pytorch教程之损失函数详解——多种定义损失函数的方法


前言:前面的系列文章已经详细介绍了使用torch.nn.Module来实现自己定义的模型、自定义层,本文将继续来说明如何自定义损失函数,需要明确一个观点,不管是定义层还是损失函数,方法有很多,但是通过统一的接口nn.Module是最便于查看的,这也是pytorch的优点之一,模型、层、损失函数的定义具有统一性,都是通过Module类来完成,不像tensorflow那样不规范。具体可以参考前面两篇文章:
pytorch教程之nn.Module类详解——使用Module类来自定义模型
pytorch教程之nn.Module类详解——使用Module类来自定义网络层
一、回顾
1.1 关于nn.Module 和 nn.functional 区别和联系
前面讲过,自定义层的时候可以通过nn.Module 和 nn.functional二者来完成,但是推荐使用前者,为什么呢?
简答的说就是, nn.Module是一个包装好的类,具体定义了一个网络层,可以维护状态和存储参数信息;而nn.functional仅仅提供了一个计算,不会维护状态信息和存储参数。在Module类内部,层的功能其实又是通过nn.functional来实现的。
对于一些不需要存储参数和状态信息的层,比如activation函数,比如(relu, sigmoid等),dropout,pooling等没有训练参数,可以使用functional模块,当然也可以使用nn.Module类来完成。
1.2 损失函数和层的共性
本质上来说,损失函数和自定义层有着很多类似的地方,他们都是通过对输入进行函数运算,得到一个输出,这不也就是层的功能吗?只不过层的函数运算比较不一样,可能是线性组合、卷积运算等,但终归也是函数运算,正是基于这样的共性,所以我们可以统一的使用nn.Module类来定义损失函数,而且定义的方式也和前面的层是大同小异的。
二、自定义的损失函数
2.1 通过nn.Module类来实现自定义的损失函数
鉴于前面所说的,损失函数的本质也就是“对输入进行函数运算,得到一个输出”,所以我们可以像定义层一样自定义一个损失函数,比如我自己定义一个 MSE 损失函数,代码如下:
class My_loss(nn.Module):
def __init__(self):
super().__init__() #没有需要保存的参数和状态信息
def forward(self, x, y): # 定义前向的函数运算即可
return torch.mean(torch.pow((x - y), 2))
在使用这个巡视函数的时候只需要如下即可:
criterion = My_loss()
loss = criterion(outputs, targets)
总结:上面的定义方法,将“模块、层、激活函数、损失函数”这些概念统一到了一起,这是pytorch做的比较好的地方(个人意见)。
其实在pytorch中,已经有很多的函数是作为类定义好了的,如下:
class _Loss(Module):
@weak_module
class L1Loss(_Loss):
@weak_module
class NLLLoss(_WeightedLoss):
@weak_module
class NLLLoss2d(NLLLoss):
@weak_module
class PoissonNLLLoss(_Loss):
@weak_module
class KLDivLoss(_Loss):
@weak_module
class MSELoss(_Loss):
@weak_module
class BCELoss(_WeightedLoss):
@weak_module
class BCEWithLogitsLoss(_Loss):
@weak_module
class HingeEmbeddingLoss(_Loss):
@weak_module
class MultiLabelMarginLoss(_Loss):
@weak_module
class SmoothL1Loss(_Loss):上面没有列举完全,,,
从上面可以看出,这跟我们自定义的损失函数是如出一辙的,没一个损失函数作为一个类,继承自_Loss类,而_Loss类又继承自Module类,这不正是跟上面的很吻合吗?我们可以来看一下MSELoss的定义,如下:
@weak_module
class MSELoss(_Loss):
__constants__ = ['reduction']
def __init__(self, size_average=None, reduce=None, reduction='mean'):
super(MSELoss, self).__init__(size_average, reduce, reduction)
@weak_script_method
def forward(self, input, target): # 这和我自己的定义是很类似的,只不过是通过nn.functional里面的函数来完成的
return F.mse_loss(input, target, reduction=self.reduction)我只需要在自定义的损失函数类里面实现构造函数__init__和forward函数即可。
比如:
from torch.nn.modules.loss import _Loss
class DiscriminativeLoss(_Loss):
def __init__(self, delta_var=0.5, delta_dist=1.5,norm=2, alpha=1.0, beta=1.0, gamma=0.001,usegpu=False, size_average=True):
def forward(self, input, target, n_clusters):
class HNetLoss(_Loss):
def __init__(self, gt_pts, transformation_coefficient, name, usegpu=True):
def forward(self, input, target, n_clusters):
2.2 通过nn.functional直接定义函数来完成
前面的定义可以看出,一般情况下,损失函数是没有参数信息和状态需要维护的,所以更多的时候我们没有必要小题大做,自己去定义一个损失函数的类,我们只需要一个计算的数学函数即可,nn.functional里面定义了一些常见的函数,当然也包括一些常见的损失函数,如下:
@weak_script
def smooth_l1_loss(input, target, size_average=None, reduce=None, reduction='mean'):
@weak_script
def l1_loss(input, target, size_average=None, reduce=None, reduction='mean'):
@weak_script
def mse_loss(input, target, size_average=None, reduce=None, reduction='mean'):
@weak_script
def margin_ranking_loss(input1, input2, target, margin=0, size_average=None,
reduce=None, reduction='mean'):
@weak_script
def hinge_embedding_loss(input, target, margin=1.0, size_average=None,
reduce=None, reduction='mean'):
@weak_script
def multilabel_margin_loss(input, target, size_average=None, reduce=None, reduction='mean'):
@weak_script
def soft_margin_loss(input, target, size_average=None, reduce=None, reduction='mean'):
@weak_script
def multilabel_soft_margin_loss(input, target, weight=None, size_average=None,
reduce=None, reduction='mean'):
@weak_script
def cosine_embedding_loss(input1, input2, target, margin=0, size_average=None,
reduce=None, reduction='mean'):
@weak_script
def multi_margin_loss(input, target, p=1, margin=1., weight=None, size_average=None):当然这里没有完全列举出来,只是其中的一部分,我们在很多时候只需要使用系统给定的损失函数即可,如果我要自定义一个简单的损失函数,比如我要将 MSE损失添加一个L1正则项,我们就可以这么做了,如下:
loss=F.mse_loss(inputs,targets)+F.l1_loss(inputs,targets)2.3 完全定义一个自己的损失函数
如果一个损失函数完全是自己定义的,很有可能nn.functional里面没有相关的函数,这个时候我就没办法简单的拼接nn.functional来得到了,事实上,损失函数仅仅是一个函数而已,我可以完全定义一个自己的函数,如下所示:
# 直接定义函数 , 不需要维护参数,梯度等信息
# 注意所有的数学操作需要使用tensor完成。
def my_mse_loss(x, y):
return torch.mean(torch.pow((x - y), 2))
这其实就是完完全全自己定义的一个函数,当然我还可以通过一个类来包装这个函数。
总结:
损失函数的定义很灵活,可以采用上面三种方式的任意一种,我们可以自定义一个函数、通过nn.functional里面的函数、定义一个类对前两者进行封装。
三、通过继承于nn.autograd.Function类来实现损失函数
除了前面的方法,我们还可以通过直接继承自nn.autograd.Function类来实现损失函数,关于nn.autograd.Function的详细说明,我会在后面的文章中再详说,这里就不再展开了。需要注意的是,要想继承nn.autograd.Function类,我们需要
自己实现backward和forward函数,即这个要自己定义实现前向传播和反向传播的计算过程。
四、自定义损失的案例
第一步:本次通过自定义一个损失函数类来实现
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
# 第一步:自定义损失函数
继承nn.Mdule
class My_loss(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x, y):
return torch.mean(torch.pow((x - y), 2))第二步:准备数据
# 第二步:准备数据集,模拟一个线性拟合过程
x_train = np.array([[3.3], [4.4], [5.5], [6.71], [6.93], [4.168],
[9.779], [6.182], [7.59], [2.167], [7.042],
[10.791], [5.313], [7.997], [3.1]], dtype=np.float32)
y_train = np.array([[1.7], [2.76], [2.09], [3.19], [1.694], [1.573],
[3.366], [2.596], [2.53], [1.221], [2.827],
[3.465], [1.65], [2.904], [1.3]], dtype=np.float32)
# 将numpy数据转化为torch的张量
inputs = torch.from_numpy(x_train)
targets = torch.from_numpy(y_train)第三步:构建模型
input_size = 1
output_size = 1
num_epochs = 60
learning_rate = 0.001
# 第三步: 构建模型,构建一个一层的网络模型
model = nn.Linear(input_size, output_size)
# 与模型相关的配置、损失函数、优化方式
# 使用自定义函数,等价于criterion = nn.MSELoss()
criterion = My_loss()
# 定义迭代优化算法, 使用的是随机梯度下降算法
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate) 第四步:训练模型
loss_history = []
# 第四步:训练模型,迭代训练
for epoch in range(num_epochs):
# 前向传播计算网络结构的输出结果
outputs = model(inputs)
# 计算损失函数
loss = criterion(outputs, targets)
# 反向传播更新参数,三步策略,归零梯度——>反向传播——>更新参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 打印训练信息和保存loss
loss_history.append(loss.item())
if (epoch+1) % 5 == 0:
print ('Epoch [{}/{}], Loss: {:.4f}'.format(epoch+1, num_epochs, loss.item()))
'''运行结果为:
Epoch [5/60], Loss: 33.1027
Epoch [10/60], Loss: 13.5878
Epoch [15/60], Loss: 5.6819
Epoch [20/60], Loss: 2.4788
Epoch [25/60], Loss: 1.1810
Epoch [30/60], Loss: 0.6551
Epoch [35/60], Loss: 0.4418
Epoch [40/60], Loss: 0.3552
Epoch [45/60], Loss: 0.3199
Epoch [50/60], Loss: 0.3055
Epoch [55/60], Loss: 0.2994
Epoch [60/60], Loss: 0.2968
'''第五步:结果展示
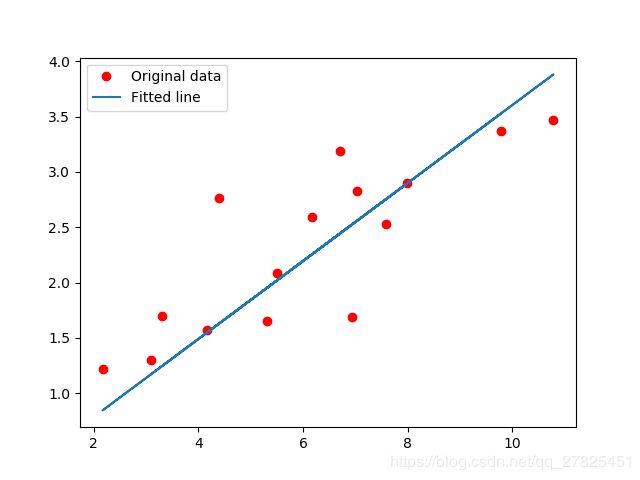
# 第五步:结果展示。画出原y与x的曲线与网络结构拟合后的曲线
predicted = model(torch.from_numpy(x_train)).detach().numpy() #模型输出结果
plt.plot(x_train, y_train, 'ro', label='Original data') #原始数据
plt.plot(x_train, predicted, label='Fitted line') #拟合之后的直线
plt.legend()
plt.show()
# 画loss在迭代过程中的变化情况
plt.plot(loss_history, label='loss for every epoch')
plt.legend()
plt.show()运行结果为: