Android常见面试题&字节跳动、阿里、腾讯2019实习生Android岗部分面试题
本文首发于github,由于篇幅较长,建议大家收藏后有时间慢慢阅读,如果文中有什么不正确的地方,可以在github上提出issue,或者直接发起pr,我会及时反馈纠正。
想要获取原文文稿(markdown格式),可关注左边栏二维码所示公众号,公众号内回复"A5"即可自动获取。
文章目录
- 什么是ANR,如何避免
- 主线程中的Looper.loop()一直无限循环为什么不会造成ANR?
- ListView原理与优化
- ContentProvider实现原理
- 如何使用ContentProvider进行批量操作?
- 为什么要使用通过`ContentResolver`类从而与`ContentProvider`类进行交互,而不直接访问`ContentProvider`类?
- 介绍Binder机制
- 如何自定义View,如果要实现一个转盘圆形的View,需要重写View中的哪些方法?
- Android事件分发机制
- 如何加载大图片
- 布局文件中,layout_gravity 和 gravity 以及 weight的作用。
- ListView里的ViewType机制
- TextView怎么改变局部颜色
- Activity A 跳转到 Activity B,生命周期的执行过程是啥?
- Android中Handler声明非静态对象会发出警告,为什么非得是静态的?
- ListView使用过程中是否可以调用addView
- 属性动画(Property Animation)和补间动画(Tween Animation)的区别,为什么在3.0之后引入属性动画
- 有没有使用过EventBus或者Otto框架,主要用来解决什么问题,内部原理
- Android里的LRU(Least Recently Used 最近最少使用)算法原理
- Service onBindService 和startService 启动的区别
- invalidate()和postInvalidate() 的区别
- 导入外部数据库
- Parcelable和Serializable区别
- 在两个 Activity 之间传递对象还需要注意什么呢?
- Android里跨进程传递数据的几种方案
- 匿名共享内存,使用场景
- Application类的作用
- 广播注册后不解除注册会有什么问题?(内存泄露)
- 属性动画(Property Animation)和补间动画(Tween Animation)的区别
- BrocastReceive里面可不可以执行耗时操作?
- Android优化工具
- TraceView
- Systrace
- Android动态权限?
- ViewPager如何判断左右滑动?
- ListView与RecyclerView
- SpannableString
- APK安装过程
- 描述一下Android手机启动过程和App启动过程?
- Android手机启动过程
- App启动过程
- Include、Merge、ViewStub的作用
- Asset目录与res目录的区别
- System.gc && Runtime.gc
- Application 在多进程下会多次调用 onCreate() 么?
- Theme && Style
- SQLiteOpenHelper.onCreate() 调用时机?
- Removecallback 失效?
- Toast 如果会短时间内频繁显示怎么优化?
- Notification 如何优化?
- 应用怎么判断自己是处于前台还是后台?
- FragmentPagerAdapter 和 FragmentStateAdapter 的区别?
- Bitmap的本质?
- SurfaceView && View && GLSurfaceView
- 请简述一下你对fragment的理解?
- 请简述一下Fragment的生命周期?
- LayoutInflater,LayoutInflater.inflate()这两个是什么意思?
- Android的多渠道打包你了解吗
- 如何对APK瘦身?
- Android当前应用跳转到三方应用
- JVM、ART、Dalvik的区别和联系
- Android中的classLoader相比java中的classLoader有什么区别?
- Socket和LocalSocket
- HttpClient和URLConnection的区别,怎么使用https
- 设计一个网络请求框架(可以参考Volley框架)
- 网络图片加载框架(可以参考BitmapFun)
- 字节跳动Android岗面试题
- java的classloader工作原理
- 开发过程中常见的内存泄漏都有哪些
- 关于JVM内存管理的一些建议
- LeakCanary的工作原理,java gc是如何回收对象的,可以作为gc根节点的对象有哪些?
- LeakCanary原理
- java gc是如何回收对象的
- 可以作为gc根节点的对象有哪些
- 既然有GC机制,为什么还会有内存泄露的情
- jvm的内存模型是什么样的?如何理解java的虚函数表?
- 如何从一百万个数里面找到最小的一百个数,考虑算法的时间复杂度和空间复杂度。
- 安卓的app加固如何做。
- mvp和mvc的主要区别是什么?为什么mvp要比mvc好。
- 安卓的混淆原理是什么?
- 如何设计一个安卓的画图库,做到对扩展开放,对修改封闭,同时又保持独立性。
- 网络优化的方案
- APP的性能优化经验
- 布局优化
- 图片的优化
- 其他优化
- 死锁的概念,怎么避免死锁
- App启动崩溃异常捕捉
- new Message和obtainMessage的区别
- ReentrantLock 、synchronized和volatile(n面)
- 用到的一些开源框架,介绍一个看过源码的,内部实现过程。
- 消息机制实现
- ReentrantLock的内部实现
- 断点续传的实现&设计一个下载器
- TreeMap具体实现
- Android的多点触控如何传递
- onTouchEvent()、onTouch()、onClick()、onLongClick()的先后顺序
- 前台切换到后台,然后再回到前台,Activity生命周期回调方法。弹出Dialog,生命值周期回调方法。
- 企业级产品中apk的大小至关重要,请提出不少于5个方案,如何缩减apk包大小
- SDK设计
- 简述Activity、Window、WindowManager、WindowManagerImpl、View、ViewRootImpl的作用和相互之间的关系。
- APP路由设计
- 列表卡顿怎么优化?首先卡顿怎么量化;其次怎么发现造成卡顿的原因;针对可能发现的问题,又如何解决?请设计一套方案。
- 插件化 组件化 热修复
- 为什么android中方法数最多只能有64k=65532个?
- 接口和抽象类的区别
- 怎样做系统调度。
- 简述Android的View绘制流程,Android的wrap_content是如何计算的。
- 数组实现队列。
- HashMap
- singleTask启动模式
- 集合的接口和具体实现类,介绍
- synchronized与ReentrantLock
- 重要:手写生产者/消费者模式、单例模式
- 逻辑地址与物理地址,为什么使用逻辑地址
- 一个无序,不重复数组,输出N个元素,使得N个元素的和相加为M,给出时间复杂度、空间复杂度。手写算法
- Android进程分类
- Activity的启动模式
- 有了解过注解么?(了解过,注释是给人看的,注解给机器看的,override,压制警告之类的)
- 自定义注解?(@interface) 具体的实现原理(不知道) 源代码阶段还是编译时还是运行时(我说编译时,好像不对?)
- 消息机制实现
- ReentrantLock的内部实现
- 二叉树,给出根节点和目标节点,找出从根节点到目标节点的路径。手写算法
- 断点续传的实现
- 逻辑地址与物理地址,为什么使用逻辑地址
- 前台切换到后台,然后再回到前台,Activity生命周期回调方法。弹出Dialog,生命值周期回调方法。
- AIDL的基本流程(如何实现AIDL),不用AIDL是否可以实现进程间通讯,用什么,如何实现
- 19年面试真题
- Thread、Process的区别(字节跳动-抖音-一面)
- singleThreadpool什么场景下使用,只有一个线程为什么不直接使用new Thread()(字节跳动-抖音-一面)
- TCP三次握手、四次挥手(字节跳动-抖音-一面、二面)
- 三次握手
- 四次挥手
- 计算机网络为什么是三次握手不是两次握手?请求方式(post、get)是放在哪个部分发送出去的(考察http协议的格式)(字节跳动-抖音-一面)?
- HTTP协议的格式
- HTTP请求
- HTTP响应
- 【算法】二叉树中序遍历(字节跳动-抖音-一面)
- 【算法】判断平衡二叉树(字节跳动-抖音-二面)
- Px、dp、sp的区别(字节跳动-抖音-二面)
- **DP**
- dip:
- px:
- sp:
- 为啥 标准dpi = 160
- java中有哪几种变量修饰符,有什么区别,protected是否是包级可见的(字节跳动-抖音-二面)
- synchronized对普通方法、静态方法加锁有什么区别(字节跳动-抖音-二面)
- Activity启动模式的解释(字节跳动-抖音-二面)
- java中保持线程同步的方式(考察锁)(字节跳动-抖音-二面)
- java的四种引用(字节跳动-抖音-二面)
- kotlin和java比的异同点(字节跳动-抖音-二面)
- okHttp源码理解(字节跳动-抖音-二面,腾讯-微信-一面)
- 数据库索引、事物的概念(字节跳动-抖音-三面Leader面)
- 关系型数据库中的主键是什么(字节跳动-抖音-三面Leader面)
- SQL语句的基本结构(字节跳动-抖音-三面Leader面)
- java里面有没有类似c 的析构函数的东西(字节跳动-抖音-三面Leader面)
- c 中参数传递有哪几种方式?java呢?(字节跳动-抖音-三面Leader面)
- c 和java有什么区别?(字节跳动-抖音-三面Leader面)
- Android中除了线程池还有哪些多线程的实现方式?(字节跳动-抖音-三面Leader面)
- AsyncTask是否可以异步?为什么?有没有看过AsyncTask的源码?(字节跳动-抖音-三面Leader面)
- 介绍一下http协议(字节跳动-抖音-三面Leader面)
- http各个状态码的意义(字节跳动-抖音-三面Leader面)
- 计算机网络中的重定向是什么(字节跳动-抖音-三面Leader面)
- 【算法】DFS考察
- android中如何计算当前view的子view的数量?(字节跳动-抖音-四面)
- okhttp中连接池的最大数量,连接池的实现原理(腾讯-微信-一面)
- 有两个View:view1和view2,view2在view1上面且比view1小,如何判断点击view1之内的屏幕是应该由view1处理事件还是由view2处理(腾讯-微信-一面)
- NDK是否可以加载任意目录下的so文件,so文件有几种加载方式(腾讯-微信-一面)
- ndk加载so时如何考虑32位和64位的不同,如何考虑不同的arm平台(腾讯-微信-一面)
- 自定义view的方法,为什么在ondraw中绘制即可产生相应效果,什么时候使用自定义view什么时候使用原生view(腾讯-微信-一面)
- sqlite是不是线程同步的(腾讯-微信-一面)
- 有没有对比过flutter和其他跨平台方案有什么异同点(腾讯-微信-一面)
- Android中如何自己实现跨线程的通信(蚂蚁金服-支付宝-一面)
- Android中的synchronized和reentrantLock有什么区别(蚂蚁金服-支付宝-一面)
- 一个线程中可以有几个handler?几个Looper?几个messageQueue?(蚂蚁金服-支付宝-一面)
- Handler机制介绍(蚂蚁金服-支付宝-一面)
- AsyncTask原理介绍,其实串行的还是并行的?如何进行并行操作?(蚂蚁金服-支付宝-一面)
- 数据库如何短时间高效批量插入数据?(蚂蚁金服-支付宝-一面)
- java静态方法是否可以被重写(蚂蚁金服-支付宝-一面)
- 静态内部类和非静态内部类的区别(蚂蚁金服-支付宝-一面)
- 使用fragment有什么好处?(蚂蚁金服-支付宝-一面)
- 有没有使用过嵌套Fragment?(蚂蚁金服-支付宝-一面)
- handler.postDelayed中的run是工作在主线程还是子线程(蚂蚁金服-支付宝-一面)
- Android中的内存管理(蚂蚁金服-支付宝-一面)
- 分配机制
- 回收机制
- 为什么App要符合内存管理机制?
- 如何编写符合Android内存管理机制的App?
- 开发时,应该如何注意App的内存管理呢?
- ArrayList和LinkedList的区别?各自的使用场景?(蚂蚁金服-支付宝-一面)
- Java gc机制介绍(蚂蚁金服-支付宝-一面)
- 如何对APK瘦身?(腾讯-音视频实验室-一面)
- java和c/c 在编译运行上有什么异同点?(腾讯-音视频实验室-一面)
- String类为什么具有不可变性?其如何实现不可变性的?
- String是object的子类,那么String[]是不是Object的子类?为什么?
- 自定义View的流程?
- 屏幕上有view1 view2 view3,其绘制流程?测量传参的形式是什么?
- 如何实现一个圆,其下四分之一加上蒙层的效果?(path)
- 在AThread中调用BThread.sleep(),休眠的是哪个线程?
- java中类的某些成员变量没有被用到,是否可以随意删除?
- NDK中的局部变量如果不手动释放一定没问题吗?
- 链表的反转
- 20亿个qq号码,如何判断其中是否存在某一个?
- ndk中的external c有什么用?
- ndk中的attachCurrentThread有什么用?
- invalidate()和postInvalidate() 以及requestLayout()的区别
什么是ANR,如何避免
ANR的全称是Application Not Responsing,即我们俗称的应用无响应。
要想知道如何避免ANR,就有必要了解哪些情况下会导致ANR
发生ANR的原因:
- 当前的事件没有机会得到处理(即主线程正在处理前一个事件,没有及时的完成或者looper被某种原因阻塞住了)
- 当前的事件正在处理,但没有及时完成
常见的以下几种情况都会导致ANR:
- 主线程中被IO操作(从Android4.0以后不允许网络IO操作在主线程中)
- 主线程中存在耗时操作
- 主线程中存在错误操作,比如Thread.wait或者Thread.sleep
Android系统会监控程序的响应情况,一旦出现以下三种情况就会弹出ANR对话框:
- View的点击事件或者触摸事件在5s内无法得到响应。
- BroadcastReceiver的onReceive()函数运行在主线程中,在10s内无法完成处理。
- Service的各个生命周期函数在20s内无法完成处理。
那么对应的避免ANR的基本思路就是避免IO操作在主线程中,避免在主线程中进行耗时操作,避免主线程中的错误操作等,具体的方法有如下几种:
- 使用AsyncTask处理耗时IO操作
- 使用Handler处理线程处理结果,而不是使用Thread.sleep或者Thread.wait来堵塞线程
- Activity的onCreat和onResume方法中尽量避免进行耗时操作
- BroadcastReceiver中的onReceive中也应该避免耗时操作,建议使用intentService处理
主线程中的Looper.loop()一直无限循环为什么不会造成ANR?
ActivityThread.java 是主线程入口的类,这里你可以看到写Java程序中司空见惯的main方法,而main方法正是整个Java程序的入口:
public static final void main(String[] args) {
...
//创建Looper和MessageQueue
Looper.prepareMainLooper();
...
//轮询器开始轮询
Looper.loop();
...
}
Looper.loop()方法:
while (true) {
//取出消息队列的消息,可能会阻塞
Message msg = queue.next(); // might block
...
//解析消息,分发消息
msg.target.dispatchMessage(msg);
...
}
显而易见的,如果main方法中没有looper进行循环,那么主线程一运行完毕就会退出。
所以ActivityThread的main方法主要就是做消息循环,一旦退出消息循环,那么你的应用也就退出了。
因为Android 的是由事件驱动的,looper.loop() 不断地接收事件、处理事件,每一个点击触摸或者说Activity的生命周期都是运行在 Looper.loop() 的控制之下,如果它停止了,应用也就停止了。只能是某一个消息或者说对消息的处理阻塞了 Looper.loop(),而不是 Looper.loop() 阻塞它。
也就说我们的代码其实就是在这个循环里面去执行的,当然不会阻塞了。
handleMessage方法部分源码:
public void handleMessage(Message msg) {
if (DEBUG_MESSAGES) Slog.v(TAG, ">>> handling: " codeToString(msg.what));
switch (msg.what) {
case LAUNCH_ACTIVITY: {
Trace.traceBegin(Trace.TRACE_TAG_ACTIVITY_MANAGER, "activityStart");
final ActivityClientRecord r = (ActivityClientRecord) msg.obj;
r.packageInfo = getPackageInfoNoCheck(r.activityInfo.applicationInfo, r.compatInfo);
handleLaunchActivity(r, null);
Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER);
}
break;
case RELAUNCH_ACTIVITY: {
Trace.traceBegin(Trace.TRACE_TAG_ACTIVITY_MANAGER, "activityRestart");
ActivityClientRecord r = (ActivityClientRecord) msg.obj;
handleRelaunchActivity(r);
Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER);
}
break;
case PAUSE_ACTIVITY:
Trace.traceBegin(Trace.TRACE_TAG_ACTIVITY_MANAGER, "activityPause");
handlePauseActivity((IBinder) msg.obj, false, (msg.arg1 & 1) != 0, msg.arg2, (msg.arg1 & 2) != 0);
maybeSnapshot();
Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER);
break;
case PAUSE_ACTIVITY_FINISHING:
Trace.traceBegin(Trace.TRACE_TAG_ACTIVITY_MANAGER, "activityPause");
handlePauseActivity((IBinder) msg.obj, true, (msg.arg1 & 1) != 0, msg.arg2, (msg.arg1 & 1) != 0);
Trace.traceEnd(Trace.TRACE_TAG_ACTIVITY_MANAGER);
break;
...........
}
}
可以看见Activity的生命周期都是依靠主线程的Looper.loop,当收到不同Message时则采用相应措施。
如果某个消息处理时间过长,比如你在onCreate(),onResume()里面处理耗时操作,那么下一次的消息比如用户的点击事件不能处理了,整个循环就会产生卡顿,时间一长就成了ANR。
让我们再看一遍造成ANR的原因,你可能就懂了。
造成ANR的原因一般有两种:
- 当前的事件没有机会得到处理(即主线程正在处理前一个事件,没有及时的完成或者looper被某种原因阻塞住了)
- 当前的事件正在处理,但没有及时完成
而且主线程Looper从消息队列读取消息,当读完所有消息时,主线程阻塞。子线程往消息队列发送消息,并且往管道文件写数据,主线程即被唤醒,从管道文件读取数据,主线程被唤醒只是为了读取消息,当消息读取完毕,再次睡眠。因此loop的循环并不会对CPU性能有过多的消耗。
总结:Looer.loop()方法可能会引起主线程的阻塞,但只要它的消息循环没有被阻塞,能一直处理事件就不会产生ANR异常。
ListView原理与优化
ListView最大的优点就是在于即使在ListView中加载非常非常多的数据,比如达到成百上千条甚至更多,ListView都不会发生OOM或者崩溃,而且随着我们手指滑动来浏览更多数据时,程序所占用的内存竟然都不会跟着增长。
而实现这种效果的原理也十分简单,就是基于Recycle机制,比如现在listview有10w个条项,那么它不会同时把这10w个条项同时加载进来,而是只讲用户可见的若干个条项加载进来,而且会进行循环利用,比如用户当前划出了一个view1,与此同时进来了一个view2,那么当view1划出可见区的同时它会被标记为recycle,这样做的好处是当新进入的view2与view1类型相同的时候getView方法传入的contentView就不是null而是view1,否则会传入null,此时需要new一个View,当内存紧张的时候View1就会被GC。这就是Listview的大概原理。
补充的一点是Adapter在listview中的作用,view负责的是将数据展示出来,而adapter负责的就是把数据加载进来,其指挥了ListView的数据加载行为,二者的关系类似于mvc中的v和c。
而listview的优化主要是在缓存上采取处理,listview的优化分为三级缓存:
- 内存缓存
- 文件缓存
- 网络加载
以listview加载Bitmap为例:
比如一个10w个条目的listview,每个item中都有一张照片,不同item的照片可能相同,那么优化的策略是在getview中,如果需要加载一张照片,先从MemoryCache中去找,如果找不到就去文件系统中找,如果文件系统中还找不到再从网络加载,同时从网络上加载完之后应把当前图片进行缓存,机制是首先考虑放入map类型的MemoryCache中,如果内存不够了不能放入内存中了,则给该图片打上TAG存入文件系统中,这样下次需要加载该图片的时候就可以从之前的缓存中加载出来。
同时有几个细节需要注意:
- 从文件中加载虽然比从网络加载快,但是比从内存中加载慢,所以应该设立busy位,当listview处于滚动状态时停止加载,这样可以环节listview的滚动卡顿问题(如何判断listview当前是否是滚动状态:通过setOnScrollListener?)
- 应该在子线程中加载图片,防止listview变卡
- 开启网络等耗时操作应该开启新的线程,应使用线程池避免资源浪费,最起码也应该使用AsyncTask
- 从网络加载的Bitmap最好先缓存入文件系统,这样做既可以方便下次加载时直接通过Url加载到,也可以方便在加载时使用Option.inSampleSize配合Bitmap.decodeFile进行内存压缩
ContentProvider实现原理
ContentProvider的底层是采用 Android中的Binder机制,既然已经有了binder实现了进程间通信了为什么还会需要contentProvider?
contentprovider是一种进程间数据交互&共享的方式,当然它也可以进行进程内通信,但是一般不会“杀鸡用牛刀”用contentProvider作为进程内通信的方式。Android系统中,每一个应用程序只可以访问自己创建的数据。然而,有时候我们需要在不同的应用程序之间进行数据共享,例如很多程序都需要访问通讯录中的联系人信息来实现自己的业务功能。由于通讯录本身是一个独立的应用程序,因此,其他应用程序是不能直接访问它的联系人信息的,这时候就需要使用Content Provider组件来共享通讯录中的联系人信息了。从垂直的方向来看,一个软件平台至少由数据层、数据访问层、业务层构成。在Android系统中,数据层可以使用数据库、文件或者网络来实现,业务层可以使用一系列应用来实现,而数据访问层可以使用Content Provider组件来实现。在这个软件平台架构中,为了降低业务层中各个应用之间的耦合度,每一个应用都使用一个Android应用程序来实现,并且它们都是运行在独立的进程中。同样,为了降低业务层和数据层的耦合度,我们也将数据访问层即Content Provider组件运行在一个独立的应用程序进程中。通过这样的划分,Content Provider组件就可以按照自己的方式来管理平台数据,而上层的Android应用程序不需要关心它的具体实现,只要和它约定好数据访问接口就行了。
不同的应用程序进程可以通过Binder进程间通信的机制来通信,但如果在传输的数据量很大的时候,直接使用Binder进程间通信机制传递数据,那么数据传输效率就会成为问题。不同的应用程序进程可以通过匿名共享内存来传输大数据,因为无论多大的数据,对匿名共享内存来说,需要在进程间传递的仅仅是一个文件描述符而已。这样,结合Binder进程间通信机制以及匿名共享内存机制,Content Provider组件就可以高效地将它里面的数据传递给业务层中的Android应用程序访问了。
比如应用A想要暴露一部分数据给其他的应用操作,那么我们可以在应用A中自定义一个继承了contentProvider抽象类 的类,选择性重写其insert(增)、delete(删)、update(改)、Cursor query(查)以暴露出数据访问的接口给其他应用,然后在manifest文件中注册该contentProvider,注册的时候指定authorities,该authorities应该是全局唯一的,同时在manifest中声明一下权限,这样就完成了应用A中提供数据访问接口的工作,那么对于另外一个应用B如果想要操作A应用暴露出的数据,首先需要在manifest中声明一下权限,然后需要在其Activity中使用getContentResolver()方法获取一个contentResolver对象,该对象可以调用insert(增)、delete(删)、update(改)、Cursor query(查)四个方法,每个方法需要传入一个Uri参数,因为只有指定了Uri,该contentRecover才知道应该去访问哪一个contentProvider提供的数据访问接口,Uri的格式是固定的,一般格式是Uri uri_user = Uri.parse(“content://authorities/表名/记录”),这样就实现了B访问A中的数据即跨进程通信。
ContentProvider 有以下两个特点:
- 封装:对数据进行封装,提供统一的接口,使用者完全不必关心这些数据是在DB,XML、Preferences或者网络请求来的。当项目需求要改变数据来源时,使用我们的地方完全不需要修改。
- 提供一种跨进程数据共享的方式。
Content Provider组件在不同应用程序之间传输数据是基于匿名共享内存机制来实现的。其主要的调用过程:
- 通过ContentResolver先查找对应给定Uri的ContentProvider,返回对应的
BinderProxy
- 如果该Provider尚未被调用进程使用过:
- 通过
ServiceManager查找activity service得到ActivityManagerService对应BinderProxy - 调用
BinderProxy的transcat方法发送GET_CONTENT_PROVIDER_TRANSACTION命令,得到对应ContentProvider的BinderProxy。
- 通过
- 如果该Provider已被调用进程使用过,则调用进程会保留使用过provider的HashMap。此时直接从此表查询即得。
- 调用
BinderProxy的query()
如何使用ContentProvider进行批量操作?
通常进行数据的批量操作我们都会使用“事务”,但是ContentProvider如何进行批量操作呢?创建 ContentProviderOperation 对象数组,然后使用 ContentResolver.applyBatch() 将其分派给内容提供程序。您需将内容提供程序的授权传递给此方法,而不是特定内容 URI。这样可使数组中的每个 ContentProviderOperation 对象都能适用于其他表。调用 ContentResolver.applyBatch() 会返回结果数组。
同时我们还可以通过ContentObserver对数据进行观察:
- 创建我们特定的
ContentObserver派生类,必须重载onChange()方法去处理回调后的功能实现 - 利用
context.getContentResolover()获得ContentResolove对象,接着调用registerContentObserver()方法去注册内容观察者,为指定的Uri注册一个ContentObserver派生类实例,当给定的Uri发生改变时,回调该实例对象去处理。 - 由于
ContentObserver的生命周期不同步于Activity和Service等,因此,在不需要时,需要手动的调用unregisterContentObserver()去取消注册。
为什么要使用通过ContentResolver类从而与ContentProvider类进行交互,而不直接访问ContentProvider类?
一般来说,一款应用要使用多个ContentProvider,若需要了解每个ContentProvider的不同实现从而再完成数据交互,操作成本高 & 难度大。所以再ContentProvider类上加多了一个 ContentResolver类对所有的ContentProvider进行统一管理。
介绍Binder机制
Binder是Android中的一种跨进程通信机制,Android是基于Linux的,所有的用户线程工作在不同的用户空间下,互相不能访问,但是他们都共享内核空间,所以传统的跨进程通信可以先从A进程的用户空间拷贝数据到内核空间,再将数据从内核空间拷贝到B进程的用户空间,这样做需要拷贝两次数据,效率太低,而Binder机制应用了内存映射的原理,其通过Binder驱动(位于内核空间)将A进程、B进程以及serviceManager连接起来,通过serviceManager来管理Service的注册与查询,在Android中Binder驱动和serviceManager都属于Android基础架构即Android系统已经帮我们实现好了,我们只需要自定义A进程和B进程,使其调用注册服务、获取服务&使用服务三个步骤即可。
如何自定义View,如果要实现一个转盘圆形的View,需要重写View中的哪些方法?
自定义View一般是继承View或者ViewGroup,然后重点是以下几个方法:
- 构造函数,这个方法的主要功能是获取view的基本参数,有四个不同参数列表的构造方法,我们一般只会用到前两种,第一种构造方法只有一个context参数,一般是使用java代码new出该view时会调用,第二种构造方法有一个context参数和一个AttributeSet参数,主要是在xml文件中使用到该view时会调用,通过AttributeSet参数获取到xml文件中定义的各种参数
- onMeasure,这个方法的主要作用是测量view的大小,而measure的执行过程也要分情况,如果是一个原始的View,只需要通过measure方法就可以完成,如果是一个ViewGroup,则除了完成自己的measure之外还需要遍历调用所有子view的measure方法
- onSizeChanged(int w, int h, int oldw, int oldh)方法,这个方法的作用是确定view的大小,虽然我们已经在onMeasure中测量到了view的大小,可是实际中view的大小不仅与自己有关,还与父View的大小有关,所以我们在确定View大小的时候最好使用系统提供的onSizeChanged回调函数。
- onLayout(boolean changed, int left, int top, int right, int bottom),一般如果是继承ViewGroup的话需要重写这个方法,做法是首先获取到各个子view,然后计算出各个子view的位置,再调用子view的layout(left, top, right, bottom)方法设置子view的位置
- onDraw(Canvas canvas) 方法,主要是根据自己的需求通过canvas进行绘制
Android事件分发机制
Android事件分发机制的对象是点击事件,本质是将点击事件(MotionEvent)传递到某个具体的View & 处理的整个过程,当用户触摸屏幕时将产生点击事件,而点击事件的相关细节被封装成MotionEvent对象,其对应的事件类型有4种:ACTION_DOWN、ACTION_UP、ACTION_MOVE、ACTION_CANCEL(非人为因素导致的结束事件),事件分发的顺序是Activity—>viewGroup—>View,其中涉及到三个主要的方法:dispatchTouchEvent、onInterceptTouchEvent、onTouchEvent,分别对应事件分发、事件拦截、事件响应,如果事件被分发给了当前view,则一定会调用该view的dispatchTouchEvent方法,在该方法中首先调用onInterceptTouchEvent方法判断当前view是否应该拦截该事件,如果确定当前View需要拦截该事件,则调用当前View的onTouchEvent进行事件响应,如果判断当前view不应该拦截该事件,则调用其子view的dispatchTouchEvent方法将该事件分发给其子View,以此类推。
ViewGroup默认不拦截任何事件。Android源码中ViewGroup的onInterceptTouchEvent方法默认返回false。
View没有onIntercepteTouchEvent方法,一旦有点击事件传递给它,那么它的onTouchEvent方法就会被调用。
如何加载大图片
当将一个图片加载到内存,在UI上呈现时,需要考虑一下几个因素:
- 预计加载完整张图片所需要的内存空间
- 呈现这张图片时控件的大小
- 屏幕大小与屏幕像素密度
如果我们要加载的图片的分辨率比较大,而呈现它的控件(比如ImageView)比较小,那我们如果直接将这张图片加载到这个控件上显然是不合适的,因此我们需要对图片的分辨率就行压缩。如何去进行图片的压缩呢?
BitmapFactory提供了四种解码(decode)的方法(decodeByteArray(), decodeFile(), decodeResource(),decodeStream()),每一种方法都可以通过BitmapFactory.Options设置一些附加的标记,以此来指定解码选项。
Options有一个inJustDecodeBunds属性,当我们将其设置为true时,表示此时并不加载Bitmap到内存中,而是返回一个null,但是此时我们可以通过options获取到当前bitmap的宽和高,根据这个宽和高,我们再根据目标宽和高计算出一个合适的采样率采样率inSampleSize ,然后将其赋值给Options.inSampleSize属性,这样在加载图片的时候,将会得到一个压缩的图片到内存中。以下是示例代码:
public static Bitmap decodeSampledBitmapFromResource(Resources res, int resId,
int reqWidth, int reqHeight) {
// 第一次加载时 将inJustDecodeBounds设置为true 表示不真正加载图片到内存
final BitmapFactory.Options options = new BitmapFactory.Options();
options.inJustDecodeBounds = true;
BitmapFactory.decodeResource(res, resId, options);
// 根据目标宽和高 以及当前图片的大小 计算出压缩比率
options.inSampleSize = calculateInSampleSize(options, reqWidth, reqHeight);
// 将inJustDecodeBounds设置为false 真正加载图片 然后根据压缩比率压缩图片 再去解码
options.inJustDecodeBounds = false;
return BitmapFactory.decodeResource(res, resId, options);
}
//计算压缩比率 android官方提供的算法
public static int calculateInSampleSize(
BitmapFactory.Options options, int reqWidth, int reqHeight) {
// Raw height and width of image
final int height = options.outHeight;
final int width = options.outWidth;
int inSampleSize = 1;
if (height > reqHeight || width > reqWidth) {
//将当前宽和高 分别减小一半
final int halfHeight = height / 2;
final int halfWidth = width / 2;
// Calculate the largest inSampleSize value that is a power of 2 and keeps both
// height and width larger than the requested height and width.
while ((halfHeight / inSampleSize) > reqHeight
&& (halfWidth / inSampleSize) > reqWidth) {
inSampleSize *= 2;
}
}
return inSampleSize;
}
采样率与图片分辨率压缩大小的关系是这样的:
- 如果inSample=1则表明与原图一样
- 如果inSample=2则表示宽和高均缩小为1/2
- nSample的值一般为2的幂次方
假如 一个分辨率为2048x1536的图片,如果设置 inSampleSize 为4,那么会产出一个大约512x384大小的Bitmap。加载这张缩小的图片仅仅使用大概0.75MB的内存,如果是加载完整尺寸的图片,那么大概需要花费12MB(前提都是Bitmap的配置是 ARGB_8888.
布局文件中,layout_gravity 和 gravity 以及 weight的作用。
android:gravity 是设置该view里面的内容相对于该view的位置,例如设置button里面的text相对于view的靠左,居中等位置。(也可以在Layout布局属性中添加,设置Layout中组件的位置)
android:layout_gravity 是用来设置该view相对与父view的位置,例如设置button在layout里面的相对位置:屏幕居中,水平居中等。
即android:gravity用于设置View中内容相对于View组件的对齐方式,而android:layout_gravity用于设置View组件相对于Container的对齐方式。
说的再直白点,就是android:gravity只对该组件内的东西有效,android:layout_gravity只对组件自身有效。
android:layout_gravity 只在 LinearLayout 和 FrameLayout 中有效
layout_weight:按屏幕剩余空间,按权重分配空间(权重、百分比布局)
ListView里的ViewType机制
当我们在Adapter中调用方法getView的时候,如果整个列表中的Item View如果有多种类型布局,如:
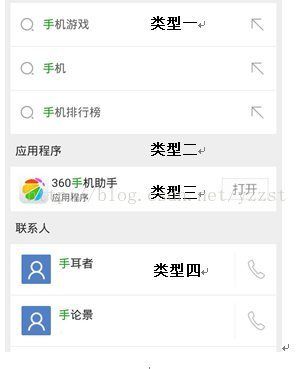
我们继续使用convertView来将数据从新填充貌似不可行了,因为每次返回的convertView类型都不一样,无法重用。
Android在设计上的时候,也想到了这点。所以,在adapter中预留的两个方法。
- public int getItemViewType(int position) ;
- public int getViewTypeCount();
只需要重写这两个方法,设置一下ItemViewType的个数和判断方法,然后在getView中获取到当前ViewType,然后通过不同的viewType解析不同的布局即可,而且Recycler还能有选择性的给出不同的convertView了。
TextView怎么改变局部颜色
Android提供了SpannableStringBuilder用来实现富文本的定制,或者也可以考虑使用HTML即写好HTML后使用tv.setText(Html.fromHtml(html))达到在TextView上显示Html的目的。
Activity A 跳转到 Activity B,生命周期的执行过程是啥?
(此处有坑 ActivityA的OnPause和ActivityB的onResume谁先执行)
打开Activity A:
- A.onCreate
- A.onStart
- A.onResume
Activity A跳转到Activity B:
- A.onPause
- B.onCreate
- B.onStart
- B.onResume
- A.onStop
在Activity B中按返回键返回Activity A:
- B.onPause
- A.onRestart
- A.onStart
- A.onResume
- B.onStop
- B.onDestroy
再按返回键退出A:
- A.onPause
- A.onStop
- A.onDestroy
Android中Handler声明非静态对象会发出警告,为什么非得是静态的?
(Memory Leak)
比如:
public class MainActivity extends Activity {
private Handler mHandler = new Handler() {
@Override
public void handleMessage(Message msg) {
//TODO handle message...
}
};
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
mHandler.sendMessageDelayed(Message.obtain(), 60000);
finish();
}
}
当Android应用启动的时候,会先创建一个应用主线程的Looper对象,Looper实现了一个简单的消息队列,一个一个的处理里面的Message对象。主线程Looper对象在整个应用生命周期中存在。当在主线程中初始化Handler时,该Handler和Looper的消息队列关联,发送到消息队列的Message会引用发送该消息的Handler对象,这样系统就可以调用 Handler.handleMessage(Message) 来分发处理该消息。然而,我们都知道在Java中,非静态(匿名)内部类会引用外部类对象。而静态内部类不会引用外部类对象。如果外部类是Activity,则会引起Activity泄露 。因为当Activity finish后,延时消息会继续存在主线程消息队列中,然后处理消息。而该消息引用了Activity的Handler对象,然后这个Handler又引用了这个Activity。这些引用对象会保持到该消息被处理完,这样就导致该Activity对象无法被回收,从而导致了上面说的 Activity泄露。也就是如果你执行了Handler的postDelayed()方法,该方法会将你的Handler装入一个Message,并把这条Message推到 MessageQueue中,那么在你设定的delay到达之前,会有一条MessageQueue -> Message -> Handler -> Activity的链,导致你的Activity被持有引用而无法被回收。
再比如:
Handler mHandler = new Handler() {
@Override
public void handleMessage(Message msg) {
mImageView.setImageBitmap(mBitmap);
}
}
当使用内部类(包括匿名类)来创建Handler的时候,Handler对象会隐式地持有一个外部类对象(通常是一个Activity)的引用(不然你怎 么可能通过Handler来操作Activity中的View?)。而Handler通常会伴随着一个耗时的后台线程(例如从网络拉取图片)一起出现,这 个后台线程在任务执行完毕(例如图片下载完毕)之后,通过消息机制通知Handler,然后Handler把图片更新到界面。然而,如果用户在网络请求过程中关闭了Activity,正常情况下,Activity不再被使用,它就有可能在GC检查时被回收掉,但由于这时线程尚未执行完,而该线程持有 Handler的引用(不然它怎么发消息给Handler?),这个Handler又持有Activity的引用,就导致该Activity无法被回收 (即内存泄露),直到网络请求结束(例如图片下载完毕)。
改进方法:
方法一:通过完善自己的代码逻辑来进行保护。
1.在关闭Activity的时候停掉你的后台线程。线程停掉了,就相当于切断了Handler和外部连接的线,Activity自然会在合适的时候被回收。
2.如果你的Handler是被delay的Message持有了引用,那么使用相应的Handler的removeCallbacks()方法,把消息对象从消息队列移除就行了。
方法二:将Handler声明为静态类,然后通过WeakReference 来保持外部的Activity对象。 由于静态类不持有外部类的对象,所以你的Activity可以随意被回收。由于Handler不再持有外部类对象的引用,导致程序不允许你在Handler中操作Activity中的对象了。所以你需要在Handler中增加一个对Activity的弱引用(WeakReference)
static class MyHandler extends Handler {
WeakReference<Activity > mActivityReference;
MyHandler(Activity activity) {
mActivityReference= new WeakReference<Activity>(activity);
}
@Override
public void handleMessage(Message msg) {
final Activity activity = mActivityReference.get();
if (activity != null) {
mImageView.setImageBitmap(mBitmap);
}
}
}
当我们在Activity中使用内部类的时候,需要时刻考虑是否可以控制该内部类的生命周期,如果不可以,则最好定义为静态内部类,以免造成内存泄漏。这是Android开发过程中经常被忽略掉的,特别是在开发自定义View组件的过程中经常忘记而导致内存泄漏。
ListView使用过程中是否可以调用addView
不能,因为ListView有一个祖先类AdapterView,这个AdapterView重写了addView方法,在里面抛出了异常:
@Override
public void addView(View child) {
throw new UnsupportedOperationException("addView(View) is not supported in AdapterView");
}
属性动画(Property Animation)和补间动画(Tween Animation)的区别,为什么在3.0之后引入属性动画
官方解释:调用简单
有没有使用过EventBus或者Otto框架,主要用来解决什么问题,内部原理
是一个Android事件发布/订阅框架,通过解耦发布者和订阅者简化Android事件传递,这里的事件可以理解为消息。事件传递既可以用于Android四大组件间通讯,也可以用于异步线程和主线程间通讯等。
传统的事件传递方式包括:Handler、BroadcastReceiver、Interface回调,相比之下EventBus的优点是代码简洁,使用简单,并将事件发布和 订阅充分解耦。
Android里的LRU(Least Recently Used 最近最少使用)算法原理
LRU是近期最少使用的算法,它的核心思想是当缓存满时,会优先淘汰那些近期最少使用的缓存对象。采用LRU算法的缓存有两种:LrhCache和DisLruCache,分别用于实现内存缓存和硬盘缓存,其核心思想都是LRU缓存算法。
LruCache的核心思想很好理解,就是要维护一个缓存对象队列,其中对象列表的排列方式是按照访问顺序实现的,即一直没访问的对象,将放在队尾,即将被淘汰。而最近访问的对象将放在队头,最后被淘汰。
Service onBindService 和startService 启动的区别
service的生命周期、service的停止方式。
invalidate()和postInvalidate() 的区别
invalidate()是用来刷新View的,必须是在UI线程中进行工作。比如在修改某个view的显示时,调用invalidate()才能看到重新绘制的界面。postInvalidate()在工作者线程中被调用。
导入外部数据库
Android系统下数据库应该存放在 /data/data/com.*.*(package name)/ 目录下,所以我们需要做的是把已有的数据库传入那个目录下。操作方法是用FileInputStream读取原数据库,再用FileOutputStream把读取到的东西写入到那个目录。
Parcelable和Serializable区别
在我们平时开发中.我们用到序列化最多的地方就是通过intent传递对象,如果你要在intent中传递基本数据类型以外的对象,那么该对象必须实现Serializable或者Parcelable,否则会报错;
同时进程间通信传递的对象是有严格要求的,除了基本数据类型,其他对象要想可以传递,必须可序列化,Android实现可序列化一般是通过实现 Serializable 或者是 Parcelable。
注意:
- 通过intent传递过去的对象是经过了序列化与反序列化的,虽然传送的对象和接收的对象内容相同,但是是不同的对象,他们的引用是不同的
- 静态变量是不会经过序列化的,所以跨进程通信的时候静态变量是传送不过去的
- 序列化过程中不会保存transient 修饰的属性,它是 Java 的关键字,专门用来标识不序列化的属性。
Serializable序列化不保存静态变量,可以使用Transient关键字对部分字段不进行序列化,也可以覆盖writeObject、readObject`方法以实现序列化过程自定义。
Serializable是java提供的序列化接口,使用方法是让待序列化的类实现Serializable接口即可,不需要额外实现任何方法,但是最好手动加上一个private static final long serialVersionUID变量,其作用是一个类序列化时,运行时会保存它的版本号,然后在反序列化时检查你要反序列化成的对象版本号是否一致,不一致的话就会报错:·InvalidClassException,如果我们不自己创建这个版本号,序列化过程中运行时会根据类的许多特点计算出一个默认版本号。然而只要你对这个类修改了一点点,这个版本号就会改变。这种情况如果发生在序列化之后,反序列化时就会导致上面说的错误,Serializable 的序列化与反序列化分别通过 ObjectOutputStream 和 ObjectInputStream 进行。
Parcelable 是 Android 特有的序列化接口,方法是实现Parcelable接口并重写相应方法,as中建议使用插件Android Parcelable Code Generator自动化完成Parcelable接口对应方法的重写。
区别:
两者最大的区别在于 存储媒介的不同,Serializable 使用 I/O 读写存储在硬盘上,而 Parcelable 是直接 在内存中读写。很明显,内存的读写速度通常大于 IO 读写,所以在 Android 中传递数据优先选择 Parcelable。
Serializable:
1.Serializable是java提供的可序列化接口
2.Serializable的序列化与反序列化需要大量的IO操作,效率比较低
3.Serializable实现起来很简单
Parcelable:
1.Parcelable是Android特有的可序列化接口
2.Parcelable的效率比较高
3.Parcleable实现起来比较复杂
4.使用场景
1.Parcleable: 内存中的序列化时使用,效率更高,如activity间传输数据
2.Serializable: 对象序列化到存储设备中、在网络中传输等,在需要保存或网络传输数据时选择
因为android不同版本Parcelable可能不同,所以不推荐使用Parcelable进行数据持久化。
在两个 Activity 之间传递对象还需要注意什么呢?
两个Activity之间一般采用 Intent.putXXX() 就可以实现各种轻量级数据的传递。对于自定义的 Object ,
直接使用 Bundle 的 putSerializable() 或者Bundle.putParcelable()即可,当然对象实现 Serializable 或者Parcelable接口,最后使用 Intent.putExtras(Bundle) 把数据放进 Intent 即可,一般用Parcleable比较高效,需要注意的是对象的大小,Intent 中的 Bundle 是使用 Binder 机制进行数据传送的。能使用的 Binder 的缓冲区是有大小限制的(有些手机是 2 M),而一个进程默认有 16 个 Binder 线程,所以一个线程能占用的缓冲区就更小了( 有人以前做过测试,大约一个线程可以占用 128 KB)。所以当你看到 The Binder transaction failed because it was too large 这类 TransactionTooLargeException 异常时,你应该知道怎么解决了。
Android里跨进程传递数据的几种方案
- Binder
- Socket/LocalSocket
- 共享内存
匿名共享内存,使用场景
在Android系统中,提供了独特的匿名共享内存子系统Ashmem(Anonymous Shared Memory),它以驱动程序的形式实现在内核空间中。它有两个特点,一是能够辅助内存管理系统来有效地管理不再使用的内存块,二是它通过Binder进程间通信机制来实现进程间的内存共享。
ashmem并不像Binder那样是Android重新自己搞的一套东西,而是利用了Linux的 tmpfs文件系统。tmpfs是一种可以基于RAM或是SWAP的高速文件系统,然后可以拿它来实现不同进程间的内存共享。
大致思路和流程是:
- Proc A 通过 tmpfs 创建一块共享区域,得到这块区域的 fd(文件描述符)
- Proc A 在 fd 上 mmap 一片内存区域到本进程用于共享数据
- Proc A 通过某种方法把 fd 倒腾给 Proc B
- Proc B 在接到的 fd 上同样 mmap 相同的区域到本进程
- 然后 A、B 在 mmap 到本进程中的内存中读、写,对方都能看到了
其实核心点就是 创建一块共享区域,然后2个进程同时把这片区域 mmap 到本进程,然后读写就像本进程的内存一样。这里要解释下第3步,为什么要倒腾 fd,因为在 linux 中 fd 只是对本进程是唯一的,在 Proc A 中打开一个文件得到一个 fd,但是把这个打开的 fd 直接放到 Proc B 中,Proc B 是无法直接使用的。但是文件是唯一的,就是说一个文件(file)可以被打开多次,每打开一次就有一个 fd(文件描述符),所以对于同一个文件来说,需要某种转化,把 Proc A 中的 fd 转化成 Proc B 中的 fd。这样 Proc B 才能通过 fd mmap 同样的共享内存文件。
使用场景:进程间大量数据传输。
Application类的作用
Android系统会为每个程序运行时创建一个Application类的对象且仅创建一个,所以Application可以说是单例 (singleton)模式的一个类。Application对象的生命周期是整个程序中最长的,它的生命周期就等于这个程序的生命周期。因为它是全局的单例的,所以在不同的Activity,Service中获得的对象都是同一个对象。所以通过Application来进行一些,数据传递,数据共享,数据缓存等操作。
广播注册后不解除注册会有什么问题?(内存泄露)
如果我们在Activity中使用了registerReceiver()方法注册了一个BroadcastReceiver,如果没在Activity的生命周期内调用unregisterReceiver()方法取消注册此BroadcastReceiver,由于BroadcastReceiver不止被Activity引用,还可能会被AMS等系统服务、管理器等之类的引用,导致BroadcastReceiver无法被回收,而BroadcastReceiver中又持有着Activity的引用(即:onReceive方法中的参数Context),会导致Activity也无法被回收(虽然Activity回调了onDestroy方法,但并不意味着Activity被回收了),从而导致严重的内存泄漏。
我们可以通过两种方式注册BroadcastReceiver,一是在Activity启动过程中通过代码动态注册,二是在AndroidManifest.xml文件中利用
- 对于第一种方法,我们需要养成一个良好的习惯:在Activity进入停止或者销毁状态的时候使用
unregisterReceiver方法将注册的BroadcastReceiver注销掉。 - 对于
onReceive被调用之后就会在任意时间内被销毁。
属性动画(Property Animation)和补间动画(Tween Animation)的区别
- 补间动画只是针对于View,超脱了View就无法操作了。
- 补间动画有四种动画操作(移动,缩放,旋转,淡入淡出)。
- 补间动画只是改变View的显示效果而已,但是不会真正的去改变View的属性。
- 属性动画改变View的实际属性值,当然它也可以不作用于View。
BrocastReceive里面可不可以执行耗时操作?
不能,当 onReceive() 方法在 10 秒内没有执行完毕,Android 会认为该程序无响应,所以在BroadcastReceiver里不能做一些比较耗时的操作,否侧会弹出 ANR 的对话框。
Android优化工具
TraceView
traceview 是Android SDK中自带的一个工具,可以 对应用中方法调用耗时进行统计分析,是Android性能优化和分析时一个很重要的工具。使用方法:第一种是在相应进行traceview分析的开始位置和结束位置分别调用startMethodTracing和stopMethodTracing方法。第二种是在ddms中直接使用,即在ddms中在选中某个要进行监控的进程后,点击如图所示的小图标开始监控,在监控结束时再次点击小图标,ddms会自动打开traceview视图。
Systrace
Systrace是Android4.1中新增的性能数据采样和分析工具。它可帮助开发者收集Android关键子系统(如surfaceflinger、WindowManagerService等Framework部分关键模块、服务)的运行信息,从而帮助开发者更直观的分析系统瓶颈,改进性能。
Systrace的功能包括跟踪系统的I/O操作、内核工作队列、CPU负载以及Android各个子系统的运行状况等。
Android动态权限?
Android 6.0 动态权限,这里以拨打电话的权限为例,首先需要在Manifest里添加android.permission.CALL_PHONE权限。
int checkCallPhonePermission = ContextCompat.checkSelfPermission(this, Manifest.permission.CALL_PHONE);
if (checkCallPhonePermission != PackageManager.PERMISSION_GRANTED) {
ActivityCompat.requestPermissions(
this, new String[]{Manifest.permission.CALL_PHONE}, REQUEST_CODE_ASK_CALL_PHONE);
return;
}
在获取权限后,可以重写Activity.onRequestPermissionsResult方法来进行回调。
@Override
public void onRequestPermissionsResult(int requestCode, @NonNull String[] permissions,
@NonNull int[] grantResults) {
switch (requestCode) {
case REQUEST_CODE_ASK_CALL_PHONE:
if (grantResults[0] == PackageManager.PERMISSION_GRANTED) {
// Permission Granted
Toast.makeText(MainActivity.this, "CALL_PHONE Granted", Toast.LENGTH_SHORT)
.show();
} else {
// Permission Denied
Toast.makeText(MainActivity.this, "CALL_PHONE Denied", Toast.LENGTH_SHORT)
.show();
}
break;
default:
super.onRequestPermissionsResult(requestCode, permissions, grantResults);
}
}
ViewPager如何判断左右滑动?
实现OnPageChangeListener并重写onPageScrolled方法,通过参数进行判断。
ListView与RecyclerView
- ViewHolder:在ListView中,ViewHolder需要自己来定义,且这只是一种推荐的使用方式,不使用当然也可以,这不是必须的。而在RecyclerView中使用
RecyclerView.ViewHolder则变成了必须,尽管实现起来稍显复杂,但它却解决了ListView面临的上述不使用自定义ViewHolder时所面临的问题。 - LayoutManager:RecyclerView提供了更加丰富的布局管理。
LinearLayoutManager,可以支持水平和竖直方向上滚动的列表。StaggeredGridLayoutManager,可以支持交叉网格风格的列表,类似于瀑布流或者Pinterest。GridLayoutManager,支持网格展示,可以水平或者竖直滚动,如展示图片的画廊。 - ItemAnimator:相比较于ListView,
RecyclerView.ItemAnimator则被提供用于在RecyclerView添加、删除或移动item时处理动画效果。 - ItemDecoration:RecyclerView在默认情况下并不在item之间展示间隔符。如果你想要添加间隔符,你必须使用
RecyclerView.ItemDecoration类来实现。 - ListView可以设置选择模式,并添加
MultiChoiceModeListener,RecyclerView中并没有提供这样功能。
SpannableString
TextView通常用来显示普通文本,但是有时候需要对其中某些文本进行样式、事件方面的设置。Android系统通过SpannableString类来对指定文本进行相关处理。可以通过SpannableString来对TextView进行富文本设置,包括但不限于文本颜色,删除线,图片,超链接,字体样式。
APK安装过程
- 将apk拷贝到data/app/pkg目录下
- 资源管理器加载资源
- 解析manifest文件
- 在data/data/目录下创建对应的数据资源目录
- 对dex文件进行优化,优化后的dexopt放在dalvik-cache目录下
- 从manifest中解析出四大组件信息注册到PackageManagerService中
- 发送广播
描述一下Android手机启动过程和App启动过程?
Android手机启动过程
当我们开机时,首先是启动Linux内核,在Linux内核中首先启动的是init进程,这个进程会去读取配置文件system\core\rootdir\init.rc配置文件,这个文件中配置了Android系统中第一个进程Zygote进程。
启动Zygote进程 --> 创建AppRuntime(Android运行环境) --> 启动虚拟机 --> 在虚拟机中注册JNI方法 --> 初始化进程通信使用的Socket(用于接收AMS的请求) --> 启动系统服务进程 --> 初始化时区、键盘布局等通用信息 --> 启动Binder线程池 --> 初始化系统服务(包括PMS,AMS等等) --> 启动Launcher
App启动过程
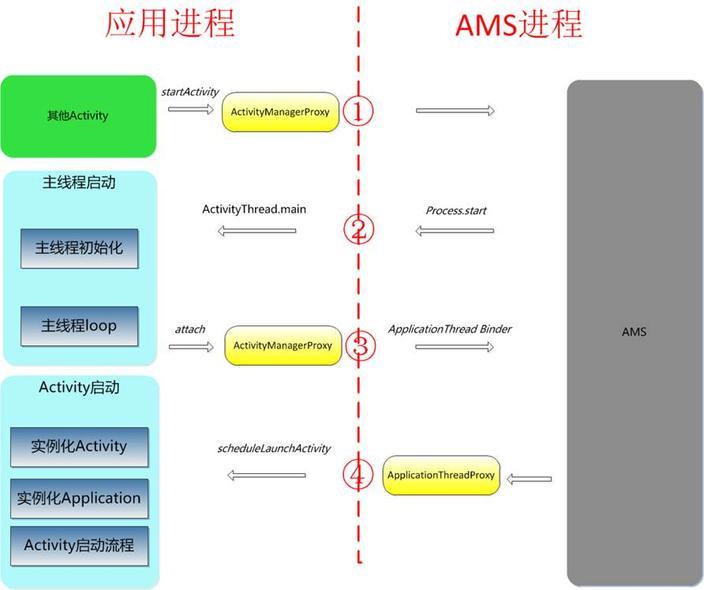
- 应用的启动是从其他应用调用
startActivity开始的。通过代理请求AMS启动Activity。 - AMS创建进程,并进入
ActivityThread的main入口。在main入口,主线程初始化,并loop起来。主线程初始化,主要是实例化ActivityThread和ApplicationThread,以及MainLooper的创建。ActivityThread和ApplicationThread实例用于与AMS进程通信。 - 应用进程将实例化的
ApplicationThread,Binder传递给AMS,这样AMS就可以通过代理对应用进程进行访问。 - AMS通过代理,请求启动Activity。
ApplicationThread通知主线程执行该请求。然后,ActivityThread执行Activity的启动。 - Activity的启动包括,Activity的实例化,Application的实例化,以及Activity的启动流程:create、start、resume。
可以看到 入口Activity其实是先于Application实例化,只是onCreate之类的流程,先于Activity的流程。另外需要scheduleLaunchActivity,在ApplicationThreaad中,对应AMS管理Activity生命周期的方法都以scheduleXXXActivity,ApplicationThread在Binder线程中,它会向主线程发送消息,ActivityThread的Handler会调用相应的handleXXXActivity方法,然后会执行performXXXActivity方法,最终调用Activity的onXXX方法
Include、Merge、ViewStub的作用
Include:布局重用
- 可以使用其他属性。
- 在
android:layout_*都是有效的,前提是必须要写layout_width和layout_height两个属性。 - 布局中可以包含两个相同的include标签
Merge:减少视图层级,多用于替换FrameLayout或者当一个布局包含另一个时,
例如:你的主布局文件是垂直布局,引入了一个垂直布局的include,这是如果include布局使用的LinearLayout就没意义了,使用的话反而减慢你的UI表现。这时可以使用标签优化。
ViewStub:需要时使用。优点是当你需要时才会加载,使用他并不会影响UI初始化时的性能。需要使用时调用inflate()。
Asset目录与res目录的区别
- assets 目录:不会在
R.java文件下生成相应的标记,assets文件夹可以自己创建文件夹,必须使用AssetsManager类进行访问,存放到这里的资源在运行打包的时候都会打入程序安装包中, - res 目录:会在R.java文件下生成标记,这里的资源会在运行打包操作的时候判断哪些被使用到了,没有被使用到的文件资源是不会打包到安装包中的。
res/raw 和 assets文件夹来存放不需要系统编译成二进制的文件,例如字体文件等
res/raw不可以有目录结构,而assets则可以有目录结构,也就是assets目录下可以再建立文件夹
读取res/raw下的文件资源,通过以下方式获取输入流来进行写操作
InputStream is =getResources().openRawResource(R.id.filename);
读取assets下的文件资源,通过以下方式获取输入流来进行写操作
/**
* 从assets中读取图片
*/
private Bitmap getImageFromAssetsFile(String fileName)
{
Bitmap image = null;
AssetManager am = getResources().getAssets();
try
{
InputStream is = am.open(fileName);
image = BitmapFactory.decodeStream(is);
is.close();
}
catch (IOException e)
{
e.printStackTrace();
}
return image;
}
注意1:Google的Android系统处理Assert有个bug,在AssertManager中不能处理单个超过1MB的文件,不然会报异常,raw没这个限制可以放个4MB的Mp3文件没问题。
注意2:assets 文件夹是存放不进行编译加工的原生文件,即该文件夹里面的文件不会像 xml, java 文件被预编译,可以存放一些图片,html,js, css 等文件。
System.gc && Runtime.gc
System.gc和Runtime.gc是等效的,在System.gc内部也是调用的Runtime.gc。调用两者都是通知虚拟机要进行gc,但是否立即回收还是延迟回收由JVM决定。两者唯一的区别就是一个是类方法,一个是实例方法。
Application 在多进程下会多次调用 onCreate() 么?
当采用多进程的时候,比如下面的Service 配置:
android:process 属性中
:的作用就是把这个名字附加到你的包所运行的标准进程名字的后面作为新的进程名称。
这样配置会调用 onCreate() 两次。
Theme && Style
- Style 是一组外观、样式的属性集合,适用于 View 和 Window 。
- Theme 是一种应用于整个 Activity 或者 Application ,而不是独立的 View。
SQLiteOpenHelper.onCreate() 调用时机?
在调getReadableDatabase或getWritableDatabase时,会判断指定的数据库是否存在,不存在则调SQLiteDatabase.onCreate创建, onCreate只在数据库第一次创建时才执行。
Removecallback 失效?
Removecallback 必须是同一个Handler才能移除。
Toast 如果会短时间内频繁显示怎么优化?
public void update(String msg){
toast.setText(msg);
toast.show();
}
Notification 如何优化?
可以通过 相同 ID 来更新 Notification 。
应用怎么判断自己是处于前台还是后台?
主要是通过 getRunningAppProcesses() 方法来实现。
ActivityManager activityManager = (ActivityManager) getSystemService(Context.ACTIVITY_SERVICE);
List appProcesses = activityManager.getRunningAppProcesses();
for (ActivityManager.RunningAppProcessInfo appProcess : appProcesses) {
if (appProcess.processName.equals(getPackageName())) {
if (appProcess.importance == ActivityManager.RunningAppProcessInfo.IMPORTANCE_FOREGROUND) {
Log.d(TAG, String.format("Foreground App:%s", appProcess.processName));
} else {
Log.d(TAG, "Background App:" appProcess.processName);
}
}
}
FragmentPagerAdapter 和 FragmentStateAdapter 的区别?
FragmentStatePagerAdapter 是 PagerAdapter 的子类,这个适配器对实现多个 Fragment 界面的滑动是非常有用的,它的工作方式和listview是非常相似的。当Fragment对用户不可见的时候,整个Fragment会被销毁,只会保存Fragment的保存状态。基于这样的特性,FragmentStatePagerAdapter 比 FragmentPagerAdapter 更适合用于很多界面之间的转换,而且消耗更少的内存资源。
Bitmap的本质?
本质是 SkBitmap 详见 Pocket
SurfaceView && View && GLSurfaceView
View:显示视图,内置画布,提供图形绘制函数、触屏事件、按键事件函数等;必须在UI主线程内更新画面,速度较慢。SurfaceView:基于view视图进行拓展的视图类,更适合2D游戏的开发;View的子类,类似使用双缓机制,在新的线程(也可以在UI线程)中更新画面所以刷新界面速度比 View 快,但是会涉及到线程同步问题。GLSurfaceView:openGL专用。基于SurfaceView视图再次进行拓展的视图类,专用于3D游戏开发的视图。
请简述一下你对fragment的理解?
fragment被称为碎片,可以作为界面来使用,在一个Activity中可以嵌入多个Fragment,而且Fragment不能单独存在,必须依附于Activity才行,但是Fragment又有自己的生命周期,也能直接处理用户的一些事件,Fragment的生命周期也受依附的Activity的生命周期影响;一般来说Fragment在平板开发中用的比较多,还有就是Tab切换
请简述一下Fragment的生命周期?
fragment的生命周期:onAttach——>onCreate——>onCreateView——>onViewCreated——>onActivityCreated——>onStart——>onResume——>onPause——>onStop——>onDestroyView——>onDestroy——>onDetach;
fragment的生命周期大致就这么多,但是还有一个比较常见的就是onHiddenChanged,这个是在切换fragment的时候会执行,至于什么场景下会执行什么,我还是建议你自己动手实验一把;这里还需要注意的是,如果是通过add方法显示fragment,那么切换fragment不会执行其生命周期,只会执行onHiddenChanged方法;如果是通过replace方法显示fragment,切换fragment的时候会重新走生命周期的流程。
LayoutInflater,LayoutInflater.inflate()这两个是什么意思?
LayoutInflater是一个用来实例化XML布局文件为View对象的类
LayoutInflater.infalte(R.layout.test,null)用来从指定的XML资源中填充一个新的View
Android的多渠道打包你了解吗
多渠道打包:就是指分不同的市场打包,如安卓市场、百度市场、谷歌市场等等,Android的这个市场有点多,就不一一列举了,多渠道打包是为了针对不同市场做出不同的一些统计,数据分析,收集用户信息。
AndroidStudio用的多的友盟多渠道打包
如何对APK瘦身?
1)使用混淆
2)开启shrinkResourse(shrink-收缩),会将没有用到的图片变成一个像素点
3)删除无用的语言资源(删除国际化文件)
4)对于非透明的大图,使用JPG(没有透明度信息),代替PNG格式
5)使用tinypng进行图片压缩
6)使用webp图片格式,进一步压缩图片资源
7)使用第三方包时把用到的代码加到项目中来,避免引用整一个第三方库
Android当前应用跳转到三方应用
从一个应用直接跳转到另外一个应用,没有就自动前往应用商店下载,需要有第三方应用的包名:
if(isApplicationInstall("第三方app包名")){
//直接进入
loge("已安装!");
PackageManager packageManager = getPackageManager();
Intent intent=new Intent();
intent = packageManager.getLaunchIntentForPackage("第三方app包名");
startActivity(intent);
}else {
//应用商店安装
loge("未安装!");
Intent intent ;
Uri uri = Uri.parse("market://details?id=第三方app包名");
intent = new Intent(Intent.ACTION_VIEW, uri);
startActivity(intent);
}
....
/**
* by moos on 2017/09/18
* func:判断手机是否安装了该应用
* @param packageName
* @return
*/
private boolean isApplicationInstall(String packageName){
return new File("/data/data/" packageName).exists();
}
JVM、ART、Dalvik的区别和联系
Jvm和Dalvik:JVM是java中的虚拟机即java virtual machies,而Dalvk是Google为了android定制的虚拟机,其相对jvm来说做了很多优化,使其更加适合于Android,dex格式是专门为Dalvik应用设计的一种压缩格式,适合于内存和处理器速度有限的平台。其允许同时独立运行多个进程,这样的好处是就算一个进程崩溃了也不会对其他进程产生影响,因为他们有各自独立的地址空间。
Dalvik和Art:Dalvik下的应用每次运行的时候都要通过即时编译器(Android Runtime,JIT)将字节码转化为机器码,即每次应用运行的时候都需要先编译再运行,这样的好处是应用在安装的时候会比较快,缺点就是应用启动的速度会变慢。为了解决这个问题,Google在2014年6月的IO大会上使用ART( Ahead-Of-Time(AOT) )代替的Dalvik,ART的优点是在安装的时候就预编译字节码为机器代码,这样在以后应用的运行时就不用再反复编译了,提高了应用的启动速度,同时也节省了手机的能耗,缺点是应用安装的时候会比较慢,同时由于同一份代码的机器代码会比字节码大10%-20%,所以造成相同的应用在Art下的大小可能比在Dalvik下大10%左右。
ART优点:
1. 系统性能的显著提升
2. 应用启动更快、运行更快、体验更流畅、触感反馈更及时
3. 更长的电池续航能力
4. 支持更低的硬件
ART缺点:
1. 更大的存储空间占用,可能会增加10%-20%
2. 更长的应用安装时间
Android中的classLoader相比java中的classLoader有什么区别?
Android中一个运行中的应用至少会有两个classLoader,一个是系统的BootClassLoader,用来加载FrameWork层级需要的东西,然后才是我们自己应用中的classLoader,当然,BootClassLoader是我们应用中classLoader的父级classLoader。在Android中classLoader是一个抽象类,在平时开发中我们一般是使用其实现类
在java的jvm中可以直接通过classL来加载.class或者.jar,但是在Android的Davik/Art下,apk在安装的时候会先经过一个叫DexOpt的工具对其做优化,转化为Dalvik下的字节码文件,处理完了之后会产生ODex文件(后缀是.dex或者.odex),在运行应用的时候去加载含有dex文件的apk或者jar文件,而不是直接加载class,所以android中classLoader的工作是由BaseDexClassLoader来完成的。BaseDexClassLoader继承了classLoader抽象类,其有两个子类:DexClassLoader和PathClassLoader,DexClassLoader可以加载Sd卡上的.dex或者.jar或者.apk文件。
Socket和LocalSocket
HttpClient和URLConnection的区别,怎么使用https
设计一个网络请求框架(可以参考Volley框架)
网络图片加载框架(可以参考BitmapFun)
字节跳动Android岗面试题
java的classloader工作原理
ClassLoader使用的是双亲委托模型来搜索类的,每个ClassLoader实例都有一个父类加载器的引用(不是继承的关系,是一个包含的关系),虚拟机内置的类加载器(Bootstrap ClassLoader)本身没有父类加载器,但可以用作其它ClassLoader实例的的父类加载器。当一个ClassLoader实例需要加载某个类时,它会试图亲自搜索某个类之前,先把这个任务委托给它的父类加载器,这个过程是由上至下依次检查的,首先由最顶层的类加载器Bootstrap ClassLoader试图加载,如果没加载到,则把任务转交给Extension ClassLoader试图加载,如果也没加载到,则转交给App ClassLoader 进行加载,如果它也没有加载得到的话,则返回给委托的发起者,由它到指定的文件系统或网络等URL中加载该类。如果它们都没有加载到这个类时,则抛出ClassNotFoundException异常。否则将这个找到的类生成一个类的定义,并将它加载到内存当中,最后返回这个类在内存中的Class实例对象。
开发过程中常见的内存泄漏都有哪些
静态的对象中(包括单例)持有一个生命周期较短的引用时,或内部类的子代码块对象的生命周期超过了外面代码的生命周期(如非静态内部类,线程),会导致这个短生命周期的对象内存泄漏。总之就是一个对象的生命周期结束(不再使用该对象)后,依然被某些对象所持有该对象强引用的场景就是内存泄漏。
当一个对象在程序中已经不再使用,但是(强)引用还是会被其他对象持有,则称为内存泄漏。内存泄漏并不会使程序马上异常,但是多处的未处理的内存泄漏则可能导致内存溢出,造成不可预估的后果。
常见情景:
1、静态成员变量持有外部(短周期临时)对象引用。 如单例类(类内部静态属性)持有一个activity(或其他短周期对象)引用时,导致被持有的对象内存无法释放。
2、内部类。当内部类与外部类生命周期不一致时,就会造成内存泄漏。如非静态内部类创建静态实例、Activity中的Handler或Thread等。
3、资源没有及时关闭。如数据库、IO流、Bitmap、注册的相关服务、webview、动画等。
4、集合内部Item没有置空。
5、方法块内不使用的对象,没有及时置空。
关于JVM内存管理的一些建议
1、尽可能的手动将无用对象置为null,加快内存回收。
2、可考虑对象池技术生成可重用的对象,较少对象的生成。
3、合理利用四种引用。
LeakCanary的工作原理,java gc是如何回收对象的,可以作为gc根节点的对象有哪些?
Android Studio供了许多对App性能分析的工具,可以方便分析App性能。我们可以使用Memory Monitor和Heap Dump来观察内存的使用情况、使用Allocation Tracker来跟踪内存分配的情况,也可以通过这些工具来找到疑似发生内存泄漏的位置。
堆存储文件(hpof)可以使用DDMS或者Memory Monitor来生成,输出的文件格式为hpof,而MAT(Memory Analysis Tool)就是来分析堆存储文件的。
然而MAT工具分析内存问题并不是一件容易的事情,需要一定的经验区做引用链的分析,需要一定的门槛。 随着安卓技术生态的发展,LeakCanary 开源项目诞生了,只要几行代码引入目标项目,就可以自动分析hpof文件,把内存泄漏的地方展示出来。
说白了就是用来检测内存泄漏的。
LeakCanary原理
主要是在Activity的&onDestroy方法中,手动调用 GC,然后利用ReferenceQueue WeakReference,来判断是否有释放不掉的引用,然后结合dump memory的hpof文件, 用HaHa(Headless Android Heap Analyzer)分析出泄漏地方。
流程:
1:用ActivityLifecycleCallbacks接口来检测Activity生命周期
2:WeakReference ReferenceQueue 来监听对象回收情况
3:Apolication中可通过processName判断是否是任务执行进程
4:MessageQueue中加入一个IdleHandler来得到主线程空闲回调
5:LeakCanary检测只针对Activiy里的相关对象。其他类无法使用,还得用MAT原始方法
java gc是如何回收对象的
那些不可能再被任何途径使用的对象,需要被回收,否则内存迟早都会被消耗空。
GC机制主要是通过可达性分析法,通过一系列称为“GC Roots”的对象作为起始点,从这些节点向下搜索,搜索所走过的路径称为引用链,当一个对象到GC Roots没有任何引用链时,即GC Roots到对象不可达,则证明此对象是不可达的。
可以作为gc根节点的对象有哪些
- 虚拟机栈(栈帧中的局部变量区,也叫做局部变量表)中引用的对象。
- 方法区中的类静态属性引用的对象。
- 方法区中常量引用的对象。
- 本地方法栈中JNI(Native方法)引用的对象。
既然有GC机制,为什么还会有内存泄露的情
理论上Java因为有垃圾回收机制不会存在内存泄露问题(这也是Java被广泛使用于服务器端编程的一个重要原因)。
然而在实际开发中,可能会存在无用但可达的对象,这些对对象不能被GC回收,因此会导致内存溢出发生。
jvm的内存模型是什么样的?如何理解java的虚函数表?
多态是面向对象的最主要的特性之一,是一种方法的动态绑定,实现运行时的类型决定对象的行为。多态的表现形式是父类指针或引用指向子类对象,在这个指针上调用的方法使用子类的实现版本。多态是IOC、模板模式实现的关键。
在C 中通过虚函数表的方式实现多态,每个包含虚函数的类都具有一个虚函数表(virtual table),在这个类对象的地址空间的最靠前的位置存有指向虚函数表的指针。在虚函数表中,按照声明顺序依次排列所有的虚函数。比如:
class Base {
public:
virtual void f() {
printf("Base::f()");
}
virtual void g() {
printf("Base::g()");
}
};
class Derived: public Base {
public:
virtual void f() {
printf("Derived::f()");
}
};
上面代码对应的类布局:
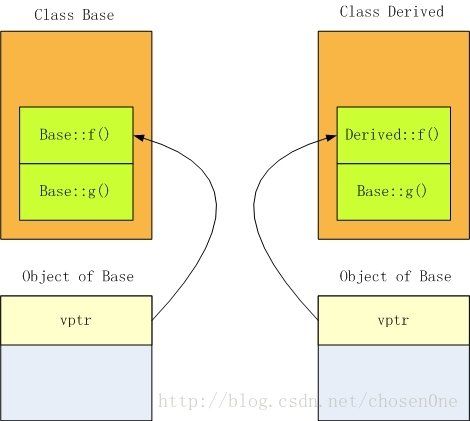
由于C 在运行时并不维护类型信息,所以在编译时直接在子类的虚函数表中将被子类重写的方法替换掉,如上图的Derived::f(),这个方法会被放到虚函数表中原来父函数在的位置。由于在编译时就确定了虚函数在虚表中的下标,所以在进行虚函数调用时,直接根据下标进行访问。比如,调用Derived对象上的f():
Base *b = new Derived;
b->f();
在调用b->f()时,内部会转化成(*b->vptr[1])(),由于虚函数表需要完成RTII,所以虚函数表的第一个slot存放的是type info,虚函数下标从1开始。实际上,虚函数表记录了这个类的所有虚函数的具体实现(就是在运行时确切要调用的),编译时就可以确定,不需要动态查找,效率较高。
Java中,在运行时会维持类型信息以及类的继承体系。每一个类会在方法区中对应一个数据结构用于存放类的信息,可以通过Class对象访问这个数据结构。其中,类型信息具有superclass属性指示了其超类,以及这个类对应的方法表(其中只包含这个类定义的方法,不包括从超类继承来的)。而每一个在堆上创建的对象,都具有一个指向方法区类型信息数据结构的指针,通过这个指针可以确定对象的类型。
JVM中用于方法调用的指令包括:
invokevirtual:用于调用实例方法,会根据对象的实际类型进行调用。
invokespecial:需要特殊处理的实例方法,比如:public final方法、私有方法和父类方法等。调用的方法取决于引用的类型。
invokeinterface:调用接口的方法。
invokestatic:调用类方法。
按照上面描述,对于子类覆盖父类的方法,编译后,调用指令应该是invokevirtual,调用的方法取决于对象的类型。invokevirtual方法查找的实现方式是:
- 通过对象中类指针找到其类信息,然后在方法表中根据方法签名找到该方法。
- 如果不在当前类,则递归查找其父类的方法表直到Object类。
- 如果找到Object类,也没有该方法,会抛出NoSuchMethodException异常。
与js、lua等动态语言类似,Java的实现方式依赖于内存中的类型体系信息,存在一个“原型链”,是一个完全动态的查找过程,相对于C 而言,效率会低一些,因为存在一个链表遍历查找的过程。之所以,Java中可以这样实现,本质上是因为它是一门虚拟机语言,虚拟机会维持所有的这些类型信息。
如何从一百万个数里面找到最小的一百个数,考虑算法的时间复杂度和空间复杂度。
解法一:采用局部淘汰法。选取前100个元素,并排序,记为序列L。然后一次扫描剩余的元素x,与排好序的100个元素中最小的元素比,如果比这个最小的要大,那么把这个最小的元素删除,并把x利用插入排序的思想,插入到序列L中。依次循环,知道扫描了所有的元素。复杂度为O(100万*100)。
解法二:采用快速排序的思想,每次分割之后只考虑比主元大的一部分,直到比主元大的一部分比100多的时候,采用传统排序算法排序,取前100个。复杂度为O(100万*100)。
解法三:在前面的题中,我们已经提到了,用一个含100个元素的最小堆完成。复杂度为O(100万*lg100)。
安卓的app加固如何做。
加固:防止代码反编译,提高代码安全性
加固三方平台:梆梆安全,360加固,爱加密等
区别:梆梆安全,360加固看不到项目中的类,爱加密看的到Java类,但看不到里面的方法实现体,效果比前面差一点点 加固的底层原理:第三方加固的应用会生成一个Apk,然后把你的APK读取出来,在封装到这个第三方应用的APK里面.
mvp和mvc的主要区别是什么?为什么mvp要比mvc好。
mvc是指用户触发事件的时候,view层会发送指令到controller层,然后controller去通知model层更新数据,model层更新完数据后会直接在view层显示结果。
对android来说 activity几乎承担了view层和controller层两种角色,并且和model层耦合严重,在逻辑复杂的界面维护起来很麻烦。
mvp模式下的activity只承担了view层的角色,controller的角色完全由presenter负责,view层和presenter层的通信通过接口实现,所以VP之间不存在耦合问题,view层与model也是完全解耦了。
presenter复用度高,可以随意搬到任何界面。
mvp模式下还方便测试维护:
可以在未完成界面的情况下实现接口调试,只需写一个Java类,实现对应的接口,presenter网络获取数据后能调用相应的方法。
相反的,在接口未完成联调的情况下正常显示界面,由presenter提供测试数据。
mvp的问题在于view层和presenter层是通过接口连接,在复杂的界面中,维护过多接口的成本很大。
解决办法是定义一些基类接口,把网络请求结果,toast等通用逻辑放在里面,然后供定义具体业务的接口继承。
安卓的混淆原理是什么?
Java 是一种跨平台、解释型语言,Java 源代码编译成的class文件中有大量包含语义的变量名、方法名的信息,很容易被反编译为Java 源代码。为了防止这种现象,我们可以对Java字节码进行混淆。混淆不仅能将代码中的类名、字段、方法名变为无意义的名称,保护代码,也由于移除无用的类、方法,并使用简短名称对类、字段、方法进行重命名缩小了程序的size。
ProGuard由shrink、optimize、obfuscate和preverify四个步骤组成,每个步骤都是可选的,需要哪些步骤都可以在脚本中配置。
- 压缩(Shrink): 侦测并移除代码中无用的类、字段、方法、和特性(Attribute)。
- 优化(Optimize): 分析和优化字节码。
- 混淆(Obfuscate): 使用a、b、c、d这样简短而无意义的名称,对类、字段和方法进行重命名。
上面三个步骤使代码size更小,更高效,也更难被逆向工程。
- 预检(Preveirfy): 在java平台上对处理后的代码进行预检。
如何设计一个安卓的画图库,做到对扩展开放,对修改封闭,同时又保持独立性。
OCP原则(开闭原则):一个软件实体如类、模块和函数应该对扩展开放,对修改关闭。
能用抽象类的别用具体类,能用接口的别用抽象类。总之一句:尽量面向接口编程。
网络优化的方案
我们对移动设备网络的需求无非快速,节省流量,节省电量。
一般而言:
快速可以通过缓存方式来实现;
节省流量可以通过缓存,压缩数据源等方式;
节省耗电量 可以通过批量操作,减少唤醒电源和电源持续时间来达到
APP的性能优化经验
布局优化
- 减少嵌套的层级(可使用RelativeLayout),减少嵌套层级可加快加载效率,
- 使用include标签
- 使用style提取相同view的公共属性,减少重复代码
- 合理使用ViewStub
图片的优化
android中图片的使用是非常占用内存资源的。
-
在图片未使用时,及时recycle()回收
-
使用三级缓存,内存-sd卡-网络
内存中再次获取最快,由于内存有限可能被gc回收,sd卡中的图片不会回收,当前面两种都不存在所需图片时,才去网洛下载 -
将大图片进行压缩处理再放到内存中,用到
BitmapFactory类 -
图片解码率也会影响图片所占内存
常见的png,JPG,webp等格式的图片在设置到UI上之前需要经过解码过程,而图片采用不同的码率,也会造成对内存的占用不同。
ARGB_8888 格式的解码率,一个像素占用4个字节,alpha(A)值,Red(R)值,Green(G)值,Blue(B)值各占8个bytes , 共32bytes , 即4个字节。这是一种高质量的图片格式,电脑上普通采用的格式。它也是Android手机上一个BitMap的默认格式。
RGB_565格式的解码率,一个像素占用2个字节,没有alpha(A)值,即不支持透明和半透明, Red(R)值占5个bytes ,Green(G)值占6个bytes ,Blue(B)值占5个bytes,共16bytes,即2个字节。 对于半透明颜色的图片来说,该格式的图片能够达到比较好的呈现效果,相对于ARGB_8888来说也能减少一半的内存开销,因此它是一个不错的选择。推荐使用
其他优化
- 网络优化
- 同一个页面数据尽量放到一个接口中去处理
- 使用Application Context代替Activity Context
- 谨慎使用static 关键字
- static使用不当容易造成内存泄漏
死锁的概念,怎么避免死锁
两个线程互相等待对方释放资源才能继续执行下去,这个时候就形成了死锁,谁都无法继续执行(或者多个线程循环等待)
如何避免死锁:多个线程以同样的顺序加锁和释放锁
App启动崩溃异常捕捉
主进程运行的所有代码都跑在Looper.loop();。前面也提到,crash的发生是由于 主线程有未捕获的异常。那么我把Looper.loop();用try-catch块包起来,应用程序就永不崩溃了!
new Handler(Looper.getMainLooper()).post(new Runnable() {
@Override
public void run() {
//主线程异常拦截
while (true) {
try {
Looper.loop();//主线程的异常会从这里抛出
} catch (Throwable e) {
}
}
}
});
sUncaughtExceptionHandler = Thread.getDefaultUncaughtExceptionHandler();
//所有线程异常拦截,由于主线程的异常都被我们catch住了,所以下面的代码拦截到的都是子线程的异常
Thread.setDefaultUncaughtExceptionHandler(new Thread.UncaughtExceptionHandler() {
@Override
public void uncaughtException(Thread t, Throwable e) {
}
});
- 通过Handler往主线程的queue中添加一个Runnable,当主线程执行到该Runnable时,会进入我们的while死循环,如果while内部是空的就会导致代码卡在这里,最终导致ANR。
- 我们在while死循环中又调用了Looper.loop(),这就导致主线程又开始不断的读取queue中的Message并执行,也就是主线程并不会被阻塞。同时又可以保证以后主线程的所有异常都会从我们手动调用的Looper.loop()处抛出,一旦抛出就会被try-catch捕获,这样主线程就不会crash了。
- 通过while(true)让主线程抛出异常后迫使主线程重新进入我们try-catch中的消息循环。 如果没有这个while的话那么主线程在第二次抛出异常时我们就又捕获不到了,这样APP就又crash了。
在Thread ApI中提供了UncaughtExceptionHandler,它能检测出某个线程由于未捕获的异常而终结的情况,然后开发者可以对未捕获异常进行善后处理,例如回收一些系统资源,或者没有关闭当前的连接等等。
Thread.UncaughtExceptionHandler是一个接口,它提供如下的方法,让我们自定义异常处理程序。
public static interface UncaughtExceptionHandler {
void uncaughtException(Thread thread, Throwable ex);
}
new Message和obtainMessage的区别
创建Message对象的时候,有三种方式,分别为:
1.Message msg = new Message();
2.Message msg2 = Message.obtain();
3.Message msg1 = handler1.obtainMessage();
这三种方式的区别如下:
-
Message msg = new Message();
这种就是直接初始化一个Message对象,没有什么特别的。
-
Message msg2 = Message.obtain();
/** * Return a new Message instance from the global pool. Allows us to * avoid allocating new objects in many cases. */ public static Message obtain() { synchronized (sPoolSync) { if (sPool != null) { Message m = sPool; sPool = m.next; m.next = null; m.flags = 0; // clear in-use flag sPoolSize--; return m; } } return new Message(); }从注释可以得知,从整个Messge池中返回一个新的Message实例,通过obtainMessage能避免重复Message创建对象。
-
Message msg1 = handler1.obtainMessage();
public final Message obtainMessage() { return Message.obtain(this); }可以看到,第二种跟第三种其实是一样的,都可以避免重复创建Message对象,所以建议用第二种或者第三种任何一个创建Message对象。
ReentrantLock 、synchronized和volatile(n面)
volatile:可见性、有序性,为什么不能保证原子性?
synchronized、ReentrantLock:可见性、原子性
用到的一些开源框架,介绍一个看过源码的,内部实现过程。
okhttp
消息机制实现
handler机制
ReentrantLock的内部实现
??
断点续传的实现&设计一个下载器
首先定义下载的相关类,存储url、文件总大小、已经下载的文件大小等信息:
public class FileInfo implements Serializable{
private String url; //URL
private int length; //长度或结束位置
private int start; //开始位置
private int now;//当前进度
//构造方法,set/get略
}
启动开始下载的监听事件:
//开始按钮逻辑,停止逻辑大致相同
strat.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
Intent intent = new Intent(MainActivity.this,DownLoadService.class);
intent.setAction(DownLoadService.ACTION_START);
intent.putExtra("fileUrl",info);
startService(intent);
}
});
使用intent来启动service。
然后在Service中的onStartCommand()中,将FileInfo对象从Intent中取出,如果是开始命令,则开启一个线程,根据该url去获得要下载文件的大小,将该大小写入对象并通过Handler传回Service,同时在本地创建一个相同大小的本地文件。暂停命令最后会讲到。
public void run() {
HttpURLConnection urlConnection = null;
RandomAccessFile randomFile = null;
try {
URL url = new URL(fileInfo.getUrl());
urlConnection = (HttpURLConnection) url.openConnection();
urlConnection.setConnectTimeout(3000);
urlConnection.setRequestMethod("GET");
int length = -1;
if (urlConnection.getResponseCode() == HttpStatus.SC_OK) {
//获得文件长度
length = urlConnection.getContentLength();
}
if (length <= 0) {
return;
}
//创建相同大小的本地文件
File dir = new File(DOWNLOAD_PATH);
if (!dir.exists()) {
dir.mkdir();
}
File file = new File(dir, FILE_NAME);
randomFile = new RandomAccessFile(file, "rwd");
randomFile.setLength(length);
//长度给fileInfo对象
fileInfo.setLength(length);
//通过Handler将对象传递给Service
mHandle.obtainMessage(0, fileInfo).sendToTarget();
} catch (Exception e) {
e.printStackTrace();
} finally { //流的回收逻辑略
}
}
}
获取到文件的大小之后就可以开始下载了,当用户点击了暂停之后将截止暂停时对应的已下载进度、url等信息保存起来(另外的文件或数据库)并结束下载进程,当用户点击了继续下载的按钮后从文件或数据库中将之前的下载进度读取出来,使用setRequestProperty告知服务器从哪里开始传递数据,传递到哪里结束,然后继续下载,直至最终下载完成。
主要涉及的点:
- 开启service,service中开启下载线程
- getContentLength()获取文件总大小
- RandomAccessFile(file, “rwd”)创建指定大小的文件和随机读写seek(start)
- 保存下载的url和当前的下载进度等信息
- setRequestProperty告诉服务器数据传送的起点
TreeMap具体实现
HashMap不保证数据有序,LinkedHashMap保证数据可以保持插入顺序,而如果我们希望Map可以保持key的大小顺序的时候,我们就需要利用TreeMap了。
Hashtable继承Dictionary类,同样是通过key-value键值对保存数据的数据结构。Hashtable和HashMap最大的不同是Hashtable的方法都是同步的,在多线程中,你可以直接使用Hashtable,而如果要使用HashMap,则必须要自己实现同步来保证线程安全。当然,如果你不需要使用同步的话,HashMap的性能是肯定优于Hashtable的。此外,HashMap是接收null键和null值的,而Hashtable不可以。
Android的多点触控如何传递
在onTouch(Event event)中通过event.getPointerCount,可以获得触摸点的个数,通过event.getX(index),添加索引可以获得不同控制点的坐标,然后做自己需要的事情。
onTouchEvent()、onTouch()、onClick()、onLongClick()的先后顺序
安卓中view和viewGroup在点击的时候有两个方法,onTouch和onTouchEvent
onTouch是设置了onTouchLisenter之后的回调方法。如果设置了onTouchLisenter就会调用ontouch方法,同时onTouchEvent方法不会再被调用
如果没有设置onTouchLisenter,就会调用onTouchEvent。就是说ontouch的优先级比onTouchEvent高。
onClickLisenter是在onTouchEvent中被调用的,优先级最低
事件传递的顺序:onTouch/onTouchEvent—>Action_Down—>Action_Move—>Action_Up
Action_Down—>Action_Move—>onLongCLick()—>Action_Up
Action_Down—>Action_Move—>Action_Up—>onCLick()
返回true表示消费了该事件,不会再继续向下传递。
onTouch/onTouchEvent—>onLongClick—>onCLick
如何保证Service不被杀死?如何保证进程不被杀死?
1、单例模式:好几种写法,要求会手写,分析优劣。一般双重校验锁中用到volatile,需要分析volatile的原理
2、观察者模式:要求会手写,有些面试官会问你在项目中用到了吗?实在没有到的可以讲一讲EventBus,它用到的就是观察者模式
3、适配器模式:要求会手写,有些公司会问和装饰器模式、代理模式有什么区别?
4、建造者模式 工厂模式:要求会手写
HashMap、LinkedHashMap、ConcurrentHashMap,在用法和原理上有什么差异,很多公司会考HashMap原理,通过它做一些扩展,比如中国13亿人口年龄的排序问题,年龄对应桶的个数,年龄相同和hash相同问题类似。
2、ArrayList和LinkedList对比,这个相对简单一点。
3、平衡二叉树、二叉查找树、红黑树,这几个我也被考到。
4、Set原理,这个和HashMap考得有点类似,考hash算法相关,被问到过常用hash算法。HashSet内部用到了HashMap
前台切换到后台,然后再回到前台,Activity生命周期回调方法。弹出Dialog,生命值周期回调方法。
resume正常前台状态
pause半透明、半覆盖状态
stop后台状态
企业级产品中apk的大小至关重要,请提出不少于5个方案,如何缩减apk包大小
- 复用系统资源
- 注意资源文件的放置位置
- 一些非必须文件用户安装后从网络下载
- 对图片等资源进行必要压缩
- 减少重复sdk的使用,对于功能相似的sdk只保留一个
- 去除不必要的依赖,比如support包下有语言依赖包,去除我们不需要的语言
- 代码混淆
SDK设计
今日头条要提供给第三方应用开屏广告SDK(App启动闪屏时出现的全屏广告),如果你是开屏广告SDK的设计者,要求开屏广告SDK有请求网络、展示图片、点击图片跳转、定时跳过的功能,并暴露相应的接口提供给第三方使用,请问:
1)请列举出开屏广告SDK应有的模块,并简述模块功能及实现方式;
2)请设计出SDK暴露给用户的接口;
简述Activity、Window、WindowManager、WindowManagerImpl、View、ViewRootImpl的作用和相互之间的关系。
View:最基本的UI组件,表示屏幕上的一个矩形区域。
Window: 一个抽象基类,唯一的实现类时PhoneWindow,表示一个窗口,包含一个View tree和窗口的layout 参数。View tree的root View可以通过getDecorView得到。还可以设置Window的Content View。
Activity包含一个Window,该Window在Activity的attach方法中通过调用PolicyManager.makeNewWindow创建。
WindowManager:一个interface,继承自ViewManager。 有一个implementation class:android.view.WindowManagerImpl。其实WindowManager并不是整个系统的窗口管理器,而是所在应用进程的窗口管理器。系统全局的窗口管理器运行在SystemServer进程中,是一个Service。ViewRoot通过IWindowSession接口与全局窗口管理器进行交互。 将一个View add到WindowManager时,WindowManagerImpl创建一个ViewRoot来管理该窗口的根View。,并通过ViewRoot.setView方法把该View传给ViewRoot。
ViewRoot用于管理窗口的根View,并和global window manger进行交互。ViewRoot中有一个nested class: W,W是一个Binder子类,用于接收global window manager的各种消息, 如按键消息, 触摸消息等。 ViewRoot有一个W类型的成员mWindow,ViewRoot在Constructor中创建一个W的instance并赋值给mWindow。 ViewRoot是Handler的子类, W会通过Looper把消息传递给ViewRoot。 ViewRoot在setView方法中把mWindow传给sWindowSession。
总之,每个窗口对应着一个Window对象,一个根View和一个ViewRoot对象。要想创建一个窗口,可以调用WindowManager的addView方法,作为参数的view将作为在该窗口上显示的根view。
APP路由设计
App 发展到一定程度时,页面越来越多,工程越来越大,合作开发的人也越来越多,这时就可能需要引入路由系统,实现模块间的解耦。请设计一个路由系统,使得app内页面的跳转就像浏览器访问网页一样易于管理和解耦。
使用注解将当前Activity加入到Map
列表卡顿怎么优化?首先卡顿怎么量化;其次怎么发现造成卡顿的原因;针对可能发现的问题,又如何解决?请设计一套方案。
如何量化卡顿:android中会每隔16ms重绘一次我们的界面,因为android设置的刷新率是60FPS(Frame Per Second),也就是一秒钟刷新16次,大概就是16ms刷新一次,如果我们的页面/列表没有在16ms内重绘完成,就会出现掉帧现象,即至少下一个16ms之后(也可能更多)用户才能看到刷新的结果,这样用户就会感觉到卡顿。
一个view的重绘主要经历这样几个耗时阶段:Measure、Layout、Draw,如果这三个阶段加起来耗费的事件超过了16ms则一定会卡顿我们可以用Hierarchy View这类工具探测一下当前界面的views在这三个阶段耗费的平均时间,然后在对应时间过长的阶段优化。
造成卡顿的原因:
-
布局复杂
一般来说CPU负责UI布局的Mesure、layout、draw计算,GPU负责根据计算结果绘制UI,如果Mesure、layout、draw这些阶段执行的操作过于耗时,就会导致CPU的计算耗时大于16ms造成卡顿,这种情况可以用用Hierarchy View这类工具探测耗时时间;
优化方案:减少Mesure、layout、draw中的耗时操作,优化算法
-
过度绘制(overdraw)
理想情况下屏幕上每个像素点在每一帧都只应该被绘制一次,如果绘制多次就出现了过度绘制现象,可以通过开启手机的开发者选项—>GPU过度绘制来查看当前界面的过度绘制情况,理想情况下一个像素点只绘制一次才是正常的。这种情况一般是因为多次绘制了背景或者绘制了不可见的view。
优化方案:取消被覆盖控件的背景,比如一个Fragment在ViewPager上,这时应该取消ViewPager的背景,另外Activity默认情况下, theme会给window设置一个纯色的背景,如果想取消这个背景可以在manifest中设置:
- @null
或者在代码中:
getWindow().setBackgroundDrawable(null); -
Ui线程复杂的运算
UI线程进行耗时操作会阻塞Looper.loop()中的循环,自然会造成卡顿。
优化方案:使用子线程执行耗时操作,使用Handler回传处理结果。
-
频繁的GC
执行GC操作的时候,任何线程的任何操作都会需要暂停,等待GC操作完成之后,其他操作才能够继续运行, 故而如果程序频繁GC, 自然会导致界面卡顿.这种情况一般是在短时间内瞬间new了很多对象然后在短时间内又被释放了,这就是内存抖动。
优化方案:不在OnDraw这类频繁调用的方法中new很多对象。
插件化 组件化 热修复
- 1.插件化:随着apk越来越大,各种业务逻辑越来越繁杂,会达到apk开发的一个瓶颈;从业务上说,业务的繁杂会导致代码急剧的膨胀,当代码中的方法数超过65535时,就无法再容纳创建新的方法。插件化时将 apk 分为宿主和插件部分,插件在需要的时候才加载进来。
- 2.组件化(Module):其实和插件化类似,主要用于解耦模块,随着APP版本不断的迭代,新功能的不断增加,业务也会变的越来越复杂,APP业务模块的数量有可能还会继续增加,而且每个模块的代码也变的越来越多,这样发展下去单一工程下的APP架构势必会影响开发效率,增加项目的维护成本,每个工程师都要熟悉如此之多的代码,将很难进行多人协作开发,而且Android项目在编译代码的时候电脑会非常卡,又因为单一工程下代码耦合严重,每修改一处代码后都要重新编译打包测试,导致非常耗时,最重要的是这样的代码想要做单元测试根本无从下手,所以必须要有更灵活的架构代替过去单一的工程架构。
- 3.热修复:热修复说白了就是”打补丁”,比如你们公司上线一个app,用户反应有重大bug,需要紧急修复。如果按照通常做法,那就是程序猿加班搞定bug,然后测试,重新打包并发布。这样带来的问题就是成本高,效率低。于是,热修复就应运而生.一般通过事先设定的接口从网上下载无Bug的代码来替换有Bug的代码。这样就省事多了,用户体验也好。
- 模块化
android中的classLoader和java的classLoader有什么不同
为什么android中方法数最多只能有64k=65532个?
android中的方法都是通过invoke-kind指令调用的,invoke-kind指令中有一个参数是需要调用方法的索引,根据这个索引去找方法并调用,巧的是这个参数是16位的,所以最多只能存 2 16 = 2 10 ∗ 2 6 = 1 k ∗ 2 6 = 64 k 2^{16}=2^{10}*2^6=1k*2^6=64k 216=210∗26=1k∗26=64k.
接口和抽象类的区别
怎样做系统调度。
简述Android的View绘制流程,Android的wrap_content是如何计算的。
ViewGroup.LayoutParams
数组实现队列。
HashMap
singleTask启动模式
集合的接口和具体实现类,介绍
synchronized与ReentrantLock
重要:手写生产者/消费者模式、单例模式
生产者和消费者的精髓是:
不同线程操作同一对象的不同方法,但是要保持其互斥,也不能出现死锁的情况,条件满足就通知其他等待的线程 ,条件不满足,就休眠等待。
在Thread-1的生产者只负责生产,在Thread-2的消费者则只负责消费,操作互斥,当生产者达到上限则进行等待,反之消费者达到上限所有线程就等待。
- 生产者持续生产,直到缓冲区满,阻塞;缓冲区不满后,继续生产
- 消费者持续消费,直到缓冲区空,阻塞;缓冲区不空后,继续消费
- 生产者可以有多个,消费者也可以有多个
android中最经典的就是Handler机制,android中有三种方式可以在非UI线程更新UI:
- view.post()
- runOnUi()
- handler
其实前两种方法的底层都是通过handler机制实现的,handler维护了一个messagequeue和Loop,这里的enqueueMessage就相当于生产者,而next就相当于消费者。
逻辑地址与物理地址,为什么使用逻辑地址
一个无序,不重复数组,输出N个元素,使得N个元素的和相加为M,给出时间复杂度、空间复杂度。手写算法
Android进程分类
Activity的启动模式
有了解过注解么?(了解过,注释是给人看的,注解给机器看的,override,压制警告之类的)
自定义注解?(@interface) 具体的实现原理(不知道) 源代码阶段还是编译时还是运行时(我说编译时,好像不对?)
消息机制实现
ReentrantLock的内部实现
二叉树,给出根节点和目标节点,找出从根节点到目标节点的路径。手写算法
断点续传的实现
逻辑地址与物理地址,为什么使用逻辑地址
前台切换到后台,然后再回到前台,Activity生命周期回调方法。弹出Dialog,生命值周期回调方法。
AIDL的基本流程(如何实现AIDL),不用AIDL是否可以实现进程间通讯,用什么,如何实现
19年面试真题
Thread、Process的区别(字节跳动-抖音-一面)
进程和线程的主要差别在于它们是不同的操作系统资源管理方式。进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响,而线程只是一个进程中的不同执行路径。线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间,一个线程死掉(将地址空间写坏)就等于整个进程死掉,所以多进程的程序要比多线程的程序健壮,但在进程切换时,耗费资源较大,效率要差一些。但对于一些要求同时进行并且又要共享某些变量的并发操作,只能用线程,不能用进程。
1) 简而言之,一个程序至少有一个进程,一个进程至少有一个线程.
-
线程的划分尺度小于进程,使得多线程程序的并发性高。
-
另外,进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率。
-
线程在执行过程中与进程还是有区别的。每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。**但是线程不能够独立执行,**必须依存在应用程序中,由应用程序提供多个线程执行控制。
-
从逻辑角度来看,多线程的意义在于一个应用程序中,有多个执行部分可以同时执行。但操作系统并没有将多个线程看做多个独立的应用,来实现进程的调度和管理以及资源分配。这就是进程和线程的重要区别。
线程和进程在使用上各有优缺点:线程执行开销小,但不利于资源的管理和保护;而进程正相反。同时,线程适合于在SMP机器上运行,而进程则可以跨机器迁移。
singleThreadpool什么场景下使用,只有一个线程为什么不直接使用new Thread()(字节跳动-抖音-一面)
Android中单线程可用于数据库操作,文件操作,应用批量安装,应用批量删除等不适合并发但可能IO阻塞性的操作。
简单说下线程池管理的线程的几点意义:
1、缓存线程、进行池化,可实现线程重复利用、避免重复创建和销毁所带来的性能开销。(如楼主理解的)
2、当线程调度任务出现异常时,会重新创建一个线程替代掉发生异常的线程。
3、任务执行按照规定的调度规则执行。线程池通过队列形式来接收任务。再通过空闲线程来逐一取出进行任务调度。即线程池可以控制任务调度的执行顺序。
4、可制定拒绝策略。即任务队列已满时,后来任务的拒绝处理规则。
以上意义对于singleThreadExecutor来说也是适用的。普通线程和线程池中创建的线程其最大的区别就是有无一个管理者对线程进行管理。
TCP三次握手、四次挥手(字节跳动-抖音-一面、二面)
三次握手
1:client:SYN=1,序列号(seq)=J(随机生成),发送完成后处于Syn_sent状态
2:server:接收到client发送的报文,处于Syn_rcvd状态,然后发送回应报文,ACK=1,确认序列号(ack)=J 1,SYN=1,序列号(seq)=K(随机生成)
3:client:接收到server的回应报文,处于Established状态,发送确定连接报文:ACK=1,确认序号(ack)=K 1,server接收到后处于Established状态
此时client和server都处于Established状态,建立连接成功
四次挥手
1:client:发送Fin=1,ack=A,seq=B,进入Fin_Wait_1状态
2:server:发送ack=B 1,seq=A,进入Close_Wait状态
3:server:发送Fin=1,ack=B,seq=D,进入Time_Wait状态
4:client:发送ack=D,seq=B,进入Closed状态
TCP中常见状态:
各个状态的意义如下:
LISTEN - 侦听来自远方TCP端口的连接请求;
SYN-SENT -在发送连接请求后等待匹配的连接请求;
SYN-RECEIVED - 在收到和发送一个连接请求后等待对连接请求的确认;
ESTABLISHED- 代表一个打开的连接,数据可以传送给用户;
FIN-WAIT-1 - 等待远程TCP的连接中断请求,或先前的连接中断请求的确认;
FIN-WAIT-2 - 从远程TCP等待连接中断请求;
CLOSE-WAIT - 等待从本地用户发来的连接中断请求;
CLOSING -等待远程TCP对连接中断的确认;
LAST-ACK - 等待原来发向远程TCP的连接中断请求的确认;
TIME-WAIT -等待足够的时间以确保远程TCP接收到连接中断请求的确认;
CLOSED - 没有任何连接状态;
计算机网络为什么是三次握手不是两次握手?请求方式(post、get)是放在哪个部分发送出去的(考察http协议的格式)(字节跳动-抖音-一面)?
第一次连接请求报文由于网络节点长时间滞留了,导致延误到连接释放后的某个时间才到达 Server。这时 Server 会再次给 Client 发送确认报文(第二次握手),但是 Client 进程程序并不会理睬确认报文,因为 Client 没有发送连接请求。现在假如没有第三次握手就会建立连接,那么这次滞后的连接请求报文就会导致 TCP 误建立连接,而 Client 却不知已经建立连接,并不会发送数据给 Server,这样 Server 就会一直处于等待状态,这样就白白浪费了 Server 的很多资源。但有了第三次握手就会避免这种问题的发生,虽然延迟的连接请求发送到了 Server,但 Client 不会处理 Server 的确认报文,也不会再次发送确认请求报文,这样 Server 就知道了 Client 并没有真正想建立连接。
HTTP协议的格式
HTTP请求
请求行:三个部分组成:第一部分是请求方法,第二部分是请求网址,第三部分是HTTP版本
请求头:请求头(request header) ;普通头(general header) ;实体头(entity header)
内容:通常来说,由于GET请求往往不包含内容实体,因此也不会有实体头。 第三部分内容只在POST请求中存在,因为GET请求并不包含任何实体
HTTP响应
状态行:第一部分是HTTP版本,第二部分是响应状态码,第三部分是状态码的描述
HTTP头:响应头(response header) ;普通头(general header) ;实体头(entity header)
内容:响应内容就是HTTP请求所请求的信息。这个信息可以是一个HTML,也可以是一个图片
【算法】二叉树中序遍历(字节跳动-抖音-一面)
void InOrderTraverse2(BiTree biTree) {
if (biTree == NULL) {
cout << "该树为空,无法遍历!" << endl;
}
stack<BiNode *> stack1;
BiNode *biNode = biTree;
while (biNode != NULL || !stack1.empty()) {
if (biNode != NULL) {
stack1.push(biNode);
biNode = biNode->lchild;
} else {
biNode = stack1.top();
stack1.pop();
cout << biNode->data << " ";
biNode = biNode->rchild;
}
}
}
【算法】判断平衡二叉树(字节跳动-抖音-二面)
递归求解或者层次遍历求解。
Px、dp、sp的区别(字节跳动-抖音-二面)
DP
这个是最常用但也最难理解的尺寸单位。它与“像素密度”密切相关,所以
首先我们解释一下什么是像素密度。假设有一部手机,屏幕的物理尺寸为1.5英寸x2英寸,屏幕分辨率为240x320,则我们可以计算出在这部手机的屏幕上,
每英寸包含的像素点的数量为240/1.5=160dpi(横向)或320/2=160dpi(纵向),160dpi就是这部手机的像素密度,像素密度的单位dpi是Dots Per Inch的缩写,即每英寸像素数量。
横向和纵向的这个值都是相同的,原因是大部分手机屏幕使用正方形的像素点。
不同的手机/平板可能具有不同的像素密度,例如同为4寸手机,有480x320分辨率的也有800x480分辨率的,前者的像素密度就比较低。
Android系统定义了四种像素密度:低(120dpi)、中(160dpi)、高(240dpi)和超高(320dpi),它们对应的dp到px的系数分别为0.75、1、1.5和2,这个系数乘以dp长度就是像素数。
例如界面上有一个长度为“80dp”的图片,那么它在240dpi的手机上实际显示为80x1.5=120px,在320dpi的手机上实际显示为80x2=160px。
如果你拿这两部手机放在一起对比,会发现这个图片的物理尺寸“差不多”,这就是使用dp作为单位的效果
dip:
Density independent pixels ,设备无关像素。
与dp完全相同,只是名字不同而已。在早期的Android版本里多使用dip,后来为了与sp统一就建议使用dp这个名字了
px:
即像素,1px代表屏幕上一个物理的像素点;
px单位不被建议使用,因为同样100px的图片,在不同手机上显示的实际大小可能不同,如下图所示
sp:
与缩放无关的抽象像素(Scale-independent Pixel)。
sp和dp很类似但唯一的区别是,Android系统允许用户自定义文字尺寸大小(小、正常、大、超大等等),当文字尺寸是“正常”时1sp=1dp=0.00625英寸,而当文字尺寸是“大”或“超大”时,1sp>1dp=0.00625英寸。
类似我们在windows里调整字体尺寸以后的效果——窗口大小不变,只有文字大小改变。
最佳实践,文字的尺寸一律用sp单位,非文字的尺寸一律使用dp单位。
例如textSize=“16sp”、layout_width=“60dp”;偶尔需要使用px单位,例如需要在屏幕上画一条细的分隔线
换算:
px = dp * dpi /160
dp = px * 160 / dpi
px = dp *(context.getResources().getDisplayMetrics().density ) 0.5
为啥 标准dpi = 160
- Android Design [1] 里把主流设备的 dpi 归成了四个档次,120 dpi、160 dpi、240 dpi、320 dpi
实际开发当中,我们经常需要对这几个尺寸进行相互转换(比如先在某个分辨率下完成设计,然后缩放到其他尺寸微调后输出),一般按照 dpi 之间的比例即 2:1.5:1:0.75 来给界面中的元素来进行尺寸定义。
也就是说如果以 160 dpi 作为基准的话,只要尺寸的 DP 是 4 的公倍数,XHDPI 下乘以 2,HDPI 下乘以 1.5,LDPI 下乘以 0.75 即可满足所有尺寸下都是整数 pixel 。
但假设以 240 dpi 作为标准,那需要 DP 是 3 的公倍数,XHDPI 下乘以 1.333,MDPI 下乘以 0.666 ,LDPI 下除以 2
而以 LDPI 和 XHDPI 为基准就更复杂了,所以选择 160 dpi
- 这个在Google的官方文档中有给出了解释,因为第一款Android设备(HTC的T-Mobile G1)是属于160dpi的。
java中有哪几种变量修饰符,有什么区别,protected是否是包级可见的(字节跳动-抖音-二面)
- public 公有访问修饰符。该修饰符修饰的变量称为公有变量,如果公有变量又在一个公有类(被public修饰的类)中,那么这个变量可以被所有包中的所有类访问;
- protected 保护访问修饰符。 该修饰符修饰的成员变量若在一个公有类中,那么它可以被所在的类本身,同一个包中的所有类,其他包中该类的子类访问。
- 默认访问修饰符。如果成员变量前没有访问修饰符,那么它为友好成员,他可以被同一个包中的所有类访问。
- private 私有访问修饰符。 该修饰符修饰的成员只能被他所在的类访问,任何其他的类都不能访问,包括它的子类。在实际项目中,最好把一个类的实例变量(不被static修饰的变量)设置为private,并在方法中设置setXXX() 和 getXXX()这样的方法进行访问。这样做有助于对客户隐蔽类的实现细节,减少错误,提高程序可修改性。
synchronized对普通方法、静态方法加锁有什么区别(字节跳动-抖音-二面)
Synchronized修饰非静态方法,是对调用该方法的对象加锁,俗称“对象锁”。
这里的对象加锁并非是说执行该加锁方法的时候整个对象的所有成员都不允许其他线程访问了,
而是说该对象内所有的加锁的非静态方法共用这一把锁, 一个加锁非静态方法执行, 另一个加锁非静态方法不能执行,要等持有锁的线程释放锁, 不同对象之间的方法不互相作用
Synchronized修饰静态方法,是对该类对象加锁,俗称“类锁”。
同样, 这里的对象加锁并非是说执行该加锁方法的时候整个类的所有(静态)成员都不允许其他线程访问了,
而是说该类内所有的加锁的静态方法共用这一把锁, 一个加锁静态方法执行, 同类另一个加锁静态方法不能执行,要等持有锁的线程释放锁
synchronized methods() {} 与 synchronized (this) {} 之间并没有什么区别。
只是前者便于阅读理解,而后者可以更精确的控制冲突限制访问区域(粒度更小),锁的范围没有变,锁住的时间变短了因而性能更好。
上述都是使用synchronized(this)的格式来同步代码块,但JAVA还支持对"任意对象"作为对象监视器来实现同步的功能。这个"任意对象"大多数是实例变量及方法的参数,使用格式为synchronized(非this对象)。
其实同理,锁住的不是当前实例对象,而是放入synchronized(非this对象)中的非this对象(与该非this对象的其他加锁方法共用锁),即对该非this对象进行加锁。
Activity启动模式的解释(字节跳动-抖音-二面)
- standard
- singleTop
- singleTask
- singleInstance
java中保持线程同步的方式(考察锁)(字节跳动-抖音-二面)
- synchronized
- reentrantLock
- volitile
java的四种引用(字节跳动-抖音-二面)
- 强引用
- 软引用
- 弱引用
- 虚引用
kotlin和java比的异同点(字节跳动-抖音-二面)
kotlin相比于java的优点:
-
空安全
java中经常遇到空指针的问题,如果要保证安全往往需要我们自己添加if判空,kotlin中用一个操作符“ ?”来明确指定一个对象,或者一个属性变量是否可以为空:
var user1:User=null;//编译不通过 var user2:User;//编译不通过 var user3:User?=null;//编译通过 user.print();//无法编译,user可能为空,无法打印 user?.print();//如果user不为空才打印 // 智能转换. 如果我们在之前进行了空检查,则不需要使用安全调用操作符调用 if (users != null) { users.print() } // 只有在确保users不是null的情况下才能这么调用,否则它会抛出异常 users!!.print() -
拓展方法的支持
-
我们可以给任何类添加函数,它比那些我们项目中典型的工具类更加具有可读性
比如我们想给Fragment增加一个toast方法:
fun Fragment.toast(message: String, duration: Int = Toast. LENGTH_SHORT) { Toast.makeText(getActivity(), message, duration).show() }然后我们就可以这样调用
fragment.toast("弹个吐司看看") -
函数式支持
java中设置点击事件一般需要实现匿名内部类(onClickListener),在kotlin中:
view.setOnClickListener { toast("Hello world!") }
kotlin相比于java的缺点:
虽然很多时候方便了代码的编写、减少了代码量,但是回降低可读性,比如:
java中的switch语句:
private void test(int value) {
switch (value) {
case 10:
println("数字10");
break;
case 20:
println("数字20");
break;
case 30:
println("数字30");
break;
default:
println("未知数");
}
}
kotlin中的:
fun test(value: Int){
when(value){
10,20 -> println("共用一个处理逻辑");
30 -> println("数字30");
else ->{
println("未知数");
}
}
}
okHttp源码理解(字节跳动-抖音-二面,腾讯-微信-一面)
数据库索引、事物的概念(字节跳动-抖音-三面Leader面)
关系型数据库中的主键是什么(字节跳动-抖音-三面Leader面)
SQL语句的基本结构(字节跳动-抖音-三面Leader面)
java里面有没有类似c 的析构函数的东西(字节跳动-抖音-三面Leader面)
java中每个类都默认有一个protected void finalize()方法,之所以要有finalize(),不是为了释放java资源,因为java资源有gc去处理,是由于在分配本地内存时可能采用了类似C语言中的做法,而非Java中的通常做法。这种情况主要发生在使用“本地方法”的情况下,本地方法是一种在Java中调用非Java代码的方式。本地方法目前只支持C和C ,但它们可以调用其他语言写的代码,所以实际上可以调用任何代码。在非Java代码中,也许会调用C的malloc()函数系列来分配存储空间,而且除非调用了free()函数,否则存储空间将得不到释放,从而造成内存泄露。当然,free()是C和C 中的函数,所以要在finalize()中用本地方法调用它。
c 中参数传递有哪几种方式?java呢?(字节跳动-抖音-三面Leader面)
在C/C 中,参数传递分为两种:值传递和地址传递
Java中不存在指针,也就不存在地址传递,Java的参数传递分为:值传递和引用传递
值传递就是将实参的数值拷贝一份到栈中新的一块内存区域中传入,方法里面对这种形式传入的参数的改变均是对实参的拷贝的改变,不会影响实参的数值;
引用传递,当我们使用new关键字实例化对象后,该对象是存储在堆区中的,栈区只是存储该对象的引用(地址),当我们将该对象作为实参传入方法后也会在栈中开辟一块新内存然后将实参的值拷贝进去,但是这次拷贝的是实际对象的地址(引用),所以在子方法中可以对该对象进行改变。
关于深拷贝和浅拷贝:
在 Java 中,除了基本数据类型(元类型)之外,还存在 类的实例对象 这个引用数据类型。而一般使用 『 = 』号做赋值操作的时候。对于基本数据类型,实际上是拷贝的它的值,但是对于对象而言,其实赋值的只是这个对象的引用,将原对象的引用传递过去,他们实际上还是指向的同一个对象。
而浅拷贝和深拷贝就是在这个基础之上做的区分,如果在拷贝这个对象的时候,只对基本数据类型进行了拷贝,而对引用数据类型只是进行了引用的传递,而没有真实的创建一个新的对象,则认为是浅拷贝(方法中传入的实参默认就是浅拷贝)。反之,在对引用数据类型进行拷贝的时候,创建了一个新的对象,并且复制其内的成员变量,则认为是深拷贝。
所以想要实现在java方法中传入对象的拷贝而不是引用,就应该考虑使用深拷贝:
首先继承Cloneable接口,然后重写protected Object clone()方法,在clone方法中进行深拷贝的逻辑,如果当前类中只有基本数据类型,那么大可不用重写,如果当前类中有别的类的成员变量,那么应该在当前类的clone方法中调用子类的clone赋值给当前类的成员变量,达到深拷贝的目的。
public CloneDemoChild cloneDemoChild;
public int b;
@Override
protected Object clone() throws CloneNotSupportedException {
CloneDemo cloneDemo= (CloneDemo) super.clone();
cloneDemo.cloneDemoChild= (CloneDemoChild) cloneDemo.cloneDemoChild.clone();
return cloneDemo;
}
c 和java有什么区别?(字节跳动-抖音-三面Leader面)
关键字:在Java中,protected关键字是对所有的子类以及同一个package中的所有的其他类可见;在C 中,protected关键字只对子类是可见的。这样看来Java中protected的保护的安全性,比C 要差。
析构函数:构造函数都是相同的 (即类的名字), Java没有准确意义上的的析构函数.
内存管理:大体上是相同的–new 来分配, 但是 Java没有 delete,因为它有垃圾回收器。
Java为解释性语言,其运行过程为:程序源代码经过Java编译器编译成字节码,然后由JVM解释执行。而C/C 为编译型语言,源代码经过编译和链接后生成可执行的二进制代码,可直接执行。因此Java的执行速度比C/C 慢,但Java能够跨平台执行,C/C 不能。
C 支持多继承,java不支持多继承,但是引入了接口的概念。
Android中除了线程池还有哪些多线程的实现方式?(字节跳动-抖音-三面Leader面)
- Activity.runOnUiThread(Runnable)
- View.post(Runnable) ;View.postDelay(Runnable , long)
- Handler
- AsyncTask
AsyncTask是否可以异步?为什么?有没有看过AsyncTask的源码?(字节跳动-抖音-三面Leader面)
介绍一下http协议(字节跳动-抖音-三面Leader面)
http各个状态码的意义(字节跳动-抖音-三面Leader面)
1 :继续
2 :成功
3 :重定向
4 :请求错误
5: 服务器内部错误
计算机网络中的重定向是什么(字节跳动-抖音-三面Leader面)
URL 重定向,也称为 URL 转发,是一种当实际资源,如单个页面、表单或者整个 Web 应用被迁移到新的 URL 下的时候,保持(原有)链接可用的技术。HTTP 协议提供了一种特殊形式的响应—— HTTP 重定向(HTTP redirects)来执行此类操作,该操作可以应用于多种多样的目标:网站维护期间的临时跳转,网站架构改变后为了保持外部链接继续可用的永久重定向,上传文件时的表示进度的页面,等等。
【算法】DFS考察
一个二维数组,数组中的内容非0即1,0代表海洋,1代表陆地,求所给二维数组代表的区域中陆地面积的最大值。
android中如何计算当前view的子view的数量?(字节跳动-抖音-四面)
ViewGroup viewGroup= (ViewGroup) view;
viewGroup.getChildCount();
先转化为viewGroup,再调用其getChildCount方法。
okhttp中连接池的最大数量,连接池的实现原理(腾讯-微信-一面)
有两个View:view1和view2,view2在view1上面且比view1小,如何判断点击view1之内的屏幕是应该由view1处理事件还是由view2处理(腾讯-微信-一面)
双亲委托,先分发给view2,让view2决定是否拦截,如果view2不拦截,则view1拦截,至于如何让view2决定是否拦截还没思路。
NDK是否可以加载任意目录下的so文件,so文件有几种加载方式(腾讯-微信-一面)
ndk加载so时如何考虑32位和64位的不同,如何考虑不同的arm平台(腾讯-微信-一面)
自定义view的方法,为什么在ondraw中绘制即可产生相应效果,什么时候使用自定义view什么时候使用原生view(腾讯-微信-一面)
sqlite是不是线程同步的(腾讯-微信-一面)
有没有对比过flutter和其他跨平台方案有什么异同点(腾讯-微信-一面)
Android中如何自己实现跨线程的通信(蚂蚁金服-支付宝-一面)
使用接口回调的理念
Android中的synchronized和reentrantLock有什么区别(蚂蚁金服-支付宝-一面)
相同点:
这两种同步方式有很多相似之处,它们都是加锁方式同步,而且都是阻塞式的同步,也就是说当如果一个线程获得了对象锁,进入了同步块,其他访问该同步块的线程都必须阻塞在同步块外面等待,而进行线程阻塞和唤醒的代价是比较高的
不同点:
这两种方式最大区别就是对于Synchronized来说,它是java语言的关键字,是原生语法层面的互斥,需要jvm实现。而ReentrantLock它是JDK 1.5之后提供的API层面的互斥锁,需要lock()和unlock()方法配合try/finally语句块来完成。
ReentrantLock相比synchronized的高级功能:
- 等待可中断,持有锁的线程长期不释放的时候,正在等待的线程可以选择放弃等待,这相当于Synchronized来说可以避免出现死锁的情况。
- 公平锁,多个线程等待同一个锁时,必须按照申请锁的时间顺序获得锁,Synchronized锁非公平锁,ReentrantLock默认的构造函数是创建的非公平锁,可以通过参数true设为公平锁,但公平锁表现的性能不是很好。
- 锁绑定多个条件,一个ReentrantLock对象可以同时绑定多个对象。
- 在资源竞争不是很激烈的情况下,Synchronized的性能要优于ReetrantLock,但是在资源竞争很激烈的情况下,Synchronized的性能会下降几十倍,但是ReetrantLock的性能能维持常态;
一个线程中可以有几个handler?几个Looper?几个messageQueue?(蚂蚁金服-支付宝-一面)
一个线程只能有一个Looper,因为在Thread中是用ThreadLocal
因为一个线程只有一个Looper,所以一个线程只有一个MessageQueue。
一个线程可以存在多个handler,一个handler发送的消息只会被自己接收,我们可以在发送Message的时候使用message.setTarget(Handler handler)方法设置当前message的target handler,这样在Looper.loop方法中,线程建立消息循环机制,循环从MessageQueue获取Message对象,调用msg.target.dispatchMessage(msg)就可以把当前消息发送给其targetHandler。
Handler机制介绍(蚂蚁金服-支付宝-一面)
AsyncTask原理介绍,其实串行的还是并行的?如何进行并行操作?(蚂蚁金服-支付宝-一面)
数据库如何短时间高效批量插入数据?(蚂蚁金服-支付宝-一面)
使用SQLiteDatabase的insert,delete等方法或者execSQL方法默认都开启了事务,如果操作的顺利完成才会更新.db数据库。事务的实现是依赖于名为rollback journal文件,借助这个临时文件来完成原子操作和回滚功能。
可以在/data/data//databases/目录下看到一个和数据库同名的.db-journal文件。
SQLite想要执行操作,需要将程序中的SQL语句编译成对应的SQLiteStatement,比如" select * from table1 ",每执行一次都需要将这个String类型的SQL语句转换成SQLiteStatement。如下insert的操作最终都是将ContentValues转成SQLiteStatementi,对于批量处理插入或者更新的操作,我们可以重用SQLiteStatement,使用SQLiteDatabase的beginTransaction()方法开启一个事务,样例如下:
try
{
sqLiteDatabase.beginTransaction();//开启新事物
SQLiteStatement stat = sqLiteDatabase.compileStatement(insertSQL);
// 插入10000次
for (int i = 0; i < 10000; i )
{
stat.bindLong(1, 123456);
stat.bindString(2, "test");
stat.executeInsert();
}
sqLiteDatabase.setTransactionSuccessful();
}
catch (SQLException e)
{
e.printStackTrace();
}
finally
{
// 结束
sqLiteDatabase.endTransaction();
sqLiteDatabase.close();
}
java静态方法是否可以被重写(蚂蚁金服-支付宝-一面)
不能被重写,虽然我们可以在子类中写和父类函数签名相同的静态方法,但是实际上不是重写,而是隐藏,如果加上@override会报错,因为静态方法只与类相关,不与具体实现相关,用的是什么类,调用的就是什么类的静态方法。
静态内部类和非静态内部类的区别(蚂蚁金服-支付宝-一面)
普通内部类可以获得外部对象的引用,所以在普通内部类能够访问外部对象的成员变量 ,也就能够使用外部类的资源,可以说普通内部类依赖于外部类,普通内部类与外部类是共生共死的,创建普通内部类的对象之前,必须先创建外部类的对象。
静态内部类没有外部对象的引用,所以它无法获得外部对象的资源,当然好处是,静态内部类无需依赖于
外部类,它可以独立于外部对象而存在。创建静态内部类的代码如下:
Outer.Inner inner = new Outer.Inner();
(1)普通内部类不能声明static的方法和变量
普通内部类不能声明static的方法和变量,注意这里说的是变量,常量(也就是final static修饰的属性)
还是可以的,而静态内部类形似外部类,没有任何限制。
(2)使用静态内部类,多个外部类的对象可以共享同一个内部类的对象。
使用普通内部类,每个外部类的对象都有自己的内部类对象,外部对象之间不能共享内部类的对象
使用fragment有什么好处?(蚂蚁金服-支付宝-一面)
- Fragment可以将activity分离成多个可重用的组件,每个都有它自己的生命周期和UI。
- Fragment可以轻松得创建动态灵活的UI设计,可以适应于不同的屏幕尺寸。从手机到平板电脑。
- Fragment是一个独立的模块,紧紧地与activity绑定在一起。可以运行中动态地移除、加入、交换等。
- Fragment 切换流畅,轻量切换。
- Fragment做局部内容更新更方便,原来为了到达这一点要把多个布局放到一个activity里面,现在可以用多Fragment来代替,只有在需要的时候才加载Fragment,提高性能。
有没有使用过嵌套Fragment?(蚂蚁金服-支付宝-一面)
handler.postDelayed中的run是工作在主线程还是子线程(蚂蚁金服-支付宝-一面)
postDelayed中传入的是Runnable对象,而这个开启的runnable会在这个handler所依附线程中运行,而这个handler是在UI线程中创建的,所以自然地依附在主线程中了。
Android中的内存管理(蚂蚁金服-支付宝-一面)
从操作系统的角度来说,内存就是一块数据存储区域,是可被操作系统调度的资源。在多任务(进程)的OS中,内存管理尤为重要,OS需要为每一个进程合理的分配内存资源。所以可以从OS对内存和回收两方面来理解内存管理机制。
- 分配机制:为每一个任务(进程)分配一个合理大小的内存块,保证每一个进程能够正常的运行,同时确保进程不会占用太多的内存。
- 回收机制:当系统内存不足的时候,需要有一个合理的回收再分配机制,以保证新的进程可以正常运行。回收时杀死那些正在占用内存的进程,OS需要提供一个合理的杀死进程机制。
同样作为一个多任务的操作系统,Android系统对内存管理有有一套自己的方法,手机上的内存资源比PC更少,需要更加谨慎的管理内存。理解Android的内存分配机制有助于我们写出更高效的代码,提高应用的性能。
下面分别从 分配 和 回收 两方面来描述Android的内存管理机制:
分配机制
Android为每个进程分配内存时,采用弹性的分配方式,即刚开始并不会给应用分配很多的内存,而是给每一个进程分配一个“够用”的内存大小。这个大小值是根据每一个设备的实际的物理内存大小来决定的。随着应用的运行和使用,Android会为进程分配一些额外的内存大小。但是分配的大小是有限度的,系统不可能为每一个应用分配无限大小的内存。
总之,Android系统需要最大限度的让更多的进程存活在内存中,以保证用户再次打开应用时减少应用的启动时间,提高用户体验。
回收机制
Android对内存的使用方式是“尽最大限度的使用”,只有当内存不足的时候,才会杀死其它进程来回收足够的内存。但Android系统否可能随便的杀死一个进程,它也有一个机制杀死进程来回收内存。
Android杀死进程有两个参考条件:
1. 进程优先级
Android为每一个进程分配了优先组的概念,优先组越低的进程,被杀死的概率就越大。根据进程的重要性,划分为5级:
1)前台进程(Foreground process)
用户当前操作所必需的进程。通常在任意给定时间前台进程都为数不多。只有在内存不足以支持它们同时继续运行这一万不得已的情况下,系统才会终止它们。
2)可见进程(Visible process)
没有任何前台组件、但仍会影响用户在屏幕上所见内容的进程。可见进程被视为是极其重要的进程,除非为了维持所有前台进程同时运行而必须终止,否则系统不会终止这些进程。
3)服务进程(Service process)
尽管服务进程与用户所见内容没有直接关联,但是它们通常在执行一些用户关心的操作(例如,在后台播放音乐或从网络下载数据)。因此,除非内存不足以维持所有前台进程和可见进程同时运行,否则系统会让服务进程保持运行状态。
4)后台进程(Background process)
后台进程对用户体验没有直接影响,系统可能随时终止它们,以回收内存供前台进程、可见进程或服务进程使用。 通常会有很多后台进程在运行,因此它们会保存在 LRU 列表中,以确保包含用户最近查看的 Activity 的进程最后一个被终止。如果某个 Activity 正确实现了生命周期方法,并保存了其当前状态,则终止其进程不会对用户体验产生明显影响,因为当用户导航回该 Activity 时,Activity 会恢复其所有可见状态。
5)空进程(Empty process)
不含任何活动应用组件的进程。保留这种进程的的唯一目的是用作缓存,以缩短下次在其中运行组件所需的启动时间。 为使总体系统资源在进程缓存和底层内核缓存之间保持平衡,系统往往会终止这些进程。
通常,前面三种进程不会被杀死。
2. 回收收益
当Android系统开始杀死LRU缓存中的进程时,系统会判断每个进程杀死后带来的回收收益。因为Android总是倾向于杀死一个能回收更多内存的进程,从而可以杀死更少的进程,来获取更多的内存。杀死的进程越少,对用户体验的影响就越小。
为什么App要符合内存管理机制?
在Android系统中,符合内存管理机制的App,对Android系统和App来说,是一个双赢的过程。如何每一个App都遵循这个规则,那么Android系统会更加流畅,也会带来更好的用户体验,App也可以更长时间的驻留在内存中。
如果真的需要很多内存,可以采用多进程的方式。
如何编写符合Android内存管理机制的App?
一个遵循Android内存管理机制的App应该具有以下几个特点:
1)更少的占用内存;
2)在合适的时候,合理的释放系统资源。
3)在系统内存紧张的情况下,能释放掉大部分不重要的资源,来为Android系统提供可用的内存。
4)能够很合理的在特殊生命周期中,保存或者还原重要数据,以至于系统能够正确的重要恢复该应用。
因此,在开发过程中要做到:
- 避免创建不必要的对象。
- 在合适的生命周期中,合理的管理资源。
- 在系统内存不足时,主动释放更多的资源。
开发时,应该如何注意App的内存管理呢?
1)减少内存资源占用
比如,使用StringBuffer,int等更少内存占用的数据结构。
2)内存溢出
主要是Bitmap。解决办法是:减少每个对象占用的内存,如图片压缩等;申请大内存。
3)内存泄露
内存泄露是指本来该被GC回收后还给系统的内存,并没有被GC回收。多数是因为不合理的对象引用造成的。
解决这种问题:1、通过各种内存分析工具,比如MAT,分析运行时的内存映像文件,找出造成内存泄露的代码,并修改。2、适当的使用WeakReference。
ArrayList和LinkedList的区别?各自的使用场景?(蚂蚁金服-支付宝-一面)
Java gc机制介绍(蚂蚁金服-支付宝-一面)
如何对APK瘦身?(腾讯-音视频实验室-一面)
- 使用混淆
- 删除无用的语言资源(删除国际化文件)
- 使用webp图片格式,进一步压缩图片资源
- 使用第三方包时把用到的代码加到项目中来,避免引用整一个第三方库
- 通过网络下载个别资源
java和c/c 在编译运行上有什么异同点?(腾讯-音视频实验室-一面)
任何一门计算机高级语言都会最终编成机器码(也就是二进制)以后,才会被计算机所识别。其中,与机器码最为接近的就是汇编了,而Java和C 都会直接或间接的变成汇编之后,然后在运行。
对于像c,c 这类高级计算机语言来说,它们的编译器(例如:Unix的CC命令,Windows的CL命令)都是直接把源码直接编译成计算机可以认识的机器码,如exe,dll之类的文件,然后直接运行即可。
Java语言的跨平台是它的最大亮点之一,为了达到平台惯性,它就不得不多一个中间步骤,也就是生成字节码文件。对于一个Java源文件来说,需要用javac命令把源文件编译成class文件,这个class文件是计算机无法直接识别的,但是却可以被Java虚拟机所认识,所以在运行一个Java程序的时候,肯定是要启动一个Java虚拟机,然后在由虚拟机去加载这些class文件,如图所示:
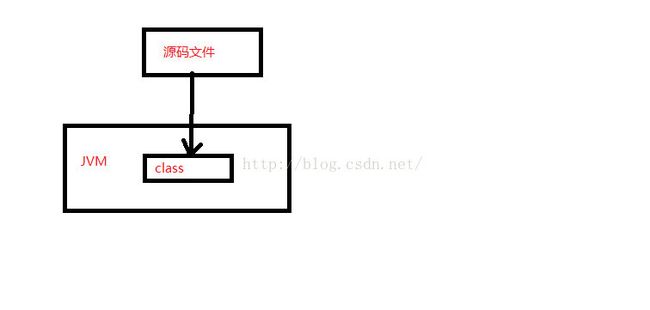
注意:class文件指的是字节码文件,而不专指类编译后的文件,不管是类,接口,枚举或其他类型,都是编译成class文件的。
所以:
c 源码编译以后,生成的是特定机器可以直接运行的文件,而Java源码经过编译后,生成的是中间的字节码文件,这些字节码文件是需要放在JVM中运行的,而JVM是有多个平台版本的。因此,Java是具有跨平台的,而C 没有。
String类为什么具有不可变性?其如何实现不可变性的?
首先明确什么是不可变对象:
如果一个对象在创建之后就不能再改变它的状态,那么这个对象是不可变的(Immutable)。不能改变状态的意思是,不能改变对象内的成员变量,包括基本数据类型变量的值不能改变,引用类型的变量不能指向其他的对象,引用类型指向的对象的状态也不能改变。
关于final关键字的特性:
如果要创建一个不可变对象,关键一步就是要将所有的成员变量声明为final类型。所以下面简单回顾一下final关键字的作用:
- final修饰类,表示该类不能被继承,俗称断子绝孙类,该类的所有方法自动地成为final方法
- final修饰方法,表示子类不可重写该方法
- final修饰基本数据类型变量,表示该变量为常量,值不能再修改
- final修饰引用类型变量,表示该引用在构造对象之后不能指向其他的对象,但该引用指向的对象的状态可以改变
我们可能经常会看到这样的代码:
String s = "abc"; //(1)
System.out.println("s = " s);
s = "123"; //(2)
System.out.println("s = " s);
嗯?s被重新赋值了?不是说不可变吗?其实不可变性说的是String本身,并不是s,s只是一个指向String类型的引用,对s二次赋值底层其实是又new了一个String然后让s指向新new出来的String对象,String不可变指的是String对象被创建后其内部的成员变量的值都不能再改变了,在这里主要就是char[] value中的内容不可再改变。
那么String不可变是如何实现的?
- 将String类修饰为final的,保证其不能被继承,防止由于继承破坏其不可变性
- 将所有成员变量都修饰为private final的,private保证了外部不可修改,final保证了内部也不能修改value指向的引用,但是value内部的值还是可以被改变的鸭?所以String通过在所有方法里都不去主动修改valu中值这个原则来保证String的不可变性
事实上,我们可以通过反射机制来破坏String的不可变性:
String s = "Hello World";
System.out.println("s = " s);
//获取String类中的value属性
Field valueField = String.class.getDeclaredField("value");
//改变value属性的访问权限
valueField.setAccessible(true);
//获取s对象上的value属性的值
char[] value = (char[]) valueField.get(s);
//改变value所引用的数组中的第6个字符
value[5] = '_';
System.out.println("s = " s);
String不可变有什么好处?
- 运行时常量池的需要,java中,比如先创建了String a=“11“,然后创建了String b=”11“,这时java不会去新开辟一块内存,而是会把b指向和a一样的地址空间,如果String可变,那么当a改变之后会影响b的值,这样不安全
- 由于String是不可变的,所以是线程安全的,同一个String可以被多个线程共享
- 允许String缓存hashCode,String源码中有一个hashCode的属性,作用是缓存器hash值,如果String值改变了,之前缓存的hash值就没有意义了。
- 安全性,比如用户名密码等都是String,如果由于人为不小心改变导致用户密码错误会引发安全性。
String是object的子类,那么String[]是不是Object的子类?为什么?
String[]也是Object的子类,如果调用b.getClass().getSuperclass()会打印出Object。
自定义View的流程?
屏幕上有view1 view2 view3,其绘制流程?测量传参的形式是什么?
View的绘制主要是三个方法,onMesure()、onLayout()、 onDraw(); onMesure()传参会传一个 32位的int型数字,高两位代表测量模式,低30位代表具体数值。
如何实现一个圆,其下四分之一加上蒙层的效果?(path)
在AThread中调用BThread.sleep(),休眠的是哪个线程?
java中类的某些成员变量没有被用到,是否可以随意删除?
NDK中的局部变量如果不手动释放一定没问题吗?
链表的反转
20亿个qq号码,如何判断其中是否存在某一个?
假设qq号码10位:
- 建立10叉数
- 数据节点有两个数据,一个存数字,一个存是否为结束位(解释:如"1234", (1, false) - (2, false) - (3, false) (4, true))
root
1(F)
2(F)
3(F)
4(T)
以此类推,构建出一个十叉树,判断一个数是否存在过,时间复杂度是O(1).