通过prometheus实现k8s hpa自定义指标 (一)
在前面的k8s controller-manager之hpa源码分析一文中曾经分析了k8s的hpa源码,讲解了hpa的流程,但只是基于传统的hepaster做分析,并没有分析自定义metric指标,但在实际的应用使用中,基于cpu/内存的自动伸缩指标并不能完全的满足业务需求,因此需要用到自定义metric指标进行自动伸缩,这里使用prometheus作为第三方metric收集器,并通过k8s-prometheus-adapter为HPA控制器提供自定义指标的client适配。
本文作为《通过prometheus实现k8s hpa自定义指标》的第一篇,主要介绍HPA metric组件相关安装和自定义扩缩容演示,该部分主要翻译自k8s-prom-hpa,主要是对自定义指标的HPA做个整体的认知。在本博文的后继系列,将分析k8s-prometheus-adapter的相关源码及原理。
自动扩展是一种根据资源使用情况自动扩缩容工作负载的方法。Kubernestes中的自动伸缩有两个维度:处理节点伸缩操作的集群自动缩放器和自动扩缩deployment或replicaset pod数量的Horizontal Pod Autoscaler。集群自动缩放和Horizontal Pod Autoscaler可用于动态调整计算能力以及满足SLA所需的并行度。虽然集群自动缩放器高度依赖于托管集群的云提供商的底层能力,但是HPA可以独立运行于Iaas/Pass提供商。
Horizontal Pod Autoscaler功能最初是在Kubernetes 1.1中引入并不断发展。HPA的第一版是根据观察到CPU利用率以及随后的内存利用率来伸缩pod。在kubernetes 1.6中,引入了一种新型的API,自定义度量API,这样HPA就能够实现基于任意度量的自动伸缩功能。Kubernestes 1.7引入了聚合层,允许第三方应用程序通过注册自己为API插件来扩展Kubernestes API。自定义度量API和聚合层使得像Promethous这样的监控系统向HPA控制器公开特定于应用程序的度量成为可能。
Horizontal Pod Autoscaler会定期查询如CPU/memory的Resource Metrics API和应用特定metrics的Custom Metrics API。
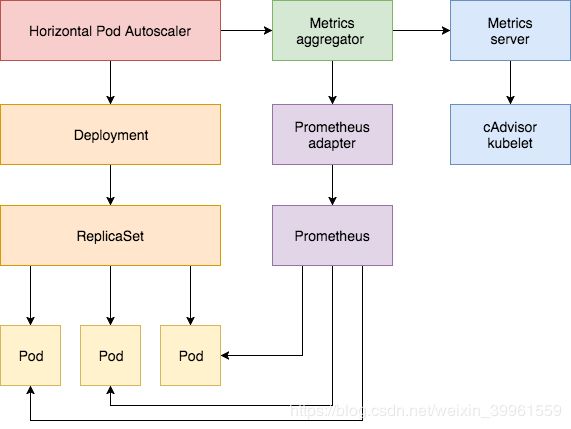
接下来是基于k8s 1.9或更高版本配置HPA V2的教程。首先按照提供核心指标的Metrics Server插件,然后使用podinfo demo应用演示基于cpu和memory 使用情况的pod自动缩放。在第二部分中,将部署prometheus和custom API server,向聚合器层注册自定义API服务,然后使用演示程序提供的自定义metrics配置HPA。
开始之前,首先要确保已安装Go 1.8以上版本,并在gopath中clone了 k8s-prom-hpa项目。
cd $GOPATH
git clone https://github.com/stefanprodan/k8s-prom-hpa
设置Metrics Server
kubernetes Metrics Server是一个集群范围的资源使用数据的聚合器,是Hepster的继承者。metrics server通过kubernetes.summary_api收集节点和pod的CPU和memory使用率。summary API是一个内存搞笑的API,用于将数据从kubelet/cAdvisor传输到metrics server。

如果在HPA的第一个版本中,需要Hepster来提供CPU和内存metrics,在HPA v2和k8s 1.8中,需要打开horizontal-pod-autoscaler-use-rest-clients选项才能使用metrics server,在k8s 1.9中,rest client是默认打开的。
在kube-system命名空间中部署Metrics Server
kubectl create -f ./metrics-server
大约一分钟后,metric-server开始报告node和pod的cpu和memory使用情况。
查看nodes metrics:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes" | jq .
查看pods metrics:
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/pods" | jq .
基于cpu和内存使用的自动扩缩容
首先在default命名空间下部署podinfo应用完成HPA测试:
kubectl create -f ./podinfo/podinfo-svc.yaml,./podinfo/podinfo-dep.yaml
通过service的NodePort端口访问podinfo,http://
接下来定义一个hpa yaml,cpu的平均使用率超过80%,内存平均使用超过200Mi时自动扩缩容Pod个数,pod数范围为2到10。
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: podinfo
spec:
scaleTargetRef:
apiVersion: extensions/v1beta1
kind: Deployment
name: podinfo
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 80
- type: Resource
resource:
name: memory
targetAverageValue: 200Mi
生成hpa:
kubectl create -f ./podinfo/podinfo-hpa.yaml
一段时间后,HPA控制器能够通过metrics server获取CPU和内存的使用:
kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
podinfo Deployment/podinfo 2826240 / 200Mi, 15% / 80% 2 10 2 5m
为了增加负载,提高cpu使用率,使用raky11/hey做负载测试:
#install hey
go get -u github.com/rakyll/hey
#do 10K requests
hey -n 10000 -q 10 -c 5 http://<K8S_PUBLIC_IP>:31198/
接着关注hpa事件:
$ kubectl describe hpa
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 7m horizontal-pod-autoscaler New size: 4; reason: cpu resource utilization (percentage of request) above target
Normal SuccessfulRescale 3m horizontal-pod-autoscaler New size: 8; reason: cpu resource utilization (percentage of request) above target
暂时删除podinfo,后面我们会再次部署:
kubectl delete -f ./podinfo/podinfo-hpa.yaml,./podinfo/podinfo-dep.yaml,./podinfo/podinfo-svc.yaml
设置Custom Metrics Server
为了基于自定义指标进行扩展,需要安装两个组件。一个组件从应用程序中收集metrics,并将他们存储在promethues的时序数据库中。另一个组件扩展k8s自定义metics API,即k8s-prometheus-adapter。

在monitoring命名空间中部署prometheus和适配器。
kubectl create -f ./namespaces.yaml
kubectl create -f ./prometheus
生成prometheus适配器所需的TLS证书:
make certs
部署Prometheus custom metrics API adapter:
kubectl create -f ./custom-metrics-api
列出prometheus提供的自定义指标:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1" | jq .
获取monitoring命名孔径下所有Pod的FS使用率:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/monitoring/pods/*/fs_usage_bytes" | jq .
基于自定义指标(custom metrics)的自动缩放
在default命名空间中创建podinfo,service以NodePort方式:
kubectl create -f ./podinfo/podinfo-svc.yaml,./podinfo/podinfo-dep.yaml
podinfo应用暴露了一个名为http_requests_total的自定义metric。Prometheas适配器删除_total后缀,并将度量标记为计数器度量(counter metric)。
从自定义metrics API中获取每秒请求总数:
kubectl get --raw "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/*/http_requests" | jq .
{
"kind": "MetricValueList",
"apiVersion": "custom.metrics.k8s.io/v1beta1",
"metadata": {
"selfLink": "/apis/custom.metrics.k8s.io/v1beta1/namespaces/default/pods/%2A/http_requests"
},
"items": [
{
"describedObject": {
"kind": "Pod",
"namespace": "default",
"name": "podinfo-6b86c8ccc9-kv5g9",
"apiVersion": "/__internal"
},
"metricName": "http_requests",
"timestamp": "2018-01-10T16:49:07Z",
"value": "901m"
},
{
"describedObject": {
"kind": "Pod",
"namespace": "default",
"name": "podinfo-6b86c8ccc9-nm7bl",
"apiVersion": "/__internal"
},
"metricName": "http_requests",
"timestamp": "2018-01-10T16:49:07Z",
"value": "898m"
}
]
}
m代表milli-units,所以901m代表901 milli-requests。
创建一个HPA,如果请求数量超过每秒10个,将扩容podinfo应用:
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: podinfo
spec:
scaleTargetRef:
apiVersion: extensions/v1beta1
kind: Deployment
name: podinfo
minReplicas: 2
maxReplicas: 10
metrics:
- type: Pods
pods:
metricName: http_requests
targetAverageValue: 10
在default命名空间下生成podinfo HPA:
kubectl create -f ./podinfo/podinfo-hpa-custom.yaml
一段时间后,HPA从metrics API获取http_requests值:
kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
podinfo Deployment/podinfo 899m / 10 2 10 2 1m
以每秒25次的平了请求podinfo应用:
#install hey
go get -u github.com/rakyll/hey
#do 10K requests rate limited at 25 QPS
hey -n 10000 -q 5 -c 5 http://<K8S-IP>:31198/healthz
几分钟后,HPA开始扩容应用:
kubectl describe hpa
Name: podinfo
Namespace: default
Reference: Deployment/podinfo
Metrics: ( current / target )
"http_requests" on pods: 9059m / 10
Min replicas: 2
Max replicas: 10
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 2m horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests above target
以当前的每秒请求速度,应用用于不会达到10个pod的最大值,3个pod的RPS可以将请求保持在每秒10个一下。
负载测试结束后,HPA将应用缩容到原始副本:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 5m horizontal-pod-autoscaler New size: 3; reason: pods metric http_requests above target
Normal SuccessfulRescale 21s horizontal-pod-autoscaler New size: 2; reason: All metrics below target
你可以发现自动伸缩器不会立即响应瞬时请求高峰。默认情况下,metrics每30秒发生一次,只有在过去3-5分钟内没有重新伸缩的情况下,才进行伸缩。通过这种方式,HPA可以防止冲突的快速执行,并为集群自动伸缩器提供启动时间。
总结
并非所有系统都可以仅依靠CPU/内存使用度量来满足服务级别协议,大多数Web和移动后端都需要基于每秒的请求自动缩放来处理任何流量突发。对于ETL应用程序,自动扩展可能会由超过某个阈值的作业队列长度触发,依此类推。通过使用Prometheaus检测应用程序并展示自动扩展的正确指标,可以微调应用程序以更好地处理突发事件并确保高可用性。