Pytorch(五)入门:DataLoader 和 Dataset
DataLoader 和 Dataset
构建模型的基本方法,我们了解了。
接下来,我们就要弄明白怎么对数据进行预处理,然后加载数据,我们以前手动加载数据的方式,在数据量小的时候,并没有太大问题,但是到了大数据量,我们需要使用 shuffle, 分割成mini-batch 等操作的时候,我们可以使用PyTorch的API快速地完成这些操作。
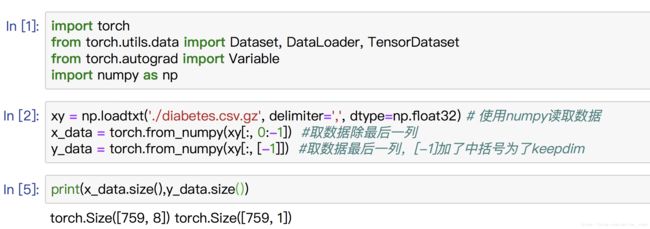
Dataset是一个包装类,用来将数据包装为Dataset类,然后传入DataLoader中,我们再使用DataLoader这个类来更加快捷的对数据进行操作。
DataLoader是一个比较重要的类,它为我们提供的常用操作有:batch_size(每个batch的大小), shuffle(是否进行shuffle操作), num_workers(加载数据的时候使用几个子进程)
现在,我们先展示直接使用 TensorDataset 来将数据包装成Dataset类
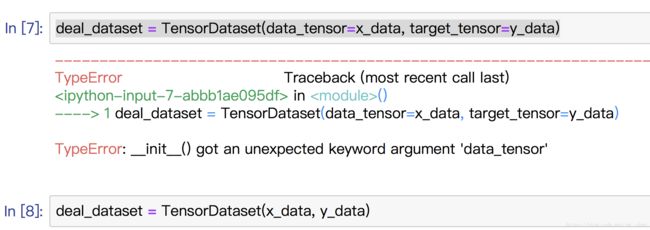
这里差个题外话,不知道为什么,出现这个错误,
torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)
TypeError: __init__() got an unexpected keyword argument 'data_tensor'
但是,改成deal_dataset = TensorDataset(x_data, y_data)这样就OK了。
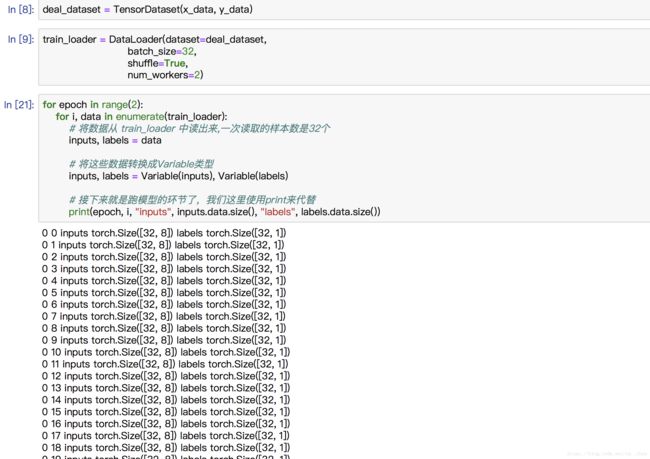
接下来,我们来继承 Dataset类 ,写一个将数据处理成DataLoader的类。
当我们集成了一个 Dataset类之后,我们需要重写 len 方法,该方法提供了dataset的大小; getitem 方法, 该方法支持从 0 到 len(self)的索引
class DealDataset(Dataset):
"""
下载数据、初始化数据,都可以在这里完成
"""
def __init__(self):
xy = np.loadtxt('../dataSet/diabetes.csv.gz', delimiter=',', dtype=np.float32) # 使用numpy读取数据
self.x_data = torch.from_numpy(xy[:, 0:-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
self.len = xy.shape[0]
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
# 实例化这个类,然后我们就得到了Dataset类型的数据,记下来就将这个类传给DataLoader,就可以了。
dealDataset = DealDataset()
train_loader2 = DataLoader(dataset=dealDataset,
batch_size=32,
shuffle=True)
for epoch in range(2):
for i, data in enumerate(train_loader2):
# 将数据从 train_loader 中读出来,一次读取的样本数是32个
inputs, labels = data
# 将这些数据转换成Variable类型
inputs, labels = Variable(inputs), Variable(labels)
# 接下来就是跑模型的环节了,我们这里使用print来代替
print("epoch:", epoch, "的第" , i, "个inputs", inputs.data.size(), "labels", labels.data.size())

torchvision 包的介绍
torchvision 是PyTorch中专门用来处理图像的库,PyTorch官网的安装教程,也会让你安装上这个包。
这个包中有四个大类。
torchvision.datasets
torchvision.models
torchvision.transforms
torchvision.utils
这里我们主要介绍前三个。
torchvision.datasets
torchvision.datasets 是用来进行数据加载的,PyTorch团队在这个包中帮我们提前处理好了很多很多图片数据集。
- MNISTCOCO
- Captions
- Detection
- LSUN
- ImageFolder
- Imagenet-12
- CIFAR
- STL10
- SVHN
- PhotoTour
我们可以直接使用,示例如下:

torchvision.models
torchvision.models 中为我们提供了已经训练好的模型,让我们可以加载之后,直接使用。
torchvision.models模块的 子模块中包含以下模型结构。
- AlexNet
- VGG
- ResNet
- SqueezeNet
- DenseNet
我们可以直接使用如下代码来快速创建一个权重随机初始化的模型
import torchvision.models as models
resnet18 = models.resnet18()
alexnet = models.alexnet()
squeezenet = models.squeezenet1_0()
densenet = models.densenet_161()
也可以通过使用 pretrained=True 来加载一个别人预训练好的模型
import torchvision.models as models
resnet18 = models.resnet18(pretrained=True)
alexnet = models.alexnet(pretrained=True)
import torchvision.models as models
# 加载一个 resnet18 模型
resnet18 = models.resnet18()
print(resnet18)
import torchvision.models as models
resnet18 = models.resnet18(pretrained=True) # 加载一个已经预训练好的模型, 需要下载一段时间...

# 我们这里还是对MNIST进行处理,初始的MNIST是 28 * 28,我们把它处理成 96 * 96 的torch.Tensor的格式
from torchvision import transforms as transforms
import torchvision
from torch.utils.data import DataLoader
# 图像预处理步骤
transform = transforms.Compose([
transforms.Resize(96), # 缩放到 96 * 96 大小
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 归一化
])
DOWNLOAD = True
BATCH_SIZE = 32
train_dataset = torchvision.datasets.MNIST(root='./data/', train=True, transform=transform, download=DOWNLOAD)
train_loader = DataLoader(dataset=train_dataset,
batch_size=BATCH_SIZE,
shuffle=True)
print(len(train_dataset))
print(len(train_loader))
以上代码参考:https://github.com/LianHaiMiao/pytorch-lesson-zh/