Hive collect、explode函数详解(包括concat、Lateral View)
背景:
最近需要对业务系统数据进行ETL,供机器学习训练,我们需要对数据进行关联聚合,多行或多列数据转换为单行单列这种操作很常见;正好hive提供collect函数可以实现这种格式需求,我们在这整理下用法,顺便扩展一下~
一、collect_set 和 collect_list 函数
collect_set / collect_list(col)函数只接受基本数据类型,它的主要作用是将某字段的值汇总,产生Array类型字段,注意该函数只能接受一列参数!我们一般都会配合group by 函数,直接汇总分组数据!
collect函数也可以实现一个功能:获取group by后面没有的字段!
collect_set 和 collect_list 函数的区别很直观,set会进行去重,而list不会!
测试数据:
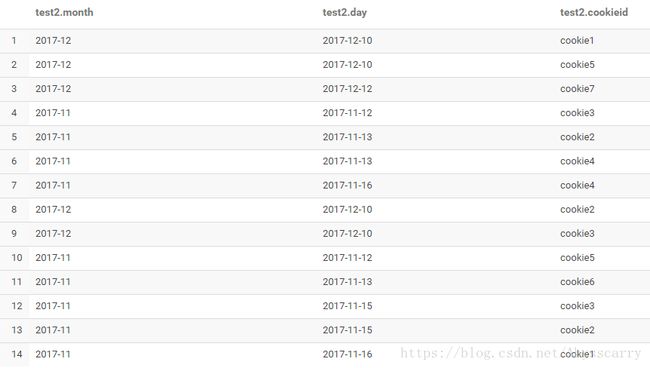
select month,day,collect_set(cookieid) from test2 group by month,day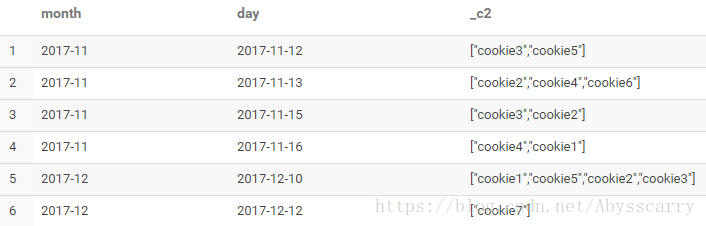
可以看到,结果字段为数组类型!
我们可以通过下标去获取数组中的数据:
select month,day,collect_set(cookieid)[0] c0 from test2 group by month,day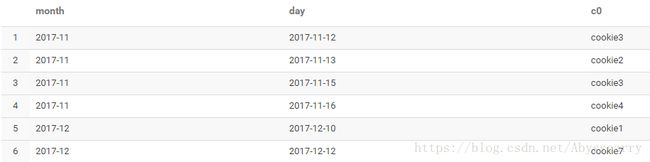
select month,day,collect_set(cookieid)[1] c1 from test2 group by month,day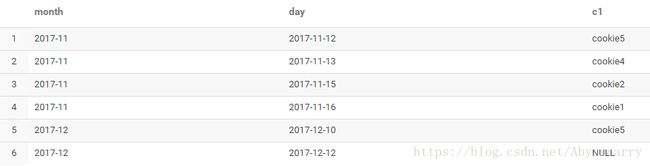
从上面结果可以看到,取值时如果下标超出范围,会返回NULL
collect_list 函数 除了不去重之外,其他特性和set一模一样:
select month,day,collect_list(cookieid) cl from test2 group by month,day
select month,day,collect_list(cookieid)[0] cl0 from test2 group by month,day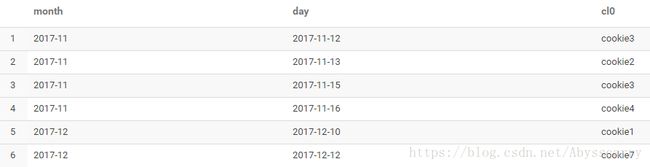
二、扩展:concat / concat_ws 函数
如果想按指定格式合并分组内全部行记录怎么处理?
而hive的collect函数只能接受一个参数,无法像mysql的group_concat函数一样能直接多列随意合并,所以我们必须通过hive的concat函数先指定格式合并再collect!
select concat('a','b') c from test2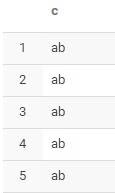
select concat('a','b',NULL) c from test2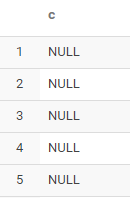
可以看到,直接用concat函数,如果其中某一列为NULL,那么合并结果也为NULL,这个时候,我们需要concat_ws函数:
concat_ws 函数第一个参数为指定合并分隔符:
select concat_ws(',','a','b') cw from test2
select concat_ws(',','a','b',NULL,'c') cw1 from test2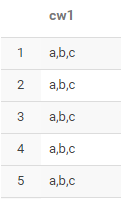
NULL字段合并对于concat_ws来说无影响!
我们用collect函数合并时结果字段为数组形式,很多时候我们并不希望是这种格式,所以可以通过concat_ws去改变:
select month,day,concat_ws(',',collect_list(cookieid)) cw from test2 group by month,day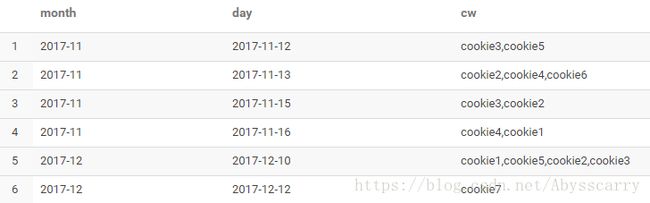
或者这种格式需求:
select month,day,collect_list(concat(cookieid,'|',day)) cl from test2 group by month,day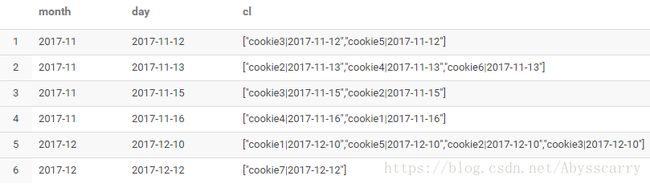
三、Explode 函数
官方解释:
explode()接收一个数组(或一个map)作为输入并将数组(map)的元素作为单独的行输出;

可以看到,explode函数的参数只能是数组或map类型
准备测试数据:
HDFS文件(字段分隔符为/t):
a b 1,2,3 money:10,age:30
c d 4,5,6 money:20,age:45创建外部表:
create external table test3 (
name1 string,
name2 string,
id array,
content map<string,int>
)
row format delimited
fields terminated by '\t'
collection items terminated by ','
map keys terminated by ':'
location '/yj/test' 
测试该函数用法:
对数组字段进行explode:
select explode(id) e from test3![]()
对map字段进行explode:
select explode(content) e from test3![]()
报错!发现取别名失败了!原来content字段为map类型,explode后会变成两列,所以必须取两个别名~
select explode(content) from test3
map类型默认字段名为key,value
select explode(content) as (mykey,myvalue) from test3
取两个别名要加括号哦~
重点来了:
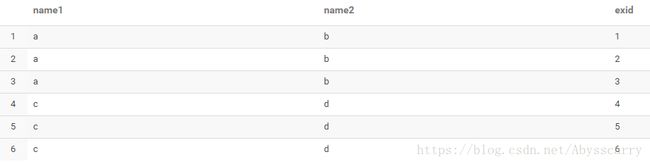
select name1,name2,explode(id) e from test3 (报错)![]()
错误信息如下:
Error while compiling statement: FAILED: SemanticException [Error 10081]:UDTF's are not supported outside the SELECT clause, nor nested in expressions
这就涉及到了explode函数作为UDTF类型函数的基本特性了:
UDTF一般有两种使用方法,一种直接放到select后面,一种和lateral view一起使用:
1:直接select中使用时:
不可以添加其他字段使用:
select a, explode_map(properties) as (col1,col2) from src(这就是上面报错的原因!)不可以嵌套调用:
select explode_map(explode_map(properties)) from src不可以和group by/cluster by/distribute by/sort by一起使用:
select explode_map(properties) as (col1,col2) from src group by col1, col22:和lateral view一起使用:
select src.id, mytable.col1, mytable.col2 from src lateral view explode_map(properties) mytable as col1, col2;那么问题来了,lateral view 到底是个什么东东?
四、lateral view 详解
以下内容为 hive官方 wiki:wiki地址
Lateral View Syntax
lateralView: LATERAL VIEW udtf(expression) tableAlias AS columnAlias (',' columnAlias)*
fromClause: FROM baseTable (lateralView)*注意语法:比一般函数多了个虚拟表别名!
Description
Lateral view is used in conjunction with user-defined table generating functions such as explode(). As mentioned in Built-in Table-Generating Functions, a UDTF generates zero or more output rows for each input row. A lateral view first applies the UDTF to each row of base table and then joins resulting output rows to the input rows to form a virtual table having the supplied table alias.
翻译:
Lateral view与用户定义的表生成函数(如explode())一起使用。正如在内置的表生成函数中提到的,UDTF为每个输入行生成零个或多个输出行。Lateral view首先将UDTF应用于基表的每一行,然后将产生的输出行连接到输入行,形成一个具有提供的表别名的虚拟表。
注:Lateral View通常和UDTF一起出现,为了解决UDTF不允许在select字段的问题
Multiple Lateral Views
A FROM clause can have multiple LATERAL VIEW clauses. Subsequent LATERAL VIEWS can reference columns from any of the tables appearing to the left of the LATERAL VIEW.
Multiple Lateral View 可以实现类似笛卡尔乘积
SELECT * FROM exampleTable
LATERAL VIEW explode(col1) myTable1 AS myCol1
LATERAL VIEW explode(myCol1) myTable2 AS myCol2;Outer Lateral Views
The user can specify the optional OUTER keyword to generate rows even when a LATERAL VIEW usually would not generate a row. This happens when the UDTF used does not generate any rows which happens easily with explode when the column to explode is empty. In this case the source row would never appear in the results. OUTER can be used to prevent that and rows will be generated with NULL values in the columns coming from the UDTF.
翻译:
即使横向视图通常不会生成一行,用户也可以指定可选的OUTER关键字来生成行。当使用的UDTF不生成任何行时,就会发生这种情况。在这种情况下,源行永远不会出现在结果中。可以使用OUTER来防止这种情况,并在来自UDTF的列中使用空值生成行。
Outer关键字可以把不输出的UDTF的空结果,输出成NULL,防止丢失数据。
测试:
select name1,name2,exid from test3 LATERAL VIEW explode(id) idtable as exid