- 开心
蒋泳频
从无比抗拒来上课到接受,感动,收获~看着波哥成长,晶晶幸福笑容满面。感觉自己做的事情很有意义,很开心!还有3个感召目标就是还有三个有缘人,哈哈。明天感召去明日计划:8:30-11:00小公益11:00-21点上班,感召图片发自App图片发自App图片发自App
- 今天我破防了
sin信仰
今天本来是大年初一,新年的第一天,应该是高高兴兴的一天,但是我怎么也高兴不起来。具体原因很简单,原本计划年后去县城找了一份会计的工作,被公公婆婆否定了,我心里立马就不舒服了,但是当时刚好肚子疼,我去了厕所,等我上完厕所,公公由于喝了酒还在那里和婆婆唠叨个没完。然后我就在心情极度压抑的情况下把午饭吃完的碗筷和锅给刷了。边刷碗筷和锅,边在那里难受,感觉自己在这个家里真的是过的憋屈死了,公婆不让我去上班
- DIV+CSS+JavaScript技术制作网页(旅游主题网页设计与制作)云南大理
STU学生网页设计
网页设计期末网页作业html静态网页html5期末大作业网页设计web大作业
️精彩专栏推荐作者主页:【进入主页—获取更多源码】web前端期末大作业:【HTML5网页期末作业(1000套)】程序员有趣的告白方式:【HTML七夕情人节表白网页制作(110套)】文章目录二、网站介绍三、网站效果▶️1.视频演示2.图片演示四、网站代码HTML结构代码CSS样式代码五、更多源码二、网站介绍网站布局方面:计划采用目前主流的、能兼容各大主流浏览器、显示效果稳定的浮动网页布局结构。网站程
- 2019-3-23晨间日记
红红火火小耳朵
今天是什么日子起床:7点40就寝:23点半天气:有太阳,不过一会儿出来一会儿进去特别清爽的凉意,还蛮舒服的心情:小激动要给女朋友过生日啦纪念日:田田女士过生日任务清单昨日完成的任务,最重要的三件事:1.英语一对一2.运动计划3.认真护肤习惯养成:调整状态周目标·完成进度英语七天打卡(5/7)轻课阅读(87/180)音标课(25/30)读书(福尔摩斯一章)学习·信息·阅读#英语课#Cookingte
- 骑昆明到北海—119 砚山县
61清风i
从十年前第一次长途骑行青海湖开始每年一次长途骑行看风景,尝各地美食,探访异域文化,记录途中美食美景美事,已逐渐形成习惯。每年春季详细规划好线路,夏季出行,2020年因为疫情迟迟不能确定线路和行程。总算到了暑期疫情逐渐消失,规划了50多天的云南昆明—广西北海计划。本次行程从云南昆明出发到广西北海市结束,五十一天骑行二千多公里线路昆明-官渡古镇-环滇池--澄江市一抚仙湖—路居镇--江川区--通海县—龙
- 无题
琴韵无声
问了几家门诊部都没有科兴疫苗,突然自我感觉这种品牌的疫苗是不是少一些,于是又无端滋生焦虑感,可别一拖再拖影响孩子上学,学校要求下学期开学得接种完新冠疫苗。我在这种自制的焦虑的驱使下,立马上网查询看哪里能打到北京科兴的疫苗,终于找到了,大喜。与珊宝一起打车过去(路比较远,早想借此机会让她徒步拉练一下的计划泡汤了)。到达目的地,一看到医院大门前一条长龙似的队伍就知道那里应该是打疫苗的地方。迅速过去排队
- Java爬虫框架(一)--架构设计
狼图腾-狼之传说
java框架java任务html解析器存储电子商务
一、架构图那里搜网络爬虫框架主要针对电子商务网站进行数据爬取,分析,存储,索引。爬虫:爬虫负责爬取,解析,处理电子商务网站的网页的内容数据库:存储商品信息索引:商品的全文搜索索引Task队列:需要爬取的网页列表Visited表:已经爬取过的网页列表爬虫监控平台:web平台可以启动,停止爬虫,管理爬虫,task队列,visited表。二、爬虫1.流程1)Scheduler启动爬虫器,TaskMast
- 数幸福D10
3c807316efec
王多妈妈幸福能力提升计划依靠皇上托举皇上做一个五半三平的小女人一:感知到的幸福和快乐1:点赞皇上①下班前皇上问我晚上吃饭准备怎么弄,我们买点菜回家做饭吧皇上问我想吃什么,我说多可以,皇上很用心的准备晚饭,一回到家皇上先回家做饭,我说后备箱还有我的行李,皇上说等一下我再下来拿好吗?语气特别好,眼神多是商量的,皇上现在总是有意识的考虑我的感受②吃完饭我们准备一起接女儿放学,皇上说碗他洗,我想着一起收拾
- 2023-06-19【感恩日记】第246篇
o泡沫o
思想日记:坚持下去,相信自己一定可以的【感恩日记】第246篇1.我真是太幸福啦!感恩孩子早起阅读,放学到学生之家完成作业,平安度过美好的一天。感恩!感恩!感恩!❤️2.我真是太幸福啦!感恩自己早起给孩子煮早餐,完成计划的工作,晚上学习。感恩!感恩!感恩!❤️3.我真是太幸福啦!感恩为我设计效果图的老师。感恩!感恩!感恩!❤️4.我真是太幸福啦!感恩父母养育了我,有妈的孩子真幸福。感恩!感恩!感恩!
- “元宇宙”带不动Meta?基本业务已“后院起火”!小扎举步维艰!
链科天下
由于宏观经济疲软、市场动荡,“放缓”已经成为美国科技股的主线逻辑,曾风光无限的科技巨头Meta也开始一路下行、举步维艰。据彭博社报道,Meta已宣布计划裁员并重组团队以削减预算,这是该公司2004年成立以来首次大幅削减预算。此次裁员或受到业绩低迷的影响,Q2财报显示Meta业绩远不及预期,上市以来营收同比出现首次下滑,净利连续三季度下降。扎克伯格表示,“希望经济能够稳定下来,但从目前的情况来看并非
- 2022-1-12晨间日记
云卷云舒_a1b9
起床:6:20就寝:23:00天气:阴心情:还好纪念日:法考主观体出分的日子叫我起床的不是闹钟是梦想年度目标及关键点:备考初级会计师;坚持运动,减重,阅读,学习本月重要成果:报名今日三只青蛙/番茄钟学习听课;瑜伽课;记账盘点成功日志-记录三五件有收获的事务1.收到鲜花2.早起做早餐3.引导孩子做计划财务检视支出严重超预算,检视一月的预算是否合理人际的投入同学联系;开卷有益-学习/读书/听书听初级课
- 进销存小程序源码 PHP网络版ERP进销存管理系统 全开源可二开
摸鱼小号
php
可直接源码搭建部署发布后使用:一、功能模块介绍该系统模板主要有进,销,存三个主要模板功能组成,下面将介绍各模块所对应的功能;进:需要将产品采购入库,自动生成采购明细台账同时关联财务生成付款账单;销:是指对客户的销售订单记录,汇总生成产品销售明细及回款计划;存:库存的日常盘点与统计,库存下限预警、出入库台账、库存位置等。1.进购管理采购订单:采购下单审批→由上级审批通过采购入库;采购入库:货品到货>
- 人要有自知之明
孟冬廿六
今天中午跟一学妹聊天,谈起结婚找对象的问题,小姑娘年龄不算大,二十七岁,但是整个人很清醒很现实,她如今在一国企上班,吃住都不花钱,再加上她经常出差,补助奖金这一块儿也不少,一年下来七七八八的有个小二十万,这对于一个小姑娘来说已经非常不错了,她计划这两年自己付首付买房,然后想要买辆MINI,小姑娘一米七六的个子,长得漂亮有气质,家庭条件也不错,所以对于择偶方面也有一定的要求,最好是事业单位的,父母有
- 2021年周总结 03
Ruby之家
这周的生活过得也是比较快,因为暂时住的离公司有点距离,所以通勤时间相对较长一点,而在地铁上的一个半小时如何充分利用起来,则是我最近一直在思考的问题,2021年想让自己的生活都运行在计划中。(有时候自己想干一件事情就总是给自己找很多借口,想着以后怎么怎么样?然而哪有那么多的以后,能够方便当下的工作生活就立马执行就OK,这仅仅只是我此时想到背的很重的老人机笔记本电脑,也算是陪伴我快8年的—当时买的时候
- 假期开始了
木子争
今天上午的考试结束后,假期就算开始了,只不过明天再去批改一下试卷就可以了。时间过得真快,不知不觉中一个学期就过去了,今年也马上就结束了,想想当初自己的目标和计划,好多都还没有实现。以后就更要好好的做事情了,坚持说到做到,按照自己的计划踏踏实实地去做事情。趁假期好好调整自己。
- python爬取微信小程序数据,python爬取小程序数据
2301_81900439
前端
大家好,小编来为大家解答以下问题,python爬取微信小程序数据,python爬取小程序数据,现在让我们一起来看看吧!Python爬虫系列之微信小程序实战基于Scrapy爬虫框架实现对微信小程序数据的爬取首先,你得需要安装抓包工具,这里推荐使用Charles,至于怎么使用后期有时间我会出一个事例最重要的步骤之一就是分析接口,理清楚每一个接口功能,然后连接起来形成接口串思路,再通过Spider的回调
- 2022-04-10
凤凰语言艺术吴老师
读刘院日更《再读稻盛和夫:习惯于用自己的承诺,倒逼自己成功》有感过去讲做人做事要“不言实行”,换言之,比起豪言壮语,默不作声、埋头实干才是美德。现如今社会,闷头干有时候也会失去动力。因为闷头干没有外界的监督,制定的计划只有自己知道,即使没有百分百完成,别人也不知道,久之就养成了得过且过的心态。就像当初自己花了不少钱报名学习日语一样,当时只是闷头学,没有开公失去了众人的监督,以致于后来因为工作和日常
- metaRTC8.0,一个全新架构的webRTC SDK库
metaRTC
webrtc音视频
概述metaRTC8.0是metaRTC开源以来架构变化最大的一个版本,是metaIPC3.0等高性能的基础。metaRTC8.0是一个全新架构版本,并非在metaRTC7.0版本上简单升级,在QOS/语音对讲/内存占用/视频文件录制读取等方面新增多个模块,在弱网对抗/语音对讲/内存优化等效果上有显著提升。metaRTC8.0在一年多的开发中进行了近200次迭代,metaRTC8.0社区版计划在2
- 黄丽红日精进98/105
做自己小太阳
感恩感恩今日份的拍照ing感恩今日份电视重新可以看感恩妹妹帮忙晾衣服感恩在路上的自己感恩我的朋友们和家人见1.今日份看了胡歌的一个节目,2010年的,10年之前,他的真实和有爱感动了我,不愧是我喜欢的胡歌2.今日份每日一练终于自己开始了调整后计划,流行病也开始复习,一切在路上3.妆容精致心情没好,在家注意收拾自己,画个淡妆最起码要精神面貌佳,回村后的我已经很像大妈了!!!感1.自己也是一个温暖的人
- 2022-11-25 疫情卷土而来
快乐微笑每一天
原计划本周因比赛休息两天半,结果一个阳性患者疫情转变了所有,轮休课表换掉,继续周五上课;比赛顺延,假期顺延,相对应确诊病例所在区域封闭。这疫情何时是一个尽头,谁也无法知晓,唯有进出带好口罩,保护自己,方能战胜疫情。疫情无情,人间温暖,期待疫情早日过去,大地重返平安和谐。
- 360前端星计划-动画可以这么玩
马小蜗
动画的基本原理定时器改变对象的属性根据新的属性重新渲染动画functionupdate(context){//更新属性}constticker=newTicker();ticker.tick(update,context);动画的种类1、JavaScript动画操作DOMCanvas2、CSS动画transitionanimation3、SVG动画SMILJS动画的优缺点优点:灵活度、可控性、性能
- 学会这招!用python爬取微博评论(无重复数据)
Python白白白白
python爬取微博评论(无重复数据)前言一、整体思路二、获取微博地址1、获取ajax地址2、解析页面中的微博地址3、获取指定用户微博地址三、获取主评论四、获取子评论1、解析子评论2、获取子评论五、主函数调用1、导入相关库2、主函数执行3、结果写在最后Tip:本文仅供学习与交流,切勿用于非法用途!!!前言前段时间微博上关于某日记的评论出现了严重的两极分化,出于好奇的我想对其中的评论以及相关用户做一
- 2021.10.25-2021.10.31一周计划
从21年9月11日起
一、事业1、工作:100封开发信。2、学习开发新客户知识补充30min/天*3天二、心灵1、晨间日记+一日总结。2、读经:15分钟/天*5天3、10min/天*5天观照自己的内心。三、成长1、趁早学习:3个主题并行。美貌、赚钱、饮食—-并落地实践2、纸质书:30分钟/天*6天《刻意练习》3、一周总结和计划4、时间管理群人员的学习跟进四、社交西湖一圈行五、亲子1、带小朋友出去走走2、制作卡片,实行积
- 2023-02-06
暖暖de严严
中原焦点团队第33期中级班学员坚持分享第353天总约练124次来访者83观察员37咨询师4过了正月十五,这个年也就算过去了。早上起床,竟然也有种不想上班的感觉。当然,这只是一瞬间的想法,责任还是促使自己立马行动起来。审视自己的生活:我对自己的要求都达到了吗?那些列在计划表上的内容都在慢慢实施了吗?那些简单易行的生活好习惯,都在坚持吗?终生学习的任务,有在完成吗?最近工作开始忙碌,手上的工作都在按步
- 让你的孩子悄悄拔尖
水墨烟岚
帮助孩子找到适合自己的方法,相信我,只要正确地努力,孩子的成绩一定会进步!1.这些准备一定要有:都有一个错题本;都有一个好题本;新课之前一定先预习;先复习后做作业;做作业要计时(限时训练)。2.计划管理——有规律长计划,短安排在制定一个长期目标的同时,一定要制定一个短期学习目标,这个目标要切合自己的实际,通过努力是完全可以实现的。最重要的是,能管住自己,也就挡住了各种学习上的负面干扰,如此,那个“
- 飞机,你好!------2020年12月25日,panda出生的第627天
小妖怪潘达
今天的婚礼,热热闹闹,很多粑粑的本科同学,可是时过境迁,大家都有了自己的朋友圈。我们临时决定今天下午就回家,本来计划是去周边玩两天,可是今天胖哒不太好,有点拉肚子,加上在这边的住宿环境不是很安静,外面轰隆的过路车,特别吵,别说胖哒,麻麻都没法好好睡觉,可能是因为熟悉了,胖哒不再拒绝坐粑粑同学的车,回程的高铁也稍微好了一丢丢,徐州站停留时间较长,我们下车出去透气,胖哒突然说"飞机,你好”,粑粑麻麻哭
- 借力创新 共同进步
徐立华
借力创新共同进步文/徐立华2021年8月22日为期3天的第七届线上教育行走全国教师公益研修夏令营活动落下来了帷幕,但是美仁们的行走热情并没有减弱,从24日到26日每个学习群里都在进行着活动后的继续分享活动,26日晚上海的周连秀老师给我们分享了作为不擅长写作的她做志愿者的计划和行动,在周老师的分享中,我深深被她的教育智慧所折服。周老师不擅长写作,但是她又非常想参加教育行走活动,怎么办呢?思考之后,她
- 爬虫之隧道代理:如何在爬虫中使用代理IP?
2401_87251497
python开发语言爬虫网络tcp/ip网络协议
在进行网络爬虫时,使用代理IP是一种常见的方式来绕过网站的反爬虫机制,提高爬取效率和数据质量。本文将详细介绍如何在爬虫中使用隧道代理,包括其原理、优势以及具体的实现方法。无论您是爬虫新手还是有经验的开发者,这篇文章都将为您提供实用的指导。什么是隧道代理?隧道代理是一种高级的代理技术,它通过创建一个加密的隧道,将数据从客户端传输到代理服务器,再由代理服务器转发到目标服务器。这样不仅可以隐藏客户端的真
- 晨间日记(202206270375)
锋听慧言曼语
起床:4:50就寝:23:00天气:晴心情:开心一、任务清单(一)昨日完成的任务,最重要的三件事1.完成45场直播的第7场;2.完成高知团队薪酬分配系列会议;3.完成;(二)未完成事情及原因(三)计划外事情(四)习惯养成:做一个长期主义者1.早起第688天;2.坚持晨跑452天。3.坚持亲子绘本伴读1636天4.坚持写晨间日记375天。5.坚持每天阅读至少1小时209(阅读超过1小时)天:二、周目
- 体适能NO.2
leeson许一
与其过几年或几十年地狱一般的日子慢慢变弱、生病,痛苦的拖延油尽灯枯的过程,我们不如把死亡压缩为生命中一个短暂的片段。与其慢慢萎缩成一团恶心的肥肉,我们的离开骑士可以像是大重量深蹲最后一组最后失败的那一次。在背迅速压垮离开这个世界之前,我们可以强大而富有生机的姿势迎接最后的时光。保持强壮,直到生命的最后一刻”——这段话摘自《力量训练计划》,与大家共勉。天生为运动而生,为什么你选择遗忘运动?心率心率指
- Java实现的简单双向Map,支持重复Value
superlxw1234
java双向map
关键字:Java双向Map、DualHashBidiMap
有个需求,需要根据即时修改Map结构中的Value值,比如,将Map中所有value=V1的记录改成value=V2,key保持不变。
数据量比较大,遍历Map性能太差,这就需要根据Value先找到Key,然后去修改。
即:既要根据Key找Value,又要根据Value
- PL/SQL触发器基础及例子
百合不是茶
oracle数据库触发器PL/SQL编程
触发器的简介;
触发器的定义就是说某个条件成立的时候,触发器里面所定义的语句就会被自动的执行。因此触发器不需要人为的去调用,也不能调用。触发器和过程函数类似 过程函数必须要调用,
一个表中最多只能有12个触发器类型的,触发器和过程函数相似 触发器不需要调用直接执行,
触发时间:指明触发器何时执行,该值可取:
before:表示在数据库动作之前触发
- [时空与探索]穿越时空的一些问题
comsci
问题
我们还没有进行过任何数学形式上的证明,仅仅是一个猜想.....
这个猜想就是; 任何有质量的物体(哪怕只有一微克)都不可能穿越时空,该物体强行穿越时空的时候,物体的质量会与时空粒子产生反应,物体会变成暗物质,也就是说,任何物体穿越时空会变成暗物质..(暗物质就我的理
- easy ui datagrid上移下移一行
商人shang
js上移下移easyuidatagrid
/**
* 向上移动一行
*
* @param dg
* @param row
*/
function moveupRow(dg, row) {
var datagrid = $(dg);
var index = datagrid.datagrid("getRowIndex", row);
if (isFirstRow(dg, row)) {
- Java反射
oloz
反射
本人菜鸟,今天恰好有时间,写写博客,总结复习一下java反射方面的知识,欢迎大家探讨交流学习指教
首先看看java中的Class
package demo;
public class ClassTest {
/*先了解java中的Class*/
public static void main(String[] args) {
//任何一个类都
- springMVC 使用JSR-303 Validation验证
杨白白
springmvc
JSR-303是一个数据验证的规范,但是spring并没有对其进行实现,Hibernate Validator是实现了这一规范的,通过此这个实现来讲SpringMVC对JSR-303的支持。
JSR-303的校验是基于注解的,首先要把这些注解标记在需要验证的实体类的属性上或是其对应的get方法上。
登录需要验证类
public class Login {
@NotEmpty
- log4j
香水浓
log4j
log4j.rootCategory=DEBUG, STDOUT, DAILYFILE, HTML, DATABASE
#log4j.rootCategory=DEBUG, STDOUT, DAILYFILE, ROLLINGFILE, HTML
#console
log4j.appender.STDOUT=org.apache.log4j.ConsoleAppender
log4
- 使用ajax和history.pushState无刷新改变页面URL
agevs
jquery框架Ajaxhtml5chrome
表现
如果你使用chrome或者firefox等浏览器访问本博客、github.com、plus.google.com等网站时,细心的你会发现页面之间的点击是通过ajax异步请求的,同时页面的URL发生了了改变。并且能够很好的支持浏览器前进和后退。
是什么有这么强大的功能呢?
HTML5里引用了新的API,history.pushState和history.replaceState,就是通过
- centos中文乱码
AILIKES
centosOSssh
一、CentOS系统访问 g.cn ,发现中文乱码。
于是用以前的方式:yum -y install fonts-chinese
CentOS系统安装后,还是不能显示中文字体。我使用 gedit 编辑源码,其中文注释也为乱码。
后来,终于找到以下方法可以解决,需要两个中文支持的包:
fonts-chinese-3.02-12.
- 触发器
baalwolf
触发器
触发器(trigger):监视某种情况,并触发某种操作。
触发器创建语法四要素:1.监视地点(table) 2.监视事件(insert/update/delete) 3.触发时间(after/before) 4.触发事件(insert/update/delete)
语法:
create trigger triggerName
after/before
- JS正则表达式的i m g
bijian1013
JavaScript正则表达式
g:表示全局(global)模式,即模式将被应用于所有字符串,而非在发现第一个匹配项时立即停止。 i:表示不区分大小写(case-insensitive)模式,即在确定匹配项时忽略模式与字符串的大小写。 m:表示
- HTML5模式和Hashbang模式
bijian1013
JavaScriptAngularJSHashbang模式HTML5模式
我们可以用$locationProvider来配置$location服务(可以采用注入的方式,就像AngularJS中其他所有东西一样)。这里provider的两个参数很有意思,介绍如下。
html5Mode
一个布尔值,标识$location服务是否运行在HTML5模式下。
ha
- [Maven学习笔记六]Maven生命周期
bit1129
maven
从mvn test的输出开始说起
当我们在user-core中执行mvn test时,执行的输出如下:
/software/devsoftware/jdk1.7.0_55/bin/java -Dmaven.home=/software/devsoftware/apache-maven-3.2.1 -Dclassworlds.conf=/software/devs
- 【Hadoop七】基于Yarn的Hadoop Map Reduce容错
bit1129
hadoop
运行于Yarn的Map Reduce作业,可能发生失败的点包括
Task Failure
Application Master Failure
Node Manager Failure
Resource Manager Failure
1. Task Failure
任务执行过程中产生的异常和JVM的意外终止会汇报给Application Master。僵死的任务也会被A
- 记一次数据推送的异常解决端口解决
ronin47
记一次数据推送的异常解决
需求:从db获取数据然后推送到B
程序开发完成,上jboss,刚开始报了很多错,逐一解决,可最后显示连接不到数据库。机房的同事说可以ping 通。
自已画了个图,逐一排除,把linux 防火墙 和 setenforce 设置最低。
service iptables stop
- 巧用视错觉-UI更有趣
brotherlamp
UIui视频ui教程ui自学ui资料
我们每个人在生活中都曾感受过视错觉(optical illusion)的魅力。
视错觉现象是双眼跟我们开的一个玩笑,而我们往往还心甘情愿地接受我们看到的假象。其实不止如此,视觉错现象的背后还有一个重要的科学原理——格式塔原理。
格式塔原理解释了人们如何以视觉方式感觉物体,以及图像的结构,视角,大小等要素是如何影响我们的视觉的。
在下面这篇文章中,我们首先会简单介绍一下格式塔原理中的基本概念,
- 线段树-poj1177-N个矩形求边长(离散化+扫描线)
bylijinnan
数据结构算法线段树
package com.ljn.base;
import java.util.Arrays;
import java.util.Comparator;
import java.util.Set;
import java.util.TreeSet;
/**
* POJ 1177 (线段树+离散化+扫描线),题目链接为http://poj.org/problem?id=1177
- HTTP协议详解
chicony
http协议
引言
- Scala设计模式
chenchao051
设计模式scala
Scala设计模式
我的话: 在国外网站上看到一篇文章,里面详细描述了很多设计模式,并且用Java及Scala两种语言描述,清晰的让我们看到各种常规的设计模式,在Scala中是如何在语言特性层面直接支持的。基于文章很nice,我利用今天的空闲时间将其翻译,希望大家能一起学习,讨论。翻译
- 安装mysql
daizj
mysql安装
安装mysql
(1)删除linux上已经安装的mysql相关库信息。rpm -e xxxxxxx --nodeps (强制删除)
执行命令rpm -qa |grep mysql 检查是否删除干净
(2)执行命令 rpm -i MySQL-server-5.5.31-2.el
- HTTP状态码大全
dcj3sjt126com
http状态码
完整的 HTTP 1.1规范说明书来自于RFC 2616,你可以在http://www.talentdigger.cn/home/link.php?url=d3d3LnJmYy1lZGl0b3Iub3JnLw%3D%3D在线查阅。HTTP 1.1的状态码被标记为新特性,因为许多浏览器只支持 HTTP 1.0。你应只把状态码发送给支持 HTTP 1.1的客户端,支持协议版本可以通过调用request
- asihttprequest上传图片
dcj3sjt126com
ASIHTTPRequest
NSURL *url =@"yourURL";
ASIFormDataRequest*currentRequest =[ASIFormDataRequest requestWithURL:url];
[currentRequest setPostFormat:ASIMultipartFormDataPostFormat];[currentRequest se
- C语言中,关键字static的作用
e200702084
C++cC#
在C语言中,关键字static有三个明显的作用:
1)在函数体,局部的static变量。生存期为程序的整个生命周期,(它存活多长时间);作用域却在函数体内(它在什么地方能被访问(空间))。
一个被声明为静态的变量在这一函数被调用过程中维持其值不变。因为它分配在静态存储区,函数调用结束后并不释放单元,但是在其它的作用域的无法访问。当再次调用这个函数时,这个局部的静态变量还存活,而且用在它的访
- win7/8使用curl
geeksun
win7
1. WIN7/8下要使用curl,需要下载curl-7.20.0-win64-ssl-sspi.zip和Win64OpenSSL_Light-1_0_2d.exe。 下载地址:
http://curl.haxx.se/download.html 请选择不带SSL的版本,否则还需要安装SSL的支持包 2. 可以给Windows增加c
- Creating a Shared Repository; Users Sharing The Repository
hongtoushizi
git
转载自:
http://www.gitguys.com/topics/creating-a-shared-repository-users-sharing-the-repository/ Commands discussed in this section:
git init –bare
git clone
git remote
git pull
git p
- Java实现字符串反转的8种或9种方法
Josh_Persistence
异或反转递归反转二分交换反转java字符串反转栈反转
注:对于第7种使用异或的方式来实现字符串的反转,如果不太看得明白的,可以参照另一篇博客:
http://josh-persistence.iteye.com/blog/2205768
/**
*
*/
package com.wsheng.aggregator.algorithm.string;
import java.util.Stack;
/**
- 代码实现任意容量倒水问题
home198979
PHP算法倒水
形象化设计模式实战 HELLO!架构 redis命令源码解析
倒水问题:有两个杯子,一个A升,一个B升,水有无限多,现要求利用这两杯子装C
- Druid datasource
zhb8015
druid
推荐大家使用数据库连接池 DruidDataSource. http://code.alibabatech.com/wiki/display/Druid/DruidDataSource DruidDataSource经过阿里巴巴数百个应用一年多生产环境运行验证,稳定可靠。 它最重要的特点是:监控、扩展和性能。 下载和Maven配置看这里: http
- 两种启动监听器ApplicationListener和ServletContextListener
spjich
javaspring框架
引言:有时候需要在项目初始化的时候进行一系列工作,比如初始化一个线程池,初始化配置文件,初始化缓存等等,这时候就需要用到启动监听器,下面分别介绍一下两种常用的项目启动监听器
ServletContextListener
特点: 依赖于sevlet容器,需要配置web.xml
使用方法:
public class StartListener implements
- JavaScript Rounding Methods of the Math object
何不笑
JavaScriptMath
The next group of methods has to do with rounding decimal values into integers. Three methods — Math.ceil(), Math.floor(), and Math.round() — handle rounding in differen
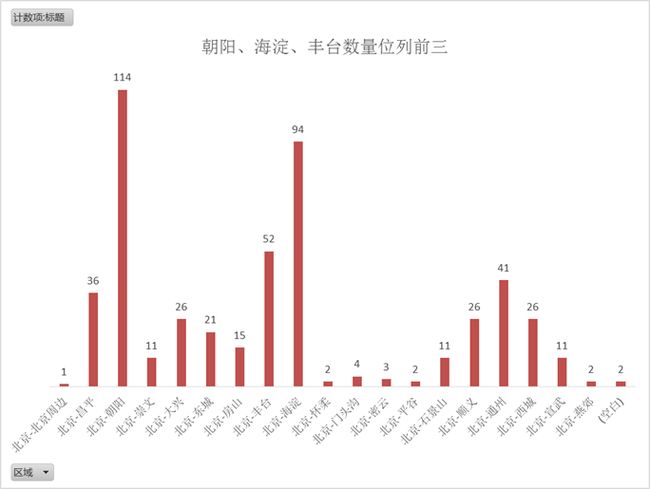 数量.png
数量.png 均价.png
均价.png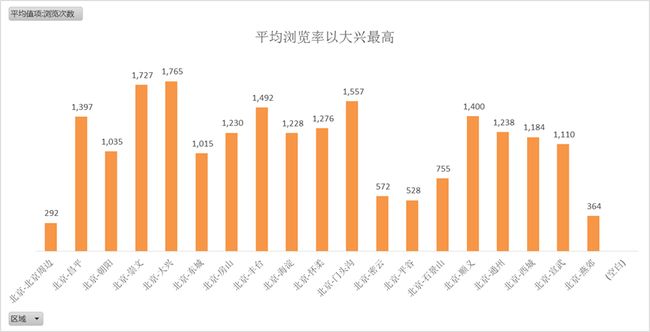 平均浏览率.png
平均浏览率.png