2019-10-09 19:55:26
问题描述:谈谈对Bert的理解。
问题求解:
2018年深度学习在NLP领域取得了比较大的突破,最大的新闻当属Google的BERT模型横扫各大比赛的排行榜。
NLP领域到目前为止有三次重大的突破:Word Embedding、Self-Attention机制和Contextual Word Embedding。
1)Word Embedding,word embedding解决了传统词向量稀疏的问题,将词映射到一个低维的稠密语义空间,从而使得相似的词可以共享上下文信息,从而提升泛化能力。这一领域最杰出的算法代表有word2vec,glove等。但是这样方案有个问题,就是没有考虑到词的上下文信息,比如bank即可能是“银行”,也可能是“水边”,通过这种方案是没有办法对这种情况进行区分的。
2)Self-Attension机制,2017年Google提出了Transformer模型,并且起了一个相当霸气的标题“Attension is all you need”,引入了Self-Attention。Self-Attention的初衷是为了用Attention替代LSTM,从而可以更好的并行(因为LSTM的时序依赖特效很难并行),从而可以处理更大规模的语料。现在Transformer已经成为Encoder/Decoder的霸主。
3)Contextual Word Embedding,2018年的研究热点就变成了怎么利用无监督的数据学到一个词在不同上下文的不同语义表示方法。在BERT之前比较大的进展是ELMo和OpenAI GPT。尤其是OpenAI GPT,它在BERT出现之前已经横扫过各大排行榜一次了,当然Google的BERT又横扫了一次。BERT的很多思路都是沿用OpenAI GPT的,要说BERT的学术贡献,最多是利用了Mask LM(这个模型在上世纪就存在了)和Next Sentence Predicting这个Multi-task Learning而已。
- Bert 整体架构
BERT是“Bidirectional Encoder Representations from Transformers”的首字母缩写。 BERT仍然使用的是Transformer模型,那它是怎么解决语言模型只能利用一个方向的信息的问题呢?答案是它的pretraining训练的不是普通的语言模型,而是Mask语言模型。
Google在论文中给了两个模型,一个base模型,还有一个大一点的large模型,它们的参数设置如下所示。
- BERT-Base,12层,768个隐单元,12个head,110M参数
- BERT-Large,24层,1024个隐单元,16个head,340M参数

Bert 输入:
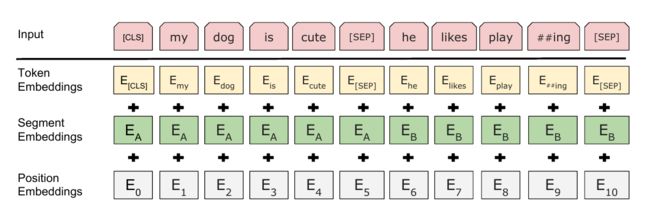
BERT的输入表示如图下图所示。比如输入的是两个句子”my dog is cute”,”he likes playing”。后面会解释为什么需要两个句子。这里采用类似GPT的两个句子的表示方法,首先会在第一个句子的开头增加一个特殊的Token [CLS],在cute的后面增加一个[SEP]表示第一个句子结束。
接着对每个Token进行3个Embedding:词的Embedding;位置的Embedding和Segment的Embedding。
BERT模型要求有一个固定的Sequence的长度,比如512。如果不够就在后面padding,否则就截取掉多余的Token,从而保证输入是一个固定长度的Token序列,后面的代码会详细的介绍。第一个Token总是特殊的[CLS],它本身没有任何语义,因此它会(必须)编码整个句子(其它词)的语义。
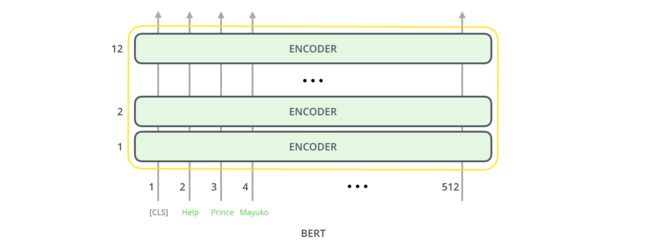
Bert 模型:
Bert模型的骨架就是Transformer的encoder模块,即一个self-attension + feed forward。
在bert-base中有12个encoder模块,在bert-large中有24个encoder模块。
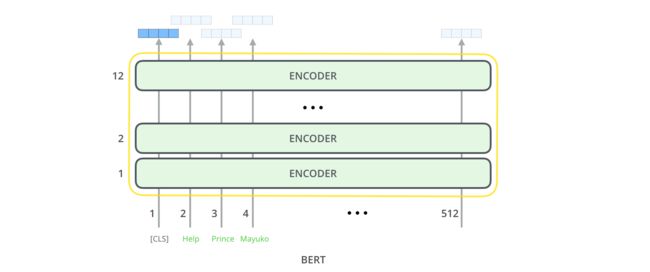
Bert 输出:
Bert 会给每个token输出一个embedding,在base中,维度为768,在large上,维度为1024。
- Bert 预训练机制
任务一:Mask LM
为了解决只能利用单向信息的问题,BERT使用的是Mask语言模型而不是普通的语言模型。Mask语言模型有点类似与完形填空——给定一个句子,把其中某个词遮挡起来,让人猜测可能的词。
这里会随机的Mask掉15%的词,然后让BERT来预测这些Mask的词,通过调整模型的参数使得模型预测正确的概率尽可能大,这等价于交叉熵的损失函数。这样的Transformer在编码一个词的时候会(必须)参考上下文的信息。
但是这有一个问题:在Pretraining Mask LM时会出现特殊的Token [MASK],但是在后面的fine-tuning时却不会出现,这会出现Mismatch的问题。因此BERT中,如果某个Token在被选中的15%个Token里,则按照下面的方式随机的执行:
- 80%的概率替换成[MASK],比如my dog is hairy → my dog is [MASK]
- 10%的概率替换成随机的一个词,比如my dog is hairy → my dog is apple
- 10%的概率替换成它本身,比如my dog is hairy → my dog is hairy
这样做的好处是,BERT并不知道[MASK]替换的是哪一个词,而且任何一个词都有可能是被替换掉的,比如它看到的apple可能是被替换的词。这样强迫模型在编码当前时刻的时候不能太依赖于当前的词,而要考虑它的上下文,甚至更加上下文进行”纠错”。比如上面的例子模型在编码apple是根据上下文my dog is应该把apple(部分)编码成hairy的语义而不是apple的语义。
任务二:NSP
在有些任务中,比如问答,前后两个句子有一定的关联关系,我们希望BERT Pretraining的模型能够学习到这种关系。因此BERT还增加了一个新的任务——预测两个句子是否有关联关系。这是一种Multi-Task Learing。BERT要求的Pretraining的数据是一个一个的”文章”,比如它使用了BookCorpus和维基百科的数据,BookCorpus是很多本书,每本书的前后句子是有关联关系的;而维基百科的文章的前后句子也是有关系的。对于这个任务,BERT会以50%的概率抽取有关联的句子(注意这里的句子实际只是联系的Token序列,不是语言学意义上的句子),另外以50%的概率随机抽取两个无关的句子,然后让BERT模型来判断这两个句子是否相关。比如下面的两个相关的句子:
[CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
下面是两个不相关的句子:
[CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
- Elmo、GPT、 Bert三者之间有什么区别
1)Elmo
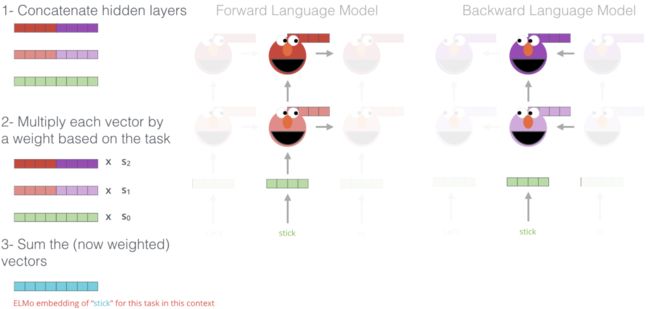
ELMo是Embeddings from Language Models的缩写,意思就是语言模型得到的(句子)Embedding。
这篇论文的想法其实非常非常简单,但是取得了非常好的效果。它的思路是用深度的双向RNN(LSTM)在大量未标注数据上训练语言模型。
然后在实际的任务中,对于输入的句子,我们使用这个语言模型来对它处理,得到输出的向量,因此这可以看成是一种特征提取。
但是和普通的Word2Vec或者GloVe的pretraining不同,ELMo得到的Embedding是有上下文的。
为了能够拿到双向信息,Elmo采用了双向分层的LSTM,最后的结果是各层hidding layer的concat后的加权
2)GPT
GPT相对于Elmo改进的地方在于使用了Transformer架构。
之前我们介绍的Transformer模型是用来做机器翻译的,它有一个Encoder和一个Decoder。这里使用的是Encoder,只不过Encoder的输出不是给Decoder使用,而是直接用它来预测下一个词,如下图所示。
但是直接用Self-Attention来训练语言模型是有问题的,因为在k时刻计算tk的时候只能利用它之前的词(或者逆向的语言模型只能用它之后的词)。但是Transformer的Self-Attention是可以利用整个句子的信息的,这显然不行,因为你让它根据”it is a”来预测后面的词,而且还告诉它整个句子是”it is a good day”,它就可能”作弊”,直接把下一个词输出了,这样loss是零。
因此这里要借鉴Decoder的Mask技巧,通过Mask让它在编码tk的时候只能利用k之前(包括k本身)的信息。
我们这里使用多层的Transformer来实现语言模型,具体为:
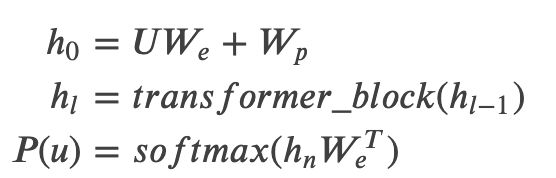
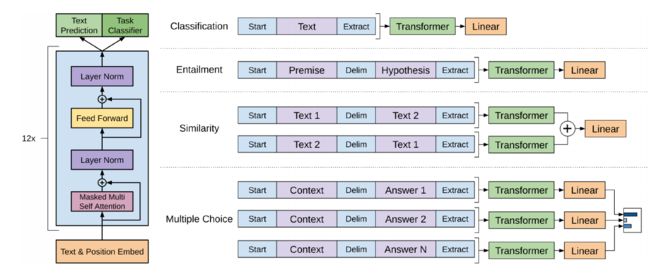
3)Bert
Elmo和GPT最大的问题就是传统的语言模型是单向的,BERT能够同时利用前后两个方向的信息。
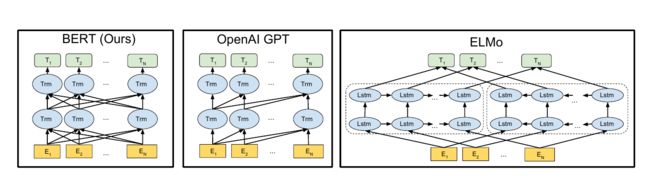
比如句子”The animal didn’t cross the street because it was too tired”。我们在编码it的语义的时候需要同时利用前后的信息,因为在这个句子中,it可能指代animal也可能指代street。根据tired,我们推断它指代的是animal,因为street是不能tired。但是如果把tired改成wide,那么it就是指代street了。传统的语言模型,不管是RNN还是Transformer,它都只能利用单方向的信息。比如前向的RNN,在编码it的时候它看到了animal和street,但是它还没有看到tired,因此它不能确定it到底指代什么。如果是后向的RNN,在编码的时候它看到了tired,但是它还根本没看到animal,因此它也不能知道指代的是animal。Transformer的Self-Attention理论上是可以同时attend to到这两个词的,但是根据前面的介绍,由于我们需要用Transformer来学习语言模型,因此必须用Mask来让它看不到未来的信息,所以它也不能解决这个问题的。
Bert采用MLM解决了双向的问题,另外Bert中还引入了NSP来方便下游任务的使用。
Bert和OpenAI GPT相比,还有一点很重要的区别就是训练数据。OpenAI GPT使用的是BooksCorpus语料,总的词数800M;而BERT还增加了wiki语料,其词数是2,500M,所以BERT训练数据的总词数是3,300M。因此BERT的训练数据是OpenAI GPT的4倍多,这是非常重要的一点。
- Bert 核心源码
根据下游任务的不同,一般来说我们需要修改的地方有如下几处。
1)tokenization.py
主要是分词的算法,BERT里英文分词主要是由FullTokenizer类来实现的,中文分词可以使用ChineseCharTokenizer类。
FullTokenizer的构造函数需要传入参数词典vocab_file和do_lower_case。如果我们自己从头开始训练模型(后面会介绍),那么do_lower_case决定了我们的某些是否区分大小写。如果我们只是Fine-Tuning,那么这个参数需要与模型一致,比如模型是uncased_L-12_H-768_A-12,那么do_lower_case就必须为True。
2)run_classifier.py / DataProcessor类
DataProcessor类负责数据是怎么读入的。这是一个抽象基类,定义了get_train_examples、get_dev_examples、get_test_examples和get_labels等4个需要子类实现的方法,另外提供了一个_read_tsv函数用于读取tsv文件。我们需要继承这个类来完成我们的数据读取操作。
3)run_classifier.py / create_model函数
在这个方法里编写实际需要处理的具体任务的代码。
4)run_classifier.py / main函数
main函数的主要代码如下,我们可以对main中模型的输出结果自定义处理方式,如调用sklearn计算准召等。
main() bert_config = modeling.BertConfig.from_json_file(FLAGS.bert_config_file) task_name = FLAGS.task_name.lower() processor = processors[task_name]() label_list = processor.get_labels() tokenizer = tokenization.FullTokenizer( vocab_file=FLAGS.vocab_file, do_lower_case=FLAGS.do_lower_case) run_config = tf.contrib.tpu.RunConfig( cluster=tpu_cluster_resolver, master=FLAGS.master, model_dir=FLAGS.output_dir, save_checkpoints_steps=FLAGS.save_checkpoints_steps, tpu_config=tf.contrib.tpu.TPUConfig( iterations_per_loop=FLAGS.iterations_per_loop, num_shards=FLAGS.num_tpu_cores, per_host_input_for_training=is_per_host)) train_examples = None num_train_steps = None num_warmup_steps = None if FLAGS.do_train: train_examples = processor.get_train_examples(FLAGS.data_dir) num_train_steps = int( len(train_examples) / FLAGS.train_batch_size * FLAGS.num_train_epochs) num_warmup_steps = int(num_train_steps * FLAGS.warmup_proportion) model_fn = model_fn_builder( bert_config=bert_config, num_labels=len(label_list), init_checkpoint=FLAGS.init_checkpoint, learning_rate=FLAGS.learning_rate, num_train_steps=num_train_steps, num_warmup_steps=num_warmup_steps, use_tpu=FLAGS.use_tpu, use_one_hot_embeddings=FLAGS.use_tpu) # 如果没有TPU,那么会使用GPU或者CPU estimator = tf.contrib.tpu.TPUEstimator( use_tpu=FLAGS.use_tpu, model_fn=model_fn, config=run_config, train_batch_size=FLAGS.train_batch_size, eval_batch_size=FLAGS.eval_batch_size, predict_batch_size=FLAGS.predict_batch_size) if FLAGS.do_train: train_file = os.path.join(FLAGS.output_dir, "train.tf_record") file_based_convert_examples_to_features( train_examples, label_list, FLAGS.max_seq_length, tokenizer, train_file) train_input_fn = file_based_input_fn_builder( input_file=train_file, seq_length=FLAGS.max_seq_length, is_training=True, drop_remainder=True) estimator.train(input_fn=train_input_fn, max_steps=num_train_steps) if FLAGS.do_eval: eval_examples = processor.get_dev_examples(FLAGS.data_dir) eval_file = os.path.join(FLAGS.output_dir, "eval.tf_record") file_based_convert_examples_to_features( eval_examples, label_list, FLAGS.max_seq_length, tokenizer, eval_file) # This tells the estimator to run through the entire set. eval_steps = None eval_drop_remainder = True if FLAGS.use_tpu else False eval_input_fn = file_based_input_fn_builder( input_file=eval_file, seq_length=FLAGS.max_seq_length, is_training=False, drop_remainder=eval_drop_remainder) result = estimator.evaluate(input_fn=eval_input_fn, steps=eval_steps) if FLAGS.do_predict: predict_examples = processor.get_test_examples(FLAGS.data_dir) predict_file = os.path.join(FLAGS.output_dir, "predict.tf_record") file_based_convert_examples_to_features(predict_examples, label_list, FLAGS.max_seq_length, tokenizer, predict_file) predict_drop_remainder = True if FLAGS.use_tpu else False predict_input_fn = file_based_input_fn_builder( input_file=predict_file, seq_length=FLAGS.max_seq_length, is_training=False, drop_remainder=predict_drop_remainder) result = estimator.predict(input_fn=predict_input_fn)