import numpy as np from sklearn.datasets import make_blobs from sklearn.cluster import KMeans from sklearn.metrics import pairwise_distances import matplotlib.pyplot as plt import matplotlib as mpl from cycler import cycler from .tools import discrete_scatter from .plot_2d_separator import plot_2d_classification from .plot_helpers import cm3 def plot_kmeans_algorithm(): X, y = make_blobs(random_state=1) # we don't want cyan in there with mpl.rc_context(rc={'axes.prop_cycle': cycler('color', ['#0000aa', '#ff2020', '#50ff50'])}): fig, axes = plt.subplots(3, 3, figsize=(10, 8), subplot_kw={'xticks': (), 'yticks': ()}) axes = axes.ravel() axes[0].set_title("Input data") discrete_scatter(X[:, 0], X[:, 1], ax=axes[0], markers=['o'], c='w') axes[1].set_title("Initialization") init = X[:3, :] discrete_scatter(X[:, 0], X[:, 1], ax=axes[1], markers=['o'], c='w') discrete_scatter(init[:, 0], init[:, 1], [0, 1, 2], ax=axes[1], markers=['^'], markeredgewidth=2) axes[2].set_title("Assign Points (1)") km = KMeans(n_clusters=3, init=init, max_iter=1, n_init=1).fit(X) centers = km.cluster_centers_ # need to compute labels by hand. scikit-learn does two e-steps for max_iter=1 # (and it's totally my fault) labels = np.argmin(pairwise_distances(init, X), axis=0) discrete_scatter(X[:, 0], X[:, 1], labels, markers=['o'], ax=axes[2]) discrete_scatter(init[:, 0], init[:, 1], [0, 1, 2], ax=axes[2], markers=['^'], markeredgewidth=2) axes[3].set_title("Recompute Centers (1)") discrete_scatter(X[:, 0], X[:, 1], labels, markers=['o'], ax=axes[3]) discrete_scatter(centers[:, 0], centers[:, 1], [0, 1, 2], ax=axes[3], markers=['^'], markeredgewidth=2) axes[4].set_title("Reassign Points (2)") km = KMeans(n_clusters=3, init=init, max_iter=1, n_init=1).fit(X) labels = km.labels_ discrete_scatter(X[:, 0], X[:, 1], labels, markers=['o'], ax=axes[4]) discrete_scatter(centers[:, 0], centers[:, 1], [0, 1, 2], ax=axes[4], markers=['^'], markeredgewidth=2) km = KMeans(n_clusters=3, init=init, max_iter=2, n_init=1).fit(X) axes[5].set_title("Recompute Centers (2)") centers = km.cluster_centers_ discrete_scatter(X[:, 0], X[:, 1], labels, markers=['o'], ax=axes[5]) discrete_scatter(centers[:, 0], centers[:, 1], [0, 1, 2], ax=axes[5], markers=['^'], markeredgewidth=2) axes[6].set_title("Reassign Points (3)") labels = km.labels_ discrete_scatter(X[:, 0], X[:, 1], labels, markers=['o'], ax=axes[6]) markers = discrete_scatter(centers[:, 0], centers[:, 1], [0, 1, 2], ax=axes[6], markers=['^'], markeredgewidth=2) axes[7].set_title("Recompute Centers (3)") km = KMeans(n_clusters=3, init=init, max_iter=3, n_init=1).fit(X) centers = km.cluster_centers_ discrete_scatter(X[:, 0], X[:, 1], labels, markers=['o'], ax=axes[7]) discrete_scatter(centers[:, 0], centers[:, 1], [0, 1, 2], ax=axes[7], markers=['^'], markeredgewidth=2) axes[8].set_axis_off() axes[8].legend(markers, ["Cluster 0", "Cluster 1", "Cluster 2"], loc='best') def plot_kmeans_boundaries(): X, y = make_blobs(random_state=1) init = X[:3, :] km = KMeans(n_clusters=3, init=init, max_iter=2, n_init=1).fit(X) discrete_scatter(X[:, 0], X[:, 1], km.labels_, markers=['o']) discrete_scatter(km.cluster_centers_[:, 0], km.cluster_centers_[:, 1], [0, 1, 2], markers=['^'], markeredgewidth=2) plot_2d_classification(km, X, cm=cm3, alpha=.4) def plot_kmeans_faces(km, pca, X_pca, X_people, y_people, target_names): n_clusters = 10 image_shape = (87, 65) fig, axes = plt.subplots(n_clusters, 11, subplot_kw={'xticks': (), 'yticks': ()}, figsize=(10, 15), gridspec_kw={"hspace": .3}) for cluster in range(n_clusters): center = km.cluster_centers_[cluster] mask = km.labels_ == cluster dists = np.sum((X_pca - center) ** 2, axis=1) dists[~mask] = np.inf inds = np.argsort(dists)[:5] dists[~mask] = -np.inf inds = np.r_[inds, np.argsort(dists)[-5:]] axes[cluster, 0].imshow(pca.inverse_transform(center).reshape(image_shape), vmin=0, vmax=1) for image, label, asdf, ax in zip(X_people[inds], y_people[inds], km.labels_[inds], axes[cluster, 1:]): ax.imshow(image.reshape(image_shape), vmin=0, vmax=1) ax.set_title("%s" % (target_names[label].split()[-1]), fontdict={'fontsize': 9}) # add some boxes to illustrate which are similar and which dissimilar rec = plt.Rectangle([-5, -30], 73, 1295, fill=False, lw=2) rec = axes[0, 0].add_patch(rec) rec.set_clip_on(False) axes[0, 0].text(0, -40, "Center") rec = plt.Rectangle([-5, -30], 385, 1295, fill=False, lw=2) rec = axes[0, 1].add_patch(rec) rec.set_clip_on(False) axes[0, 1].text(0, -40, "Close to center") rec = plt.Rectangle([-5, -30], 385, 1295, fill=False, lw=2) rec = axes[0, 6].add_patch(rec) rec.set_clip_on(False) axes[0, 6].text(0, -40, "Far from center")
过程解析: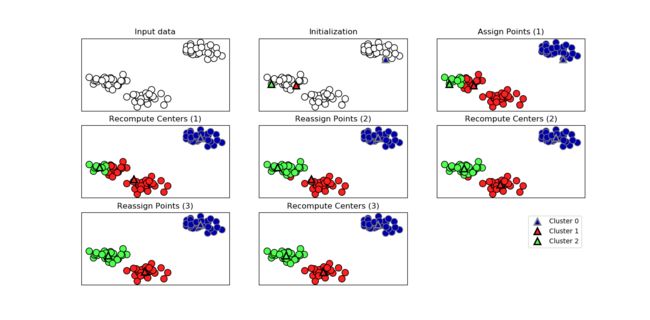
在大数据集的情况下还可以使用scikit-learn 提供了MiniBatchKMeans算法,大致思想就是对数据进行抽样,每次不使用所有的数据来计算,这就会导致准确率的损失。
MiniBatchKmeans 继承自Kmeans 因为MiniBathcKmeans 本质上还利用了Kmeans 的思想.从构造方法和文档大致能看到这些参数的含义,了解了这些参数会对使用的时候有很大的帮助。batch_size 是每次选取的用于计算的数据的样本量,默认为100.Mini Batch K-Means算法是K-Means算法的变种,采用小批量的数据子集减小计算时间,同时仍试图优化目标函数,这里所谓的小批量是指每次训练算法时所随机抽取的数据子集,采用这些随机产生的子集进行训练算法,大大减小了计算时间,与其他算法相比,减少了k-均值的收敛时间,小批量k-均值产生的结果,一般只略差于标准算法。
代码只需要修改一行:
clf = MiniBatchKMeans(n_clusters = 3)