姓名:李嘉蔚学号:16020520034
【嵌牛导读】:你们这些科学家在干什么!怎么教会AI打群架啦!
成百上千的AI agent,分成两支AI大军对战起来。从动图中还可以看出来,它们的战斗方式并不是简单的平A,包围、游击等等高级战术在这三场AI战役中悉数登场。
战役发生的地点,是上海交大中英联合AI研究小组Geek.ai最新发布的强化学习平台:MAgent。
【嵌牛鼻子】:强化学习平台:MAgent。量子位。AI的集体智慧。
【嵌牛提问】:什么是MAgent.什么是AI的集体智慧?
【嵌牛正文】:
夏乙 若朴 发自 凹非寺
量子位 出品 | 公众号 QbitAI
强化学习平台不少,MAgent是一个异类。OpenAI Gym、微软Malmo等等前辈几经改进,却都只能训练一个或者几个智能体,就算它们强调“multi-agent”,最多也不过支持几十个而已。
而在MAgent平台上,可以训练比更多还更多的agent,支持的量级可达到从数百到数百万。开发团队称之为“many-agent”。
量子位暂时按捺住把它翻译成“智能体大军”的冲动,在本文中就叫“群智能体”吧。
把这么多agent放在一起,要研究什么呢?我们先来看一段视频:
搭配BGM看小方块跑来跑去,莫名的燃~
Geek.ai团队说,把成百上万的agent聚集在一个环境中,是为了研究Artificial Collective Intelligence(ACI),也就是AI如何群策群力,创造集体智慧。ACI的研究虽然还很初步,但已经在股票交易、策略博弈、城市交通优化等等领域有所应用。
AI的集体智慧
成群的AI聚在一起形成了一个小社会,出现交流、竞争、合作等社会现象,里面的agent个体也会有种种社会行为。
展示了基于MAgent设计的三个群智能体环境:追逐(Pursuit)、采集(Gathering)和战斗(Battle),大致相当于人类老祖宗们常做的三件事:一起打猎、出去摘果子、和另一拨老祖宗打架。
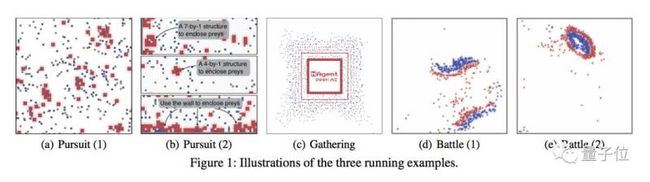
追逐
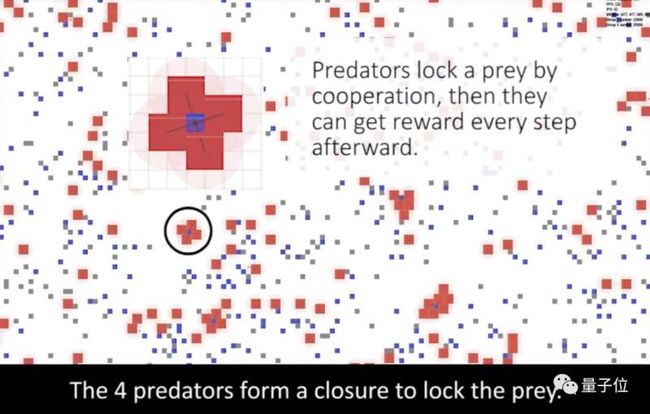
在追逐环境中,红色智能体代表捕食者、蓝色表示猎物、灰色的是墙。捕食者包围、锁定猎物,接下来就能在攻击时就能得到奖励,而猎物被攻击会受到惩罚。
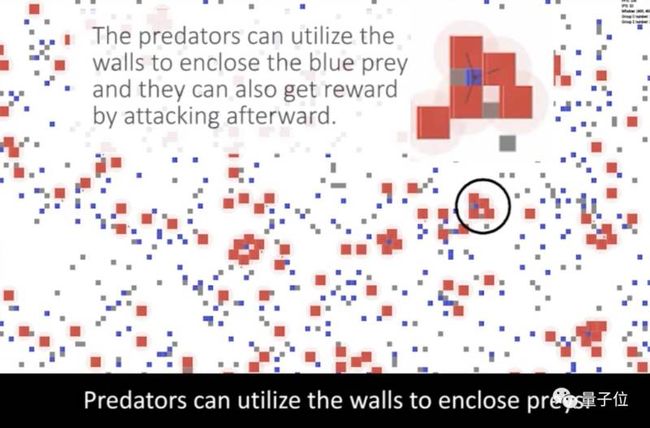
我们可以看到局部合作行为的出现。经过训练,四个捕食者会合作包围一个猎物,还会在包围猎物时利用墙壁作为辅助。
采集
在采集环境中,红色方块是食物,蓝色的是agent,agent可以互相攻击,吃到(采集到)食物就会获得奖励。有两个选择摆在他们面前:是直接去吃掉食物,还是杀死竞争者独占食物。
于是,竞争出现了。

经过训练,agent在一开始时会选择直接冲过去吃掉食物,如果两个agent相遇,就会尝试杀死对方、独占食物、获得奖励。食物越少,agent越好斗。
战斗
战斗环境,就是我们在文章最开头看到的AI打群架啦。
这其中既有合作又有竞争,红色和蓝色agent分别组成两支军队,杀死对手就能获得奖励,被杀死就会被惩罚。也就是说,agent在这个环境中的任务,是和队友合作去消灭敌军。
这些agent通过简单的自我对局训练,学会了全局和局部策略,包括包围、游击等等。
MAgent详情
在MAgent平台上,每个agent都是一个小方块,带有详细的局部信息,有些还带有全局信息。agent可以移动、旋转、攻击。
它们背后有一个C++引擎,支持多样化的agent,通过简单设置状态空间、行为空间和agent的属性,可以创造出多样的环境。
为了让用户灵活地设计环境,MAgent还提供一种用来描述奖励、agent标志、事件的语言,还支持“与/或/非”逻辑运算。
另外,MAgent还提供一个简单的图形化渲染器,对环境和agent的当前状态进行交互式展示,用户可以拖动、缩放窗口,甚至可以操纵游戏中的agent。
更多详情,可以看看MAgent的论文,或者把代码拿来上手试一试。
论文(将在AAAI-18 Demonstrations Program上展示):
MAgent: A Many-Agent Reinforcement Learning Platform for Artificial Collective Intelligence
Lianmin Zheng, Jiacheng Yang, Han Cai, Weinan Zhang, Jun Wang, Yong Yu
http://cn.arxiv.org/abs/1712.00600
代码:
https://github.com/geek-ai/MAgent
背后的Geek(们)
这篇论文的共同第一作者,是上海交大的郑怜悯(Lianmin Zheng)和杨嘉成(Jiacheng Yang)。