在目标检测领域,人脸检测和行人检测是应用最为广泛,小到各种美颜特效相机,大到车辆自动驾驶的目标识别。尤其最近深度学习一统天下,从 AlexNet 到 VGG,GoogleLeNet ,ResNet 等深度神经网络,其对于 General object 的识别准确率逐渐升高。CNN 等深度网络的坑先放着这,等有时间在把它填了。
这次主要用 HOG+SVM 的经典模型来实现行人检测(Pedestrian Detection),先来看看要实现的效果:
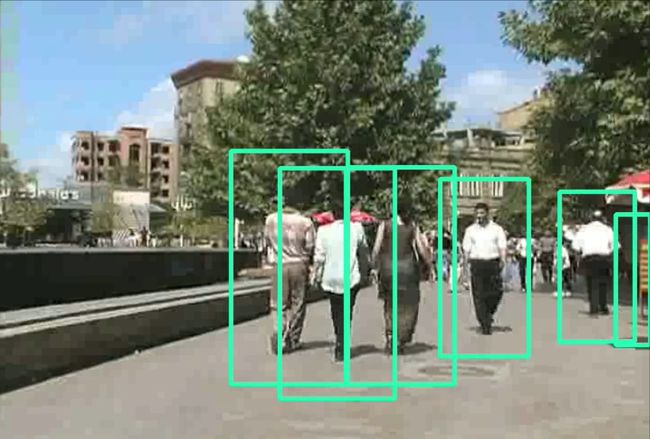
再来看看动图GIF效果:
1.HOG特征
特征是一个很关键的东西,我们要让计算机在一幅图像中识别物体时,一般做法是寻找包含该物体的特征,依据所获取的特征信息建立数学模型,然后依据模型的输出来判断是不是该物体。打个比方,如果把模型当成一个分类器,我们要做的就是提取图像的特征,然后把它输入分类器,如果输出值大于设定的阈值,比如说0.5,那么就判断这幅图是这个物体,小于0.5就不是。该分类器就是依据概率所建立的模型,像逻辑回归(logistic regression),支持向量机(support vector machine)等,都是这样的模型,它们能够完成这种二分类任务。
那么,什么是HOG特征呢,HOG即 Histogram of Oriented Gradient 梯度直方图,它反应了一幅图像所包含的梯度信息,梯度是图像像素值的变化快慢,对于图像可以理解为它的边缘信息。HOG 简单点说就是,计算图像梯度,按方向360°进行划分,然后统计其梯度信息形成梯度方向直方图。具体梯度计算可以参考Dalal在2005的CVPR发表的HOG+SVM的行人检测算法,很经典,但是读起来很难受。
2.SVM支持向量机
支持向量机可以说是机器学习里最有理论基础,有一套完整统计理论,对其Large Margin分类器有一个很好的数学解释,线性核和高斯核等核函数的应用使得SVM一统分类问题,直到后面深度神经网络的出现。我从Andrew NG的 Machine Learning课程中得到的intuition是,SVM 依据数据训练能形成一个超平面,每类最近的样本到其的距离是最大的,这也是为什么SVM被叫做最大间距分类器的原因,因而SVM具有比LR模型更好的分类准确率。
3.目标检测的实现
图像的目标检测有几个需要注意的点:
-
Sliding Window
有了前面的SVM分类器我们就可以开始进行检测了,但实际操作时,我们是采用一个滑动窗口的方式来检测,因为一幅图像中不知道目标在哪,所以我们用一个窗口按一定的步长来滑动,绿色的窗口滑动整幅图像来判断行人位置。
 2.png
2.png Image pyramid
由于图像里的目标大小和分类的用来训练的大小存在区别,那么就得对图像进行缩放scale,不同的缩放比例就形成了一个图像金字塔。视频流的检测
一段视频就可以看成是每一帧图像连贯的显示出来而形成的,那么对视频的每一帧画面进行检测就可以实现视频流的检测了。我这是简单粗暴的方式,后期可以用MOG前景物体识别,识别出画面中移动的物体,在将移动的物体放到SVM里检测,可以省略滑动窗口的大量计算时间,此外还可以利用帧差信息对目标进行追踪,那就是另外一个问题了,这里就不说了。
4.Opencv实现
Opencv 里读入一段视频可以用
#创建读取视频实例
cap=cv2.VideoCapture(r'G:\影视剧\clip.mkv')
ret,frame=cap.read()
cap.read()返回视频的当前帧画面frame,然后对这帧画面frame进行人脸或行人检测,再写入到一个新视频流中。
#-*-coding:UTF-8-*-
# import the necessary packages
from imutils.object_detection import non_max_suppression
import numpy as np
import imutils
import cv2
def Draw_body(img_name):
# convert the image into gray
gray=cv2.cvtColor(img_name,cv2.COLOR_BGR2GRAY)
# initialize the detector
hog=cv2.HOGDescriptor()
hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector())
# detect people in img
peoples,weights=hog.detectMultiScale(gray,winStride=(1,1),padding=(8,8),scale=1.05)
# apply non-max suppresion to the bounding boxes
peoples=np.array([[x,y,x+w,y+h] for (x,y,w,h) in peoples])
pick=non_max_suppression(peoples,probs=None,overlapThresh=0.65)
# draw the final bounding boxes
for (xa,ya,xb,yb) in pick:
cv2.rectangle(img_name,(xa,ya),(xb,yb),(180,255,45),3)
def Faces_Detect(img):
# convert image
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# detect faces
faces = faces_cascade.detectMultiScale(img, 1.3, 5)
result = []
for (x, y, width, height) in faces:
result.append((x, y, x + width, y + height))
return result
# Draw faces
def Draw_Faces(img):
faces = Faces_Detect(img)
if faces:
for (x1, y1, x2, y2) in faces:
cv2.rectangle(img, (x1, y1), (x2, y2), (255, 255, 0), 2)
#Test
if __name__=='__main__':
# 创建读取视频实例
cap=cv2.VideoCapture("E:\FFOutput\schoolpeople.mp4")
# 获取视频编码格式,帧率FPS,Size
fourcc=cv2.VideoWriter_fourcc(*'XVID')
out=cv2.VideoWriter('C:\\Users\Administrator\Desktop\demo1.avi',fourcc,30,(856,480))
while cap.isOpened():
# 读取每一帧
ret,frame=cap.read()
if ret==True:
Draw_body(frame)#检测行人
#Draw_Faces(frame)#检测人脸
out.write(frame)#写入
else:
break
cap.release()
检测效果如文章开头所示
我们再来看看人脸的检测效果动图:
人脸效果也还不错!Job down!
