Pytorch实现 卷积神经网络LeNet
1、LeNet简介
参考网址:https://www.jianshu.com/p/ce609f9b5910
LeNet-5共有7层,不包含输入,每层都包含可训练参数;每个层有多个Feature Map,每个FeatureMap通过一种卷积滤波器提取输入的一种特征,然后每个FeatureMap有多个神经元。
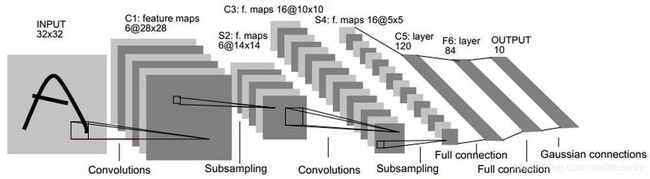
2、Pytorch实现
深度学习的算法本质上是通过反向传播求导数,Pytorch的Autograd模块实现了此功能。torch.nn是专门为神经网络设计的模块化接口,nn构建于Autograd之上,nn.Module是nn中最重要的类。
1)定义网络
定义网络时,需要继承nn.Module,实现它的forward方法,把网络中具有可学习参数的层放在构造函数 _ _ init _ _中.只要在nn.Module的子类中定义了forword函数,backward函数会被自动实现。
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
# nn.Model 子类的函数必须在构造函数中执行父类的构造函数
# 下式等价于nn.Model.__init__(self)
super(Net,self).__init__()
# 卷积层‘1’表示输入图片为单通道, ‘6’表示输出通道数
# ‘5’表示卷积核为5*5
self.conv1 = nn.Conv2d(1,6,5)
# 卷积层
self.conv2 = nn.Conv2d(6,16,5)
# 仿射层/ 全连接层,y=Wx + b
self.fc1 = nn.Linear(16*5*5,120)
self.fc2 = nn.Linear(120,84)
self.fc3 = nn.Linear(84,10)
def forward(self,x):
# 卷积 -> 激活 -> 池化
x = F.max_pool2d(F.relu(self.conv1(x)),(2,2))
x = F.max_pool2d(F.relu(self.conv2(x)),2)
# reshape, '-1' 表示自适应
x = x.view(x.size()[0], -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
print(net)
2)定义损失函数和优化器
nn实现了神经网络中大多数的损失函数
output = net(input) #调用网络函数 net()
target = Variable(t.arange(0,10))
target = target.reshape(1,10)
target = target.float() #为使target类型和output类型一致
criterion = nn.MSELoss() #计算均方差
loss = criterion(output,target)
3)训练网络并更新网络参数
在反向传播计算完所有参数的梯度后,还需要使用优化方法更新网络的权重和参数。torch.optim中实现了深度学习中绝大多数的优化方法。
import torch.optim as optim
import numpy as np
# 新建一个优化器,指定要调整的参数和学习率
optimizer = optim.SGD(net.parameters(),lr=0.01)
# 在训练过程中
# 先梯度清零(与net.zero_grad()效果一样)
optimizer.zero_grad()
# 计算损失output = net(input)
target = Variable(t.arange(0,10))
target = target.reshape(1,10)
target = target.float()
criterion = nn.MSELoss()
loss = criterion(output,target)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()