Spark Dataset介绍和使用
Dataset是从Spark 1.6开始引入的一个新的抽象,当时还是处于alpha版本;然而在Spark 2.0,它已经变成了稳定版了。下面是DataSet的官方定义:
Dataset是特定域对象中的强类型集合,它可以使用函数或者相关操作并行地进行转换等操作。每个Dataset都有一个称为DataFrame的非类型化的视图,这个视图是行的数据集。上面的定义看起来和RDD的定义类似,RDD的定义如下:
RDD也是可以并行化的操作,DataSet和RDD主要的区别是:DataSet是特定域的对象集合;然而RDD是任何对象的集合。DataSet的API总是强类型的;而且可以利用这些模式进行优化,然而RDD却不行。
Dataset的定义中还提到了DataFrame,DataFrame是特殊的Dataset,它在编译时不会对模式进行检测。在未来版本的Spark,Dataset将会替代RDD成为我们开发编程使用的API(注意,RDD并不是会被取消,而是会作为底层的API提供给用户使用)。
实例:
import com.spark.DataFrameRDDApp.SetLogger
import org.apache.spark.sql.SparkSession
/**
* Created by *** 2017/12/23 16:17
* DataSet的使用
*/
object DataSetApp {
def main(args: Array[String]): Unit = {
SetLogger()
val spark = SparkSession.builder()
.master("local[2]")
.appName("DataFrameRDDApp").getOrCreate()
val path = "src/data/sales.csv"
// 解析CSV文件
val salesDF = spark.read.option("header", "true").option("inferSchema", "true").csv(path)
salesDF.show()
// 注意:需要导入隐式转换
import spark.implicits._
//转换成DataSet
val salesDS = salesDF.as[Sales]
salesDS.show()
salesDS.map(line => line.itemId).show()
salesDF.select("itemId").show()
salesDS.select("transactionId").show()
spark.stop()
}
case class Sales(transactionId: Int, customerId: Int, itemId: Int, amountPaid: Double)
}
transactionId,customerId,itemId,amountPaid
111,1,1,100.0
112,2,2,505.0
113,3,3,510.0
114,4,4,600.0
115,1,2,500.0
116,1,2,500.0
117,1,2,500.0
118,1,2,500.0
119,2,3,500.0
120,1,2,500.0
121,1,4,500.0
122,1,2,500.0
123,1,4,500.0
124,1,2,500.0DataSet静态类型和运行时类型安全示意图:
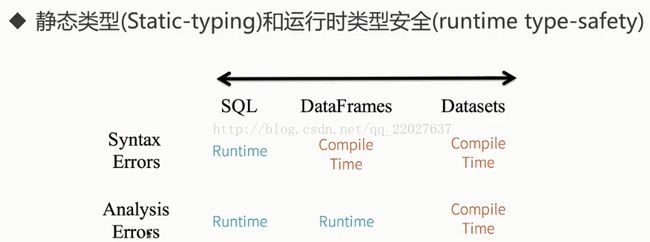
SQL:
seletc name from perple; 编译(compile)时——通过,执行时(Running)——报错 【spark.sql(" seletc name from perple")】
DataFrame:
peopleDF.seletc("name") 编译(compile)时——报错
peopleDF.select("nname") 编译(compile)时——通过,执行时(Running)——报错
DataSet:
peopleDS.seletc("name") 编译(compile)时——报错
salesDS.map(line => line.itemIddd).show() 编译(compile)时——报错