PyTorch: RNN实战详解之分类名字
版权声明:博客文章都是作者辛苦整理的,转载请注明出处,谢谢! http://blog.csdn.net/m0_37306360/article/details/79316013
本文从数据集到最终模型训练过程详细讲解RNN,教程来自于作者Sean Robertson写的教程,我根据原始文档,一步一步跑通了代码,下面是我的学习笔记。
任务描述
从机器学习的角度来说,这是个分类任务。具体来说,我们将从18种语言的原始语言中训练几千个名字,并根据测试集的名字来预测这个名字来自哪一种语言。数据集下载地址:https://download.pytorch.org/tutorial/data.zip
里面包含18个名为“[Language] .txt”的文本文件。每个文件包含很多名字数据集,每行一个名字。每个文件所包含的名字来自一种语言(比如中文、英文),所以数据集包含的18种语言代表18类。训练的样本是(名字,语言),当模型训练后,输入名字,预测此名字属于哪一类(属于那种语言)。
PyTorch之RNN实战分类
本文采用PyTorch框架使用RNN进行数据分类。
数据预处理
首先解决编码问题以及将类别放入python list。然后类别对应的名字以字典类型读入,方面后面模型训练使用。
from io import open
import glob
import unicodedata
import string
def findFiles(path):
return glob.glob(path)
# 所有的英文字母加上五个标点符号" .,;'"。一个57个字符
all_letters = string.ascii_letters + " .,;'"
n_letters = len(all_letters)
# Turn a Unicode string to plain ASCII, thanks to http://stackoverflow.com/a/518232/2809427
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
and c in all_letters
)
#print(unicodeToAscii('Ślusàrski'))
# Build the category_lines dictionary, a list of names per language
category_lines = {}
all_categories = []
# Read a file and split into lines
def readLines(filename):
lines = open(filename, encoding='utf-8').read().strip().split('\n')
return [unicodeToAscii(line) for line in lines]
for filename in findFiles('nlpdata/data/names/*.txt'):
category = filename.split('/')[-1].split('.')[0]
category = category.split('\\')[1]
# 18种类别
all_categories.append(category)
lines = readLines(filename)
# category_lines:字典类型(类别: 名字list)
category_lines[category] = lines
n_categories = len(all_categories)
print("all_letters: "+str(len(all_letters)))
print("n_categories: "+str(n_categories))
print("category_lines:"+str(category_lines['Italian'][:5]))
输出结果:
all_letters: 57
n_categories: 18
category_lines:['Abandonato', 'Abatangelo', 'Abatantuono', 'Abate', 'Abategiovanni']
Process finished with exit code 0在PyTorch中,我们需要将名字数据转换成Tensor才能在模型中读入使用。在本文中,最小粒度为字符,意思是我们将名字里面的每个字符都作为一个独立的语言粒度来处理,为了数学化字符,我们这里使用”one-hot vector”来表示,这里每个字符被表示成<1 * 57>的向量。由于名字由多个字符组成,所以每个名字就被表示成了2D的矩阵<名字字符个数 * 1 * 57>。
import torch
# Find letter index from all_letters, e.g. "a" = 0
# 字母所在位置
def letterToIndex(letter):
return all_letters.find(letter)
# Turn a letter into a <1 x n_letters> Tensor (one-hot vector)
def letterToTensor(letter):
tensor = torch.zeros(1, n_letters)
# One-hot encoding
tensor[0][letterToIndex(letter)] = 1
return tensor
# Turn a line into a ,
# or an array of one-hot letter vectors
def lineToTensor(line):
tensor = torch.zeros(len(line), 1, n_letters)
for li, letter in enumerate(line):
tensor[li][0][letterToIndex(letter)] = 1
return tensor
print(letterToTensor('J'))
print(lineToTensor('Jones').size())
输出结果:
Columns 0 to 12
0 0 0 0 0 0 0 0 0 0 0 0 0
Columns 13 to 25
0 0 0 0 0 0 0 0 0 0 0 0 0
Columns 26 to 38
0 0 0 0 0 0 0 0 0 1 0 0 0
Columns 39 to 51
0 0 0 0 0 0 0 0 0 0 0 0 0
Columns 52 to 56
0 0 0 0 0
[torch.FloatTensor of size 1x57]
torch.Size([5, 1, 57])
Process finished with exit code 0
定义网络模型
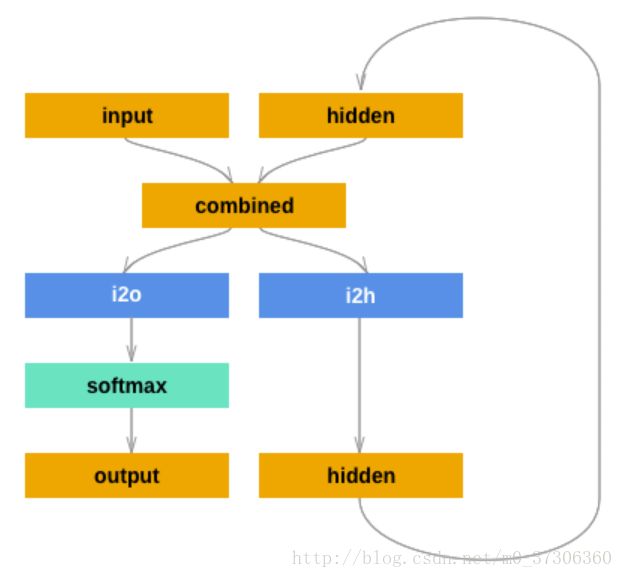
为了运行这个网络的一个步(step),我们需要传入输入(在我们的例子中,当前字母的张量)和一个先前的隐藏状态(初始化为零)。 我们将返回输出(每种语言的概率)和下一个隐藏状态(我们为下一步保留)。
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(input_size + hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
combined = torch.cat((input, hidden), 1)
hidden = self.i2h(combined)
output = self.i2o(combined)
output = self.softmax(output)
return output, hidden
# 初始化第一个隐藏层输入
def initHidden(self):
return Variable(torch.zeros(1, self.hidden_size))训练网络
训练过程如下:
1.创建输入和目标张量
2.创建一个初始隐藏状态(0初始化)
3.输入该步字母然后保持该步的隐藏状态,将此隐藏状态和下一步的字母输入一起组成下一步输出
4.比较最终输出结果和标记目标(类)
5.反向传播(并且更新参数)
6.返回输出和损失
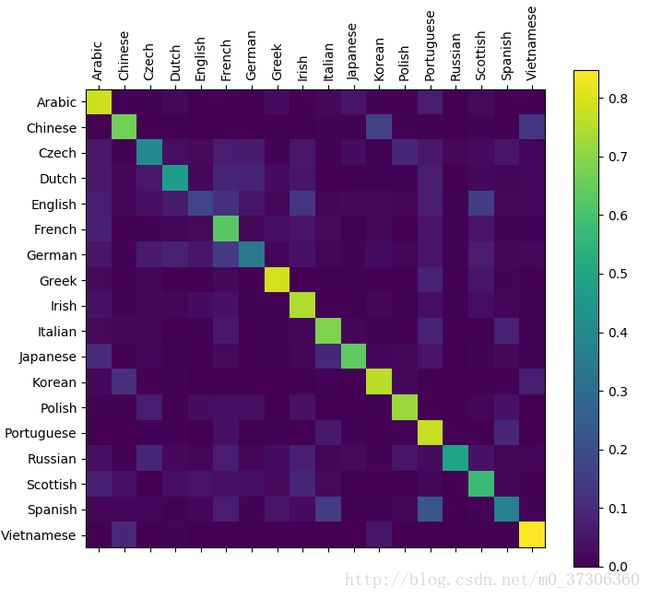
为了看网络在不同类别上的表现如何,我们创建一个混淆矩阵。
完整代码
from io import open
import glob
def findFiles(path):
return glob.glob(path)
#print(findFiles('nlpdata/data/names/*.txt'))
import unicodedata
import string
# 所有的英文字母
all_letters = string.ascii_letters + " .,;'"
n_letters = len(all_letters)
# Turn a Unicode string to plain ASCII, thanks to http://stackoverflow.com/a/518232/2809427
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
and c in all_letters
)
#print(unicodeToAscii('Ślusàrski'))
# Build the category_lines dictionary, a list of names per language
category_lines = {}
all_categories = []
# Read a file and split into lines
def readLines(filename):
lines = open(filename, encoding='utf-8').read().strip().split('\n')
return [unicodeToAscii(line) for line in lines]
for filename in findFiles('nlpdata/data/names/*.txt'):
category = filename.split('/')[-1].split('.')[0]
category = category.split('\\')[1]
all_categories.append(category)
lines = readLines(filename)
category_lines[category] = lines
n_categories = len(all_categories)
import torch
# Find letter index from all_letters, e.g. "a" = 0
# 字母所在位置
def letterToIndex(letter):
return all_letters.find(letter)
# Just for demonstration, turn a letter into a <1 x n_letters> Tensor
def letterToTensor(letter):
tensor = torch.zeros(1, n_letters)
# One-hot encoding
tensor[0][letterToIndex(letter)] = 1
return tensor
# Turn a line into a ,
# or an array of one-hot letter vectors
def lineToTensor(line):
tensor = torch.zeros(len(line), 1, n_letters)
#print(tensor)
for li, letter in enumerate(line):
tensor[li][0][letterToIndex(letter)] = 1
return tensor
import torch.nn as nn
from torch.autograd import Variable
# Creating the network
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(input_size + hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
combined = torch.cat((input, hidden), 1)
hidden = self.i2h(combined)
output = self.i2o(combined)
output = self.softmax(output)
return output, hidden
# 初始化第一个隐藏层输入
def initHidden(self):
return Variable(torch.zeros(1, self.hidden_size))
# our model
n_hidden = 128
rnn = RNN(n_letters, n_hidden, n_categories)
# 类别
def categoryFromOutput(output):
top_n, top_i = output.data.topk(1) # Tensor out of Variable with .data
category_i = top_i[0][0]
return all_categories[category_i], category_i
# loss function
criterion = nn.NLLLoss()
# Train loop
learning_rate = 0.005 # If you set this too high, it might explode. If too low, it might not learn
def train(category_tensor, line_tensor):
hidden = rnn.initHidden()
rnn.zero_grad()
for i in range(line_tensor.size()[0]):
output, hidden = rnn(line_tensor[i], hidden)
loss = criterion(output, category_tensor)
loss.backward()
# Add parameters' gradients to their values, multiplied by learning rate
for p in rnn.parameters():
p.data.add_(-learning_rate, p.grad.data)
return output, loss.data[0]
# 随机采样训练样本对
import random
def randomChoice(l):
return l[random.randint(0, len(l) - 1)]
def randomTrainingExample():
category = randomChoice(all_categories)
line = randomChoice(category_lines[category])
category_tensor = Variable(torch.LongTensor([all_categories.index(category)]))
line_tensor = Variable(lineToTensor(line))
return category, line, category_tensor, line_tensor
import time
import math
n_iters = 100000
print_every = 5000
plot_every = 1000
# Keep track of losses for plotting
current_loss = 0
all_losses = []
def timeSince(since):
now = time.time()
s = now - since
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)
start = time.time()
for iter in range(1, n_iters + 1):
category, line, category_tensor, line_tensor = randomTrainingExample()
output, loss = train(category_tensor, line_tensor)
current_loss += loss
# Print iter number, loss, name and guess
if iter % print_every == 0:
guess, guess_i = categoryFromOutput(output)
correct = '✓' if guess == category else '✗ (%s)' % category
print('%d %d%% (%s) %.4f %s / %s %s' % (iter, iter / n_iters * 100, timeSince(start), loss, line, guess, correct))
# Add current loss avg to list of losses
if iter % plot_every == 0:
all_losses.append(current_loss / plot_every)
current_loss = 0
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
plt.figure()
plt.plot(all_losses)
plt.show()
# 矩阵
confusion = torch.zeros(n_categories, n_categories)
n_confusion = 10000
# Just return an output given a line
def evaluate(line_tensor):
hidden = rnn.initHidden()
for i in range(line_tensor.size()[0]):
output, hidden = rnn(line_tensor[i], hidden)
return output
# Go through a bunch of examples and record which are correctly guessed
for i in range(n_confusion):
category, line, category_tensor, line_tensor = randomTrainingExample()
output = evaluate(line_tensor)
guess, guess_i = categoryFromOutput(output)
category_i = all_categories.index(category)
confusion[category_i][guess_i] += 1
# Normalize by dividing every row by its sum
for i in range(n_categories):
confusion[i] = confusion[i] / confusion[i].sum()
# Set up plot
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(confusion.numpy())
fig.colorbar(cax)
# Set up axes
ax.set_xticklabels([''] + all_categories, rotation=90)
ax.set_yticklabels([''] + all_categories)
# Force label at every tick
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
# sphinx_gallery_thumbnail_number = 2
plt.show()
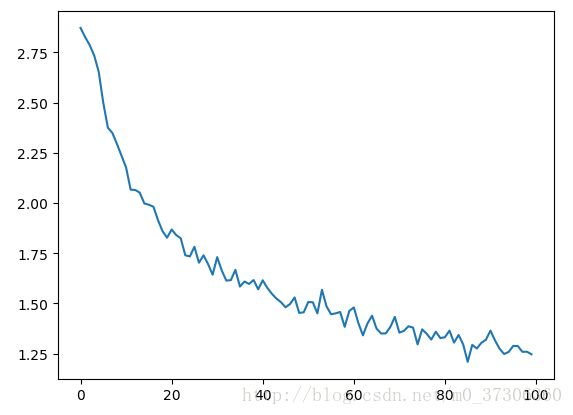
每训练1000次输出loss:
网络在不同类别上的表现:
注意:PyTorch模块对Variables 进行操作,而不是直接对Tensors进行操作。所以转换成Tensors后要用Variables封装。
例一:
input = Variable(letterToTensor('A'))
hidden = Variable(torch.zeros(1, n_hidden))
output, next_hidden = rnn(input, hidden)
例二:
input = Variable(lineToTensor('Albert'))
hidden = Variable(torch.zeros(1, n_hidden))
output, next_hidden = rnn(input[0], hidden)参考:http://pytorch.org/tutorials/intermediate/char_rnn_classification_tutorial.html