Fast R-CNN
目录
一、概括
二、Fast R-cnn框架介绍
三、主要内容
3.1 RoI pooling layer
3.2 从预训练网络中初始化
3.3 微调网络用来检测
3.4 尺度不变性
四、训练过程/测试过程
4.1 训练过程
4.2 测试过程
参考资料
一、概括
在前面两篇帖子《R-CNN》和《Spatial Pyramid Pooling》中,我们知道R-CNN和SPP在当时的目标检测领域绝对是被研究的热门,虽然也存在很多的不足,随着对网络结构的优化,和一些深度学习技巧的使用,于是Fast R-CNN就诞生,并迅速替代了前面的方法,相对于R-CNN与SPP-net,Fast R-cnn的主要亮点有:Fast R-CNN将借助多任务损失函数,将物体识别和位置修正合成到一个网络中,不再对网络进行分步训练,不需要大量内存来存储训练过程中特征的数据;用RoI层代替SPP层,可以使用BP算法更高效的训练更新整个网络。现在,这些方法已经很少使用了,但是经典的网络中涉及到的框架结构搭建,训练与优化等技巧还是值得我们去学习。
二、Fast R-cnn框架介绍
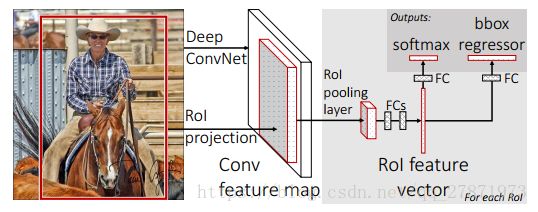
框架介绍:一张包含多个RoI(regions of interest)的图片(上图便于说明只显示一个RoI,灰色部分)输入一个多层的卷积网络中,获得Conv feature map,然后每一个RoI被池化成一个固定大小的feature map,feature map被全连接层拉伸成一个特征向量。对于每一个RoI,经过FC层后得到的feature vector最终被分享:一个进行全连接之后用来做softmax回归,用来对RoI区域做物体识别,另一个经过全连接之后用来做b-box regression做修正定位,使得定位框更加精准。
三、主要内容
3.1 RoI pooling layer
不同于前面的SPP,在Fast RCNN网络中,RoI来完成SPP层的作用。RoI指的是在一张图片上完成Selective Search后得到的“候选框”在特征图上的一个映射,RoI层的作用主要有两点:
- 考虑到感兴趣区域(RoI)尺寸不一,但是输入图中后面FC层的大小是一个统一的固定值,因为ROI池化层的作用类似于SPP-net中的SPP层,即将不同尺寸的RoI feature map池化成一个固定大小的feature map。具体操作:假设经过RoI池化后的固定大小为
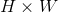 是一个超参数,因为输入的RoI feature map大小不一样,假设为
是一个超参数,因为输入的RoI feature map大小不一样,假设为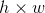 ,需要对这个feature map进行池化来减小尺寸,那么可以计算出池化窗口的尺寸为:
,需要对这个feature map进行池化来减小尺寸,那么可以计算出池化窗口的尺寸为: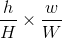 ,即用这个计算出的窗口对RoI feature map做max pooling,Pooling对每一个feature map通道都是独立的。
,即用这个计算出的窗口对RoI feature map做max pooling,Pooling对每一个feature map通道都是独立的。 - 其次RoI有四个参数
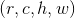 除了尺寸参数
除了尺寸参数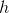 、
、 外,还有两个位置参数
外,还有两个位置参数 、
、 表示RoI的左上角在整个图片中的坐标。
表示RoI的左上角在整个图片中的坐标。
3.2 从预训练网络中初始化
作者使用有5个最大池化层和5到13个不等的卷积层的三种网络进行预训练:CaffeNet,VGG_CNN_M_1024,VGG-16,使用这些网络初始化Fast R-CNN前,需要以下修改:
①用RoI pooling layer取代网络的最后一个池化层
②最后一个FC层和softmax被替换成fast R-CNN框架图介绍的两个并列层
③输入两组数据到网络:一组图片和每一个图片的一组RoIs
3.3 微调网络用来检测
不同于SPP-net,Fast R-CNN整个网络可以被使用BP算法训练是一个极大的优点,论文中作者提到SPP层中的感受野非常大,使用BP算法训练时效率低。作者利用特征分享的优势,提出一个更加有效的训练方法:SGD mini_batch分层采样方法。
首先随机取样N张图片,然后每张图片取样R/N个RoIs 。除此之外,网络在一次微调中将softmax分类器和bbox回归一起优化,区别于R-CNN的softmax回归,SVM,bbox回归的三步分开优化。
一步优化中涉及到:多任务损失(multi-task loss)、小批量取样(mini-batch sampling)、RoI pooling层的反向传播(back-propagation through RoI pooling layers)、SGD超参数(SGD hyperparameters),其中multi-task loss在论文里对应着分类任务和定位任务的结合,back-propagation through RoI pooling layers在论文里作者详细讲解了如何使用BP算法对RoI层训练,这两个小部分比较重要,也是论文的核心亮点,以后有机会单独拿出来学习一下。
3.4 尺度不变性
作者测试了两种方法来实现目标检测的尺度不变性:“强制”学习和图像金字塔方法。在“强制”方法中,在训练和测试过程中,每个图像都按照预先定义的像素大小进行处理。网络直接从训练数据中学习尺度不变性检测。相比之下,多尺度方法通过图像金字塔为网络提供了近似的尺度不变性。在测试时,使用图像金字塔方法对each object proposal进行标准化。
四、训练过程/测试过程
FastR-CNN的训练和测试过程结合文中的框架图进行理解。
4.1 训练过程
对训练集中的图片,用selective search提取出每一个图片对应的一些proposal,保存图片路径和bounding box信息;
对每张图片,根据图片中bounding box的ground truth信息,给该图片的每一个proposal标记类标签,并保存。具体操作:对于每一个proposal,如果和ground truth中的proposal的IOU值超过了阈值(IOU>=0.5),则把ground truth中的proposal对应的类标签给原始产生的这个proposal,其余的proposal都标为背景;
使用mini-batch=128,25%来自非背景标签的proposal,其余来自标记为背景的proposal;
训练CNN,最后一层的结果包含分类信息和位置修正信息,用多任务的loss,一个是分类的损失函数,一个是位置的损失函数。
4.2 测试过程
用selective search方法提取图片的2000个proposal,并保存到文件;
将图片输入到已经训好的多层全卷积网络,对每一个proposal,获得对应的RoI Conv featrue map;
对每一个RoI Conv featrue map,按照3.1中的方法进行池化,得到固定大小的feture map,并将其输入到后续的FC层,最后一层输出类别相关信息和4个boundinf box的修正偏移量;
对bounding box 按照上述得到的位置偏移量进行修正,再根据nms对所有的proposal进行筛选,即可得到对该张图片的bounding box预测值以及每个bounding box对应的类和score。
其他资料
GitHub上一些Fast R-CNN实现:
https://github.com/rbgirshick/fast-rcnn
https://github.com/mahyarnajibi/fast-rcnn-torch
参考资料
[1] Fast R_CNN
[2] https://blog.csdn.net/xg123321123/article/details/53067518
[3] http://shartoo.github.io/RCNN-series/
[4] https://www.jianshu.com/p/38bed2b9f49a