BERT引发的深度学习1
本文是作者即将在CSDN作直播的课程的预备知识,对课程感兴趣但是没有相关背景知识的同学可以提前学习这些内容。
目录
- 背景知识
- 深度学习基础知识
- Word Embedding
- 语言模型
- RNN/LSTM/GRU、Seq2Seq和Attention机制
- Tensorflow基础知识
- PyTorch基础知识
- BERT
背景知识
为了理解课程的内容,读者需要以下背景知识。
- 深度学习基础知识
- Word Embedding
- 语言模型
- RNN/LSTM/GRU
- Seq2Seq模型
- Attention机制
- Tensorflow基础知识
- PyTorch基础知识
深度学习基础知识
- 从Image Caption Generation理解深度学习(part I)
介绍机器学习和深度学习的基本概念。
- 从Image Caption Generation理解深度学习(part II)
介绍多层神经网络(DNN)的基本概念
- 从Image Caption Generation理解深度学习(part III)
介绍反向传播算法,不感兴趣的读者可以跳过细节。
- 自动梯度求解——反向传播算法的另外一种视角
建议了解一下就行,自动梯度是深度学习框架的基础。我们通常不需要实现反向算法,因为框架通常帮我们做了,但是了解一下它的原理是有用的。
- 自动梯度求解——cs231n的notes
内容主要参考CS231N课程的Notes,还是介绍自动梯度。
- 自动梯度求解——使用自动求导实现多层神经网络
使用自动梯度实现多层神经网络,对怎么自己实现自动梯度感兴趣的读者可以参考,不感兴趣的可以跳过。
- 详解卷积神经网络
卷积神经网络的介绍。
- Theano tutorial和卷积神经网络的Theano实现 Part1
卷积神经网络的实现,代码实现是用theano的,建议了解一下就行。现在更建议使用Tensorflow或者PyTorch。
- Theano tutorial和卷积神经网络的Theano实现 Part2
同上。
- 卷积神经网络之Batch Normalization的原理及实现
介绍Batch Normalization。读者了解一下原理即可,现在的框架都有现成的。
- 卷积神经网络之Dropout
Dropout是最常见也最有用的防止过拟合的技巧之一。
- 三层卷积网络和vgg的实现
自动动手实现CNN,并且实现常见的CNN架构——VGG。比较关注实现细节,不感兴趣的读者可以跳过。
- Caffe训练ImageNet简介及深度卷积网络最新技术
训练ImageNet的过程可以跳过,因为现在很少需要自己从零开始训练ImageNet了,大部分框架都有Pretraining好的模型。读者可以了解一下ResNet和Inception,后面的BERT也使用到了残差连接,在如今(2019年)这是非常常用的技巧了。
- Neural Networks and Deep Learning
Michael Nielsen的免费书籍,作者前面的文章参考了很多里面的内容。有兴趣的读者可以阅读一下,大部分内容前面已经介绍过了,因此也可以跳过。
- CS231N课程
斯坦福的课程,作者的文章也参考了一些内容。有兴趣的读者可以学习一下,跳过不影响对课程的理解。
Word Embedding
- Word Embedding教程
理解Word Embedding的概念即可,跳过Word2Vec的推导、Softmax和Negative Sample并不影响后续阅读。
语言模型
- 语言模型教程
理解语言模型的概念即可,N-Gram可以稍微了解一下,平滑和回退等tricky可以跳过,RNN语言模型需要RNN的知识,请参考RNN/LSTM/GRU的部分。
RNN/LSTM/GRU、Seq2Seq和Attention机制
- 循环神经网络简介
介绍vanilla RNN、LSTM和GRU的基本概念。
- 手把手教你用PyTorch实现图像描述
包含PyTorch的基本概念,包括用RNN来进行人名国家分类,生成不同国家的人名。本来还有一个看图说话的例子,但是编辑似乎忘了加进去。
- 手把手教你搭一个机器翻译模型
使用PyTorch实现一个机器翻译系统,包括LSTM/GRU、Attention机制等内容。
- 使用PyTorch实现Chatbot
使用PyTorch实现一个Chatbot。里面会涉及Seq2Seq模型和Attention机制。
Tensorflow基础知识
- Tensorflow简明教程
Tensorflow的基础知识,熟悉的读者也建议读读,也许会有新的收获。
PyTorch基础知识
- PyTorch简明教程
来自官网的教程,包含60分钟PyTorch教程、通过例子学PyTorch和迁移学习教程。
BERT
下面的内容会在课程上详细讲解,但是建议同学们提前预习一下。
- Transformer图解
通过图解详细的介绍Transformer的原理。
- Transformer代码阅读
详细解读Transformer的代码。
- BERT模型详解
本文详细介绍BERT模型的原理,包括相关的ELMo和OpenAI GPT模型。
- BERT代码阅读
详细解读BERT模型的代码。
- 从Image Caption Generation理解深度学习(part-1)
0. 前面的话
建丁让我写一篇深度学习相关小文章,目标读者是国内的开发者。刚接到这个任务时我是颇为忐忑的,写文章要讲究厚积薄发,如果“水之积也不厚”,“则其负大舟也无力”。因为我自知水平很有限,又不是在学校和科研机构做研究,只不过因为工作和个人的兴趣,对深度学习有一点点粗浅的了解,所以担心写出来的东西不但于人无益,甚至还让人误入歧途。但后来又一想,如果把自己作为一个深度学习的学习者,和对它感兴趣的普通开发者分享一些学习的经历,包括学习过程中遇到的问题,可能也是有一些意义的。毕竟读论文或者听学术大牛的讲座只能看到“成功”的经验,而且大部分开发者相对来说没有太多的背景知识,而很多圈内的人都是假设读者拥有这些知识的。但是对于普通的开发者来说,很多基础知识比如线性代数和微积分在上完大学后估计就还给老师了,因此可能理解起来难度更大。而从另外一个角度来说,工程师(开发者)和科学家(科研工作者)关注的点也是不一样的。科学家更关注理论的东西,比如一个模型是怎么提出来的,为什么要这么设计模型,这样的模型怎么转化成一个优化问题。而工程师则更关注这个东西能够做什么,具体这个优化问题怎么求解更高效。学术界每年有大量的论文发表,大量的idea被提出,其中有好有坏,有的工作可能看起来理论很漂亮,但实际应用起来很难;有些工作可能不被太多人关注,但却是某些工业界非常需要的。
另外从人工智能的发展来说,我个人觉得在传统行业的普及也是非常重要的。现在很多人工智能创业公司,很多想用人工智能创造一个全新的产品,比如早期类似Siri的语音助手到现在火热的机器人。但我个人觉得目前的人工智能的水平还很难做出达到用户预期的产品,尤其是很多初创公司吹牛吹得有些过分,导致用户期望过高,而真正使用产品后则形成巨大的反差。我觉得目前阶段人工智能更大的用处是提升现有系统,用我自己的话来说就是目前的人工智能只是锦上添花而不是雪中送碳。也就是说光靠人工智能是不能吸引用户来购买你的产品的。
比如现在国外很火的Amazon的智能音箱产品Echo,如果我不想买一个音箱,估计你很难这样说服我购买Echo——我们的Echo有非常智能的语音交互功能,可以问天气,可以设置闹钟,可以Uber打车,可以控制家里的智能冰箱。但是如果我想购买一个音箱,现在面临两个选择:一个是传统的音箱,另一个是Echo。那么你对我说Echo有多么牛逼的智能可能会打动我,反正也差不了多少钱,能有这么多听起来很酷炫的功能也挺不错的。
由于Echo的成功,国内很多人也想“山寨”一个类似的产品,不过可能很多人忽略了美国和中国的一些细小差异,那就是音箱似乎不是大城市居民的必备品。就我个人的朋友圈来说,每个家庭肯定都有个电视,但是有音箱寥寥无几。为什么会这样呢,因为中国的大城市居民大都是住楼房,很多老破小隔音效果都很差,你整个音箱弄家里还没high两分钟,估计邻居就该敲门了。倒是耳机,屌丝们挤公交地铁时的必备利器,也许会更好卖。
说了这么多,想表达的就是目前人工智能应该更多的提高现有产品。比如提到Google,大家可能会想到它收购的Deepmind的AlphaGo,但是我们可能没有意识到日常使用的很多产品中都使用了深度学习。比如搜索引擎的排序,邮件的智能回复生成,都大量使用了深度学习。而AlphaGo的作用则更多的是一种市场PR,一种宣传作用,让大家知道人工智能目前的一些进展,而现在AlphaGo团队则是想将其技术用到医疗行业帮助医生诊断疾病。
也就是说人工智能在未来也许就像计算机,互联网,云计算一样是一个非常基础的设施,在任何需要用机器来替代或者减少人力的场景都是有用武之地的。目前不论是国内还是国外,人工智能的人才都是非常稀缺的,而且都是集中在少数学校的实验室和大公司的研究院里。因此向普通开发者传播相关的知识就显得尤为重要。基于这样的考虑,虽然自己的能力不够,但还是愿意把自己学习的一些经验和问题向大家分享。
1. 为什么分享Image Caption Generation这个话题?
这篇小文章并没有限定什么范围,只要是深度学习相关的就行。这反倒让人烦恼,就和人生一样,选择太多了也是一种烦恼。因为最近工作有空之余正在学习斯坦福的课程CS231N,Convolutional Neural Networks for Visual Recognition。这个课程非常好,除了详尽的slides和notes,最值得一提的就是它的作业。每个作业包含完整的模型,比如CNN、LSTM,所有的模型的代码都只是用最简单的python代码实现,而不是用现成的库比如TensorFlow/Theano/Caffe。纸上得来终觉浅,绝知此事要躬行。很多理论,光听课看slides,似乎觉得自己懂了,其实还是一知半解,真正要掌握,就得自己动手,最好是全部自己实现。但是全部自己实现需要花的时间太多,而且从实际工作的角度来说,大部分开发者肯定都是用TensorFlow这样的工具。而这个课程的好处就是:把一些琐碎的与核心代码不相关的部分包括学习的框架都已经实现了,然后用IPython notebook把关键的代码的函数的输入和输出都描述的非常清楚,学习者只需要实现一个一个这样的函数就行了,而且每个函数都会有类似单元测试的检测代码正确性的数据,从而保证我们的每一步都是在朝着正确的方向前进。
因此这篇小文章打算讲一讲其中的Assignment3的Image Caption Generation部分。目的是想通过一个具体的任务来给大家介绍深度学习的一些知识,让大家对深度学习有一些概念和兴趣。选择Image Caption Generation的原因,一来这个任务挺有意思的;第二就是它涉及到很多深度学习流行的模型如CNN,RNN/LSTM,Attention。
首先来介绍一下什么叫做Image Caption Generation。
对于计算机视觉相关的任务,图片分类和定位大家可能比较熟悉。图片分类就是给定一张图片,让计算机告诉我们它是一只猫还是一只狗;而图片定位除了告诉我们这是一张狗的图片,还需要用用一个矩形框把狗的位置标识出来。当然还有要求更高的Image Segmentation,需要告诉我们哪一些像素属于狗,而另外一些属于背景。
图1就是这些任务的例子:
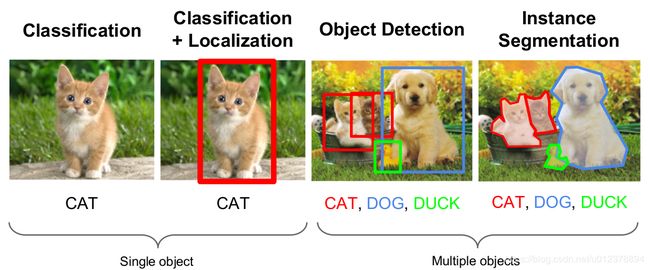
图1:常见机器视觉任务 图片来自 http://cs231n.stanford.edu/slides/winter1516_lecture8.pdf
而Image Caption Generation任务是给定一张图片,需要让计算机用一句话来描述这张图片。
如图2所示:
图2:Caption Generation任务示例 图片来自 http://mscoco.org/dataset/#captions-challenge2015
从实际的应用来说,这个任务也是很有用处的。比如一个手机拍完照片之后,我们可以用这个方法生成一句话来描述这个图片,方便分享和以后查找。
而从理论研究的角度来说,Caption Generation相对于之前的task来说需要更加深入“理解”图片中物体之间的关系,甚至包括一些抽象的概念。它把一幅信息量极大的图片压缩成短短一句话。
我是做自然语言处理(NLP)相关工作的,之前对计算机视觉有一些错误的看法。认为视觉信号是更底层和原始的信号,除了人类,动物也有很强的视觉能力,也能分辨不同物体。而语言是人类创造的符号系统,属于更高层的抽象,因而属于更高级的人工智能问题,似乎不少人会有类似的观点。
但是现在我有了一些不同的看法,人类的大脑并没有什么特殊之处。一个小孩在一岁之前一般不会说话,他认识世界的主要方式就是主要通过视觉系统来区分物体,也许和神经网络类似,通过复杂的神经元的连接来“理解”世界。这些不同层次的网络就是不同层次的特征,就像神经网络的“黑盒”,我们自己也很难用精确的语言描述我们大脑到底学习到了什么样的特征。而且很可能每个人学到的特征,尤其是底层的特征都是不相同的。
比如下图的一个汽车,最底层的特征可能是不同方向的线条,而中间层的特征可能是各种基本的形状,而更上层的特征就是车轮这样的更上层概念。

图片来自 http://cs231n.stanford.edu/slides/winter1516_lecture7.pdf
一个复杂的概念由一些简单的概念组合而成,而简单的概念可能由最基本的原子概念组合而成。语言就是对这些概念的描述,或者说就是一个标签,一种命名。但是语言有一个特点就是它是用来沟通和交流的,所以语言的使用者需要达成一定程度的共识。那怎么达成共识呢,比如我们在教小孩语言时是怎么与他达成共识的呢?比如一个桌子,我们通过手指这一个条狗狗,反复对小孩说“狗狗”这个词(其实是声音,为了简化,我们暂且当成文字),这样我们就和小孩达成了共识,“狗狗”就是指这样一个动物,然后又指着另外一条狗狗,也说“狗狗”,小孩就学到这一“类”物体都是狗狗。所以他需要调整他的神经元连接,使得那些符合某种特征的物体都被识别成狗狗。至于具体这个识别狗狗的神经网络的参数是什么样的,我们很难知道,也许刚开始他需要分类的物体很少,比如只有“爸爸”,“妈妈”和“狗狗”,那么它可能需要不是那么“本质”的特征来区分,比如他可能认为四条腿走的是“狗狗”,两条腿直立行走的就是“爸爸”和“妈妈”。当随着需要识别的类别的增多,比如有了“猫猫”,那他一上来可能认为也是“狗狗”,但父母告诉他分类错误,这不是“狗狗”而是“猫猫”。那么他可能需要别的特征来区分猫猫和狗狗,也许他学到的是:四条腿走并且嘴很长的是狗狗,而四条腿圆脸的是猫猫。
那为了能够区分猫猫和狗狗,小孩的中层的特征可能需要抽取类似“脸”的特征,或者说概念。我们也会告诉他这是狗狗的脸,这是猫猫的脸,这是爸爸的脸。这样他需要学习出脸的共性的特征。
从上面的过程我们可以发现,概念本身只是一种“特征”的指代,是我们的感觉系统(视觉)对一个物体的反应。而语言是一部分相似的生物对同一个/类物体达成共识的一种指代。但每个人的感觉系统和神经网络结构都是不一样的,所以也只能在非常粗糙的程度达成比较一致的共识,而在非常精细的概念层次是很难达成广泛共识的。因此我们会把周围的人打上各种标签,分成各种类别,由此各种概念也就产生——肤色,语言,宗教,性别,阶级。每个人也只能和同一个标签的人在某个方面达成共识,所以要找到一个完全“了解”自己的人是如此之难,而不同的物种的共识可能就更难了。所以就像《庄子·齐物论》里说的“毛嫱、丽姬,人之所美也;鱼见之深入,鸟见之高飞,麋鹿见之决骤。四者孰知天下之正色哉?自我观之,仁义之端,是非之涂,樊然殽乱,吾恶能知其辩!”毛嫱、丽姬是我们人类眼中的美,但是在鱼和雁看来只是可怕的敌人。可笑的是自恋的人类却还要曲解庄子的愿意,认为它们是因为惊异于她们的美丽才沉鱼落雁闭月羞花的。不说动物,即使是人类而言,美也是很难达成共识的,那些黑人国家的美女,我们中国人是很少会认为她们是美女的。
因此从这个意义上来说,语言也许并没有我们想像中的那么高大上。 就目前人工智能或者深度学习的水平来说,也许研究小孩在建立复杂概念之前的行为更有用处。
从Image Caption Generation理解深度学习(part II)
2. 机器学习基本概念和前馈神经网络
2.1 机器学习基本概念
大家可能平时都写过很多程序,写程序和机器学习的思路可能有一些不同。写程序时,我们是“上帝”,我们规定计算机的每一个步骤,第一步做什么第二步做什么,我们称之为算法。我们能够控制所有的情况,如果出了任何问题,肯定都是程序员的责任。而在机器学习的时候,我们只是“老师”。我们告诉学生(计算机)输入是什么,输出是什么,然后期望它能够学到和我们类似的知识。比如我们跟小孩说这是狗,那是猫,我们没有办法像上帝那样拿着“纳米手术刀”去操作人脑神 经元的连接方式。我们只能不断的给小孩“训练数据”,然后期望他能够学会什么是猫,即使我们觉得他“学会”了识别猫,我们也没有办法知道他是“怎么”学会 的,而且同样的训练过程可能换一个人就不好使。
机器学习和人类的学习是类似的——我们也是给它训练数据,然后期望它能学会。我们会给机器建一个模型,从数学的角度来说一个模型就是一个函数,它的输入一般是一个向量【当然可以是二维的矩阵如图片或者三维的张量比如视频】,输出可以是有限的离散的标签如“猫”,“狗”,这类问题我们称之为分类;而如果输出 是连续的值比如用这个模型来预测气温,那么我们就称之为回归。其实人类的很多科学活动和日常生活,都是在“学习”模型和“应用”模型。比如开普勒通过观测 大量天文数据“归纳”出行星的运动规律。从本质上讲,智能就是从“过去”学习,然后根据“现在”来预测可能的将来并根据自己的目标选择有利于自己行为。只不过之前,似乎只有人类能够从数据中“学习”出规律,而人工智能的目标就是让机器也有类似的学习能力。
模型用数学来说就是一个函数,我们人脑的函数由神经元的连接构成,它可能是一个很复杂的函数,我们现在还很难彻底研究清楚。神经网络就是试图通过计算机来 模拟和借鉴人脑这个模型,除了我们这里要讲的神经网络之外,机器学习领域还有各种各样的模型,它们各有特点。但不管形式怎么变化,本质都是一个函数。一个(或者更准确的是一种)模型一般都是一种函数形式,它有一些“参数”可以改变。而学习的过程就是不断调整这些参数,使得输出(尽量)接近“正确”的答案。 但是一般情况下很难所有的数据我们都能预测正确,所以一般我们会定义一个loss function,可以理解为“错误”的程度,错的越“离谱”,loss就越大。而我们的目标就是调整参数使得loss最小。
但是我们是在“训练”数据上调整的参数,那么它能在“测试”数据上也表现的好吗?这个就是模型的“泛化”能力了。就和人在学校学习一样,有的同学做过的一 模一样的题就会,但是考试时稍微改变一下就不会了,这就是“泛化”能力太差,学到的不是最本质的东西。所以平时会定期有一些“模拟考试”,来检验学生是不 是真的学会了,如果考得不好,那就打回去重新训练模型调整参数。这在机器学习里对应的就是validation的阶段。最后到最终的考试了,就是最终检验 的时候了,这个试卷里的题目是不能提前让人看到的,只能拿出来用一次,否则就是作弊了。对应到机器学习里就是test阶段。
当然这里用通俗的话描述了机器学习,主要是有监督的学习。其实机器学习还有无监督的学习和强化学习。前者就是不给答案,只给数据,让人总结规律;而后者会有答案,但是答案不是现在就告诉你。我个人觉得人类社会里更多的是监督学习和强化学习。从人类社会总体来说,强化学习是获取新知识的唯一途径,也就是向自 然学习,我们做了一个决策,其好坏可能要很长一段时间才能显现出来。而学习出来的这些知识通过监督的方式,通过家庭和学校的教育教给下一代。
另外输出除了简单的分为离散和连续,还可以是序列(时序)的,比如自然语言(文本)是一个字符串的序列 ,对于我们的Image Caption Generation就是生成一个单词序列。另外还有更复杂的输出,比如parsing,输出是一棵语法树。
2.2 多层神经网络
前面介绍了机器学习的基本概念,接下来我们就来学习一下神经网络。现在流行的说法“深度学习”,其实大多指的就是“深度神经网络”,那么首先我们先了解一下“浅度神经网络”,也就是传统的神经网络。这里的内容主要来自http://neuralnetworksanddeeplearning.com的前两章。
2.2.1 手写数字识别问题
我们在学习一门新的语言时会写一个hello world程序,而mnist数据的手写数字识别就是一个很好的学习机器学习(包括深度学习)的一个hello world任务。
计算机和人类大脑似乎有很大的不同,很多人类认为复杂的工作计算机可能认为很简单,而人类认为很简单的事情计算机可能非常难处理。比如数字的计算,记忆,人类的准确度和速度都远远不如计算机。但是识别0-9的手写数字,我们觉得很轻而易举的事情,让计算机程序来处理却异常困难。经过数百万年进化的人类视觉系统在我们大脑没有意识到的时候就已经帮我们完成了数字的识别,把那些复杂的视觉处理过程深深的掩藏了起来。但当我们想自己写一个程序来识别数字的时候,这些困难才能体现出来。首先,对于计算机来说,它“看到”的不是数字,甚至不是笔画。它“看到”的只是一个二位的矩阵(数组),每个点都是一个数字。比如下图,我们“看到”的是左边的“猫”,其实计算机“看到”的是右边的像素灰度值。当然我们视觉系统的视网膜看到的也是类似的一些“数值”,只不过我们的视觉系统已经处理了这些信息并且把它识别成了“猫”(甚至和语言还做了映射)。

MNIST数据介绍:MNIST的每个图片经过缩放和居中等预处理之后,大小是28*28,每个点都是0-255的灰度值,下图是一些样例。总共有60,000个训练数据(0-9共10个类别,每个类别6,000个)和10,000个测试数据。一般会拿60000个中的50000个来做训练集,而剩下的10000个用来做验证集(用来选择一些超参数)。
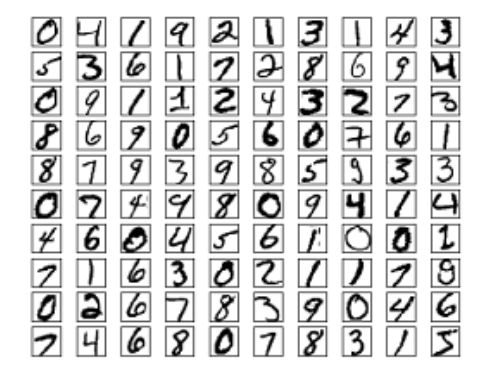
mnist样例数据
如果我们自己来写一个“算法”识别数字“9”,我们可能会这么定义:9在上面有个圆圈,在这个圆圈的右下部分有一个竖直的笔画。说起来很简单,如果用算法 来实现就很麻烦了:什么是圆圈?每个人画的圆圈都不同,同样竖直的笔画怎么识别,圆圈和竖直笔画连接处怎么寻找,右下是哪?大家如果有兴趣可以尝试一下用 上面的方法,其实最早做数字识别就是这样的思路。
机器学习的思路则不同,它不需要这么细节的“指示”计算机应该怎么做。而是给计算机足够的“训练”样本,让它“看”不同的10个数字,然后让它“学”出 来。前面我们也讲了,现在的机器学习一般是一个参数化的模型。比如最简单的一个线性模型:f(w;x)=w0+ w1*x1+w2*x2。如果我们的输入有两个“特征”x1和x2,那么这个模型有3个参数w0,w1和w2,机器学习的过程就是选择“最优”的参数。对 于上面的mnist数据,输入就是28*28=784维的向量。
如果用“原始”的输入作为“特征”,线性的模型很可能学到一些简单的特征,比如它看到1一般是分布在从上到下居中的一些位置,那么对于这些位置一旦发现有比较大的灰度值,那么就倾向于判断成1。如果一个像素点2也经常出现,但3不出现,那么它就能学到如果这个像素出现,那么这个数字是2和3的可能性就大一些。
但是这样的“特征”可能不是“本质”的,因为我写字的时候笔稍微平移一点,那么你之前“学到”的参数就可能有问题。而更“本质”的特征是什么呢?可能还是像之前我们总结的——9在上面有个圆圈,在这个圆圈的右下部分有一个竖直的笔画。我们把识别一个数字的问题转化成圆圈和竖直笔画的问题。传统的机器学习需要方法来提取“类似”(但不完全是)基本笔画这样的“特征”,这些特征相对于像素的特征会更加“本质”。但是要“提取”这些特征需要很多的“领域”知识,比如图像处理的技术。所以使用传统的机器学习方法来解决问题,我们不但需要很多机器学习的知识,而且也需要很多“领域”的知识,同时拥有这两方面的知识是比较难的。
而“深度学习”最近之所以火热,其中很重要的一个原因就是对于很多问题,我们只需要输入最原始的信号,比如图片的像素值,通过“多层”的网络,让底层的网络学习出“底层”的特征,比如基本的形状,而中间的层学习出抽象一点的特征,比如眼睛鼻子耳朵。而更上的层次识别出这是一个猫还是一个狗。所有这些都是机器学习出来的,所以基本不需要领域的知识。

上面的图就说明了这一点,而且我们发现越是底层的特征就越“通用”,不管是猫鼻子还是狗眼睛,可能用到的都是一些基本的形状,因此我们可以把这些知识(特征)transfer到别的任务,也就是transfer learning,后面我们讲到CNN的时候还会提及。
2.2.2 单个神经元和多层神经网络(MLP)
神经网络从名字来看是和人类的大脑有些关系的,而且即使到现在,很多有用的东西如CNN和Attention,都有很多借鉴神经科学研究人脑的结果的。不过这里我就不介绍这些东西了,有兴趣的读者可以找一些资料来了解。
一个神经元如下图的结构:
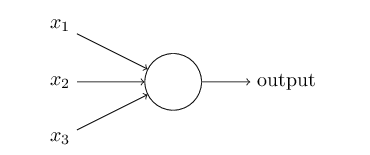
它的输入是一个向量,(x1,x2,x3),输出是一个标量,一个实数。z=w0+ w1*x1 + w2*x2 + w3*x3。z是输入的加权累加,权值是w1,w2,w3,w0是bias,输出 output = f(z)。函数f一般叫做激活函数。最早流行的激活函数是Sigmoid函数,当然现在更流行Relu和它的改进版本。Sigmoid函数的公式和图形如下:
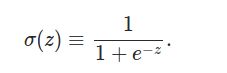
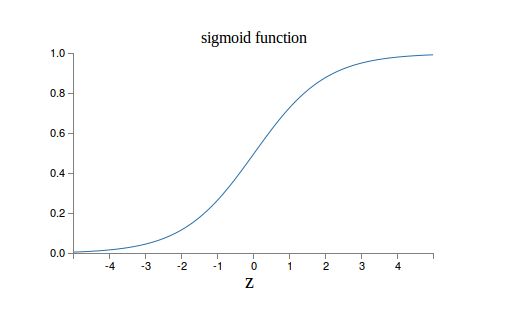
当z=0时,sigmoid(z)=0.5 z趋于无穷大时,sigmoid(z)趋近于1,z趋于负无穷,值趋于0。为什么选择这样的激活函数呢?因为是模拟人脑的神经元。人脑的神经元也是把输入的信号做加权累加,然后看累加和是否超过一个“阈值”。如果超过,继续向下一个神经元发送信号,否则就不发送。因此人脑的神经元更像是一个阶跃函数:
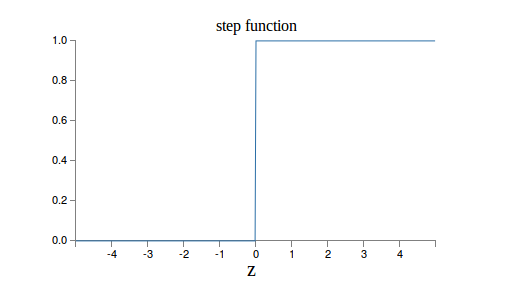
最早的感知机(Perception)其实用的就是这个激活函数。但是它有一个缺点就是0之外的所有点的导数都是0,在0点的导数是无穷大,所以很难用梯度的方法优化。而Sigmoid函数是处处可导。下面我手工推导了一下,如果大家不熟悉可以试着推导一下Sigmoid函数的导数,我们后面也会用到。
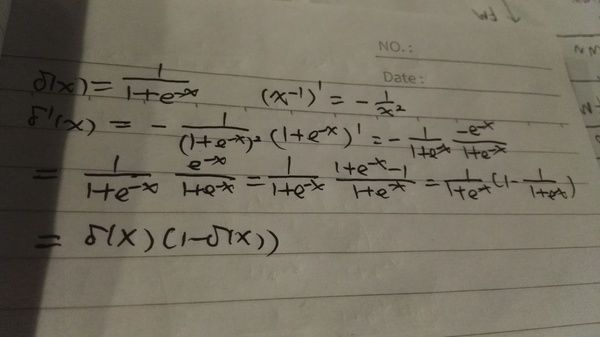
我们把许多的单个神经元按照层次组织起来就是多层的神经网络。
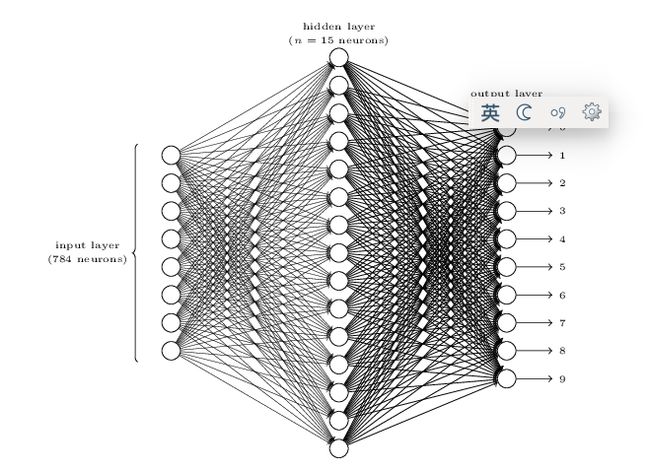
比如我们的手写数字识别,输入层是784维,就是神经网络的地一层,然后中间有15个hidden(因为我们不知道它的值)神经元,然后输出层是10个神经元。中间隐层的每个神经元的输入都是784个原始像素通过上面的公式加权累加然后用sigmoid激活。而输出层的每一个神经元也是中间15个神经元的累加然后激活。上面的图就是一个3层的神经网络。
输入一个28*28的图像,我们得到一个10维的输出,那么怎么分类呢?最直接的想法就是把认为最大的那个输出,比如输出是(10,11,12,13,14,15,16,17,18,19),那么我们认为输出是9。
当然,更常见的做法是最后一次经过线性累加之后并不用Sigmoid函数激活,而是加一个softmax的函数,让10个输出加起来等于1,这样更像一个 概率。而我们上面的情况,虽然训练数据的输出加起来是1,但是实际给一个其它输入,输出加起来很可能不是1。不过为了与Nielsen的文章一致,我们还 是先用这种方法。
因此,假设我们有了这些参数【总共是784*15 + 15(w0或者叫bias) + 15*10 + 10】,我们很容易通过上面的公式一个一个的计算出10维的输出。然后选择最大的那个作为我们识别的结果。问题的难点就在怎么 选择这么多参数,然后使得我们分类的错误最少。
而我们怎么训练呢?对于一张图片,假设它是数字“1”,那么我们期望它的输出是(0,1,0,0,0,0,0,0,0,0),所以我们可以简单的用最小平方错误作为损失函数。不过你可能会有些疑问,我们关注的指标应该是分类的“正确率”(或者错误率),那么我们为什么不直接把分类的错误率作为损失函数呢?这样神经网络学习出来的参数就是最小化错误率。
主要的原因就是错误率不是参数的连续函数。因为一个训练数据如果分类正确那么就是1,否则就是0,这样就不是一个连续的函数。比如最简单的两类线性分类器,f(x)=w0+w1*x1+w2*x2。如果f(x)>0我们分类成类别1;否则我们分类成类别2。如果当前的w0+w1*x1+w2*x2<0,我们很小的调整w0(或者w1,w2),w0+w1*x1+w2*x2仍然小于0,【事实上对于这个例子,只要是w0变小,他们的累加都是小于0的】所以f(x)的值不会变化,而w0一直增大到使累加和等于0之前都不会变化,只有大于0时突然变成1了,然后一直就是1。因此之前的错误率都是1,然后就突然是0。所以它不是个连续的函数。
因为我们使用的优化算法一般是(随机)梯度下降的算法,在每次迭代的时候都是试图做一个微小的参数调整使得损失变小,但是不连续的函数显然也不可导,也就没法用这个算法来优化参数。
因此我们使用了最小平方误差(MSE)损失函数。
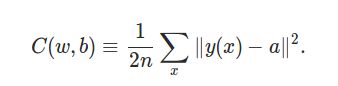
y(x)就是神经网络的输出,可能写成f(x)大家会习惯一点。a是目标的输出,比如当前分类是数字1,那么我们期望的输出就是(0,1,0,0,0,0,0,0,0,0)。
首先这个损失函数是参数w的连续函数,因为y(x)就是神经网络的输出,每个神经元都是它的输入的线性加权累加,然后使用sigmoid激活函数【如果使用最早的阶跃函数就不连续了,所以后来使用了Sigmoid函数】,然后每一层的神经元都是用上一层的神经元通过这样的方式计算的(只不过每个神经元的参数也就是权重是不同的数值而已),所以这些连续函数的复合函数也是连续的。
其次这个损失函数和我们的最终优化目标是“大致”一致的。比如C(w,b)趋于0时,它就要求y(x)趋于a,那么我们的分类也就趋于正确。当然可能存在一种极端的情况,比如有3个训练数据,第一组参数,它分类正确了2个训练数据,但是错的那1个错的很“离谱”,也就是y(x)和a差距极大;而第二组参数,他正确分类了1个训练数据,但是错的那两个都还不算太差。那么这种情况下MSE和正确率并不一致。
2.2.3 随机梯度下降(Stochastic Gradient Descent)和自动求梯度(Automatic Derivatives)
上面说了,我们有了一个参数化的模型,训练的过程就是根据训练数据和loss function,选择“最优”的参数,使得loss“最小”,这从数学上来讲就是一个优化问题。这看起来似乎不是什么值得一提的问题,也许你还记得微积 分里的知识,极值点的各种充分必要条件,比如必要条件是导数是0,然后直接把参数解出来。但在现实生活中的函数远比教科书里学到的复杂,很多模型都无法用 解析的方式求出最优解。所以现实的方法就是求“数值”解,一般最常见的方法就是迭代的方法,根据现在的参数,我们很小幅度的调整参数,使得loss变小一 点点。然后一步一步的最终能够达到一个最优解(一般是局部最优解)。那怎么小幅调整呢?像闷头苍蝇那样随机乱试显然效率极低。因此我们要朝着一个能使函数 值变小的方向前进。而在一个点能使函数值变小的方向有无穷多个,但有一个方向是下降速度最快的,那就是梯度。因此更常见的方法就是在当前点求函数的梯度, 然后朝着梯度的方向下降。朝梯度的方向走多远呢?一般走一个比较小的值是比较安全的,这个值就是“步长”。一般刚开始随机的初始化参数,loss比较大, 所以多走一些也没关系,但是到了后面,就不能走太快,否则很容易错过最优的点。
因为loss是所有训练数据的函数,所以求loss的梯度需要计算所有的训练数据,对于很多task来说,训练数据可能上百万,计算一次代价太大,所以一 般会“随机”的采样少部分数据,比如128个数据,求它的梯度。虽然128个点的梯度和一百万个的是不一样的,但是从概率来讲至少是一致的方向而不会是相 反的方向,所以也能使loss变小。当然这个128是可以调整的,它一般被叫做batch size,最极端的就是batch是1和一百万,那么分别就是online learning和退化到梯度下降。batch size越大,计算一次梯度的时间就越久【当然由于GPU和各种类似SSE的指令,一次计算128个可能并不比计算1个慢多少】,随机梯度和真正梯度一致 的概率就越大,走的方向就更“正确”;batch size越小,计算一次的时间就越短,但可能方向偏离最优的方向就更远,会在不是“冤枉路”。但实际的情况也很难说哪个值是最优的,一般的经验取值都是几 十到一两百的范围,另外因为计算机都是字节对齐,32,64,128这样的值也许能稍微加快矩阵运算的速度。但是实际也很多人选择10,50,100这样 的值。
除了常见的随机梯度下降,还有不少改进的方法,如Momentum,Adagrad等等,有兴趣的可以看看http://cs231n.github.io/neural-networks-3/#update ,里面还有个动画,比较了不同方法的收敛速度的比较。
通过上面的分析,我们把问题变成了怎么求loss对参数W的梯度。
求梯度有如下4种方法:
-
手工求解析解
比如 f(x)=x^2, df/dx=2*x。然后我们要求f(x)在x=1.5的值,代进去就2*1.5=3
-
数值解
使用极限的定义:
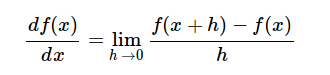
-
机器符号计算
让机器做符号运算,实现1的方法,但是机器如果优化的不好的话可能会有一些不必要的运算。
比如 x^2 + 2*x*y + y^2,直接对x求导数变成了 2*x + 2*y,两次乘法一次加分,但是我们可以合并一下变成2*(x+y),一次乘法一次加分。
-
自动梯度
下面我会在稍微细讲一下,所以这里暂时跳过。
这些方法的优缺点:
-
手工求解“数学”要求高,有可能水平不够求不对,但效率应该是能最优的。
-
没任何函数,甚至没有解析导数的情况下都能使用,缺点是计算量太大,而且只是近似解【因为极限的定义】,在某些特别不“连续”的地方可能误差较大。所以实际使用是很少,只是用它来验证其它方法是否正确。
-
机器符号计算,前面说的,依赖于这个库的好坏。
实际的框架,如TensorFlow就是自动梯度,而Theano就是符号梯度。
2.2.4 编程实战
通过上面的介绍,我们其实就可以实现一个经典的前馈(feed forward)神经网络了,这种网络结构很简单,每一层的输入是前一层的输出。输入层没有输入,它就是原始的信号输入。而且上一层的所有神经元都会连接到下一层的所有神经元,就像我们刚才的例子,输入是784,中间层是15,那么就有785*15个连接【再加上每个中间节点有一个bias】。所以这种网络有时候也加做全连接的网络(full connected),用来和CNN这种不是全连接的网络有所区别,另外就是信号是从前往后传递,没有反馈,所以也叫前溃神经网络,这是为了和RNN这种有反馈的区别。
当然,我们还没有讲怎么计算梯度,也就是损失函数相对于每一个参数的偏导数。在下一部分我们会详细讨论介绍,这里我们先把它当成一个黑盒的函数就好了。
-
代码
我们这里学习一下Nielsen提供的代码。代码非常简洁,只有不到100行代码。
https://github.com/mnielsen/neural-networks-and-deep-learninggit clone https://github.com/mnielsen/neural-networks-and-deep-learning.git
-
运行
创建一个 test_network1.py,输入如下代码:
import mnist_loader import network training_data, validation_data, test_data = mnist_loader.load_data_wrapper() net = network.Network([784, 30, 10]) net.SGD(training_data, 30, 10, 3.0, test_data=test_data)
保存后直接运行 Python test_network1.py。这里我们让他进行了30次迭代,最终在测试数据上的准确率大概在95%左右(当然因为随机初始化参数不同,最终的结果可能有所不同)
Epoch 0: 8250 / 10000Epoch 1: 8371 / 10000Epoch 2: 9300 / 10000......Epoch 28: 9552 / 10000Epoch 29: 9555 / 10000
3. 代码阅读
Python代码很容易阅读,即使之前没有用过,稍微学习两天也就可以上手,而且大部分机器学习相关的代码不会用到太复杂的语言特性,基本就是一些数学的线性代数的运算。而Python的numpy这个库是用的最多的,后面阅读代码的时候我会把用到的函数做一些介绍,继续下面的阅读之前建议花十分钟阅读一下 http://cs231n.github.io/python-numpy-tutorial/。
3.1 mnist_loader.load_data_wrapper函数
这个函数用来读取mnist数据,数据是放在data/mnist.pkl.gz。首先这是个gzip的压缩文件,是Pickle工具序列化到磁盘的格式。不熟悉也没有关系,反正我们知道这个函数的返回值就行了。
这个函数返回三个对象,分别代表training_data,validation_data和test_data。
training_data是一个50,000的list,然后其中的每一个元素是一个tuple。tuple的第一个元素是一个784维的numpy一维数组。第二个元素是10维的数组,也就是one-hot的表示方法——如果正确的答案是数字0,那么这个10维数组就是(1, 0, 0, …)。
而validation_data是一个10,000的list,每个元素也是一个tuple。tuple的第一个元素也是784维的numpy一维数组。第二个元素是一个0-9的数字,代表正确答案是那个数字。
test_data的格式和validation_data一样。
为什么training_data要是这样的格式呢?因为这样的格式计算loss更方便一些。
3.2 Network类的构造函数
我们在调用net = network.Network([784, 30, 10])时就到了init函数。为了减少篇幅,代码里的注释我都去掉了,重要的地方我会根据自己的理解说明,但是有空还是值得阅读代码里的注释。
class Network(object): def __init__(self, sizes):self.num_layers = len(sizes) self.sizes = sizes self.biases = [np.random.randn(y, 1) for y in sizes[1:]] self.weights = [np.random.randn(y, x) for x, y in zip(sizes[:-1], sizes[1:])]
比如上面的参数,我们保存下来的self.num_layers=3,也就是3层的网络。每一层的神经元的个数保存到self.sizes里。接下来就是构造biases数组并随机初始化。因为输入层是没有参数的,所以是for y in sizes[1:],我们使用了numpy的random.randn生成正态分布的随机数用来作为参数的初始值。注意这里生成了2维的随机变量。回忆一下,如果我们有30个hidden unit,那么bias的个数也是30,那就生成一个30维的1维数组就行了,为什么要是30*1的二维数组呢?其实用1维也可以,不过为了和weights一致,后面代码方便,就用二维数组了。另外weights也是一样的初始化方法,不过注意randn(y,x)而不是randn(x,y)。比如对于我们输入的[784,30,10],weights分别是30*784和10*30的。当然其实weights矩阵转置一下也可以,就是计算矩阵乘法的时候也需要有一个转置。不同的文献可能有不同的记法,但是我们在实现代码的时候只需要随时注意矩阵的大小,检查矩阵乘法满足乘法的约束就行了,矩阵AB能相乘,必须满足的条件是B的列数等于A的函数就行。
对于Nielsen的记法,矩阵的每一行就是一个神经元的784个参数,那么weights(30*784) * input(784*1)就得到30个hidden unit的加权累加。
3.3 feedforward函数
给点输入a(784维),计算最终神经网络的输出(10维)。
def feedforward(self, a): """Return the output of the network if ``a`` is input."""for b, w in zip(self.biases, self.weights): a = sigmoid(np.dot(w, a)+b) return a
代码非常简单,这里用到了np.dot,也就是矩阵向量的乘法,此外这里有一个Sigmoid函数,这个函数的输入是numpy的ndarray,输出也是同样大小的数组,不过对于每个元素都进行了sigmoid的计算。用numpy的术语就是universal function,很多文献里一般都叫elementwise的function。我觉得后面这个名字更直接。
#### Miscellaneous functionsdef sigmoid(z): """The sigmoid function."""return 1.0/(1.0+np.exp(-z))def sigmoid_prime(z): """Derivative of the sigmoid function."""return sigmoid(z)*(1-sigmoid(z))
上面就是Sigmoid函数,另外也把sigmoid_prime,也就是Sigmoid的导数放在了一起【不记得的话看前面Sigmoid的导数的推导】。
3.4 SGD函数
这个函数是训练的入口,比如我们之前的训练代码:
net.SGD(training_data, 30, 10, 3.0, test_data=test_data)def SGD(self, training_data, epochs, mini_batch_size, eta,
test_data=None):if test_data: n_test = len(test_data)
n = len(training_data) for j in xrange(epochs):
random.shuffle(training_data)
mini_batches = [
training_data[k:k+mini_batch_size] for k in xrange(0, n, mini_batch_size)] for mini_batch in mini_batches:
self.update_mini_batch(mini_batch, eta) if test_data: print "Epoch {0}: {1} / {2}".format(
j, self.evaluate(test_data), n_test) else: print "Epoch {0} complete".format(j)
第一个参数就是training_data。
第二个参数就是epochs,也就是总共对训练数据迭代多少次,我们这里是30次迭代。
第三个参数是batch大小,我们这里是10,最后一个参数是eta,也就是步长,这里是3.0。除了网络结构(比如总共多少个hidden layer,每个hidder layer多少个hidden unit),另外一个非常重要的参数就是步长。前面我们也讨论过了,步长太小,收敛速度过慢,步长太大,可能不收敛。实际的情况是没有一个万能的准则,更多的是根据数据,不停的尝试合适的步长。如果发现收敛太慢,就适当调大,反之则调小。所以要训练好一个神经网络,还是有很多tricky的技巧,包括参数怎么初始化,激活函数怎么选择,比SGD更好的优化算法等等。
第四个参数test_data是可选的,如果有(我们的例子是穿了进来的),则每次epoch之后都测试一下。
代码的大致解释我用注释的形式嵌在代码里了:
for j in xrange(epochs): ## 一共进行 epochs=30 轮迭代
random.shuffle(training_data) ## 训练数据随机打散
mini_batches = [
training_data[k:k+mini_batch_size] for k in xrange(0, n, mini_batch_size)] ## 把50,000个训练数据分成5,000个batch,每个batch包含10个训练数据。
for mini_batch in mini_batches: ## 对于每个batch
self.update_mini_batch(mini_batch, eta) ## 使用梯度下降更新参数
if test_data: ## 如果提供了测试数据
print "Epoch {0}: {1} / {2}".format(
j, self.evaluate(test_data), n_test) ## 评价在测试数据上的准确率
else:
print "Epoch {0} complete".format(j)
下面是evaluate函数:
def evaluate(self, test_data): test_results = [(np.argmax(self.feedforward(x)), y) for (x, y) in test_data] return sum(int(x == y) for (x, y) in test_results)
对于test_data里的每一组(x,y),y是0-9之间的正确答案。而self.feedforward(x)返回的是10维的数组,我们选择得分最高的那个值作为模型的预测结果np.argmax就是返回最大值的下标。比如x=[0.3, 0.6, 0.1, 0, ….],那么argmax(x) = 1。
因此test_results这个列表的每一个元素是一个tuple,tuple的第一个是模型预测的数字,而第二个是正确答案。
所以最后一行返回的是模型预测正确的个数。
3.5 update_mini_batch函数
def update_mini_batch(self, mini_batch, eta):nabla_b = [np.zeros(b.shape) for b in self.biases] nabla_w = [np.zeros(w.shape) for w in self.weights] for x, y in mini_batch: delta_nabla_b, delta_nabla_w = self.backprop(x, y) nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)] nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)] self.weights = [w-(eta/len(mini_batch))*nw for w, nw in zip(self.weights, nabla_w)] self.biases = [b-(eta/len(mini_batch))*nb for b, nb in zip(self.biases, nabla_b)]
它的输入参数是mini_batch【size=10的tuple(x,y)】和eta【3.0】。
def update_mini_batch(self, mini_batch, eta):nabla_b = [np.zeros(b.shape) for b in self.biases] ## 回忆一下__init__,biases是一个列表,包含两个矩阵,分别是30*1和10*1 ## 我们先构造一个和self.biases一样大小的列表,用来存放累加的梯度(偏导数) nabla_w = [np.zeros(w.shape) for w in self.weights] ## 同上, weights包含两个矩阵,大小分别是30*784和10*30 for x, y in mini_batch: delta_nabla_b, delta_nabla_w = self.backprop(x, y) ## 对于一个训练数据(x,y)计算loss相对于所有参数的偏导数 ## 因此delta_nabla_b和self.biases, nabla_b是一样大小(shape) ## 同样delta_nabla_w和self.weights,nabla_w一样大小 nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)] ## 把bias的梯度累加到nabla_b里 nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)] ## 把weight的梯度累加到nable_w里 self.weights = [w-(eta/len(mini_batch))*nw for w, nw in zip(self.weights, nabla_w)] ## 使用这个batch的梯度和eta(步长)更新参数weights self.biases = [b-(eta/len(mini_batch))*nb for b, nb in zip(self.biases, nabla_b)] ## 更新biases ## 这里更新参数是除了batch的大小(10),有的人实现时不除,其实没有什么区别,因为超参数eta会有所不同,如果不除,那么eta相当于是0.3(在eta那里就除了batch的大小了)。
3.6 backprop函数
这个函数就是求loss相对于所有参数的偏导数,这里先不仔细讲解,等下次我们学习梯度的求解方法我们再回来讨论,这里可以先了解一下这个函数的输入和输出,把它当成一个黑盒就行,其实它的代码也很少,但是如果不知道梯度的公式,也很难明白。
def backprop(self, x, y): nabla_b = [np.zeros(b.shape) for b in self.biases] nabla_w = [np.zeros(w.shape) for w in self.weights] # feedforwardactivation = x activations = [x] # list to store all the activations, layer by layerzs = [] # list to store all the z vectors, layer by layerfor b, w in zip(self.biases, self.weights): z = np.dot(w, activation)+b zs.append(z) activation = sigmoid(z) activations.append(activation) # backward passdelta = self.cost_derivative(activations[-1], y) * \ sigmoid_prime(zs[-1]) nabla_b[-1] = delta nabla_w[-1] = np.dot(delta, activations[-2].transpose()) for l in xrange(2, self.num_layers): z = zs[-l] sp = sigmoid_prime(z) delta = np.dot(self.weights[-l+1].transpose(), delta) * sp nabla_b[-l] = delta nabla_w[-l] = np.dot(delta, activations[-l-1].transpose()) return (nabla_b, nabla_w)
它的输入就是一个训练样本(x,y)分别是784*1和10*1。输出就是和self.biases,self.weights一样大小的列表,然后列表中的每一个数组的大小也是一样。具体到上面的例子,输出nabla_b包含两个矩阵,大小分别是30*1和10*1;nabla_w也包含两个矩阵,大小分别是30*784和10*30。
从Image Caption Generation理解深度学习(part III)
环信作为国内唯一拥有从云通讯到服务云,再到机器人的完整一体化产品技术储备的公司,目前在积极筹备关于深度学习系列的公开课,本系列公开课文章面向深度学习研发者,共计14篇,系统讲解了深度学习的基本知识及实践,以Image Caption Generation为切入点,逐步介绍自动梯度求解、卷积神经网络(CNN)、递归神经网络(RNN)等知识点。
本篇文章( part I、part II、part III)希望通过Image Caption Generation,一个有意思的具体任务,来介绍深度学习的知识,涉及到很多深度学习流行的模型,如CNN,RNN/LSTM,Attention等。作者李理,毕业于北京大学,就职于环信,在环信从事智能客服和智能机器人相关工作,致力于用深度学习来提高智能机器人的性能。
2.2.5 反向传播算法的推导
前面我们用很简单的几十行python代码基本上完成了一个多层神经网络。但是还差最重要的部分,那就是计算loss function对参数的偏导数,也就是反向传播算法。下面我们来仔细的完成公式的推导,以及接下来会讲怎么用代码来实现。这一部分数学公式多一些,可能很多读者会希望跳过去,不过我还是建议大家仔细的阅读,其实神经网络用到的数学相比svm,bayes network等机器学习算法,已经非常简单了。请读者阅读的时候最好准备一支笔和几张白纸,每一个公式都能推导一下。如果坚持下来,你会觉得其实挺简单的。
(1) feedforward阶段的矩阵参数表示和计算
之前我们讨论的是一个神经元的计算,而在代码里用到的却是矩阵向量乘法。而且细心的读者会发现我们在构造参数矩阵weights的时候,行数和列数分别是后一层的节点数和前一层的节点数。这似乎有点不自然,为什么不反过来呢?看过下面这一部分就会明白了。
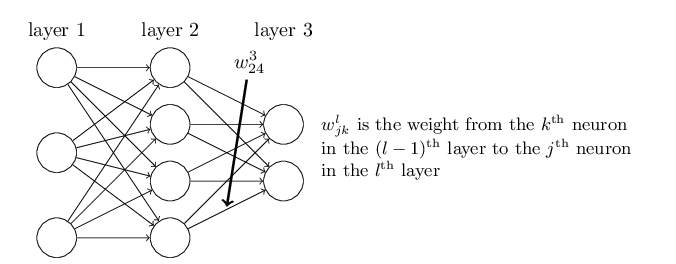
首先我们熟悉一下第L(因为小写的L和1太像,所以我用大写的L)层的参数w_jk。它表示第L-1层的第k个神经元到第L层的第j个神经元的权重。比如第3层的w_24,参考上面的图,它表示的是第2层的第4个神经元到第3层的第二个神经元。
对bias和激活函数后的结果a也采用类似的记号,如下图所示。
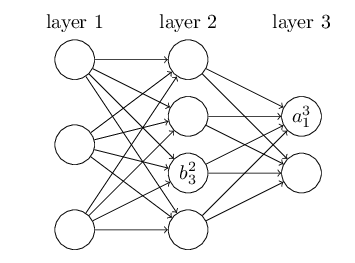
b_32表示第2层的第3个神经元的bias,而a_13第3层的第1个神经元的激活。
使用上面的记号,我们就可以计算第L层的第j个神经元的输出a_jl:
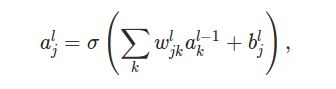
第L层的第j个神经元的输入是L-1层的a_1,a_2,...;对应的权值是w_j1,w_j2,...;bias是b_jL。所以a_jL就是上面的公式,k的范围是从1到第L-1层的神经元的个数。
为了用矩阵向量乘法来一次计算第L层的所有神经元的输出,我们需要定义第L层的参数矩阵w_l,它的大小是m*n,其中m是第L层的神经元个数;而n则是第L-1层的个数。它的第i行第j列就是我们上面定义的w_jk。此外我们还要定义向量b_l,它的大小是m(也就是第L层神经元的个数),它的第j个元素就是我们上面定义的b_j。
最后,我们定义element-wise的函数,比如f(x) = x^2,如果输入是一个向量,那么结果是和输入一样大小的向量,它的每个元素是对输入向量的每一个元素应用这个函数的结果。

有了上面的定义,我们就可以一次计算出第L层的输出(一个长度为m的向量)
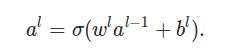
下面是对上面这个公式的详细证明(说明):
我们需要证明的是向量aL的第j个元素就是前面的a_jL

此外,为了方便后面的求解,我们把加权累加和也用一个符号z_l来表示。
![]()
其中,它的第j个元素就是第L层的第j个神经元的加权累加和:
![]()
这样a_l就可以简单的对z_l的每个元素计算激活函数
![]()
现在我们再回顾一下feedforward的代码就非常直观了:
def feedforward(self, a):"""Return the output of the network if a is input."""for b, w in zip(self.biases, self.weights): a = sigmoid(np.dot(w, a)+b)return a
传给函数feedforward的参数a就是输入向量x,第一层就是x,第二层就是第一个隐层,每一层的计算就是非常简单的参数矩阵w_l乘以上一层的激活a_l-1在加上b_l,然后用激活函数计算。
初始化的时候w的大小是 (后一层的神经元个数) * (前一层的神经元个数),再回顾一下初始化参数的代码:
# sizes = [784, 30, 10]def __init__(self, sizes):self.num_layers = len(sizes) self.sizes = sizes self.biases = [np.random.randn(y, 1) for y in sizes[1:]] self.weights = [np.random.randn(y, x)for x, y in zip(sizes[:-1], sizes[1:])]
x, y in zip(sizes[:-1], sizes[1:]) x是第一层到最后倒数第二层,y是第二层到最后一层,比如上面的sizes=[784, 30, 10]
x是[784, 30], y是[30, 10],注意随机的矩阵是(y,x),所以self.weights是两个矩阵,大小分别是30*784和10*30
(2) 关于损失函数C的两个假设
1. 损失函数是每个训练数据的损失的平均
也就是C是这样的形式:
![]()
对于之前我们使用的MSE损失函数,这是满足的。我们使用batch的梯度下降的时候需要求C对参数w的偏导数,因为损失函数是每个训练数据的损失的平均,所以我们只需要求每个数据的偏导数,然后加起来平均就行。这个假设几乎所有的损失函数都是满足的【我是没见过损失函数不满足这个条件】
-
损失函数是最后一层输出的函数
![]()
这个条件几乎常见的损失函数都是这样的,我们之前时候的MSE就是计算最后一层的输出aL和正确的y(one-hot)的均方误差,显然是满足的。
(3) Hadamard product
这个名字看起来很复杂,其实很简单,就是两个向量elementwise的乘法。看一个例子就清楚了:
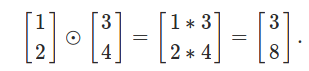
(4) 反向传播算法(back propagation)的4个公式
回顾一下,我们之前说了,梯度下降其实最核心的问题就是求损失函数对每一个参数的偏导数。那我们就直接一个一个求好了,为什么又要搞出一个反向传播算法呢?其实这个算法在不同的领域被不同的人重复“发现”过很多次,有过很多不同的名字,最本质的应该就是逆向求导(reverse-mode differentiation)或者叫做自动求导(automatic differentiation)。自动求导(AD)是非常通用的一种求偏导数的方法,很早就在流体力学和大气物理等领域使用,反向传播算法可以认为是AD在神经网络中的应用。不过最早发现这个算法的人(是谁最早好像还有点争议)并不是先知道AD可以直接用于神经网络,他发现这个算法是基于错误的反向传播而得到的,所有命名为(错误的)反向传播算法。后面我们会讲到AD,这是一个强大的算法,任何一个函数,你能把它分解成有向无环图的计算图【函数一般都能分解成一些无依赖的最基础的变量的复合函数,因此肯定可以表示成这样一个有向无环图】,然后每个节点都表示一个函数。只要你能求出这个函数在特定点的梯度【也就是这个函数对所以自变量的偏导数】(不需要求解析的偏导数,当然很多情况,这些函数都是能直接求出解析解,然后代入这个特定点就行,但理论上我们是可以用其他方法,比如数值梯度近似来求的),就能自动的计算损失函数对每一个参数的偏导数(也是在这个点的),而且只要反向根据拓扑排序遍历这个图一次就行,非常高效和简单。后面我们会详细的介绍AD。这个方法非常通用,TensorFlow的核心就是AD。使用AD的框架就比较灵活,我想“创造”一种新的网络结构,我又不想【其实更可能是不会】推导出梯度的公式,那么我只需要把我的网络能用这样一个有向无环图表示就行。当然节点必须要能够求出梯度来,一般我们的函数比如矩阵的运算,卷积等等TensorFlow都封装好了——它把它叫做一个op。我们只需要搭积木一样把这个计算图定义出来,TensorFlow就自动的能根据AD计算出损失函数对所有参数的梯度来了。当然如果你要用到一个TensorFlow没有的op,那你就需要根据它的规范实现这个op,一个op最核心的接口就是两个,一个是输入x,求f(x);另一个就是求f在某个x0点的梯度。
不过这里,我们还是沿着神经网络的发展历史,从错误的反向传播角度来理解和推导这个算法。
首先,我们会对每一个神经元比如第L层的第j个,都定义一个错误δ_jL
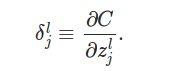
也就是损失函数对z也就是线性累加和的偏导数。为什么定义这样一个东西呢?我们假设在第L层的第j个神经元上有一个精灵(Daemon)
当这个神经元得到来自上一次的输入累加计算出z_jL的时候,它会恶作剧的给一点很小的干扰Δz_jL。原来它应该输出的是σ(z_jL),现在变成了σ(z_jL +Δz_jL)。这个微小的变化逐层传播,最终导致损失函数C也发生如下的变化:
![]()
这个其实就是导数的直觉定义:微小的Δx引起微小的Δy,Δy/Δx约等于导数。
不过这个精灵是个好精灵,它想帮助我们减少损失。 当
![]()
大于0的时候,它让Δz_jL小于0,反之当它小于0的时候它让Δz_jL大于0。这样
![]()
总是小于0
因此我们的loss就会变小。而其绝对值越大,我们的损失减少的越多。
当然你会说为什么不能让Δz_jL非常大,这样我们的损失总是减少很多?可惜这个精灵是个数学家,它说如果Δx太大,那么Δy=df/dx *Δx就不准确了。
所以我们可以这样认为:它就是第L层的第j个神经元“引起”的“错误”。如果绝对值大,则它的“责任”也大,它就得多做出一些调整;反之如果它趋近于0,说明它没有什么“责任”,也就不需要做出什么改变。
因此通过上面的启发,我们定义出δ_jL来。

接下来我们逐个介绍反向传播算法的4个公式。
公式1. 第L层(最后一层) 的错误
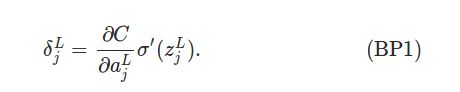
这个公式的第一项,就是损失C对a_jL的导数,它越大,说明C受a_jL的影响也就越大,如果有了错误,第a_jL的“责任”也就越大,错误也就越大。第二项是a_jL受z_jL的影响。两者乘起来就是z_jL对最终损失的影响,也就是它的“责任”的大小。
这个公式很好计算,首先第二项就是把z_jL的值(这个在feedforward节点就算出来并存储下来了)代入σ'(x)。如果σ是sigmoid函数,我们前面也推导过它的导数:σ’(x)=σ(x)*(1-σ(x))。第一项当然依赖于损失函数的定义,一般也很好求。比如我们的MSE损失:
![]()
![]()
具体的推导我在纸上写了一下,虽然很简单,我们也可以练练手,尤其是对于求和公式的展开,希望大家能熟悉它,以后的推导我可能就不展开求和公式了,你需要知道求和公式里哪些项是和外面的自变量无关的。

公式BP1是elementwise的,我们需要变量j来计算每一个δ_jL。我们也可以把它写成向量的形式,以方便利用线性代数库,它们可以一次计算向量或者矩阵,可以用很多技术利用硬件特性来优化(包括GPU,SSE等)速度。
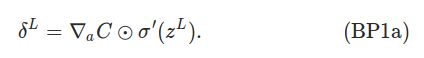
右边δ'(z_L)很容易理解,左边的记号可能有些费解,其实我们把∇aC当成一个整体就好了,它是一个向量,第一个元素是∂C/∂a_1L,第二个就是∂C/∂a_2L,…
如果算上函数C是MSE的话,上面的公式就可以简化成:

公式2. 第l层(非最后一层) 的错误

等下我们会证明这个公式,不过首先我们来熟悉一下公式。如果我们想“背”下这个公式的话,似乎看起来比第一个BP1要复杂很多 。我们先检查一下矩阵和向量的维度,假设l+1层有m个元素,l层n个。则w_l+1的大小是m*n,转置之后是n*m, δ_l+1的大小是n*1,所以矩阵相乘后是m*1,这和δ_l是一样的,没有问题。
接下来我们仔细观察一下BP2这个公式,首先第二项σ'(z_l)和前面的含义一样,代表a_l对于z_l的变化率。
而第一项复杂一点,我们知道第l层的第j个神经元会影响第l+1层的所有神经元,从而也影响最终的损失C。这个公式直接给了一个矩阵向量的形式,看起来不清楚,所以我在草稿纸上展开了:
最终第L层的第j个神经元的损失就是如下公式:
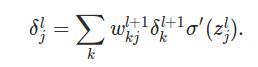
这下应该就比较清楚了,第l层的第j个神经元的损失,就是把l+1层的损失“反向传播”回来,当然要带上权重,权重越大,“责任”也就越大。
如果要“背”出这个公式也没有那么复杂了,先不看σ'(z_l),第一项应该是矩阵w_l+1乘以δ_l+1。由于矩阵是m*n,而
向量δ_l+1是m*1,为了能让矩阵乘法成立,那么就只能把w转置一下,变成n*m,然后就很容易记住这个公式了。
注意,BP2的计算是从后往前的,首先根据BP1,最后一层的δ_L我们已经算出来了,因此可以向前计算L-1层的δ_L-1,
有了δ_L-1就能计算δ_L-2,…,最终能算出第一个隐层(也就是第2层)δ_1来。
公式3. 损失函数对偏置b的梯度
这前面费了大力气求δ_l,不要忘了我们的最终目标是求损失函数对参数w和b的偏导数,而不是求对中间变量z的偏导数。
因此这个公式就是对b的偏导数。

或者写成向量的形式:
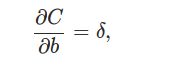
∂C/∂b就是δ!
公式4. 损失函数对w的梯度

或者参考下图写成好记的形式:
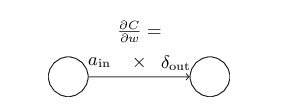
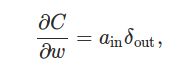
也就是说对于一条边w_jkL,∂C/∂w_ij就是这条边射出的点的错误δ乘以进入点的激活。非常好记。
我们把这四个公式再总结一下:

(5) 这四个公式的证明
首先是BP1,请参考下图:

然后是BP2:
这里用到了chain rule,其实也非常简单和直观,就是复合函数层层组合。最简单的方法就是用图画出来,比如y最终
是x的函数,我们要求∂y/∂x,如果y是u,v的函数,然后u,v才是x的函数,那么我们把变量x,y,u,v都画成图上的点,y是u,v的函数,那么我们画上从u和v到y的边,同样,我们画上从x到u和v的边,然后从y到x的每条路径,我们经过的边都是一个偏导数,我们把它累加起来就行【这其实就是后面我们会讲的AD】。因此∂y/∂x=∂y/∂u * ∂u/∂x +∂y/∂v * ∂v/∂x。

剩下的BP3和BP4也非常类似,我就不证明了。
反向传播算法
1. a_1 = 输入向量x
2. Feedforward 根据公式
![]()
和
![]()
计算z_l和a_l并存储下来(反向传播时要用的)
3. 计算最后一层的错误
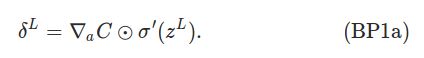
-
向前计算所有层的错误
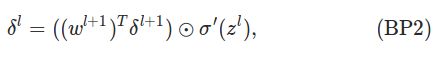
-
计算损失对所有参数的偏导数


2.2.6 代码实现反向传播算法
我们已经把公式推导出来了,那怎么用代码实现呢?我们先把代码复制一下,然后说明部分都是作为代码的注释了,
请仔细阅读。
class Network(object): def update_mini_batch(self, mini_batch, eta): # mini_batch是batch大小,eta是learning rate nabla_b = [np.zeros(b.shape) for b in self.biases] # 构造和self.biases一样大小的向量,比如前面的例子 sizes=[784,30,10],则 # nabla_b是两个向量,大小分别是30和10 nabla_w = [np.zeros(w.shape) for w in self.weights] # 构造和self.weights一样大小的矩阵,比如前面的例子 sizes=[784,30,10],则 # nabla_w是两个矩阵,大小分别是30*784和10*30 for x, y in mini_batch: #对于每个训练样本x和y delta_nabla_b, delta_nabla_w = self.backprop(x, y) # 用backprop函数计算损失函数对每一个参数的偏导数。 # backprop函数下面会详细讲解 nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)] # 把返回的对b偏导数累加到nabla_b中 nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)] # 把返回的对w的偏导数累加到nabla_w中 self.weights = [w-(eta/len(mini_batch))*nw for w, nw in zip(self.weights, nabla_w)] # 计算完一个batch后更新参数w self.biases = [b-(eta/len(mini_batch))*nb for b, nb in zip(self.biases, nabla_b)] # 更新b... def backprop(self, x, y): # 输入是x和y,返回损失函数C对每个参数w和b的偏导数 # 返回的格式是两个元组,第一个是b的偏导数,第二个是w的。 nabla_b = [np.zeros(b.shape) for b in self.biases] # 构造和self.biases一样大小的向量,比如前面的例子 sizes=[784,30,10],则 # nabla_b是两个向量,大小分别是30和10 nabla_w = [np.zeros(w.shape) for w in self.weights] # 构造和self.weights一样大小的矩阵,比如前面的例子 sizes=[784,30,10],则 # nabla_w是两个矩阵,大小分别是30*784和10*30 # feedforward activation = x activations = [x] # 用一个list保存所有层的激活,下面backward会有用的 zs = [] # 同样的用一个list保存所有层的加权累加和z,下面也会用到。 #下面这段代码在feedward也有,不过那里是用来predict用的不需要保存zs和activations for b, w in zip(self.biases, self.weights): z = np.dot(w, activation)+b zs.append(z) activation = sigmoid(z) activations.append(activation) # backward pass #1. 首先计算最后一层的错误delta,根据公式BP1,它是损失函数对a_L的梯度乘以σ'(z_L) # sigmoid_prime就是σ'(z_L),而∂C/∂a_L就是函数cost_derivative,对于MSE的损失函数, # 它就是最后一层的激活activations[-1] - y delta = self.cost_derivative(activations[-1], y) * \ sigmoid_prime(zs[-1]) # 2. 根据公式BP3,损失对b的偏导数就是delta nabla_b[-1] = delta # 3. 根据公式BP4,损失对w的偏导数时delta_out * activation_in # 注意,我们的公式BP4是elementwise的,我们需要写成矩阵向量的形式 # 那怎么写呢?我们只需要关心矩阵的大小就行了。 # 假设最后一层有m(10)个神经元,前一层有n(30)个, # 则delta是10*1, 倒数第二层的激活activations[-2]是30*1 # 我们想求的最后一层的参数nabla_w[-1]是10*30,那么为了能够正确的矩阵乘法, # 只要一种可能就是 delta 乘以 activations[-2]的转置,其实也就是向量delta和activations[-2]的外积 nabla_w[-1] = np.dot(delta, activations[-2].transpose()) # 接下来从倒数第二层一直往前计算delta,同时也把对w和b的偏导数求出来。 # 这里用到一个比较小的trick就是python的下标是支持负数的,-1表示最后一个元素,-2是倒数第二个 # l表示倒数第l层,2就表示倒数第2层,num_layers - 1就表示顺数第2层(也就是第1个隐层) # 比如我们的例子:sizes=[784, 30, 10],那么l就是从2到3(不包含3),l就只能是2,页就是第1个(也是唯一的一 # 个)隐层 for l in xrange(2, self.num_layers): # 倒数第l层的z z = zs[-l] # 计算σ'(z_l) sp = sigmoid_prime(z) # 根据BP2,计算delta_l,注意weights[-l+1]表示倒数第l层的下一层 delta = np.dot(self.weights[-l+1].transpose(), delta) * sp # 同上,根据BP3 nabla_b[-l] = delta # BP4,矩阵乘法参考前面的说明 nabla_w[-l] = np.dot(delta, activations[-l-1].transpose()) return (nabla_b, nabla_w)
2.2.7 为什么反向传播算法是一个高效的算法?
分析完代码,我们发现一次backprop函数调用需要feedforward一次,网络有多少边,就有多少次乘法,有多少个点就有多少次加分和激活函数计算(不算第一层输入层)。反向计算也是一样,不过是从后往前。也就是说这是时间复杂度为O(n)的算法。
如果我们不用反向传播算法,假设我们用梯度的定义计算数值梯度。对于每一个参数wj,
我们都用公式 limit (f(w1, w2, …, wj+Δ wj, …) - f(w1, w2, …, wj, …)/Δwj
f(w1, w2, wj, …)只需要feedforward一次,但是对于每个参数wj,都需要feedforward一层来计算f(w1, w2, …, wj+Δ wj, …),它的时间复杂度是O(n),那么对所有的参数的计算需要O(n^2)的时间复杂度。
假设神经网络有1百万个参数,那么每次需要10^12这个数量级的运算,而反向传播算法只需要10^6,因此这个方法比反向传播算法要慢1百万倍。
自动梯度求解 反向传播算法的另外一种视角
前面我们讲过了反向传播算法的详细推导过程,大家可能会觉得有些复杂。事实上其实就是链式求导法则的应用。今天我们将会继续讨论这个问题,不过是从Computational Graphs的角度,也就是我们之前说过的自动求导(Automatic Differentiation or Reverse-mode Differentiation)。并且通过CS231n的Assignment2来学习使用这种方法,通过这种方法来实现一个多层的神经网络。
Calculus on Computational Graphs: Backpropagation
首先我们介绍一篇博客文章: https://colah.github.io/posts/2015-08-Backprop/ 基本是翻译过来,不过部分地方是我自己的理解,建议读者结合这篇文章一起阅读。
简介
反向传播算法是神经网络的核心算法,不过这个算法在不同的领域被多次”发现“过,因此有不同的名称。
计算图(Computational Graphs)
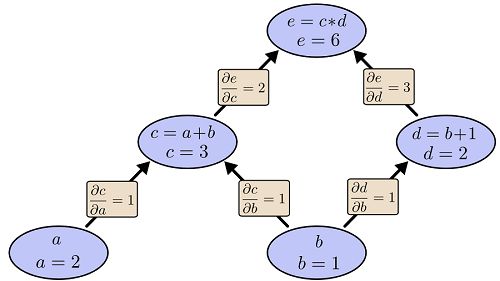
考虑一个简单的函数 e=(a+b)∗(b+1)e=(a+b)∗(b+1) 。这个函数有两个操作(函数),加法和乘法。为了指代方便,我们引入两个中间变量,c和d。
-
c=a+b
-
d=b+1
-
e=c∗d
下面我们把它画成一个计算图,每一个操作是图中一个节点,最基本的变量a和b也是一个节点。每个节点和它的输入变量直接有一条边。比如d的输入变量是b,那么d和b直接就有一条边。
任何一个显示定义的函数(隐函数不行,不过我们定义的神经网络肯定不会通过隐函数来定义)都可以分解为一个有向无环图(树),其中叶子节点是最基本的无依赖的自变量,而中间节点是我们引入的中间变量,而树根就是我们的函数。比如上面的例子,计算图如下所示:
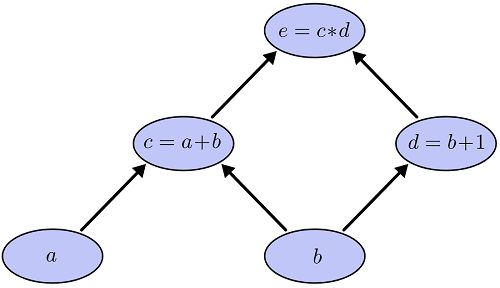
给定每一个自变量的值,我们可以计算最终的函数值,对应与神经网络就是feedforward计算。具体用”算法“怎么计算呢?首先因为计算图是一个有向无环图,因此我们可以拓扑排序,先是叶子节点a和b,他们的值已经给定,然后删除a和b出发的边,然后c和d没有任何未知依赖,可以计算,最后计算e。计算过程如下图:
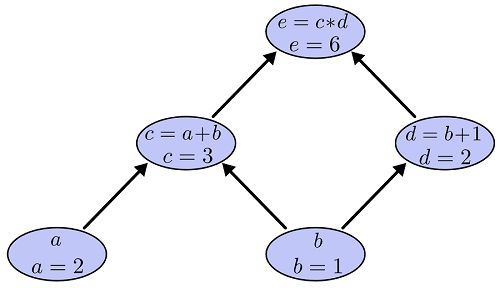
计算图的导数计算
首先我们可以计算每条边上的导数,也就是边的终点对起点的导数,而且导数是在起点的取前向计算值时的导数,具体过程如图所示:
有些边的导数不依赖于输入的值,比如:
![]()
但是还有很多边的导数是依赖于输入值的,比如:
![]()
因为在“前向”计算的过程中,每个节点的值都计算出来了,所以边的计算很简单,也不需要按照什么的顺序。
不过我们一般比较感兴趣的是最终函数对某个自变量的导数,比如
![]()
根据链式法则,只要找到这两个节点的所有路径,然后把路径的边乘起来就得到这条边的值,然后把所有边加起来就可以了。
比如上面的例子b到e有两条路径:b->c->e和b->d->e,所以
![]()
如果用“链式”法则来写就是
![]()
路径反过来而已。
使用上面的方法,我们可以计算任何一个点(上面的变量)对另外一个点(上面的变量)的导数。不过我们一般的情况是计算树根对所有叶子的导数,当然我们可以使用上面的算法一个一个计算,但是这样会有很多重复的计算。
比如a->e的路径是 a->c->e,b->e有一条边是b->c->e,其中c->e是重复的【这个例子不太好,我们可以想像c->e是一条很长的路径】,每次都重复计算c->e这个“子”路径是多余的。我们可以从后往前计算,也就是每个节点都是存放树根变量(这个例子是e)对当前节点的导数(其实也就是树根到当前节点的所有路径的和)。
反向导数计算
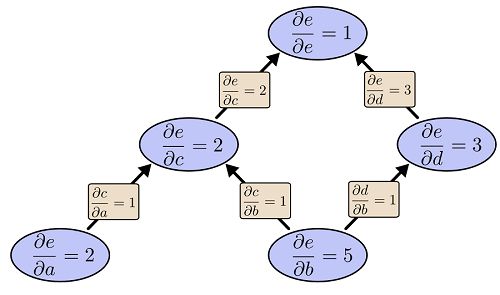
计算流程文字描述如下:
首先还是对这个图进行拓扑排序,不过是反过来。
首先是
![]()
这个没什么好说的。
然后计算
![]()
然后计算
![]()
然后计算
![]()
计算
![]()
前向导数计算
如果我们需要计算每一个变量对某一个变量的导数,就可以使用前向计算的方法。不过我们的神经网络都是相反——计算某个一个变量(一般是损失函数)对所有变量的导数,所以这里就不详细介绍了。
Optimization
这一部分内容来自:CS231n Convolutional Neural Networks for Visual Recognition
简介
我们的目标:x是一个向量,f(x)是一个函数,它的输入是一个向量(或者认为是多变量的函数,这个输入向量就是自变量),输出是一个实数值。我们需要计算的是f对每一个自变量的导数,然后把它们排成一个向量,也就是梯度。
![]()
为什么要求这个呢?前面我们也讲了,我们的神经网络的损失函数最终可以看成是权重weights和bias的函数,我们的目标就是调整这些参数,使得损失函数最小。
简单的表达式和梯度的解释
首先我们看一个很简单的函数 f(x,y)=xy,求f对x和y的偏导数很简单:
![]()
首先来看导数的定义:
![]()
函数在某个点的导数就是函数曲线在这个点的斜率,也就是f(x)随x的变化率。
比如上面的例子,当x=4,y=−3时 f(x,y)=−12,f对x的偏导数
![]()
也就是说,如果我们固定y=4,然后给x一个很小的变化h,那么f(x,y)的变化大约是-3*h。
因此乘法的梯度就是
![]()
同样,加法的梯度更简单:
![]()
最后一个简单函数是max函数:
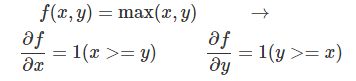
这个导数是ReLU(x)=max(x,0)的导数,其实也简单,如果 x>=y,那么 max(x,y)=x,则导数是1,否则 max(x,y)=0,那么对x求导就是0。
复杂表达式的链式法则
接下来看一个稍微复杂一点的函数 f(x,y,z)=(x+y)z。我们引入一个中间变量q,f=qz,q=x+y,我们可以使用链式法则求f对x和y的导数。
![]()
对y的求导也是类似的。
下面是用python代码来求f对x和y的导数在某一个点的值。
# 设置自变量的值x = -2; y = 5; z = -4# “前向”计算fq = x + y # q becomes 3f = q * z # f becomes -12# 从“后”往前“反向”计算# 首先是 f = q * zdfdz = q # 因为df/dz = q, 所以f对z的梯度是 3dfdq = z # 因为df/dq = z, 所以f对q的梯度是 -4# 然后 q = x + ydfdx = 1.0 * dfdq # 因为dq/dx = 1,所以使用链式法则计算dfdx=-4dfdy = 1.0 * dfdq # 因为dq/dy = 1,所以使用链式法则计算dfdy=-4
我们也可以用计算图来表示和计算:

绿色的值是feed forward的结果,而红色的值是backprop的结果。
不过我觉得cs231n课程的这个图没有上面blog的清晰,原因是虽然它标示出来了最终的梯度,但是没有标示出local gradient,我在下面会画出完整的计算过程。
反向传播算法的直觉解释
我们如果把计算图的每一个点看成一个“门”(或者一个模块),或者说一个函数。它有一个输入(向量),也有一个输出(标量)。对于一个门来说有两个计算,首先是根据输入,计算输出,这个一般很容易。还有一种计算就是求输出对每一个输入的偏导数,或者说输出对输入向量的”局部“梯度(local gradient)。一个复杂计算图(神经网络)的计算首先就是前向计算,然后反向计算,反向计算公式可能看起来很复杂,但是如果在计算图上其实就是简单的用local gradient乘以从后面传过来的gradient,然后加起来。
Sigmoid模块的例子
接下来我们看一个更复杂的例子:
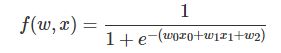
这个函数是一个比较复杂的复合函数,但是构成它的基本函数是如下4个简单函数:
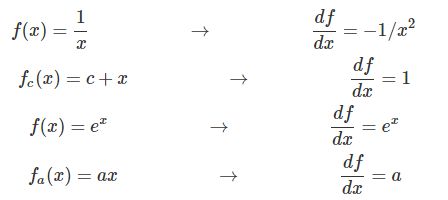
下面是用计算图画出这个计算过程:
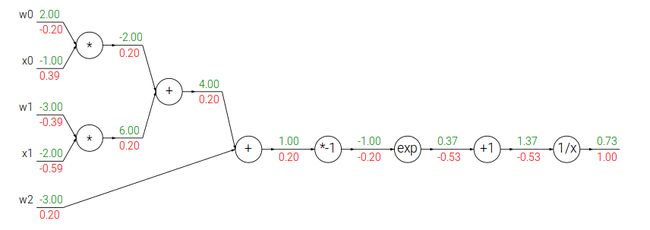
这个图有4种gate,加法,乘法,指数和倒数。加法有加一个常数和两个变量相加,乘法也是一样。
上图绿色的值是前向计算的结果,而红色的值是反向计算的结果,local graident并没有标示出来,所以看起来可能有些跳跃,下面我在纸上详细的分解了其中的步骤,请读者跟着下图自己动手计算一遍。

上图就是前向计算的过程,比较简单。
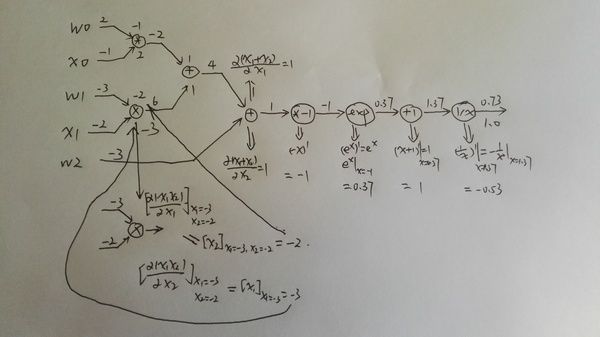
第二个图是计算local gradient,对于两个输入的乘法和加法,local gradient也是两个值,local gradient的值我是放到图的节点上了。
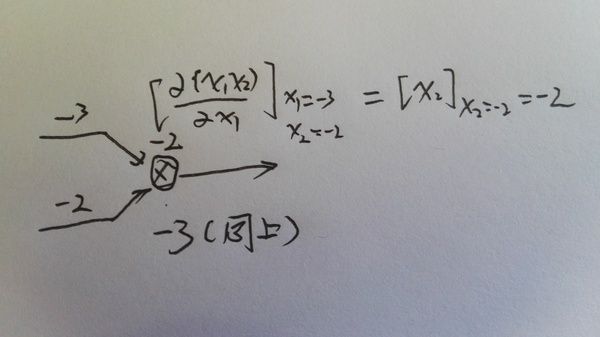
第三个图是具体计算一个乘法的local gradient的过程,因为上图可能看不清,所以单独放大了这一步。
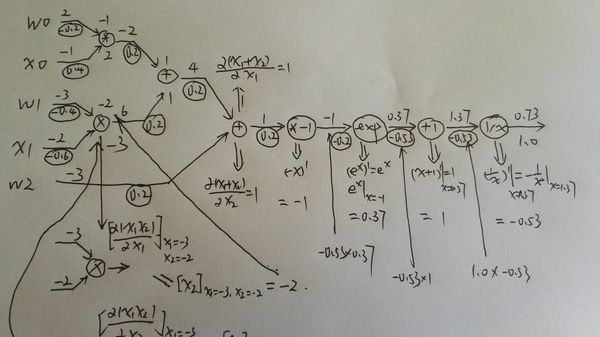
最后计算真正的梯度,是把local gradient乘以来自上一步的gradient。不过这个例子一个节点只有一个输出,如果有多个的话,梯度是加起来的,可以参考1.4的
![]()
上面我们看到把
![]()
分解成最基本的加法,乘法,导数和指数函数,但是我们也可以不分解这么细。之前我们也学习过了sigmoid函数,那么我们可以这样分解:
![]()
σ(x)σ(x) 的导数我们之前已经推导过一次了,这里再列一下:
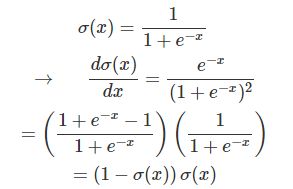
因此我们可以把后面一长串的gate”压缩“成一个gate:

我们来比较一下,之前前向计算 σ(x)σ(x) 需要一次乘法,一次exp,一次加法导数;而反向计算需要分别计算这4个gate的导数。
而压缩后前向计算是一样的,但是反向计算可以”利用“前向计算的结果
![]()
这只需要一次减法和一次乘法!当然如果不能利用前向的结果,我们如果需要重新计算 σ(x)σ(x) ,那么压缩其实没有什么用处。能压缩的原因在于σ函数导数的特殊形式。而神经网络的关键问题是在训练,训练性能就取决于这些细节。如果是我们自己来实现反向传播算法,我们就需要利用这样的特性。而如果是使用工具,那么就依赖于工具的优化水平了。
下面我们用代码来实现一下:
w = [2,-3,-3] # assume some random weights and datax = [-1, -2]# forward passdot = w[0]*x[0] + w[1]*x[1] + w[2] f = 1.0 / (1 + math.exp(-dot)) # sigmoid function# backward pass through the neuron (backpropagation)ddot = (1 - f) * f # gradient on dot variable, using the sigmoid gradient derivationdx = [w[0] * ddot, w[1] * ddot] # backprop into xdw = [x[0] * ddot, x[1] * ddot, 1.0 * ddot] # backprop into w# we're done! we have the gradients on the inputs to the circuit
上面的例子用了一个小技巧,就是所谓的staged backpropagation,说白了就是给中间的计算节点起一个名字。比如dot。为了让大家熟悉这种技巧,下面有一个例子。
Staged computation练习
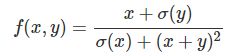
我们用代码来计算这个函数对x和y的梯度在某一点的值
前向计算
x = 3 # example valuesy = -4# forward passsigy = 1.0 / (1 + math.exp(-y)) # 分子上的sigmoid #(1)num = x + sigy # 分子 #(2)sigx = 1.0 / (1 + math.exp(-x)) # 分母上的sigmoid #(3)xpy = x + y #(4)xpysqr = xpy**2 #(5)den = sigx + xpysqr # 分母 #(6)invden = 1.0 / den #(7)f = num * invden # done! #(8)
反向计算
# backprop f = num * invdendnum = invden # gradient on numerator #(8)dinvden = num #(8)# backprop invden = 1.0 / den dden = (-1.0 / (den**2)) * dinvden #(7)# backprop den = sigx + xpysqrdsigx = (1) * dden #(6)dxpysqr = (1) * dden #(6)# backprop xpysqr = xpy**2dxpy = (2 * xpy) * dxpysqr #(5)# backprop xpy = x + ydx = (1) * dxpy #(4)dy = (1) * dxpy #(4)# backprop sigx = 1.0 / (1 + math.exp(-x))dx += ((1 - sigx) * sigx) * dsigx # Notice += !! See notes below #(3)# backprop num = x + sigydx += (1) * dnum #(2)dsigy = (1) * dnum #(2)# backprop sigy = 1.0 / (1 + math.exp(-y))dy += ((1 - sigy) * sigy) * dsigy #(1)# done! phew
需要注意的两点:1. 前向的结果都要保存下来,反向的时候要用的。2. 如果某个变量有多个出去的边,第一次是等于,第二次就是+=,因为我们要把不同出去点的梯度加起来。
下面我们来逐行分析反向计算:
(8) f = num * invden
local gradient
![]()
而上面传过来的梯度是1,所以 dnum=1∗invden。注意变量的命名规则, df/dnum就命名为dnum【省略了df,因为默认我们是求f对所有变量的偏导数】
同理: dinvden=num
(7) invden = 1.0 / den
local gradient是 (−1.0/(den∗∗2)) ,然后乘以上面来的dinvden
(6) den = sigx + xpysqr
这个函数有两个变量sigx和xpysqr,所以需要计算两个local梯度,然后乘以dden
加法的local梯度是1,所以就是(1)*dden
(5) xpysqr = xpy**2
local gradient是2*xpy,再乘以dxpysqr
(4) xpy = x + y
还是一个加法,local gradient是1,所以dx和dy都是dxpy乘1
(3) sigx = 1.0 / (1 + math.exp(-x))
这是sigmoid函数,local gradient是 (1-sigx)*sigx,再乘以dsigx。
不过需要注意的是这是dx的第二次出现,所以是+=,表示来自不同路径反向传播过来给x的梯度值
(2) num = x + sigy
还是个很简单的加法,local gradient是1。需要注意的是dx是+=,理由同上。
(1) sigy = 1.0 / (1 + math.exp(-y))
最后是sigmoid(y)和前面(3)一样的。
请仔细阅读上面反向计算的每一步代码,确保自己理解了之后再往下阅读。
梯度的矩阵运算
前面都是对一个标量的计算,在实际实现时用矩阵运算一次计算一层的所有梯度会更加高效。因为矩阵乘以向量和向量乘以向量都可以看出矩阵乘以矩阵的特殊形式,所以下面我们介绍矩阵乘法怎么求梯度。
首先我们得定义什么叫矩阵对矩阵的梯度!
我查阅了很多资料,也没找到哪里有矩阵对矩阵的梯度的定义,如果哪位读者知道,请告诉我,谢谢!唯一比较接近的是Andrew Ng的课程cs294的背景知识介绍的slides linalg的4.1节定义了gradient of Matrix,关于矩阵对矩阵的梯度我会有一个猜测性的解释,可能会有问题。
首先介绍graident of matrix
假设 f:Rm×n→R是一个函数,输入是一个m×n的实数值矩阵,输出是一个实数。那么f对A的梯度是如下定义的:

看起来定义很复杂?其实很简单,我们把f看成一个mn个自变量的函数,因此我们可以求f对这mn个自变量的偏导数,然后把它们排列成m*n的矩阵就行了。为什么要多此一举把变量拍成矩阵把他们的偏导数也排成矩阵?想想我们之前的神经网络的weights矩阵,这是很自然的定义,同时我们需要计算loss对weights矩阵的每一个变量的偏导数,写出这样的形式计算起来比较方便。
那么什么是矩阵对矩阵的梯度呢?我们先看实际神经网络的一个计算情况。对于全连接的神经网络,我们有一个矩阵乘以向量 D=WxD=Wx 【我们这里把向量x看成矩阵】。现在我们需要计算loss对某一个 WijWij 的偏导数,根据我们之前的计算图, WijWij 有多少条出边,那么就有多少个要累加的梯度乘以local梯度。
假设W是m×n的矩阵,x是n×p的矩阵,则D是m×p的矩阵
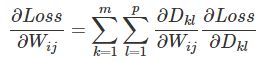
根据矩阵乘法的定义
![]()
我们可以计算:

请仔细理解上面这一步,如果 k≠i,则不论s是什么,Wks跟Wij不是同一个变量,所以导数就是0;如果k=i,∑sWisxsl=xjl,也就求和的下标s取j的时候有WijWij。
因此

上面计算了loss对一个Wij的偏导数,如果把它写成矩阵形式就是:
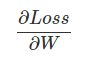
前面我们推导出了对Wij的偏导数的计算公式,下面我们把它写成矩阵乘法的形式并验证【证明】它。
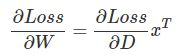
为什么可以写成这样的形式呢?

上面的推导似乎很复杂,但是我们只要能记住就行,记法也很简单——把矩阵都变成最特殊的1 1的矩阵(也就是标量,一个实数)。D=w x,这个导数很容易吧,对w求导就是local gradient x,然后乘以得到dW=dD x;同理dx=dD W。
但是等等,刚才那个公式里还有矩阵的转置,这个怎么记?这里有一个小技巧,就是矩阵乘法的条件,两个矩阵能相乘他们的大小必须匹配,比如D=Wx,W是m n,x是n p,也就是第二个矩阵的行数等于第一个的列数。
现在我们已经知道dW是dD”乘以“x了,dW的大小和W一样是m n,而dD和D一样是m p,而x是n p,那么为了得到一个m n的矩阵,唯一的办法就是 dD∗xT
同理dx是n p,dD是m p,W是m*n,唯一的乘法就是 WT∗dD
下面是用python代码来演示,numpy的dot就是矩阵乘法,可以用numpy.dot(A,B),也可以直接调用ndarray的dot函数——A.dot(B):
# forward passW = np.random.randn(5, 10)X = np.random.randn(10, 3) D = W.dot(X)# now suppose we had the gradient on D from above in the circuitdD = np.random.randn(*D.shape) # same shape as DdW = dD.dot(X.T) #.T gives the transpose of the matrixdX = W.T.dot(dD)