基本需求
用spark sql求出每个院系每个班每个专业前3名
样本数据
数据格式:id,studentId,language,math,english,classId,departmentId,即id,学号,语文,数学,外语,班级,院系
1,111,68,69,90,1班,经济系
2,112,73,80,96,1班,经济系
3,113,90,74,75,1班,经济系
4,114,89,94,93,1班,经济系
5,115,99,93,89,1班,经济系
6,121,96,74,79,2班,经济系
7,122,89,86,85,2班,经济系
8,123,70,78,61,2班,经济系
9,124,76,70,76,2班,经济系
10,211,89,93,60,1班,外语系
11,212,76,83,75,1班,外语系
12,213,71,94,90,1班,外语系
13,214,94,94,66,1班,外语系
14,215,84,82,73,1班,外语系
15,216,85,74,93,1班,外语系
16,221,77,99,61,2班,外语系
17,222,80,78,96,2班,外语系
18,223,79,74,96,2班,外语系
19,224,75,80,78,2班,外语系
20,225,82,85,63,2班,外语系
用Spark sql实现
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SparkSession
object TestSqlGroupByOrder {
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sparkSession=SparkSession.builder().appName("SparkSqlGroup").master("local[6]").getOrCreate()
import sparkSession.implicits._
val scoreInfo = sparkSession.read.textFile("/Users/wangpei/Desktop/scores2.txt").map(_.split(",")).map(item=>(item(1),item(2).toInt,item(3).toInt,item(4).toInt,item(5),item(6)))
.toDF("studentId","language","math","english","classId","departmentId")
scoreInfo.createOrReplaceTempView("scoresTable")
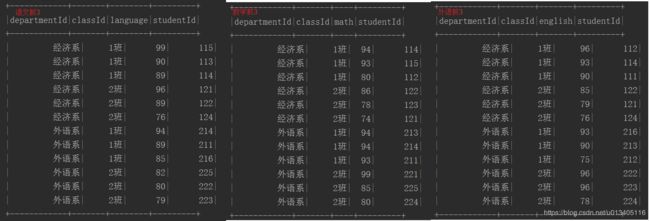
println("############# 语文前3 ##############")
sparkSession.sql("SELECT departmentId,classId,language,studentId FROM (SELECT *, row_number() OVER (PARTITION BY departmentId,classId ORDER BY language DESC) rank FROM scoresTable ) tmp WHERE rank <= 3").show()
println("############# 数学前3 ##############")
sparkSession.sql("SELECT departmentId,classId,math,studentId FROM (SELECT *, row_number() OVER (PARTITION BY departmentId,classId ORDER BY math DESC) rank FROM scoresTable ) tmp WHERE rank <= 3").show()
println("############# 外语前3 ##############")
sparkSession.sql("SELECT departmentId,classId,english,studentId FROM (SELECT *, row_number() OVER (PARTITION BY departmentId,classId ORDER BY english DESC) rank FROM scoresTable ) tmp WHERE rank <= 3").show()
}
}