pytorch 损失函数总结
PyTorch深度学习实战
4 损失函数
损失函数,又叫目标函数,是编译一个神经网络模型必须的两个参数之一。另一个必不可少的参数是优化器。
损失函数是指用于计算标签值和预测值之间差异的函数,在机器学习过程中,有多种损失函数可供选择,典型的有距离向量,绝对值向量等。
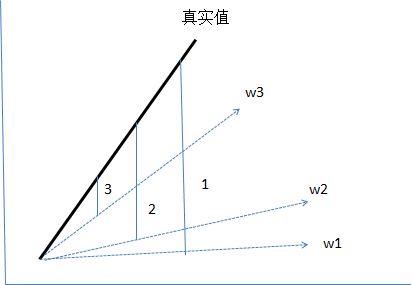
上图是一个用来模拟线性方程自动学习的示意图。粗线是真实的线性方程,虚线是迭代过程的示意,w1 是第一次迭代的权重,w2 是第二次迭代的权重,w3 是第三次迭代的权重。随着迭代次数的增加,我们的目标是使得 wn 无限接近真实值。
那么怎么让 w 无限接近真实值呢?其实这就是损失函数和优化器的作用了。图中 1/2/3 这三个标签分别是 3 次迭代过程中预测 Y 值和真实 Y 值之间的差值(这里差值就是损失函数的意思了,当然了,实际应用中存在多种差值计算的公式),这里的差值示意图上是用绝对差来表示的,那么在多维空间时还有平方差,均方差等多种不同的距离计算公式,也就是损失函数了,这么一说是不是容易理解了呢?
这里示意的是一维度方程的情况,那么发挥一下想象力,扩展到多维度,是不是就是深度学习的本质了?
下面介绍几种常见的损失函数的计算方法,pytorch 中定义了很多类型的预定义损失函数,需要用到的时候再学习其公式也不迟。
我们先定义两个二维数组,然后用不同的损失函数计算其损失值。
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
sample = Variable(torch.ones(2,2))
a=torch.Tensor(2,2)
a[0,0]=0
a[0,1]=1
a[1,0]=2
a[1,1]=3
target = Variable (a)
sample 的值为:[[1,1],[1,1]]。
target 的值为:[[0,1],[2,3]]。
4.1 nn.L1Loss
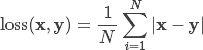
L1Loss 计算方法很简单,取预测值和真实值的绝对误差的平均数即可。
criterion = nn.L1Loss()
loss = criterion(sample, target)
print(loss)
最后结果是:1。
它的计算逻辑是这样的:
先计算绝对差总和:|0-1|+|1-1|+|2-1|+|3-1|=4;
然后再平均:4/4=1。
4.2 nn.SmoothL1Loss
SmoothL1Loss 也叫作 Huber Loss,误差在 (-1,1) 上是平方损失,其他情况是 L1 损失。
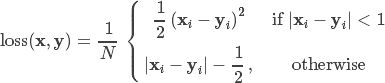
criterion = nn.SmoothL1Loss()
loss = criterion(sample, target)
print(loss)
最后结果是:0.625。
4.3 nn.MSELoss
平方损失函数。其计算公式是预测值和真实值之间的平方和的平均数。
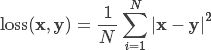
criterion = nn.MSELoss()
loss = criterion(sample, target)
print(loss)
最后结果是:1.5。
4.4 nn.BCELoss
二分类用的交叉熵,其计算公式较复杂,这里主要是有个概念即可,一般情况下不会用到。
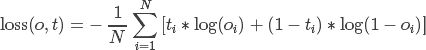
criterion = nn.BCELoss()
loss = criterion(sample, target)
print(loss)
最后结果是:-13.8155。
4.5 nn.CrossEntropyLoss
交叉熵损失函数
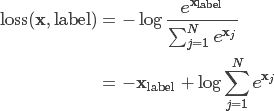
该公式用的也较多,比如在图像分类神经网络模型中就常常用到该公式。
criterion = nn.CrossEntropyLoss()
loss = criterion(sample, target)
print(loss)
最后结果是:报错,看来不能直接这么用!
看文档我们知道 nn.CrossEntropyLoss 损失函数是用于图像识别验证的,对输入参数有各式要求,这里有这个概念就可以了,在图像识别一文中会有正确的使用方法。
4.6 nn.NLLLoss
负对数似然损失函数(Negative Log Likelihood)
![]()
在前面接上一个 LogSoftMax 层就等价于交叉熵损失了。注意这里的 xlabel 和上个交叉熵损失里的不一样,这里是经过 log 运算后的数值。这个损失函数一般也是用在图像识别模型上。
criterion = F.nll_loss()
loss = criterion(sample, target)
print(loss)
loss=F.nll_loss(sample,target)
最后结果是:报错,看来不能直接这么用!
Nn.NLLLoss 和 nn.CrossEntropyLoss 的功能是非常相似的!通常都是用在多分类模型中,实际应用中我们一般用 NLLLoss 比较多。
4.7 nn.NLLLoss2d
和上面类似,但是多了几个维度,一般用在图片上。
-
input, (N, C, H, W)
-
target, (N, H, W)
比如用全卷积网络做分类时,最后图片的每个点都会预测一个类别标签。
criterion = nn.NLLLoss2d()
loss = criterion(sample, target)
print(loss)
最后结果是:报错,看来不能直接这么用!