All you need is attention(Tranformer) --学习笔记
1、回顾
传统的序列到序列的机器翻译大都利用RNN或CNN来作为encoder-decoder的模型基础。实际上传统机器翻译基于RNN和CNN进行构建模型时,最关键一步就是如何编码这些句子的序列。往往第一步是先将句子进行分词,然后每个词转化为对应的词向量,那么每个句子都可以由这些词向量来构造对应的句子的序列表示向量。
(1)RNN递归进行:
不管是LSTM、GRU还是SRU,缺点是无法并行计算,速度慢,并且RNN无法特别好地学习到全局的信息,仍然无法彻底解决长距离依赖问题。
(2)CNN卷积:
窗口式遍历,比如卷积核大小为3,那么它的窗口就是3,可以捕获:
诸如其他卷积也一样可以捕获到相对应核大小的窗口信息,还有一种空洞卷积可以使跨度增大但有间隔的方式去捕获更多的全局信息。并且CNN方便并行。
2、Transformer
纯注意力机制可以一步到位可以获得全局信息,具体方案:
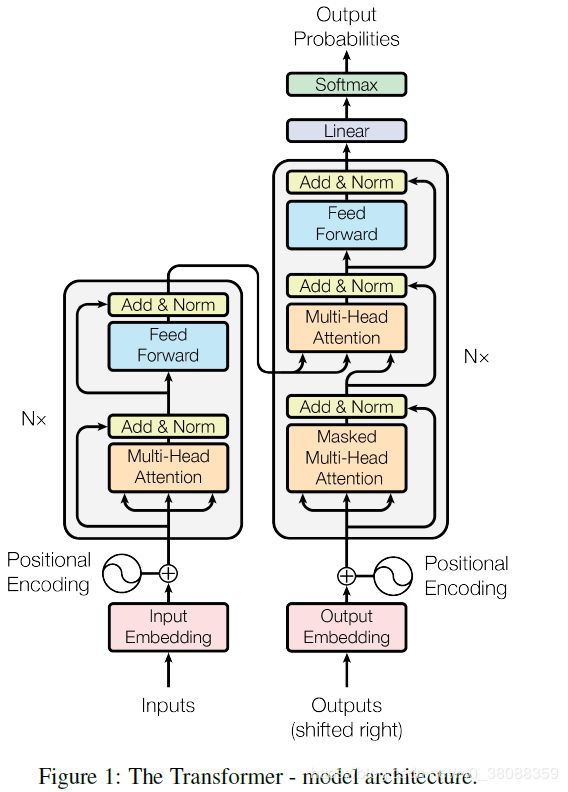
上图结构在原论文中是如下复述的:
Encoder: 编码器由6个相同的层堆叠在一起,每一层又有两个支层。第一个支层是一个多头的内部注意机制,第二个支层是一个简单的全连接前馈网络。在两个支层外面都添加了一个residual的连接,然后进行了layer nomalization的操作。模型所有的支层以及embedding层的输出维度都是dmodel = 512.
备注:
剩余(residual)连接等同于“跳过连接”。它们被用来允许梯度通过网络直接流动,而不通过非线性激活函数。非线性激活函数,本质上是非线性的,导致梯度爆炸或消失(取决于权重)。
跳过连接从概念上形成了一个“总线”,它沿着网络向右流动,反过来,梯度也可以沿着它向后流动。
每个网络层的“块”,如conv层、poolings等,在总线上的某个点上使用值,然后在总线上添加/减去值。这意味着块确实会影响梯度,反过来也会影响正向输出值。
现在,用一个直接连接替换其中一个块。如果你喜欢,可以用一个标识块替换,或者根本就没有。这是一个剩余/跳过连接。实际上,剩余的conv单元可能是两个系列单元,中间有一个激活层。
Decoder: 模型的解码器也是堆叠了六个相同的层。不过每层除了编码器中那两个支层,解码器还加入了第三个支层,如图中所示同样也用了residual以及layer normalization。
3、Attention层
Attention层分成了一下两种形式:
(1)Multi-Head Attention
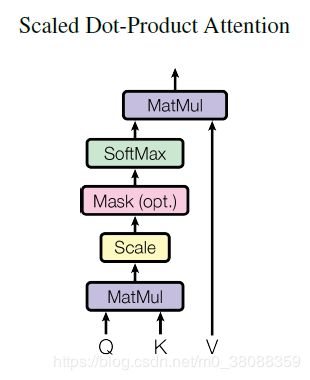
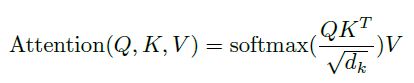
Q的维度为ndk,K的维度为mdk,V的维度为mdv。如果忽略softmax,三个矩阵相乘的结果就是一个ndv矩阵。d为每个词向量的维度,n为词的个数。
不计softmax,实际上计算得到的是n×dk,dk×m,m×dv三个矩阵相乘的结果,一个n*dv的矩阵。
在这里可以理解为将ndk的序列Q编码成了一个新ndv序列。
接softmax结构:

在以上公式中的Q、K、V,分别可以看作是多个query,keys,values分别拼接构成的矩阵,输出是由带权的values加起来得到,这里的权值也就是上面公式中的softmax的结果。
原论文里面提到scaled的点乘attention,其实目的是为了避免softmax函数内的值过大,导致softmax要不是0要不就是1,显然不符合常理,所以除以 d k \sqrt{d_k} dk。总结下来就是计算query和所有keys的点乘然后除以 d k \sqrt{d_k} dk得到values的权重,再乘以values,然后对最后得到的多个结果相加即可得到对应的那个query的Attention。
(2)Multi-Head Attention
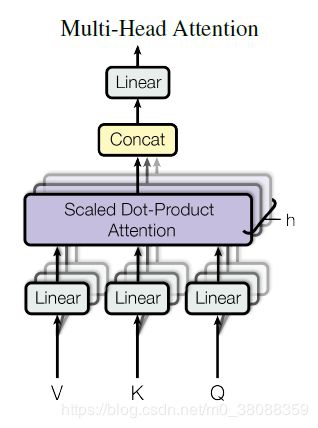
将Q,K,V通过参数矩阵映射一下,然后再做attention,把整个过程重复做h次:
![]()
然后把这h个结果拼接起来再做一次映射:
![]()
其中:
![]()
![]()
4、Self-Attention(内部注意力)
X为输入序列。
在具体阅读理解应用中,Q是篇章的词向量序列,K=V为问题的词向量序列。
5、位置Embedding
因为纯注意力机制不像CNN和RNN可以把序列顺序信息也考虑进去,在纯注意力机制模型里面不管词的顺序如何,得到的结果都是一样,这样显然不现实,而且语言本身是带有顺序序列信息的,所以要引入位置的Embedding。
这里有很多办法可以引入位置信息,但是论文中用了以下函数进行位置信息引入,分别是sin和cos函数。

pos是词的位置,i是维度,每一个位置维度的编码对应于正弦值。选择这两个函数为了方便模型学习,并且cos与sin提供了一个重要的性质:
以上性质可以表达语言中的相对位置信息。
意思是将id为pos的位置映射为一个dmodel维的位置向量,这个向量的第i个元素的数值就是PE(pos,2i)。
备注:
位置向量和词向量的结合可以使用直接相加的方式进行结合,也可以进行拼接,但论文中使用的是直接相加。
6、Position-wise Feed-Forward Networks(前馈网络)
每层里面除了注意力支层以外,还包含了前馈网络这个支层。
该网络是两个线性变换,中间加了一个ReLU激活函数。每个位置(position)上的线性变换是一样的,但是不同层与层的参数是不一样的。该网络的输入和输出维度都是dmodel =512,不过中间层的维度是2048.
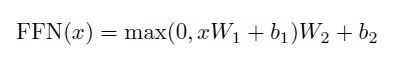
7、模型中Attention的使用
1 在encoder-decoder的attention层,queries来自于之前的decoder层,而keys和values都来自于encoder的输出。这个类似于很多已经提出的seq-to-seq模型所使用的attention机制。
2 在encoder含有self-attention层。在一个self-attention层中,所有的keys, values以及queries都来自于同一个地方,本例中即encoder之前一层的的输出。
3 decoder中的self-attention层也是一样。不同的是在scaled点乘attention操作中加了一个mask的操作(设置为负无穷),这个操作是保证softmax操作之后不会将非法的values连到attention中。如上图Scaled Dot-Product Attention所示。
8、总结
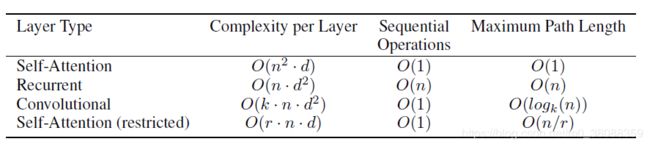
attention的方式不仅能够完全并行(训练阶段的encoder和decoder,inference阶段的encoder),和facebook的convseq2seq并行方式同理,而且计算量比convseq2seq还低,因为考虑到conv还有一个kernel的宽度k。比RNN既能减少计算量,又能增大并行方式。
文献中的table:
代码地址:https://github.com/tensorflow/tensor2tensor
学习自:
(1)https://www.zhihu.com/question/61077555
(2)https://kexue.fm/archives/4765#Self%20Attention
(3)https://arxiv.org/abs/1706.03762