基于Volta MPS执行资源配置下的多容器共享GPU性能测试
基于Volta MPS执行资源配置下的多容器共享GPU性能测试
终于有机会再V100上做实验啦,接上篇博客《你真得了解多个docker容器如何共享GPU么?》,继续在GPU共享的道路上徘徊摸索。。。
一、实验背景
一般而言,多容器共享GPU会引发资源竞争和浪费的问题,不仅GPU利用率不高,也无法保证QoS。当使用NVIDIA MPS时,MPS Sever会通过一个CUDA Context管理GPU硬件资源,多个MPS Clients会将它们的任务通过MPS Server传入GPU,从而越过了硬件时间分片调度的限制,使得它们的CUDA kernels实现真正意义上的并行。特别地,Volta MPS可以兼容docker容器,并且支持执行资源配置(即每个Client context只能获取一定比例的threads),提高了多容器共享GPU的QoS。
二、实验目的
通过实验主要回答以下三方面问题:
- 开启/关闭MPS对多容器共享GPU的性能影响如何?
- Volta MPS的执行资源配置效果如何?
- 多容器共享GPU的公平性如何?
三、实验环境
系统:Ubuntu 18.04.1 LTS
内核:4.15.0-43-generic
显卡:Tesla V100-PCIE-16GB
软件:CUDA 10.0, NVIDIA-DOCKER 2.0, DOCKER 1.39, NVIDIA Drivers 410.48, gcc 7.3.0
四、实验步骤
- 开启与关闭MPS
第一部分,我们主要研究开启和关闭MPS对GPU性能的影响。默认情况下,GPU是没有开启MPS的,每个CUDA程序会创建自己的CUDA Context来管理GPU资源,并以时间分片的方式共享GPU。开启MPS后,在需要的时候,MPS control daemon会启动一个MPS Server,监听任务请求。
开启MPS的方式如下(以第1块GPU为例):
| root@amax-2:~# export CUDA_VISIBLE_DEVICES=0 root@amax-2:~# nvidia-smi -i 0 -c EXCLUSIVE_PROCESS root@amax-2:~# nvidia-cuda-mps-control -d |
关闭MPS的方式如下:
| root@amax-2:~# echo quit | nvidia-cuda-mps-control root@amax-2:~# nvidia-smi -i 0 -c DEFAULT |
注意以上两个命令需要管理员权限。
下面,我们来研究不同计算负载下[1],开启与关闭MPS对多容器共享GPU的性能有多大提升?

图 1:MPS与GPU性能的关系
如图1所示,多容器共享GPU可以从MPS中受益。开启MPS后,单个任务的完成时间相对于未开启MPS有了较大的缩减。同时提交5个任务和10个任务,时间分别减少了21.2%和18.6%。
同时,我们利用nvidia-smi命令获取了GPU的运行状态。具体命令如下:
| root@amax-2:~# nvidia-smi stats -d gpuUtil,memUtil -i 0 |
为了不失一般性,我们选择了低、中、高三种计算负载的任务,并绘制了GPU利用率[2]和显存利用率[3]随时间变化的曲线,如下图2所示。

图2:GPU利用率
从图2可以看出,随着任务的增多GPU的利用率(内核活动时间的百分比)也随之增高,表现为从左到右曲线峰值变高,从上到下曲线峰值持续时间变长。对于同时提交5和10个低负载任务,开启MPS的GPU利用率竟然没有未开启MPS的高,这似乎与常识相悖。但可以这样理解,在单个任务未能完全利用GPU所有计算资源的情况下,开启MPS,多个任务可以在同一时刻共享GPU,而不是通过时间切片的调度方式共享GPU。所以,GPU就会表现得“更闲”。注意,nvidia-smi命令提供的GPU利用率与SMs活跃的数量和代码的繁忙程度无关。
MPS提供了每一时刻GPU限制内核资源的“再利用”,因此当任务数目越多,任务负载越高,MPS所能起到的作用就会变小,这就可以解释在开启MPS的情况下同时提交10个任务的GPU性能提升幅度比5个任务的要低的原因。
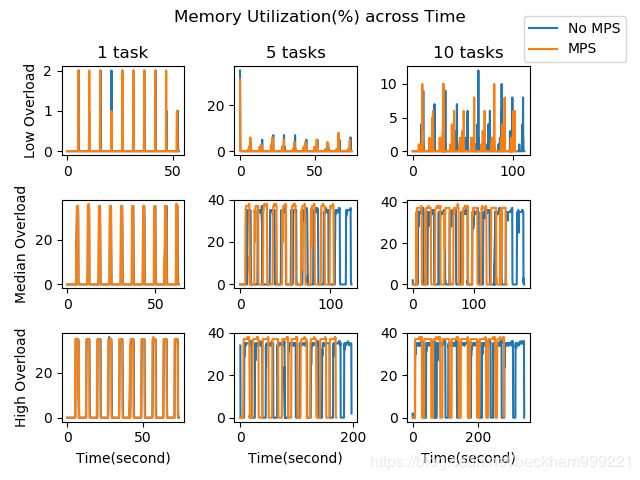
图3:显存利用率
同样,对于低负载任务,开启MPS的显存利用率要比未开启MPS的要低,因为MPS使得同一时刻可以完成更多的完成的显存读写操作。
另外,对于中、高负载任务,当同时提交的任务数目从5增加到10,显存利用率并没有提高,主要因为GPU内核已经满负荷,单位时间读写显存的次数达到了最高,这与任务数无关。
- Volta MPS执行资源配置
第二部分,我们研究Volta MPS执行资源配置。该功能旨在实现两个目标:一是减少Client内存指纹(memory footprint),二是提高共享GPU的QoS。
执行资源配置的方法如下:
| root@amax-2:~# nvidia-cuda-mps-control set_default_active_thread_percentage 10 |
上述命令展示如何为每个MPS Client限制10%的threads。但这不意味着为每个Client预留专用资源,而是限制它们可以最多使用多少threads。默认情况下,每个Client可以获取所有threads(即100%)。
我们对比了分配不同比例threads对GPU性能的影响,如下图:

图4:MPS执行资源配置对GPU性能的影响
如图4所示,同时向GPU提交5个任务(低、中、高负载),每个任务平均完成时间随着threads配置的百分比的变化而变化。对于低、中、高负载,任务完成时间分别在threads配置为20%、80%和10%达到最低。由于低负载任务占用GPU资源很少,为每个任务分配适当的threads可以保证相互不会影响。中负载任务占用GPU资源较多,尽量分配较多的threads可以提高吞吐率。当任务负载达到一定程度时,最好降低每个任务的threads,避免过度资源竞争。MPS对低负载任务性能提升的效果不明显,可能是由于Server的调度时间占主要因素。
另外,我们还测试了大任务独占显存的实验,虽然执行资源配置对threads分配进行了限制,但无法对任务所占显存容量进行限制,依然存在大任务独占整块GPU显存的可能。
- MPS公平性
第三部分,我们研究多任务共享GPU的公平性问题。关闭MPS,多任务通过时间分片的调度方式共享GPU;开启MPS,多任务共享Server的CUDA Context。无论哪种情况,在所有任务所占显存总容量不超出GPU容量时,每个任务都能公平地获得GPU的threads。

图5-1:开启MPS多任务共享GPU性能分析
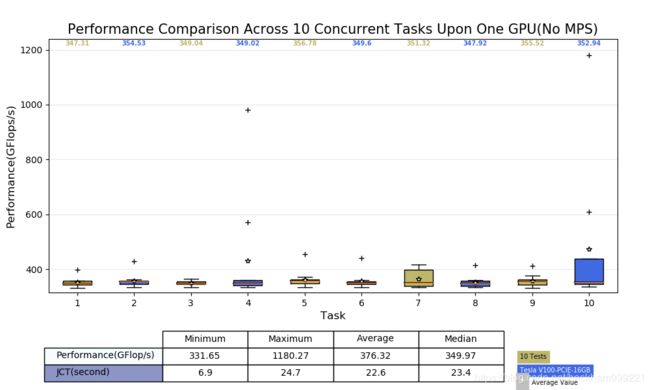
图5-2:关闭MPS多任务共享GPU性能分析
如图5 所示,同时向GPU提交10个高负载任务,重复10次实验,每个任务的平均完成时间无明显差异,说明GPU资源调度是公平的。
五、实验结论
- 开启MPS对GPU性能提升有较大帮助,在不同计算负载的情况下,同时提交5个和10个任务,每个任务平均完成时间分别缩少21.2%和18.6%。
- Volta MPS支持执行资源配置,可以对每个容器占有的GPU资源(准确来说指threads)进行限制。一个较好配置策略是将整个GPU threads份额除以预期Client的一半(例如,100%/0.5n)。但是,实验表明显存容量限制并不被支持。
- 开启MPS,多个任务提交到GPU,显存占满的情况下,可以公平共享整个GPU资源(准确来说是threads)。
[1] 实验中采用的矩阵大小相同,但乘法的循环次数不同,从而造成任务的计算负载不同。
[2] 单位时间内GPU内核活动时间的百分比,并非代码的繁忙程度或使用了多少SMs。
[3] 单位时间内显存被读写时间的百分比。