载入内存,以树形结构方式存储
XML比较复杂的时候,或者当你需要随机处理文档中数据的时候不建议使用 - SAX
相比DOM是一种更为轻量级的方案
采用串行方法读取 --- 逐行读取
编程较为复杂
无法修改XML数据
- DOM
2. DOM解析原理及结构模型
XML DOM 和 HTML DOM类似,XML DOM 将 整个XML文档加载到内存,生成一个DOM树,并获得一个Document对象,通过Document对象就可以对DOM进行操作。
DOM中的核心概念就是节点,在XML文档中的元素、属性、文本等,在DOM中都是节点!
3. API使用
如果需要使用dom4j,必须导入jar包。

dom4j 必须使用核心类SaxReader加载xml文档获得Document,通过Document对象获得文档的根元素,然后就可以操作了。
常用API如下:
- SaxReader对象
a) read(…) 加载执行xml文档 - Document对象
a) getRootElement() 获得根元素 - Element对象
a) elements(…) 获得指定名称的所有子元素。可以不指定名称
b) element(…) 获得指定名称第一个子元素。可以不指定名称
c) getName() 获得当前元素的元素名
d) attributeValue(…) 获得指定属性名的属性值
e) elementText(…) 获得指定名称子元素的文本值
f) getText() 获得当前元素的文本内容
节点操作
1.获取文档的根节点.
Element root = document.getRootElement();
2.取得某个节点的子节点.
Element element=node.element(“书名");
3.取得节点的文字
String text=node.getText();
4.取得某节点下所有名为“member”的子节点,并进行遍历.
List nodes = rootElm.elements("member");
for (Iterator it = nodes.iterator(); it.hasNext();)
{ Element elm = (Element) it.next(); // do something}
节点对象属性
1.取得某节点下的某属性
Element root=document.getRootElement(); //属性名name
Attribute attribute=root.attribute(“属性”);//getValue()
2.取得属性的文字
String text=attribute.getText(); === getValue();
3.取得某属性的文字
String value=node.attributeValue(“属性”);
解析web.xml文件:
public class Dom4jTest {
@Test
public void demo03() throws Exception{
//#1 获得document
SAXReader saxReader = new SAXReader();
Document document = saxReader.read(new File("src/com/yzy/mytomcat/schema/web.xml"));
//#2 获得根元素
Element rootElement = document.getRootElement();
//打印version属性值
String version = rootElement.attributeValue("version");
System.out.println(version);
//#3 获得所有子元素。例如:/
List allChildElement = rootElement.elements();
//#4 遍历所有
for (Element childElement : allChildElement) {
// #5.1 打印元素名
String childEleName = childElement.getName();
System.out.println(childEleName);
// #5.2 处理 ,并获得子标签的内容。例如: 等
if("servlet".equals(childEleName)){
// 方式1:获得元素对象,然后获得文本
Element servletNameElement = childElement.element("servlet-name");
String servletName = servletNameElement.getText();
System.out.println("\t" + servletName);
// 方式2:获得元素文本值
String servletClass = childElement.elementText("servlet-class");
System.out.println("\t" + servletClass);
}
// #5.3 处理 省略...
}
}
}
4. dom4j-xpath使用
XPath 是一门在 XML 文档中查找信息的语言
XPath 可用来在 XML 文档中对元素和属性进行遍历
XPath简化了Dom4j查找节点的过程
使用XPath必须导入jaxen-1.1-beta-6.jar否则出现NoClassDefFoundError: org/jaxen/JaxenException
在DOM4J中使用XPATH:
获取所有符合条件的节点
selectNodes(String xpathExpression) 返回List集合
获取符合条件的单个节点
selectSingleNode(String xpathExpression) 返回一个Node对象。
如果符合条件的节点有多个,那么返回第一个。
六、实例:编写服务器软件,访问指定配置内容
- 1.创建实例工厂
编写接口
public interface MyServlet {
public void init(); //1.初始化
public void service(); //2.执行
public void destory(); //3.销毁
}
实现接口
public class HelloMyServlet implements MyServlet {
@Override
public void init() {
System.out.println("1.初始化");
}
@Override
public void service() {
System.out.println("2.执行中....");
}
@Override
public void destory() {
System.out.println("3.销毁");
}
}
测试,创建实现类实例对象
public class TestApp {
@Test
public void demo01(){
//手动创建执行
MyServlet myServlet = new HelloMyServlet();
myServlet.init();
myServlet.service();
myServlet.destory();
}
}
-
- 反射创建实例对象
测试程序我们直接new HelloServlet,这种编程方式我们称为硬编码,及代码写死了。为了后期程序的可扩展,开发中通常使用实现类的全限定类名(cn.itcast.e_web.HelloMyServlet),通过反射加载字符串指定的类,并通过反射创建实例。
- 反射创建实例对象
@Test
public void demo02() throws Exception{
/* 反射创建执行
* 1) Class.forName 返回指定接口或类的Class对象
* 2) newInstance() 通过Class对象创建类的实例对象,相当于new Xxx();
*/
String servletClass = "com.yzy.mytomcat.web.implement.HelloMyServlet";
//3 获得字符串实现类实例
Class clazz = Class.forName(servletClass);
MyServlet myServlet = (MyServlet) clazz.newInstance();
//4 执行对象的方法
myServlet.init();
myServlet.service();
myServlet.destory();
}
- 解析xml
使用反射我们已经可以创建对象的实例,此时我们使用的全限定类名,在程序是仍写死了,我们将器配置到xml文档中。
xml文档内容:
HelloMyServlet
com.yzy.mytomcat.web.implement.HelloMyServlet
HelloMyServlet
/implement
解析实现
@Test
public void demo03() throws Exception{
/* 读取xml配置文件,获得配置的内容,取代固定字符串
*/
//1.1 加载xml配置文件,并获得document对象
SAXReader saxReader = new SAXReader();
Document document = saxReader.read(new File("src/com/yzy/mytomcat/schema/web.xml"));
//1.2 获得根元素
Element rootElement = document.getRootElement();
//1.3 获得第一个 子元素
Element servletElement = rootElement.element("servlet");
//1.4 获得字符串实现类 的值
String servletClass = servletElement.elementText("servlet-class");
//3 获得字符串实现类实例
Class clazz = Class.forName(servletClass);
MyServlet myServlet = (MyServlet) clazz.newInstance();
//4 执行对象的方法
myServlet.init();
myServlet.service();
myServlet.destory();
}
-
- 模拟浏览器路径
上面我们已经解析xml,不过我们获得内容是固定。我们希望如果用户访问的路径是/implement,将执行com.yzy.mytomcat.web.implement.HelloMyServlet程序,如果访问时/implement2,将执行com.yzy.mytomcat.web.implement.HelloMyServlet2程序。
在执行测试程序前(@Before),解析xml文件,将解析的结果存放在Map中,map中数据的格式为:路径=实现类。
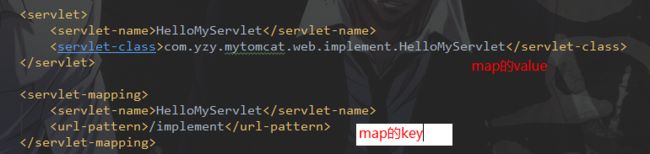 image.png
image.png
- 模拟浏览器路径
xml文件内容:
HelloMyServlet
com.yzy.mytomcat.web.implement.HelloMyServlet
HelloMyServlet
/implement
HelloMyServlet2
com.yzy.mytomcat.web.implement2.HelloMyServlet2
HelloMyServlet2
/implement2
解析xml思路:先解析
//最终存放 key=请求路径,value=实现类
private Map data = new HashMap();
@Before
public void demo04Before() throws Exception{
//在执行前执行,解析xml,并将结果存放到Map<路径,实现类>中
//1 获得document
SAXReader saxReader = new SAXReader();
Document document = saxReader.read(new File("src/com/yzy/mytomcat/schema/web.xml"));
//2 获得根元素
Element rootElement = document.getRootElement();
//3 获得所有的子元素 、等
List allChildElement = rootElement.elements();
/* 4 遍历所有
* 1)解析到,将其子标签与存放到Map中
* 2)解析到,获得子标签和, 从map中获得1的内容,组合成 url = class 键值对
*/
for (Element childElement : allChildElement) {
//4.1 获得元素名
String eleName = childElement.getName();
//4.2 如果是servlet,将解析内容存放到Map中
if("servlet".equals(eleName)){
String servletName = childElement.elementText("servlet-name");
String servletClass = childElement.elementText("servlet-class");
data.put(servletName, servletClass);
}
//4.3 如果是servlet-mapping,获得之前内容,组成成key=url,value=class并添加到Map中
if("servlet-mapping".equals(eleName)){
String servletName = childElement.elementText("servlet-name");
String urlPattern = childElement.elementText("url-pattern");
// 获得之前存放在Map中值
String servletClass= data.get(servletName);
// 存放新的内容 url = class
data.put(urlPattern, servletClass);
// 将之前存放的数据删除
data.remove(servletName);
}
//打印信息
System.out.println(data);
}
}
模拟浏览器请求路径,通过url从map获得class,并使用反射执行实现类。
@Test
public void demo04() throws Exception{
//1 模拟路径
//String url = "/implement";
String url = "/implement2";
//2 通过路径获得对应的实现类
String servletClass = data.get(url);
//3 获得字符串实现类实例
Class clazz = Class.forName(servletClass);
MyServlet myServlet = (MyServlet) clazz.newInstance();
//4 执行对象的方法
myServlet.init();
myServlet.service();
myServlet.destory();
}
-
- 浏览器访问
使用Socket编写服务,通过浏览器可以访问,并解析浏览器发送的请求数据,最终获得请求路径。
访问路径:
http://localhost:8888/implement
http://localhost:8888/implement2
- 浏览器访问
@Test
public void demo05() throws Exception{
//使用socket获得请求路径
//1.1 给本地计算机绑定端口8888
ServerSocket serverSocket = new ServerSocket(8888);
//1.2 程序阻塞,等待浏览器请求。
Socket accept = serverSocket.accept();
//1.3 获得请求所有数据
BufferedReader reader = new BufferedReader(new InputStreamReader(accept.getInputStream()));
//1.4 获得第一行数据,请求行,例如:GET /hello HTTP/1.1
String firstLine = reader.readLine();
//1.5 请求行三部分数据由空格连接,获得中间数据。表示请求路径
String url = firstLine.split(" ")[1];
System.out.println(url);
//2 通过路径获得对应的实现类
String servletClass = data.get(url);
//3 获得字符串实现类实例
Class clazz = Class.forName(servletClass);
MyServlet myServlet = (MyServlet) clazz.newInstance();
//4 执行对象的方法
myServlet.init();
myServlet.service();
myServlet.destory();
//5 释放资源
reader.close();
控制台等待链接时:

输入网址测试,控制台效果:



