Spark2.3.2源码解析: 4.2.Yarn cluster 模式 SparkSubmit源码分析(二)ApplicationMaster
准备工作:
| 启动脚本 | --name spark-test --class WordCount --master yarn --deploy-mode cluster /A/spark-test/spark-test.jar /tmp/zl/data/data.txt |
| 执行jar包 | spark-test.jar |
| 代码 | 核心:
val conf = new SparkConf() val textFile = sc.textFile(args(0)) println(" result : " + counts.count())
|
上篇文章:https://blog.csdn.net/zhanglong_4444/article/details/84875818
启动ApplicationMaster的命令为:
{{JAVA_HOME}}/bin/java
-server
-Xmx1024m
-Djava.io.tmpdir={{PWD}}/tmp
-Dspark.yarn.app.container.log.dir=
org.apache.spark.deploy.yarn.ApplicationMaster
--class 'WordCount'
--jar file:/A/spark-test/spark-test.jar
--arg '/tmp/zl/data/data.txt' --properties-file {{PWD}}/__spark_conf__/__spark_conf__.properties 1>
所以,接下来,我们从这里开始分析:
org.apache.spark.deploy.yarn.ApplicationMaster
传入参数:--class WordCount --jar file:/A/spark-test/spark-test.jar --arg '/tmp/zl/data/data.txt' --properties-file /A/application_1544436077214_7170/__spark_conf__/__spark_conf__.properties
直接看main方法:
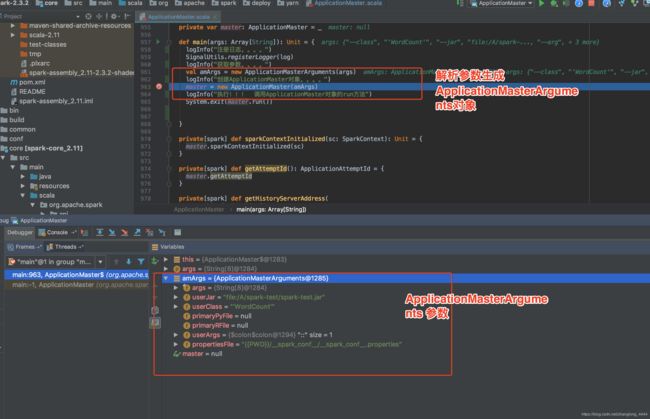
其实就是解析参数,生成参数对象。
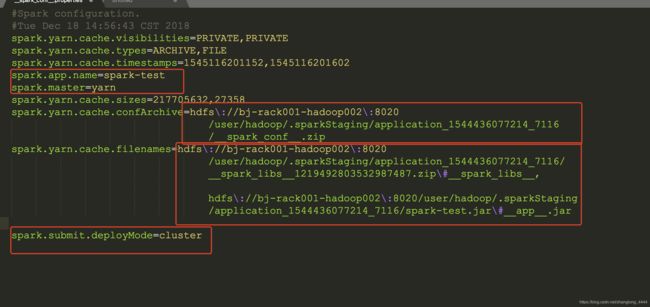
propertiesFile 自行改成配置文件的路径,这个文件怎么生成的在上篇文章中有讲解,本地要有一份,hdfs上面也要有一份数据啊。因为这个配置文件里面写着需要jar&配置文件的信息
/A/application_1544436077214_7170/__spark_conf__/__spark_conf__.properties
直接看ApplicationMaster对象
master = new ApplicationMaster(amArgs)
不用说,先加载环境变量 SparkConf,就是本地文件的那个。
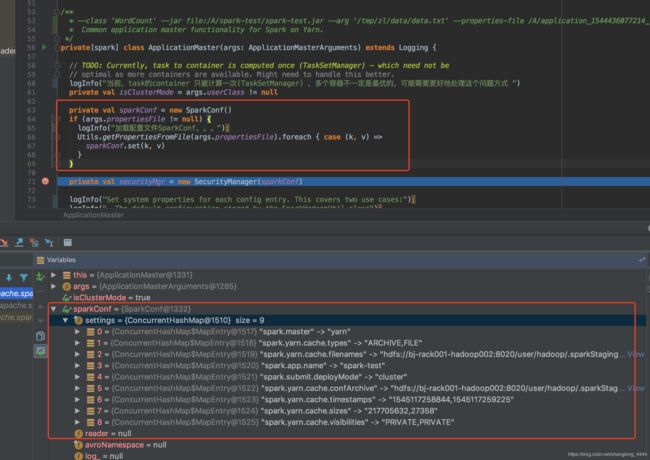
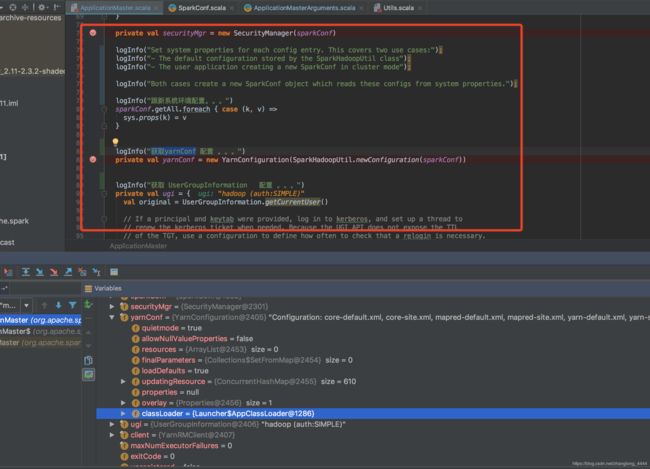
加载类:
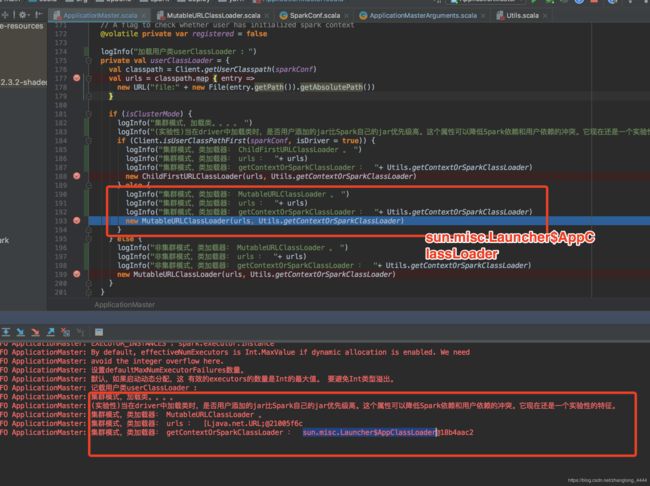
18/12/19 09:41:09 INFO ApplicationMaster: 集群模式,类加载器: MutableURLClassLoader 。
18/12/19 09:41:11 INFO ApplicationMaster: 集群模式,类加载器: urls : [Ljava.net.URL;@21005f6c
18/12/19 09:41:23 INFO ApplicationMaster: 集群模式,类加载器: getContextOrSparkClassLoader : sun.misc.Launcher$AppClassLoader@18b4aac2
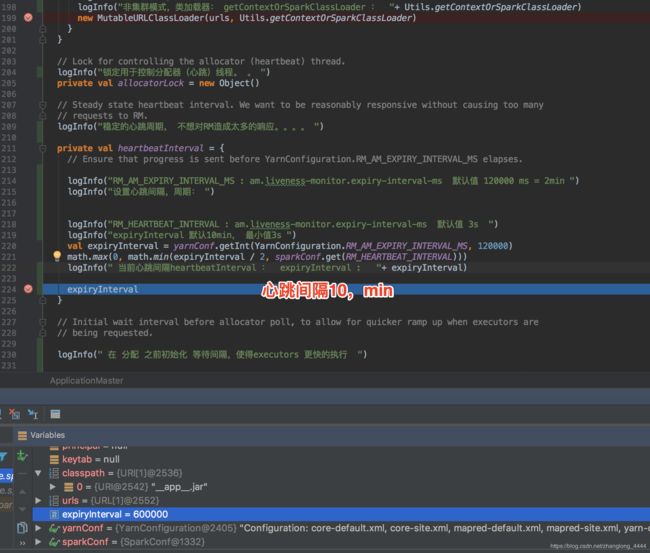
设置心跳间隔:
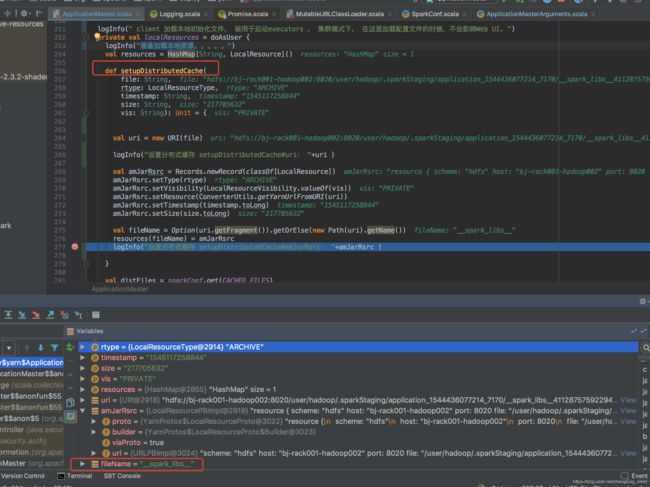
加载资源文件(三个个):
/user/hadoop/.sparkStaging/application_1544436077214_7170/spark-test.jar
/user/hadoop/.sparkStaging/application_1544436077214_7170/__spark_libs__4112875759229452839.zip/user/hadoop/.sparkStaging/application_1544436077214_7170/__spark_conf__.zip
为executors分配配置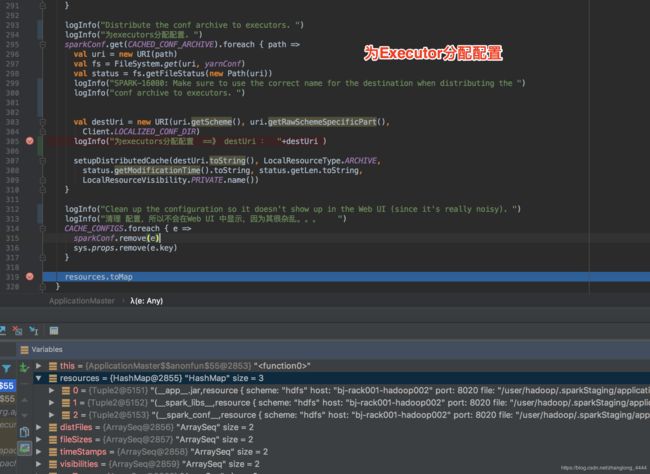
构建 ApplicationMaster 完成 ,核心是执行run方法
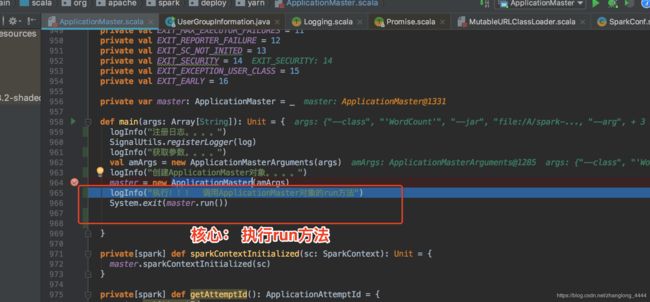
实际执行:runImpl() 方法
接下来就是加载环境变量&用户权限之类的,就不做细说了
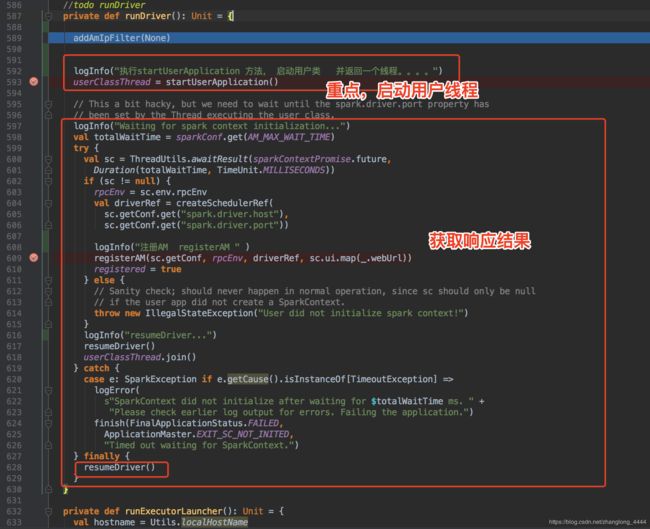
主要执行 runDriver 方法(cluster模式,非集群模式,调用的是runExecutorLauncher方法):
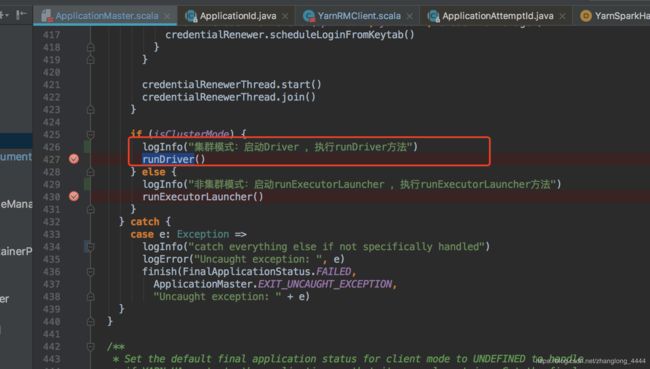
重点是
执行startUserApplication 方法, 启动用户类 并返回一个线程
userClassThread = startUserApplication()
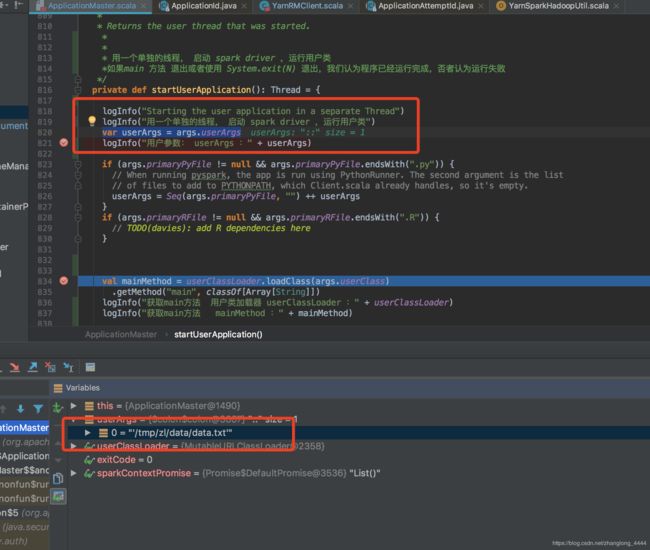
直接看 startUserApplication 方法
用一个单独的线程, 启动 spark driver ,运行用户类如果main 方法 退出或者使用 System.exit(N) 退出,我们认为程序已经运行完成,否者认为运行失败
startUserApplication首先,加载参数:
var userArgs = args.userArgs
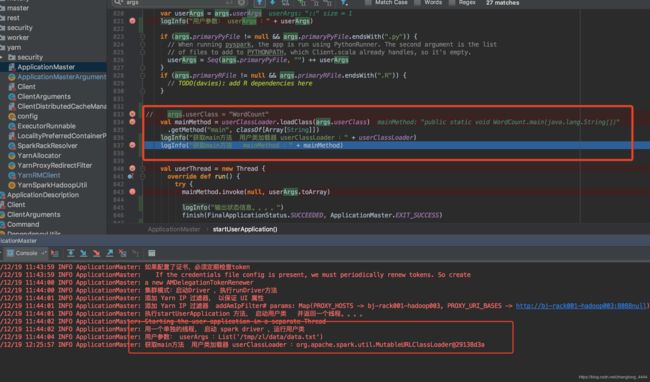
加载类:WordCount
用户参数: userArgs :List('/tmp/zl/data/data.txt')
用户类加载器 userClassLoader :org.apache.spark.util.MutableURLClassLoader@29138d3a
实例对象: mainMethod.invoke(null, userArgs.toArray)
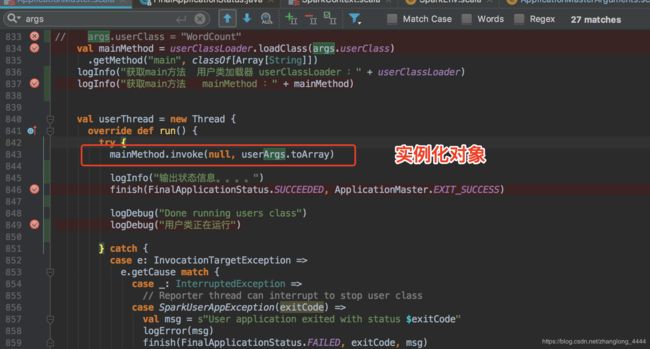
在这里面开始执行 自定义的类 WordCount
剩下的就是 获取响应结果,循环打印就好
注意代码:
registerAM(sparkConf, rpcEnv, driverRef, sparkConf.getOption("spark.driver.appUIAddress"))这段代码是 向 Yarn 注册ApplicationMaster
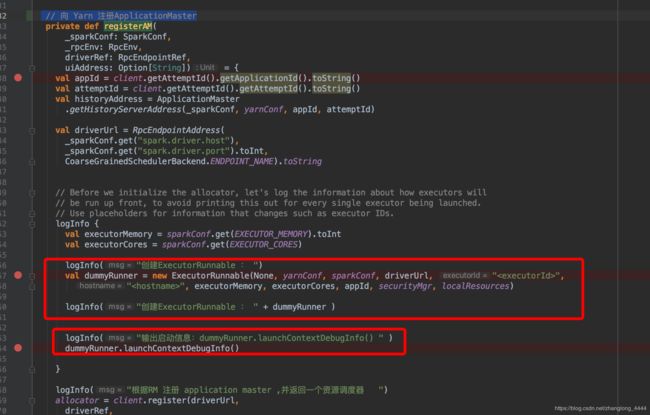
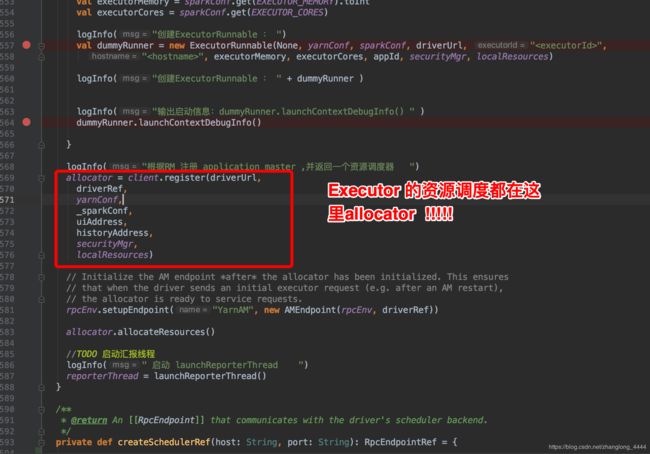
allocator负责与ResourceManager 交互, 申请,创建 Executor 关于 executor 的创建 , 请看下一篇文章:
Spark2.3.2源码解析: 4.3.Yarn cluster 模式 Executor 启动源码 分析
https://blog.csdn.net/zhanglong_4444/article/details/87877672