机器学习视觉图像算法工程师--面试笔试--常考知识点乱找总结
目录
经验风险最小化
结构风险最小化
最大似然估计
归一化,标准化
激活函数(Sigmoid, tanh, Relu)
特征图大小计算
凸集概念
是否需要归一化
无监督学习方法
增大感受野方法
正则化作用和方法
计算进行了多少次乘-加操作
梯度下降法和牛顿法的优缺点
CNN中感受野大小的计算
L1和L2正则化项区别
深度学习优化方法
——————————————————————
经验风险最小化
用模型f(x)在这个给定的样本集上的平均损失最小化来代替无法求得得期望风险最小化。
根据大数定律,当样本数趋于无穷大时,经验风险趋于期望风险。
即用部分数据的模型代总的。
经验风险是模型关于训练样本集的平均损失。
经验风险最小化(empirical risk minimization,ERM)的策略认为,经验风险最小的模型是最优的模型。根据这一策略,按照经验风险最小化求最优模型就是求解最优化问题:
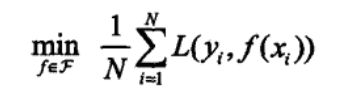
当样本容量足够大时,经验风险最小化能保证有很好的学习效果,在现实中被广泛采用。例如,极大似然估计(MLE)就是经验风险最小化的一个例子。当模型是条件概率分布,损失函数是对数损失函数时,经验风险最小化就等于极大似然估计。
对于小样本问题,经验风险效果并不理想,因为经验风险最小化容易带来过拟合现象。过拟合现象其实就是模型的选择太在意训练误差了,反而导致预测误差随着训练误差减小而增大,造成训练结果不理想。
结构风险最小化
而结构风险最小化(structural risk minimization, SRM)是为了防止过拟合而提出的策略。结构风险最小化等价于正则化。结构风险在经验风险的基础上加上表示模型复杂度的正则化项。在假设空间、损失函数以及训练集确定的情况下,结构风险的定义是: 
其中,J(f)为模型的复杂度,是定义在假设空间上的泛函。模型f越复杂,复杂度J(f)就越大。也就是说,复杂度表示了对复杂模型的惩罚。结构风险小的模型往往对训练数据和未知的测试数据都有较好的预测。
比如,贝叶斯估计中的最大后验概率估计(MAP)就是结构风险最小化的例子。当模型是条件概率分布,损失函数是对数损失函数,模型复杂度由模型的先验概率表示时,结构风险最小化就等价于最大后验概率估计(不太懂)。
结构风险最小化的策略认为结构风险最小的模型是最优的模型。所以求解模型,就是求解最优化问题:

参考:
https://www.cnblogs.com/zf-blog/p/7794871.html
https://blog.csdn.net/zhang_shuai12/article/details/53064697
https://blog.csdn.net/w5688414/article/details/79381136
最大似然估计
参考:https://blog.csdn.net/qq_39355550/article/details/81809467
极大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。通过若干次试验,观察其结果,利用试验结果得到某个参数值能够使样本出现的概率为最大,则称为极大似然估计。
利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值。
求最大似然估计量![]() 的一般步骤:
的一般步骤:
(1)写出似然函数;
(2)对似然函数取对数,并整理;
(3)求导数;
(4)解似然方程。
归一化
就是将训练集中某一列数值特征(假设是第i列)的值缩放到0和1之间。方法如下所示:

标准化
就是将训练集中某一列数值特征(假设是第i列)的值缩放成均值为0,方差为1的状态。如下所示:
![]()
标准化归一化的好处:提升模型精度,提升收敛速度。
如果你不用正则,那么,标准化并不是必须的,如果你用正则,那么标准化是必须的。
激活函数(Sigmoid, tanh, Relu)
Sigmoid

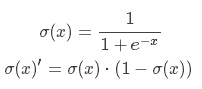
优点:连续,方便求导。 把数值映射到0-1,压缩数据。二分类输出。
缺点:
- 梯度消失,权重无法更新。
- 不对原点对称,导致w总体变化的方向就被L函数的形式限定下来了。也就是说,随着Loss函数的形式改变了,w变化的总体方向也会跟着改变。W1/w2/w3...一起变大或者变小,不能有的变大有的变小。
- 有指数,计算复杂。
Tanh


仍梯度饱和。计算复杂。没有不对称问题。
ReLU
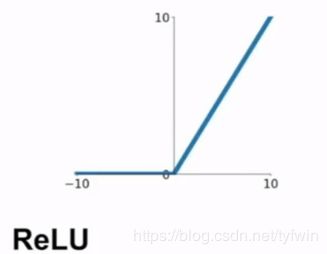
![]()
参考:https://blog.csdn.net/weixin_41417982/article/details/81437088
特征图大小计算
输入图片大小 W×W
Filter大小 F×F
步长 S
padding的像素数 P
于是我们可以得出
N = (W − F + 2P )/S+1
输出图片大小为 N×N
凸集
实数R上(或复数C上)的向量空间中,如果集合S中任两点的连线上的点都在S内,则称集合S为凸集。
所以直线是凸集。
是否需要归一化
概率模型(决策树)不需要归一化,因为他们不关心变量的值,而是关心变量的分布和变量之间的条件概率。
像SVM、线性回归之类的最优化问题需要归一化。归一化之后加快了梯度下降求最优解的速度,并有可能提高精度。
无监督学习方法
强化学习、K-means 聚类、自编码、受限波尔兹曼机 、DBSCN 等
增大感受野方法
dilated 卷积(空洞卷积)、池化、增大卷积核
正则化作用和方法
防止过拟合,提高泛化能力
early stopping、数据集扩增(Data augmentation)
L1、L2(L2 regularization也叫weight decay):L1、L2正则化是通过修改代价函数来实现的
Dropout: 我们随机地“删除”一半的隐层单元,视它们为不存在
(减少神经网络层数。错误,减少网络层数实际上是减弱了网络的拟合能力
减小权重衰减参数。错误,应该是增大权重衰减系数,类似于 L2 正则化项中参数 lambda 的作用)
算进行了多少次乘-加操作
100×100×3,3×3 卷积核,输出是 50×50×10,算进行了多少次乘-加操作?
解答:输出的每个像素点都要经过 3×3×3 = 27 次乘-加操作,因此总共需要进行 50×50×10×27 次乘-加操作。
梯度下降法和牛顿法的优缺点
随机梯度下降法:适用于样本量大的情况,需要内存小;但每一步可能并不是向着最优解方向
牛顿法:收敛速度快;但对目标函数有严格要求,必须有连续的一、二阶偏导数,计算量大
CNN中感受野大小的计算
参考:https://blog.csdn.net/lx_xin/article/details/82713045
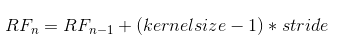
其中RFn为当前层的感受野大小,RFn-1为上一层感受野大小,kernelsize为当前层卷积核大小,stride为之前所有层的stride的乘积。当n=0时RF=1。可用递归或者循环实现。
L1和L2正则化项区别
L1和L2是正则化项,又叫做罚项,是为了限制模型的参数,防止模型过拟合而加在损失函数后面的一项。
相同点:都用于避免过拟合。
不同点:L1可以让一部分特征的系数缩小到0,从而间接实现特征选择。所以L1适用于特征之间有关联的情况。
L2让所有特征的系数都缩小,但是不会减为0,它会使优化求解稳定快速。所以L2适用于特征之间没有关联的情况
区别:
L1是模型各个参数的绝对值之和。
L2是模型各个参数的平方和的开方值。
L1会趋向于产生少量的特征,而其他特征都是0。因为最优参数值很大概率出现在坐标轴上,这样就会导致某一维的权重为0 ,产生稀疏权重矩阵。
L2会选择更多的特征,这些特征都会接近于0。 最优的参数值很小概率出现在坐标轴上,因此每一维的参数都不会是0。当最小化||w||时,就会使每一项趋近于0。
深度学习优化方法
https://blog.csdn.net/u014595019/article/details/52989301
https://blog.csdn.net/weixin_40170902/article/details/80092628