图像分割
DenseNet(2017年)
网络参考
DenseNet参考了ResNet和GoogleNet的优点:ResNet的特征passthrough layer(但ResNet的pass layer的特征是相加的形式,破坏了特征在网络中的传播);GoogleNet的特征串联形式 xl=Hl([x,x1,x2,...,xl+1]) x l = H l ( [ x , x 1 , x 2 , . . . , x l + 1 ] ) ;分块处理的形式:Dense Block(不同块之间经历pooling操作,size不同)和transition layers
基本结构
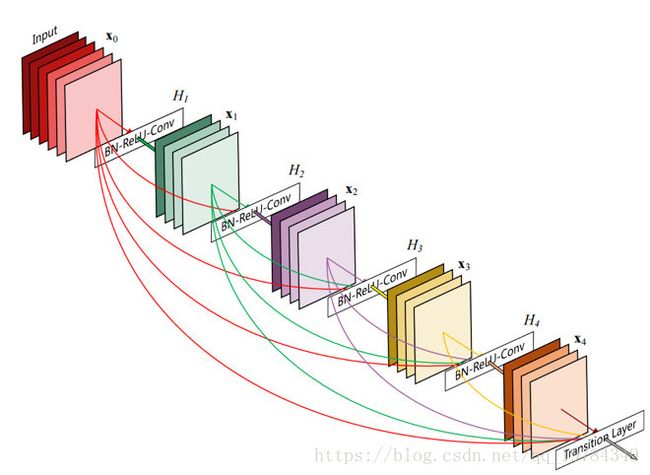
DenseNet 是一种具有密集连接的卷积神经网络。在该网络中,任何两层之间都有直接的连接,也就是说,网络每一层的输入都是前面所有层输出的并集,而该层所学习的特征图也会被直接传给其后面所有层作为输入。
启发来源
作者前面参考传统神经网络的dropout思想,随机丢掉CNN中的某些层,实现CNN的dropout,发现可以显著提高ResNet的泛化能力。该实验的成功带来以下两点启发:
- 首先,它说明了神经网络其实并不一定要是一个递进层级结构,也就是说网络中的某一层可以不仅仅依赖于紧邻的上一层的特征,而可以依赖于更前面层学习的特征。想像一下在随机深度网络中,当第 l 层被扔掉之后,第 l+1 层就被直接连到了第 l-1 层;当第 2 到了第 l 层都被扔掉之后,第 l+1 层就直接用到了第 1 层的特征。因此,随机深度网络其实可以看成一个具有随机密集连接的 DenseNet。
- 其次,我们在训练的过程中随机扔掉很多层也不会破坏算法的收敛,说明了 ResNet 具有比较明显的冗余性,网络中的每一层都只提取了很少的特征(即所谓的残差)。实际上,我们将训练好的 ResNet 随机的去掉几层,对网络的预测结果也不会产生太大的影响。既然每一层学习的特征这么少,能不能降低它的计算量来减小冗余呢?
DenseNet 的设计正是基于以上两点观察。网络中的每一层都直接与其前面层相连,实现特征的重复利用;同时把网络的每一层设计得特别「窄」,即只学习非常少的特征图(最极端情况就是每一层只学习一个特征图),达到降低冗余性的目的。这两点也是 DenseNet 与其他网络最主要的不同。需要强调的是,第一点是第二点的前提,没有密集连接,我们是不可能把网络设计得太窄的,否则训练会出现欠拟合(under-fitting)现象,即使 ResNet 也是如此。
DenseNet优点
- 省参数、省计算(DenseNet 的每一层只需学习很少的特征(相对应的,深度也更深一些),使得参数量和计算量显著减少。每一层输出的channel数都不高;作者认为网络学习有冗余。。达到和ResNet一样的精度时,DenseNet计算量只需要ResNet一半左右)
- 抗过拟合(DenseNet 具有非常好的抗过拟合性能,在数据集不是很大的时候表现尤其突出。。个人认为是深层特征学习(每层的feature maps都较少)的不像其他网络那么多,且最后的output也参考了input的原始信息,所以网络本身可以看做有过拟合的作用。)
- 减轻梯度消失现象(每层的输入都是前面所有层的输出的连接,所以loss是直接与每一层、与输入input直接连接的。)
- 支持特征重用
- 强化特征传播(对比ResNet是直接相加的,那么输入特征的表现会收到影响)
对于 DenseNet 抗过拟合的原因有一个比较直观的解释:神经网络每一层提取的特征都相当于对输入数据的一个非线性变换,而随着深度的增加,变换的复杂度也逐渐增加(更多非线性函数的复合)。相比于一般神经网络的分类器直接依赖于网络最后一层(复杂度最高)的特征,DenseNet 可以综合利用浅层复杂度低的特征,因而更容易得到一个光滑的具有更好泛化性能的决策函数。
作者还做过一些简单的实验,比如每一层都只连接到前面最近的 m 层(例如 m=4),或者奇(偶)数层只与前面的偶(奇)数层相连,但这样简化后的模型并没有比一个相应大小的正常 DenseNet 好。当然这些都只是一些非常初步的尝试,如果采用一些好的剪枝(prune)的方法,我觉得 DenseNet 中一部分连接是可以被去掉而不影响性能的。
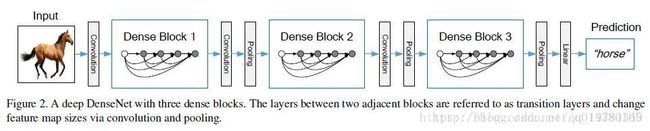
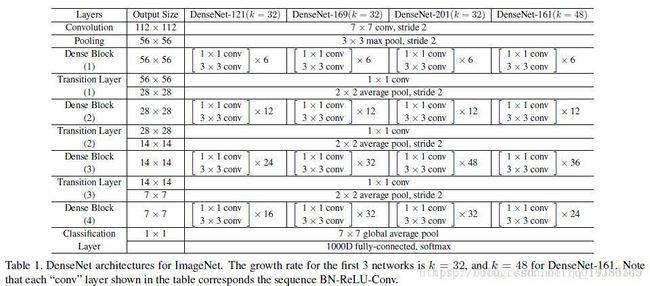
从上面的结构图可以看出,DenseNet的层数如果够大,那么其每层的输入都在不断叠加,所以作者引入了 bottlenet和transition layer的概念。实际上,bottlenet和transition layer都是 1∗1 1 ∗ 1 的卷积核,用于降低输入维度。其中bottlenet是在dense block内作用的,其作用于 3∗3 3 ∗ 3 的卷积前,如DenseNet-169的Dense Block(3)的第32层,其输出channel为32,其输入channel为 31∗32+上一个DenseBlock的输出channel=992+上一个DenseBlock的输出channel 31 ∗ 32 + 上 一 个 D e n s e B l o c k 的 输 出 c h a n n e l = 992 + 上 一 个 D e n s e B l o c k 的 输 出 c h a n n e l 。所以在 3∗3 3 ∗ 3 卷积层之前添加 1∗1 1 ∗ 1 卷积层以降低channel数,这就叫做bottlenet,这里的 1∗1 1 ∗ 1 卷积核的个数为 32∗4=128 32 ∗ 4 = 128 。而transition layer是在不同Dense Block中作用的,Dense Block的输出channel为 32∗32+上一个DenseBlock的输出channel 32 ∗ 32 + 上 一 个 D e n s e B l o c k 的 输 出 c h a n n e l ,其 1∗1 1 ∗ 1 卷积核个数由超参数reduction决定,默认为0.5。【带有Bottlenet layers的网络结构称为DenseNet-B;带有transition layers的网络结构称为DenseNet-C;拥有两个结构的称为DenseNet-BC】compression。
作者实现网络的时候,使用的池化方式为平均池化。大概是因为输入的叠加,出现0现象的情况基本不会出现,所以可以采取区域信息收集的方式。
FCN(2015年)
FCN采用的基础结构是AlexNet;其除了最后的移除全连接层后,添加对应channel的卷积层输出,最后添加一个上采样层(反卷积)输出原图大小。
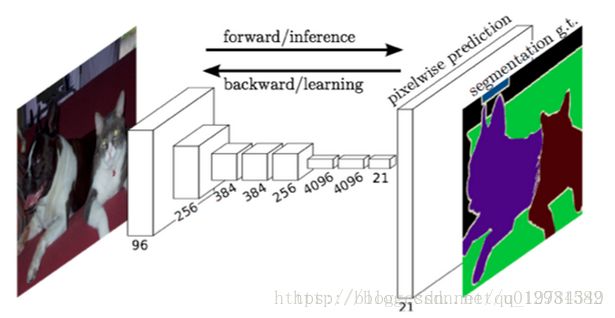

如上图所示,对原图像进行conv1、pool1后缩小为原图像 1/2 1 / 2 ;conv2、pool2后为 14 1 4 ;conv3、pool3为 18 1 8 ,此时保留pool3的featureMap;conv4、pool4,缩小为原图像的 116 1 16 ,保留pool4的featureMap;最后对图像进行第五次卷积操作conv5、pool5,缩小为原图像的 132 1 32 ;经过conv6、conv7后,feature的channel改变,但size不变,为 132 1 32 原图像;此时进行32倍上采样得到原图大小,这个结果叫做 FCN-32s(结果太平滑,不精细)。pool4和经过2倍上采样的conv4的和,再经过16倍上采样,得到 FCN-16s。pool3和经过两倍的pool4,经过4倍的conv7的和,再经过8倍上采样,得到 FCN-8s。

FCN优点:
- 应该是第一个pixed-pixed的网络
- 与CNN语义分割方法比较,不用重复计算(CNN语义分割方法,用滑动窗口,一个窗口对应一个点)
FCN缺点:
- 即时是FCNN-8s的结果也不算精细,对图像的细节不够敏感。(因为在decoder时,也就是上采样,只有一个转置卷积,此时的倍数太大,label太稀疏)
SegNet(2015年)
SegNet的结构如下:

可以看出,整个结构就是一个encoder和一个decoder.前面的encoder就是采用的vgg-16的网络结构,而decoder和encoder基本上就是对称的结构.
SegNet和FCN最大的不同就在于decoder的upsampling方法,上图结构中,注意,前面encoder每一个pooling层都把pooling indices保存,并且传递到后面对称的upsampling层. 进行upsampling的过程具体如下:
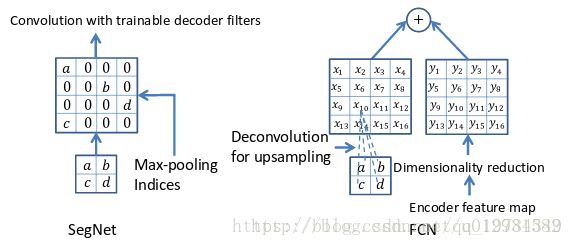
左边是SegNet的upsampling过程,就是把feature map的值 abcd, 通过之前保存的max-pooling的坐标映射到新的feature map中,其他的位置置零.
右边是FCN的upsampling过程,就是把feature map, abcd进行一个反卷积,得到的新的feature map和之前对应的encoder feature map 相加.
U-net(2015年)
U-net 是基于FCN的一个语义分割网络,适合用来做医学图像的分割。

基于CNN的图像分割算法,其定位精度和分类精度不可兼得(在每个点去一个patch作为输入,判断该点类别)。当感受野选取较大时,图像缩到点的降维倍数较大,会导致定位精度降低;当感受野选取较小时,patch分类精度降低;
U-net:较浅的高分辨率层用来解决像素定位的问题,较深的层用来解决像素分类的问题。将通分辨率对应的特征级联在一起时,低级特征需要裁剪(如上结构图所示,中间截取合适部分)。
在医学图像分割表现好:
- 因为利用了底层的特征(同分辨率级联)改善上采样的信息不足。
- 医学图像数据一般较少,底层的特征其实很重要。
其劣势:
通常要随机初始化,从头开始训练。当然,在2D和3D方面均可以通过迁移学习,拿VGG-Net或者C3D的权重进行权重初始化,对这个问题进行解决。或者采用COCO等分割数据,进行预训练。