TensorFlow 实现基于LSTM的语言模型
一、LSTM的相关概念
博客上有很多讲解的很好的博主,我看的是这个博主的关于LSTM的介绍,感觉很全面,如果对LSTM原理不太明白的,可以点击这个链接。LSTM相关概念,这里就不多做介绍了哈!
二、GRU介绍
这里为什么要介绍下GRU呢!因为在RNN的各种变种中,除了LSTM,另一个非常流行的网络结构就是GRU,它相比于LSTM,结构更简单,比LSTM减少了一个Gate,所以计算效率更高。
除此之外,它也改变了RNN的隐藏层,使其更好地捕捉深层连接,改善了梯度消失问题。
三、LSTM与GRU
LSTM和GRU的区别可以看一下公式,这个是我看吴恩达《深度学习》网课时做的笔记。有兴趣的可以去网易云课堂看下吴恩达的网课。
LSTM:

GRU:
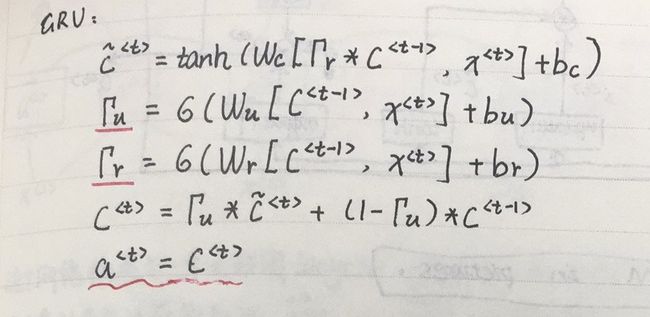
四、实现(本节代码来自tensorflow开源实现)
首先下载PTB数据集并解压放到工作路径下。wget http://www.fit.vutbr.cz/~imikolov/rnnlm/simple-examples.tgz
tar xvf simple-examples.tgz然后下载tensorflow models库,进入目录models/tutorials/rnn/ptb。然后载入常用的库,和tensorflow models中的PTB reader,通过它读取数据。
git clone https://github.com/tensorflow/models.git
cd models/tutorials/rnn/ptb载入常用的库,这里如果在执行程序的时候,报“没有reader库“的错,那么请参考这里链接,和这里。(之前我程序有这个错误就参考的这两个大大的)。
import time
import numpy as np
import tensorflow as tf
import reader接着定义语言模型,用来处理输入数据的class。
class PTBInput(object):
def __init__(self, config, data, name=None):
self.batch_size = batch_size = config.batch_size
self.num_steps = num_steps = config.num_steps #num_steps是LSTM的展开步数
self.epoch_size = ((len(data) // batch_size) - 1) // num_steps #epoch_size即为每个epoch内需要多少轮训练的迭代。
#用reader.ptb_producer获取特征数据input_data,以及label数据targets。
self.input_data, self.targets = reader.ptb_producer(
data, batch_size, num_steps, name=name)然后定义语言模型中的class,PTBModel。
class PTBModel(object):
def __init__(self, is_training, config, input_): #is_trainin是训练标记 config是配置参数 input_是PTBInput的实例
self._input = input_
batch_size = input_.batch_size
num_steps = input_.num_steps
size = config.hidden_size #hidden_size是LSTM的节点数
vocab_size = config.vocab_size #vocab_size是词汇表大小使用tf.contrib.rnn.BasicLSTMCell设置默认的LSTM单元,
def lstm_cell( ):
return tf.contrib.rnn.BasicLSTMCell(
size, forget_bias=0.0, state_is_tuple=True)
attn_cell = lstm_cell
if is_training and config.keep_prob < 1:
def attn_cell():
return tf.contrib.rnn.DropoutWrapper(
lstm_cell(), output_keep_prob=config.keep_prob)
cell = tf.contrib.rnn.MultiRNNCell(
[attn_cell() for _ in range(config.num_layers)],
state_is_tuple=True)
self._initial_state = cell.zero_state(batch_size, tf.float32)创建网络的词嵌入embedding部分。embedding是将one-hot的编码格式的单词转化为向量表达形式
with tf.device("/cpu:0"):
embedding = tf.get_variable(
"embedding", [vocab_size, size], dtype=tf.float32)
inputs = tf.nn.embedding_lookup(embedding, input_.input_data)
if is_training and config.keep_prob < 1:
inputs = tf.nn.dropout(inputs, config.keep_prob)定义输出outputs。
outputs = []
state = self._initial_state
with tf.variable_scope("RNN"):
for time_step in range(num_steps):
if time_step > 0: tf.get_variable_scope().reuse_variables()
(cell_output, state) = cell(inputs[:, time_step, :], state) #inputs有三个维度,第一个代表batch中的第几个样本,2是样本中第几个单词,3是单词的向量表达的维度
outputs.append(cell_output)将output的内容用tf.concat串接到一起,使用tf.reshape将其转换为一个特别长的一维向量。
output = tf.reshape(tf.concat(outputs, 1), [-1, size])
softmax_w = tf.get_variable(
"softmax_w", [size, vocab_size], dtype=tf.float32)
softmax_b = tf.get_variable("softmax_b", [vocab_size], dtype=tf.float32)
logits = tf.matmul(output, softmax_w) + softmax_b #网络的最后输出
loss = tf.contrib.legacy_seq2seq.sequence_loss_by_example(
[logits],
[tf.reshape(input_.targets, [-1])],
[tf.ones([batch_size * num_steps], dtype=tf.float32)])
self._cost = cost = tf.reduce_sum(loss) / batch_size
self._final_state = state
if not is_training:
returnself._lr = tf.Variable(0.0, trainable=False) #_lr是学习速率,这里是不可训练
tvars = tf.trainable_variables() #tvars是全部可训练的参数
grads, _ = tf.clip_by_global_norm(tf.gradients(cost, tvars),
config.max_grad_norm)
optimizer = tf.train.GradientDescentOptimizer(self._lr)
self._train_op = optimizer.apply_gradients(zip(grads, tvars),
global_step=tf.contrib.framework.get_or_create_global_step())#定义一个用来控制学习速率的
self._new_lr = tf.placeholder(
tf.float32, shape=[], name="new_learning_rate")
self._lr_update = tf.assign(self._lr, self._new_lr) #assign_lr用来在外部控制模型的学习速率
def assign_lr(self, session, lr_value):
session.run(self._lr_update, feed_dict={self._new_lr: lr_value})到这里,模型定义的部分就完成了。在定义PTBModel class的一些property(它可以将返回变量设为只读,防止修改变量引发的问题)
@property
def input(self):
return self._input
@property
def initial_state(self):
return self._initial_state
@property
def cost(self):
return self._cost
@property
def final_state(self):
return self._final_state
@property
def lr(self):
return self._lr
@property
def train_op(self):
return self._train_op定义集中不同大小的模型的参数,先是小模型。
class SmallConfig(object):
init_scale = 0.1 #是网络中权重值的初始scale
learning_rate = 1.0 #学习速率的初始值
max_grad_norm = 5 #梯度的最大范数
num_layers = 2 #LSTM可以堆叠的层数
num_steps = 20 #LSTM梯度反向传播的展开步数
hidden_size = 200 #LSTM可以堆叠的层数
max_epoch = 4 #初始学习速率可训练的epoch数,在此之后需要调整学习速率
max_max_epoch = 13 #总共可训练的epoch数
keep_prob = 1.0 #dropout层的保留节点的比例
lr_decay = 0.5 #学习速率的衰减速度
batch_size = 20 #每个batch中样本的数量
vocab_size = 10000中模型
class MediumConfig(object):
init_scale = 0.05
learning_rate = 1.0
max_grad_norm = 5
num_layers = 2
num_steps = 35
hidden_size = 650
max_epoch = 6
max_max_epoch = 39
keep_prob = 0.5
lr_decay = 0.8
batch_size = 20
vocab_size = 10000大
class LargeConfig(object):
init_scale = 0.04
learning_rate = 1.0
max_grad_norm = 10
num_layers = 2
num_steps = 35
hidden_size = 1500
max_epoch = 14
max_max_epoch = 55
keep_prob = 0.35
lr_decay = 1 / 1.15
batch_size = 20
vocab_size = 10000#这里只是为了测试使用,参数都尽量的使用最小值,为了测试可以完整运行模型
class TestConfig(object):
init_scale = 0.1
learning_rate = 1.0
max_grad_norm = 1
num_layers = 1
num_steps = 2
hidden_size = 2
max_epoch = 1
max_max_epoch = 1
keep_prob = 1.0
lr_decay = 0.5
batch_size = 20
vocab_size = 10000接着定义训练一个epoch数据的函数run_epoch。记录当前时间,初始化损失costs和迭代数iters,并执行model.initial_state来初始化状态并获得初始状态。
接着创建输出结果的字典表fetches,其中包括cost和final_state,如果有评测操作eval_op,也一并加入到fetches。
进入循环,次数为epoch_size。每次循环中,生成训练用的feed_dict。将全部LSTM单元的state加入feed_dict中,然后传入feed_dict并执行fetches对网络进行一次训练,拿到cost和state。我们每完成约10%的epoch,就进行一次结果的展示,一次展示当前的epoch的进度。最后返回perplexity作为函数结果。和训练速度最后返回perplexity作为函数结果。
PS:perplexity:平均cost的自然常熟指数,是语言模型中用来比较模型性能的重要指标,越低代表模型输出的概率分布在预测样本上越好。
def run_epoch(session, model, eval_op=None, verbose=False):
start_time = time.time()
costs = 0.0
iters = 0
state = session.run(model.initial_state) #model.initial_state来初始化状态并获得初始状态
#创建输出结果字典表
fetches = {
"cost": model.cost,
"final_state": model.final_state,
}
if eval_op is not None:
fetches["eval_op"] = eval_op
#进入训练循环中
for step in range(model.input.epoch_size):
feed_dict = {}
for i, (c, h) in enumerate(model.initial_state):
feed_dict[c] = state[i].c
feed_dict[h] = state[i].h
vals = session.run(fetches, feed_dict)
cost = vals["cost"]
state = vals["final_state"]
cost += cost
iters += model.input.num_steps
if verbose and step % (model.input.epoch_size // 10) == 10:
print("%.3f perplexity: %.3f speed: %.0f wps" %
(step * 1.0 / model.input.epoch_size, np.exp(costs / iters),
iters * model.input.batch_size / (time.time() - start_time)))
return np.exp(costs / iters)使用reader.ptb_raw_data直接读取解压后的数据,得到训练数据,验证数据和测试数据。
raw_data = reader.ptb_raw_data('simple-examples/data/')
train_data, valid_data, test_data, _= raw_data
config = SmallConfig()
eval_config = SmallConfig()
eval_config.batch_size = 1
eval_config.num_steps = 1
创建默认的Graph,使用tf.random_uniform_initializer设置参数的初始化器。
with tf.Graph().as_default():
initializer = tf.random_uniform_initializer(-config.init_scale,
config.init_scale)
with tf.name_scope("Train"):
train_input = PTBInput(config=config, data=train_data, name="TrainInput")
with tf.variable_scope("Model", reuse=None, initializer=initializer):
m = PTBModel(is_training=True, config=config, input_=train_input)
with tf.name_scope("Valid"):
valid_input = PTBInput(config=config, data=valid_data, name="ValidInput")
with tf.variable_scope("Model", reuse=True, initializer=initializer):
mvalid = PTBModel(is_training=False, config=config, input_=valid_input)
with tf.name_scope("Test"):
test_input = PTBInput(config=eval_config, data=test_data,
name="TestInput")
with tf.variable_scope("Model", reuse=True, initializer=initializer):
mtest = PTBModel(is_training=False, config=eval_config,
input_=test_input)使用tf.train.Supervisor()创建训练的管理器sv,并使用sv.managed_session创建默认Session,再执行训练多个epoch数据的循环。
sv = tf.train.Supervisor()
with sv.managed_session() as session:
for i in range(config.max_max_epoch):
lr_decay = config.lr_decay ** max(i + 1 - config.max_epoch, 0.0)
m.assign_lr(session, config.learning_rate * lr_decay)
print("Epoch: %d Learning rate: %.3f" % (i + 1, session.run(m.lr)))
train_perplexity = run_epoch(session, m, eval_op=m.train_op,
verbose=True)
print("Epoch: %d Train perplexity: %.3f" % (i + 1, train_perplexity))
test_perplexity = run_epoch(session, mtest)
print("Test Perplexity: %.3f" % test_perplexity)在SmallConfig小型模型的最后结果,我的电脑配置不高,训练速度大概2000+单词每秒,
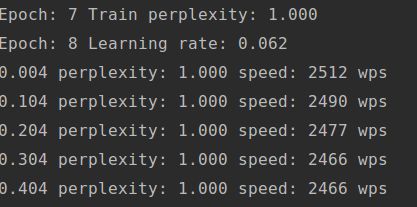
看起来我们预测的结果还是很好滴哈!