深度学习模型压缩之MobileNetV2
-
-
- 摘要
- 1 引言
- 2 相关工作
- 3 预备知识、讨论、直觉
- 3.1 深度可分离卷积
- 3.2 线性瓶颈(Linear Bottlenecks)
- 3.3 反向残差(Inverted residuals)
- 3.4 信息流解释
- 4 模型结构
- 5 执行记录
- 5.1 内存有效管理
- 6 实验
- 6.1 ImageNet分类
- 6.2 目标检测
- 6.3 语义分割
- 6.4 模型简化测试(Ablation study)
- 7 结论和未来工作
-
论文名称:MobileNetV2: Inverted Residuals and Linear Bottlenecks
摘要
在本文中我们描述了一个新的移动端网络结构MobileNetV2,其在多任务和基准测试以及在不同的模型尺寸下都提升到了最好的效果。同时我们也描述了在一个新的框架SSDLite中应用移动结构到目标检测任务的有效方式。另外,我们证明了如何通过一种简化形式的DeepLabv3(我们称之为Mobile DeepLabv3)来构建语义分割模型。
基于反向残差结构在薄化瓶颈层之间使用shortcut连接。中间扩展层使用轻量深度卷积来滤波非线性源特征。另外,我们发现为了维持网络表达能力,在窄层中移除非线性表达是非常重要的。我们证明了这有助于提升性能。,并且直觉觉得应该这么设计。
最后,我们的方法从转换开始就允许输入输出域的解耦,其能对未来的分析提供一个便利的框架。我们在ImageNet分类数据集(Imagenet large scale visual recognition challenge.)、COCO目标检测数据集(Microsoft COCO: Common objects in context)、VOC图像分割数据集(The pascal visual object classes challenge a retrospective.)上进行实验。我们测试了准确率、由乘加操作定义的计算量以及实际延迟和阐述数量之间的权衡关系。
1 引言
神经网络使得机器智能以及具有挑战性的超过人类精度的图像识别任务中发生了革命性的剧变。然而,提升精度的同时也会经常需要付出代价:现代最先进的网络要求好的计算资源,其远远超过了许多移动端、嵌入式应用设备的承载能力。
本文介绍了为移动端和资源限制环境下量身定做的一种新的神经网络结构。我们的网络推动了移动端定制计算机视觉网络的最好结果,即在相同准确率下大大减少了操作数以及需要的内存数。
我们的主要贡献在于设计一种新型的层模块:具有线性瓶颈的反向残差(the inverted residual with linear bottleneck)。该模块以低维压缩表示作为输入,首先将其扩展到高维,然后用一个轻量级深度卷积来进行滤波。特征随后投影为一个低维表示与一个线性的卷积,官方实现可作为Tensorflow-Slim模型库的一部分来使用(https://github.com/tensorflow/ models/tree/master/research/slim/ nets/mobilenet)。
这个模块能够使用任何模型中的标准操作来执行,并且可以针对标准的基准测试来在多个关键性能点上都能使用我们的模型打败现在最好结果的模型。更进一步,这个卷积模块非常适合移动端设计,因为它允许通过稀疏化的大的中间层的tensor来显著减少测试阶段所需要占用的内存空间。这减少了许多嵌入式硬件设计对主要内存访问的需求,提供了少量非常快的软件控制缓存策略。
2 相关工作
在过去几年,调整深度神经结构来达到准确率和性能之间的优化平衡已经变成一个非常活跃的研究领域。手工结构探索和训练算法的提升都有许多的团队在做,并取得了不错的效果,如早期AlexNet、VGGNet、GoogLeNet和ResNet,最近也有大量的工作集中于算法结构的探索,包含超参数的优化(Random search for hyper-parameter optimization.)(Practical bayesian optimization of ma- chine learning algorithms)(Scalable bayesian optimization using deep neural networks.)还有各种网络微调的方法(Second order derivatives for network pruning: Optimal brain surgeon)(Advances in Neural Information Process- ing Systems)(Learning both weights and connections for efficient neural network.)(DSD: regularizing deep neural networks with dense-sparse-dense training flow)(Advances in Neural Information Processing Systems)(Pruning filters for efficient convnets)以及连通性学习(Connectivity learning in multi-branch networks)(Learning time- efficient deep architectures with budgeted super networks)。随后一些工作集中于改变内部卷积块的连通结构如ShuffleNet(Shufflenet: An extremely efficient convolutional neural network for mobile devices.)或者是引入稀疏性(The power of sparsity in convolutional neural networks.)或者是其他的(Design of efficient convolutional layers using single intra-channel convolution, topological subdivisioning and spatial ”bottleneck” structure.)
最近,(Learning transferable architectures for scalable image recognition.)(Genetic CNN.)(Large-scale evolution of image classifiers.)(Neural architecture search with reinforcement learning.)开辟了一个新的方向即利用遗传算法和增强学习来对网络结构进行搜索的优化方法。然而,一个缺点是最终得到的网络非常复杂。在本文中,我们追求的目标是发展一种直觉理解神经网络如何运作以及使用其来指导更加简单可行的网络设计。我们的方法可以看作是(Learning transferable architectures for scalable image recognition)改进的相关工作,在这方面我们的做法和ShuffleNet与(Design of efficient convolutional layers using single intra-channel convolution, topological subdivisioning and spatial ”bottleneck” structure)相同,而且进一步提升了性能。同时也提供了内部运用的可视化理解。我们的网络设计基于MobileNetV1,保留了它的简单性,并且不需要任何特殊的操作同时显著提升了它的准确率,在移动应用中的多图像分类和检测任务中取得了最好的效果。
3 预备知识、讨论、直觉
3.1 深度可分离卷积
深度可分离卷积对于许多有效的神经网络结构来说都是非常关键的组件(ShuffleNet)(MobileNetV1)(Xception),而且对于我们的工作来说,也是如此。基本的想法就是利用一个分解版本的卷积来代替原来的标准卷积操作,即将标准卷积分成两步来实现,第一步叫深度卷积(depthwise convolution),它通过对每个输入通道执行利用单个卷积核进行滤波来实现轻量级滤波,第二步是一个1x1卷积,叫做逐点卷积(pointwise convolution),它负责通过计算输入通道间的线性组合来构建新的特征。
标准卷积利用一个 hi∗wi∗di h i ∗ w i ∗ d i 的输入张量 Li L i ,以及卷积核 K∈Rk∗k∗di∗dj K ∈ R k ∗ k ∗ d i ∗ d j 得到一个 hi∗wi∗di h i ∗ w i ∗ d i 输出张量 Lj L j ,标准卷积层的计算量为 hi∗wi∗di∗dj∗k∗k h i ∗ w i ∗ d i ∗ d j ∗ k ∗ k 。
深度可分离卷积是标准卷积层的部分替代。就经验而言,他们几乎和标准卷积一样,但是计算损失只有 hi∗wi∗di(k2+dj) h i ∗ w i ∗ d i ( k 2 + d j ) ,其为深度卷积和1x1逐点卷积的和。有效的深度可分离卷积相较于标准卷积减少了大约 k2 k 2 的参数,MobileNetV2使用k=3(3x3可分离卷积层)因此计算量相较于标准卷积少了8~9倍。但是只有很少的精度损失。
3.2 线性瓶颈(Linear Bottlenecks)
考虑一个深层神经网络有n层 Li L i 构成,每一层之后都有维数为 hi∗wi∗di h i ∗ w i ∗ d i 的激活张量,通过这节我们将会讨论这些激活张量的基本属性,我们可以将其看作具有 di d i 维的有 hi∗wi h i ∗ w i 像素的容器。非正式的,对于真实图片的输入集,一组层激活(对于任意层 Li L i )形成一个“感兴趣流形”,长期以来,人们认为神经网络中的感兴趣流形可以嵌入到低维子空间中。换句话说,当我们单独看一层深度卷积层所有d维通道像素时,这些依次嵌入到一个低维子空间的值以多种形式被编码成信息。
乍一看,这可以通过简单的约减一层的维数来做到,从而减少了运算空间的维数。这已经在MobileNetV1中被采用,通过宽度乘法器来有效对计算量和准确率进行权衡。并且已经被纳入了其他有效的模型设计当中(Shufflenet: An extremely efficient convolutional neural network for mobile devices.)。遵循这种直觉,宽度乘法器允许一个方法来减少激活空间的维数指导感兴趣的流形横跨整个空间。然而,这个直觉当我们知道深度卷积神经网络实际上对每个坐标变换都有非线性激活的时候被打破。就好像ReLU,比如,ReLU应用在一维空间中的一条线就产生了一条射线,那么在 Rn R n 空间中,通常产生具有n节的分段线性曲线。
很容易看到通常如果ReLu层变换的输出有一个非零值S,那么被映射到S的点都是对输入经过一个线性变换B之后获得,从而表明对应整个维数的输出部分输入空间被限制在为一个线性变换。换句话说,深度网络只对输出域部分的非零值上应用一个线性分类器。我们应用一个补充材料来更加详细的正式描述。
另一方面,当没有ReLU作用通道时,那必然失去了那个通道的信息。然而,如果我们通道数非常多时,可能在激活流形中有一个结构,其信息仍然被保存在其他的通道中。在补充材料中,我们展示了如果输入流形能嵌入到一个显著低维激活子空间中,那么ReLU激活函数能够保留这个信息同时将所需的复杂度引入到表达函数集合中。
总的来说,我们已经强调了两个性质,它们表明了感兴趣的流形应该存在于高维激活空间中的一个低维子空间中的要求。
1. 如果感兴趣流形在ReLU之后保持非零值,那么它对应到一个线性变换。
2. ReLU能够保存输入流形的完整信息,但是输入流形必须存在于输入空间的一个低维子空间中。
这两点为我们优化现有神经网络提供了经验性的提示:假设感兴趣流形是低维的,我们能够通过插入线性瓶颈层到卷积块中来得到它。经验性的证据表明使用线性层是非常重要的,因为其阻止了非线性破坏了太多的信息。在第6节中,我们展示了经验性的在瓶颈中使用非线性层确实使得性能下降了几个百分点,这更加进一步的验证了我们的假设。我们注意到有类似的实验在(Deep pyramidal residual networks.)中,即传统的残差块的输入中去掉非线性结果提升了在CIFAR数据集的性能。
论文的接下来部分,我们将利用瓶颈卷积,我们将输入瓶颈尺寸和内部尺寸的比值称为扩展率。

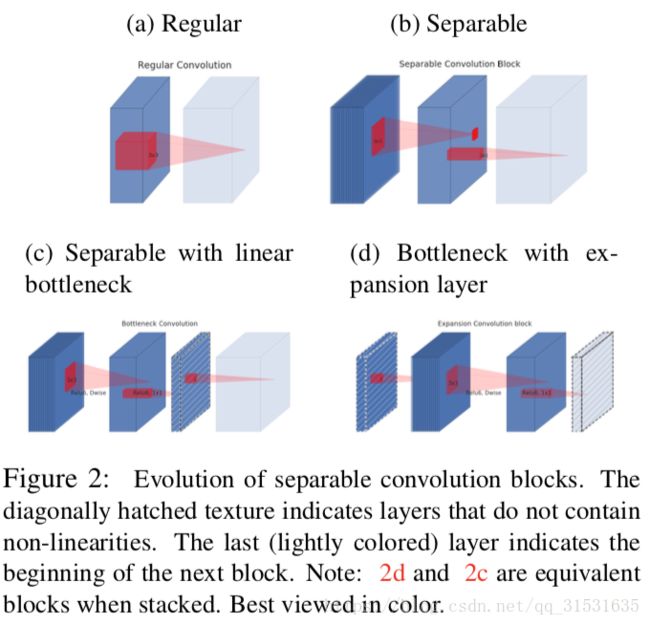
3.3 反向残差(Inverted residuals)
瓶颈块看起来与残差块相同,每个块包含一个输入接几个瓶颈然后进行扩展。然而,受到直觉的启发,瓶颈层实际上包含了所有必要的信息,同时一个扩展层仅仅充当实现张量非线性变换的实现细节部分,我们直接在瓶颈层之间运用shortcuts,图3提供了一个设计上差异的可视化。插入shortcuts的动机与典型的残差连接相同,我们想要提升在多层之间梯度传播的能力,然而,反向设计能够提高内存效率(第五节详细描述)以及在我们的实验中变现的更好一点。

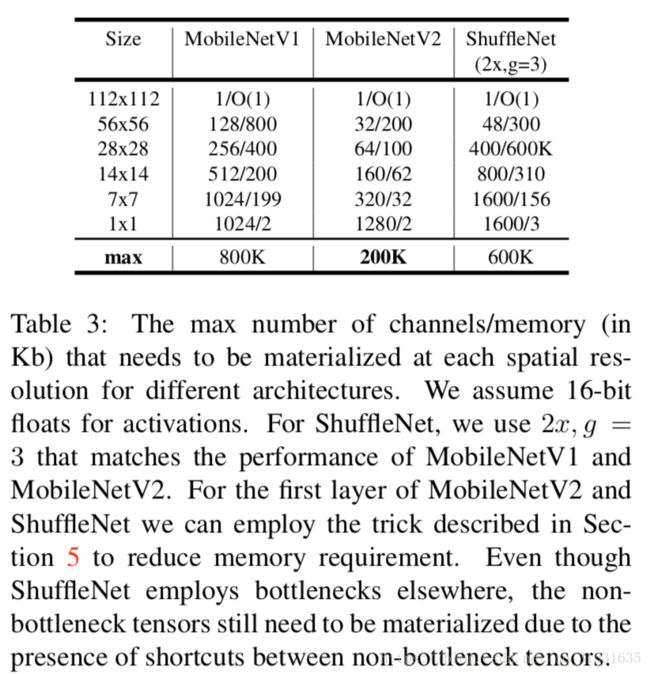
瓶颈层的运行时间和参数量,基本的实现结构在表1中体现。对于一个大小为hxw的块,扩展因子t和卷积核大小k,输入通道数为 d′ d ′ ,输出通道数为 d′′ d ′ ′ ,那么乘加运算有 h∗w∗d′∗t(d′+k2+d′′) h ∗ w ∗ d ′ ∗ t ( d ′ + k 2 + d ′ ′ ) 。与之前的计算量比较,这个表达式多出了一项,因为我们有额外的1x1卷积,然而我们的网络性质允许我们利用更小的输入和输出的维数。在表3中我们比较了不同分辨率下MobileNetV1、MobileNetV2、ShuffleNet所需要的尺寸大小。

3.4 信息流解释
我们结构的一个特性在于构建块(瓶颈层)的输入输出域之间提供一个自然分离,并且层变换—这是一种输入到输出之间的非线性函数。前者能看成是网络每层的容量,而后者看作是网络的表达能力。这与传统卷积块相反,传统卷积块的正则化和可分离性,在表达能力和容量上都结合在一起,是输出层深度的函数。
特别地,在我们的例子中,当内层深度为0时,下面层卷积由于shortcuts变成了恒等函数。当扩展率小于1时,这就变成了一个经典的残差卷积块。然而,为了我们的目的,当扩展率大于1时是最有效的。
这个解释允许我们从网络的容量来研究网络的表达能力,而且我们相信对可分离性更进一步探索能够保证对网络的性质理解更加深刻。
4 模型结构
现在我们详细的描述我们的模型结构。就像掐面提到的一样,基本的构建块是残差瓶颈深度可分离卷积块,块的详细结构在表1中可以看到。MobileNetV2包含初始的的32个卷积核的全卷积层,后接19个残差瓶颈层(如表2),我们使用ReLU6作为非线性激活函数,用于低精度计算时,ReLU6激活函数更加鲁棒。我们总使用大小为3x3的卷积核,并且在训练时候利用dropout和batchnorm规范化。
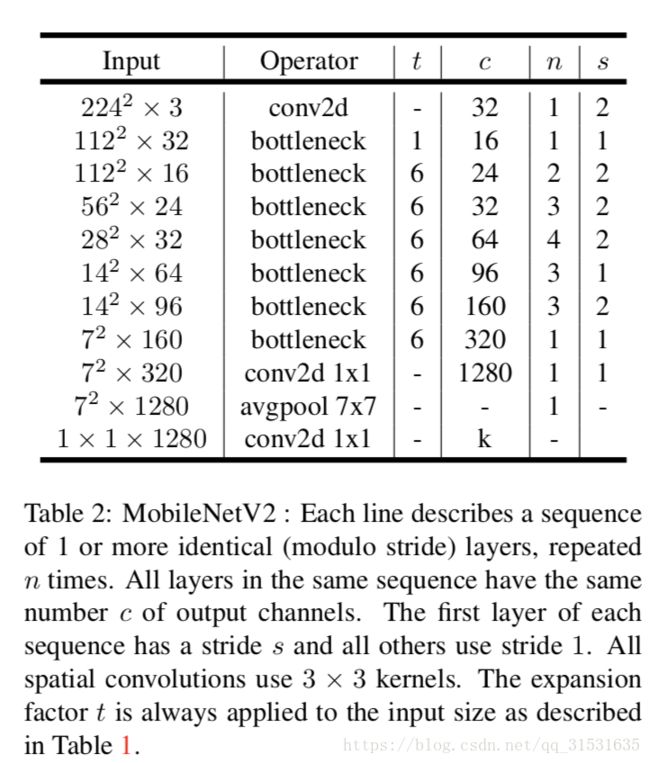
除开第一层之外,我们在整个网络中使用常数扩展率。在我们的实验中,我们发现扩展率在5~10之间几乎有着相同的性能曲线。随着网络规模的缩小,扩展率略微降低效果更好,而大型网络有更大的扩展率,性能更佳。
我们主要的实验部分来说,我们使用扩展率为6应用在输入张量中。比如,对于一个瓶颈层来说,输入为64通道的张量,产生一个128维的张量,内部扩展层就是64x6=384通道。
权衡超参数 就像MobileNetV1中一样,我们对于不同的性能要求制定不同的结构。通过使用输入图像分辨率以及可调整的宽度乘法器超参数来根据期望的准确率/性能折衷来进行调整。我们先前的工作(宽度乘法器,1,224x224),有大约3亿的乘加计算量以及使用了340万的参数量。我们探索对于输入分辨率从96至224,宽度乘法器从0.35至1.4来探索性能的权衡。网络计算量从7变成了585MMAds,同时模型的尺寸变化影响参数量从1.7M到6.9M。
与MobileNetV1实现小小不同的是,MobileNetV1的宽度乘法器的取值小于1,除了最后一层卷积层,我们对所有层都运用了宽度乘法器,这对于小模型提升了性能。
5 执行记录
5.1 内存有效管理
反向残差瓶颈层允许一个特别的内存有效管理方式,这对于移动应用来说非常重要。一个标准有效的管理比如说Tensorflow或者Caffe,构建一个有向无环计算超图G,由表示操作的边和表示内部计算的张量构成。为了最小化需要存储在内存中的张量数,计算是按顺序进行的。在最一般的情况下,其搜索所有可能的计算顺序 ∑(G) ∑ ( G ) ,然后选能够最小化下式的顺序。 M(G)=minπ∈∑(G)maxi∈1..n[∑A∈Ri,π,G|A|]+size(πi) M ( G ) = m i n π ∈ ∑ ( G ) m a x i ∈ 1.. n [ ∑ A ∈ R i , π , G | A | ] + s i z e ( π i ) ,其中 R(i,π,G) R ( i , π , G ) 是与任意点{ πi...πn π i . . . π n }相连接的中间张量列表。|A|表示张量A的模,size(i)表示i操作期间,内部存储所需要的内存总数。
对于只有不重要的并行结构的图(如残差连接),只有一个重要可行的计算顺序,因此在测试时所需要的总的内存在计算图G中可以简化为: M(G)=maxop∈G[∑A∈opinp|A|+∑B∈opout|B|+|op|] M ( G ) = m a x o p ∈ G [ ∑ A ∈ o p i n p | A | + ∑ B ∈ o p o u t | B | + | o p | ] 。所有操作中,内存量只是结合输入和输出的最大总的大小。在下文中,我们展示了如果我们将一个瓶颈残差块看作一个单一操作(并且将内部卷积看作一个一次性的张量),总的内存量将会由瓶颈张量的大小决定,而不是瓶颈内部的张量大小决定(这可能会更大)
瓶颈残差块一个瓶颈块操作F(x)如图3b,可以看作由三个操作组成: F(x)=[A⋅N⋅B]x F ( x ) = [ A ⋅ N ⋅ B ] x ,其中A是线性变换: Rs∗s∗k R s ∗ s ∗ k -> Rs∗s∗n R s ∗ s ∗ n ,N是非线性变换: Rs∗s∗n R s ∗ s ∗ n -> Rs′∗s′∗n R s ′ ∗ s ′ ∗ n ,B也是一个线性变换 Rs′∗s′∗n R s ′ ∗ s ′ ∗ n -> Rs′∗s′∗k′ R s ′ ∗ s ′ ∗ k ′ 。
对我们的网络来说, N=ReLU6⋅dwise⋅ReLU6 N = R e L U 6 ⋅ d w i s e ⋅ R e L U 6 ,但是其结果应用于任意单通道转换。假定输入尺寸大小为|x|,输入尺寸大小为|y|,那么计算F(X)的内存计算要求能变成和 |s2k|+|s′2k′|+O(max(s2,s′2)) | s 2 k | + | s ′ 2 k ′ | + O ( m a x ( s 2 , s ′ 2 ) ) 。
算法基于内部张量I能够被表示为t个张量的串联结合,即每个t张量的尺寸为n/t,那么我们的公式能表示为 F(x)=∑ti=1(Ai⋅B⋅Bi)(x) F ( x ) = ∑ i = 1 t ( A i ⋅ B ⋅ B i ) ( x ) ,通过求和,我们只要求中间块的尺寸n/t一直在内存中保存,使用n=t时,则我们只需要在所有时候保存中间表达过程的单通道。使用这个技巧有两个约束条件
(1)包含非线性和depthwise的内部转换是单通道的。
(2)连续结合的操作(非单通道)对于输出来说输出尺寸占了很大的比例。
对于大多数传统神经网络而言,这个技巧将不会产生很大的提升。
我们注意到,使用t路分离需要计算F(x)的乘加操作的数量和t是独立。然而在已有的实现中我们发现利用少数小的集合来代替一个矩阵乘法的做法对运行时间性能是不利的,因为造成了缓存的丢失。我们发现这个方法对于使用t(2~5之间)是最有用的。这有效的节省了内存空间,但是仍然通过优化矩阵乘法和卷积操作能得到最大的效率。因此特殊框架水平的优化可能会导致运行时间更近一步的提升优化。

6 实验
6.1 ImageNet分类
训练设置我们利用Tensorflow训练模型,使用标准的RMSProp优化方法,并且衰减率和动量都设置为0.9。我们在每一层之后都使用batch normalization,标准的权重衰减设置为0.00004。接着MobileNetV1的设置,我们使用初始学习率为0.045,学习率衰减为每个epoch衰减0.98.我们使用16个GPU异步工作器并且使用96作为batch size。
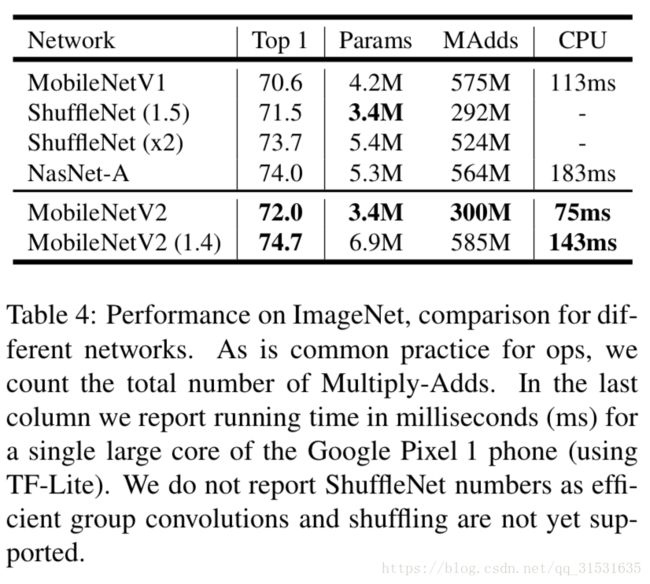
结果我们与MobileNetV1、ShuffleNet、NASNet-A模型进行比较,几个模型的统计数据如表4。性能的比较在图5中。

6.2 目标检测
6.3 语义分割
6.4 模型简化测试(Ablation study)
7 结论和未来工作
我们描述了一个非常简单的网络结构,允许我们能够构建一个高效的移动端模型。我们的基础构建单元有一个特殊的属性使得其更加适合移动应用。其能实现内存管理更加高效并且能在所有神经框架上的标准操作来实现。
对于ImgeNet数据集,我们的结构对于性能点的广泛范围提升到了最好的水平。
对于目标检测任务,就COCO数据集上的准确率和模型复杂度而言,我们的网络优于最好的实时检测器模型。尤其,我们的模型与SSDLite检测模块结合,相较于YOLOV3而言,计算量少了20多倍,参数量少了10多倍。
理论层面,提出的卷积块有一个独一无二的性质,即从网络的容量(由瓶颈输入进行编码)中分离出网络的表达能力(对扩展层进行编码),探索这个是未来研究的一个重要的方向。