第二十五节决策树系列之信息增益和信息增益率(4)
上一节我们讲解了决策树的分裂条件以及评估纯度的其中一个方式,基尼系数。本节的话,我们再讲解一个评估纯度的方式,基于信息增益的方式,即ID3树使用的评估方式。它办的事跟Gini系数一样,也是评价纯度,但是它更客观一点,但它算起来比Gini系数稍慢一点,它办的事跟Gini系数一样,也是评价纯度,但是它更客观一点,算起来比Gini系数稍慢一点,更准确一点。这是两种不同的评价方式。
目录
1-信息增益
2-信息增益率
1-信息增益
带着信息两字就离不开熵,熵首先是一个热力学的概念,比如一个罐子,里面有好多气体分子,分子在做随机无规则的运动,叫热运动,运动的越激烈,系统内的熵就越高。它的根源是一个热力学上的概念。引入到信息论里的熵,虽然还是这个字,但已经跟原来的热力学没有直接的关系了,只不过公式形式是一样的。即:
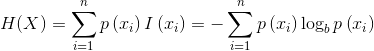
我们明显的发现它分为两部分,一部分是pi,pi代表标签值或者类别值在这个系统里的占比,另一部分是log pi。我们称![]() 叫做信息,它的单位是bit,0和1的比特。信息的原始公式是:
叫做信息,它的单位是bit,0和1的比特。信息的原始公式是:![]() 。举个例子来说明下:假设无线电考试作弊,选择题是ABCD四个选项,用0和1编码的话,不混淆的情况下,辨别四个选项。应该如何的设置这个暗号?最直观的方法就是下面这种表示方法:即A表示为00,B表示为01,C表示为10,D表示为11。在不知道它们的概率的情况下,这么选最合适。但是这种每次发的话如果有24道题,就会发48个数字。如果收费是按数字来的话有没有相对更经济点的方式能少发点总次数让答案还不被损失的传过去?假如考试95%的答案都是C,还用两位数字编码就有点浪费了。我们自然而然想到的是让答案比较多的选项用尽量少的位数表示。假设ABCD的概率分布是1/8,1/8,1/2,1/4,C出现的概率最高。我用0表示C,如果用D表示1 的话,为了不混淆的话,A,B只能用两位以上的表示01或者10,100等 ,如果发过来的是01,那么答案到底是一个C,一个D 还是A或者B。所以所以为了避免混淆,1就再也不能单独再表示答案了。那什么可以用呢?两位的可以用。假如D设为10的话,01还能再用于别的答案吗?不能,因为比如来一个0010,不知道是两个0,一个10。还是一个0,一个10和0。10被D用的话,11还能在用吗?不能了。因为如果A设置为为11的话,最后剩一个答案B从000~111都不能表示了,都会和11混淆。所以11在D为10的前提下不能再用了。所以两位的只能用10。即D用10。剩下A,B的表示都是三位数了。有兴趣的可以试下在C 用0表示,D用10表示,A用111,B用101表示不会被混淆。假如我们40道题,20道题是C,10道题是D,5道题是B,5道题是A,现在只需要发送20*1+10*2+5*3+5*3=70。对比平均编码长度,都是两位的话。40*2=80,少发送了10个字节。在完全无损的情况下,我们只用了一点点的小技巧,就能使数据进行压缩。并且压缩是免费的。
。举个例子来说明下:假设无线电考试作弊,选择题是ABCD四个选项,用0和1编码的话,不混淆的情况下,辨别四个选项。应该如何的设置这个暗号?最直观的方法就是下面这种表示方法:即A表示为00,B表示为01,C表示为10,D表示为11。在不知道它们的概率的情况下,这么选最合适。但是这种每次发的话如果有24道题,就会发48个数字。如果收费是按数字来的话有没有相对更经济点的方式能少发点总次数让答案还不被损失的传过去?假如考试95%的答案都是C,还用两位数字编码就有点浪费了。我们自然而然想到的是让答案比较多的选项用尽量少的位数表示。假设ABCD的概率分布是1/8,1/8,1/2,1/4,C出现的概率最高。我用0表示C,如果用D表示1 的话,为了不混淆的话,A,B只能用两位以上的表示01或者10,100等 ,如果发过来的是01,那么答案到底是一个C,一个D 还是A或者B。所以所以为了避免混淆,1就再也不能单独再表示答案了。那什么可以用呢?两位的可以用。假如D设为10的话,01还能再用于别的答案吗?不能,因为比如来一个0010,不知道是两个0,一个10。还是一个0,一个10和0。10被D用的话,11还能在用吗?不能了。因为如果A设置为为11的话,最后剩一个答案B从000~111都不能表示了,都会和11混淆。所以11在D为10的前提下不能再用了。所以两位的只能用10。即D用10。剩下A,B的表示都是三位数了。有兴趣的可以试下在C 用0表示,D用10表示,A用111,B用101表示不会被混淆。假如我们40道题,20道题是C,10道题是D,5道题是B,5道题是A,现在只需要发送20*1+10*2+5*3+5*3=70。对比平均编码长度,都是两位的话。40*2=80,少发送了10个字节。在完全无损的情况下,我们只用了一点点的小技巧,就能使数据进行压缩。并且压缩是免费的。
我们来看下一个信息的计算。-log2(1/2)=1,-log2(1/4)=2,-log2(1/8)=3。当概率为1/2的时候,用一位编码解决,概率为1/4的时候可以用两位编码解决,而1/8的时候用三位编码解决。发现信息的值刚好和位数对应上,所以这也就是为什么用-log2Pi来表示信息的概念。它的单位真的是比特。它是无损压缩的理论上限,意思就是说你再怎么耍技巧。要想把信息完整的发过来,至少需要这么多信息。这也是信息的来源。而我们的熵其实就是平均码长。计算方式为1/8*3+1/8*3+1/2*1+1/4*2。意思就是说有两个1/8的数需要3个码长,1/2的数需要1个码长,1/4的数需要2个码长,所以整个系统发送过来平均发送一个答案需要1/8*3+1/8*3+1/2*1+1/4*2这么多的码长。这个就是熵。假如答案全部是A,或者里面答案只有1个A的时候,实际上我们就不需要发送那么多码长了,直接发送A的编号,或者不发,因为我们已经知道答案就是A了。所以这个系统里面答案越纯,发送的信息越少。而里面答案越多,越没有规律可循,我们就需要用越大的信息来发送。所以我们就用熵的概念来表示决策树分类的子集的纯度。对于纯度来说,纯度的pi代表标签值在这个系统里的占比,纯度越纯代表熵越低,我们用信息熵来评估纯度,它其实思路和基尼系数一样,基尼系数越低越纯,熵也是,越低越纯。
了解完熵的概念,我们再说下信息增益:分裂前的信息熵 减分裂后的信息熵。它一样也需要在前面加一个权重。
IG= H(D)- H(D1)*|D1|/|D|- H(D2)*|D2|/|D|。
假如如下数据:

分裂之前的熵是H(D)=-log2(0.2)-log2(0.8)。分裂之后的熵是H(D1)=-log2(0.3)-log2(0.7)和H(D1)=-log2(0.5)-log2(0.5).那么信息增益IG=H(D)-(D1/D*H(D1)+D2/D*H(D2))=H(D)-(100/1000*H(D1)+900/1000*H(D2))。如果不乘以比重的话假如一个节点里面就分了一个数据,另一个节点分了很多的数据。会导致一个加权的很高,一个加权的很低,很不合理。所以需要乘以各自数据所占的比重。信息增益是正数还是负数呢?我们来推测下,熵是越分越低好,还是越分越高好,肯定是越分越低好,越低代表越纯。也就是说原先系统比较混乱,越分后面越清楚,越纯,所以我们一开始的熵是比较高的,后面越来越低,而信息增益是拿之前的熵减去之后的熵,所以肯定是个正数。这个正数越大越好,因为越大代表这次分裂使系统的混乱程度降低的越多。
我们来看一个实际应用信息增益解决生活中的一个案例:
以下是一个统计用户流失度的一个数据,is_lost是它的标签,第一列是用户ID,第二列gender是性别,第三列act_info是活跃度,第四列is_lost是否流失。我们希望通过分析找到最能影响用户流失的因素。

其中重点说下第三列,本身来说活跃度应该是个连续性数据,这里做了一些处理。因为信息增益天生对连续性数据支持的不是特别好。这里连续性训练集交给计算机的数据,一般是把同一个区间段的归为一类,让它变成离散型数据。比如身高是连续性数据,以10厘米一组的话,就会分成各个组,每组的数据再进行统计。我们在做其他算法模型的时候有时候还会对处理完后的离散数据进行one-hot编码,假如训练集里有四个城市,北京,上海,广州,深圳,在统计上就是表中的某一列,要怎么把它转化成计算机数据?北京为1,广州为2,上海为3,深圳为4,直观的讲难道深圳>北京,所以这样的数据交给算法是不合适的。所以这里我们用one-hot编码对数据进行处理,即把一个维度上的四个值拆成四列,is北京,is广州,is上海,is深圳,这四列里只会同时有一个为1,如果住在北京,那么北京是1,其它为0。即把原本在一个维度上提取下来的数据,强制地拆成若干个列的这种方式叫做one-hot编码,所谓one-hot,即独热编码,就是这四项里边只有一个被点亮了。通常对于没有大小顺序的数据我们一定要使用one-hot编码。本例中因为只是单纯看下活跃度的数据情况各个占比对总体用户损失情况的影响,所以没必要再转成one-hot编码。我们对上面的数据进行一个统计:
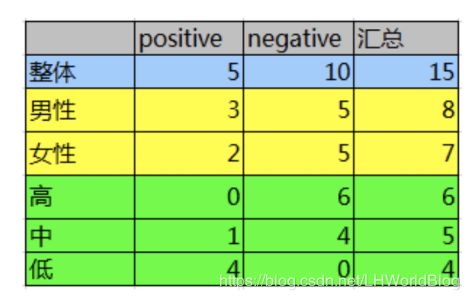
这里面positive是没有流失,对应数值1。negative是流失,对应数值是0。所以第二行的统计实际上就是在男性的前提下,positive为3,可以用条件概率表示成p(y=1|x=man)=3/8。我们看下上面两个条件分裂下各自的信息增益。
15个样本,其中负例有10个,正例有5个。P1对应着10/15,P2对应着5/15,所以原始的整体熵H(D)。
![]()
假设选择男女作为分裂条件,则性别熵是:男是g1,女是g2。相当于分成两个子树。
![]()
![]()
则性别信息增益:因为男性占8/15,女性占7/15,又乘以各自比例,所以:
![]()
同理计算活跃度的熵:相当于分成3个子树。
则 ![]()
活跃度信息增益:
![]()
很明显活跃度的信息增益比较大,说明熵减的厉害,也就是意味着活跃度对用户流失的影响更大。
2-信息增益率
假如不幸以这uid一列作为分裂条件去选择了,我们的目标是选择信息增益最大的方式去分裂,什么情况下信息增益最大?当分了一个和用户数量同样多分枝的子节点,15个子节点的时候,此时信息增益是最大的,因为所有叶子节点都最纯了,只有一个数据,则每一个节点的熵都是-log2(1)=0,按照信息增益的计算公式IG=E(s)-0=E(s),相当于没减,那么信息增益肯定是最大的。但这样会导致什么问题呢,过拟合问题。对训练集分的特别完美。为了去惩罚这种分裂方式,我们引入另一个计算纯度的计算方式:信息增益率。
计算公式为:信息增益/类别本身的熵。
![]()

既然是熵,公式形式就是- ∑Pi*log2Pi的形式,算熵就需要pi,要pi就需要把原来的数据分为几堆。原来是靠yi=label来分堆的,那么比如30,30,10,p1=3/10,p2=3/10,p3=0.1,来算节点内部的pi,而现在的pi是总的系统的pi,系统分成三份了,就有三类数据,此时的pi就是以节点的数据占总的数据占比为依据,而不是以看节点内y的label 标签为依据。比如下图:
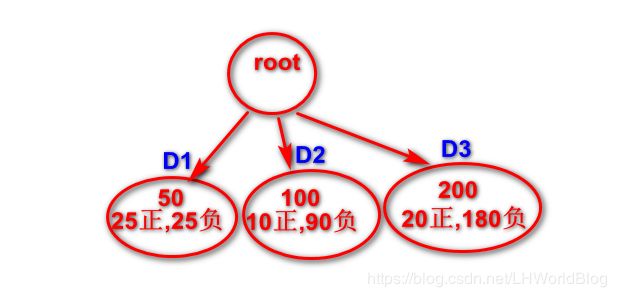
我们计算这次分裂情况的类别本身的熵时应该把D1,D2,D3都考虑进去。D1个数占总数为50/350,所以T1/T=-50/350,依次类推。所以SIS=-50/350*log250/350-100/350*log100/350-200/350*log200/350,为这次分裂情况下类别本身的熵。如果我们按照之前计算用户留存的例子来说,按照序号来分的话,分成15个节点,此时的信息增益非常非常大。但是分子SIS会变大还是小呢?我们可以直观地感受下,此时分成的15个子节点,每一个子节点都只包含一个数据,而计算SIS的时候是考虑所有节点的,所以相当于把分成的15个节点看成一个整体,每一个子节点都是一个子集,此时这个系统里面类别特别多,所以特别混乱,整体熵肯定越高。所以把这个数放在分母上,即便原先的信息增益很大,但因为除了一个很大的分母,所以整体值也变小。所以我们要想使得信息增益率大就需要分母越小,即系统本身的熵越小,说明分的节点不是那么多,并且作为一个系统来说,相对类别纯一点,没有那么多节点,整体系统熵就越低。分子越大,即信息增益又很大,说明本次分类使系统混乱程度降低的越多。
所以信息增益率能自动的帮我们选择分几支,用什么条件分最好的问题,为什么要引入信息增益率呢?实际上背后是符合最大熵模型的。
我们总结下分类树如何分裂?即遍历所有可能的分裂方法。 可以使用3种方式判断纯度 即 Gini系数对应CART树, 信息增益 对应ID3树, 信息增益率对应 C4.5树。
下一节我们讲解另一种分裂方式,回归树。