阅读《Learning to Ask: Neural Question Generation for Reading Comprehension 》
阅读《Learning to Ask: Neural Question Generation for Reading Comprehension 》
@(NLP)[自然语言生成|LSTM|QA|Attention]
Abstract
作者为解决机器生成问题,提出了一种基于注意力的序列学习模型并研究了句子级别和段落信息编码之间的影响。与以前的工作不同,他们的模型不依赖手工生成的规则或者复杂的NLP管道(不是很理解,原文为 Sophisticated NLP pipeline )。人工评价生成的问题更自然,也更难回答,与原文在语法和句话上有区别,需要推理回答。
Introduction
Question generate function
In addition to the above applications, question generation systems can aid in the development of annotated data sets for natural language processing (NLP) research in reading comprehension and question answering. Indeed the creation of such datasets.
Example :the natural qusetion and their answers

Natural question features
Vanderwende 指出学会问问题是NLP研究一个重要的问题,并且问题不仅仅是一个陈述句句子的句法转换。
自然的问题常常有以下特点:
- In particular, a natural sounding question often compresses the sentence on which it is based (e.g., question 3 in Figure 1)
- 一个自然而然的问题往往明白句子是基于什么的
- uses synonyms for terms in the passage (e.g., “form” for “produce” in question 2 and “get” for “produce” in question 3),
- 使用段落中的同义词
- refers to entities from preceding sentences or clauses (e.g., the use of “photosynthesis” in question 2).
- 涉及到前文或从句中的实体
- Othertimes, world knowledge is employed to produce a good question (e.g., identifying “photosynthesis” as a “life process” in question 1).
- 知识会被用来产生一个好问题
文章中提出的模型不同于以前的模型,它完全由数据驱动,没有手工生成的规则
Task Definition
Goal: to generate a natural question y relation information in the sentence
y can be a sequence of an arbitrary length: [y1,…,y|y|] [ y 1 , … , y | y | ] . Suppose the length of the input sentence is M M , x x could then be represented as a sequence of tokens [x1,...,xM] [ x 1 , . . . , x M ] . The QG task is defined as finding y, such that:
y¯¯¯=argymaxP(y|x)(1) (1) y ¯ = a r g y m a x P ( y | x )
Model
Decoder
在字级别构造公式一的概率:
where probability of each yt y t is predicted based on all the words that are generated previously (i.e.,y<t) ( i . e . , y < t ) , and input sentence x x .
看公式,最终Qusetion y y 的出现概率是每一个词出现概率的乘积,很好理解。
with ht h t being the recurrent neural networks state variable at time step t t , and ct c t being the attention-based encoding of x x at decoding time step t t (Section 4.2)
ht h t 是 t t 时刻循环神经网络的参数值, ct c t 是 t t 时刻 x x 输入编码时的注意力系数, Ws W s 和 Wt W t 是需要学习的参数。
It generates the new state ht h t , given the representation of previously generated word yt−1 y t − 1 (obtained from a word look-up table), and the previous state ht−1 h t − 1 .
上一次预测得到的输出 yt−1 y t − 1 和上一时刻的循环网络状态值 ht−1 h t − 1 被用来生成当前值 yt y t
解码器隐藏状态的初始化区分了我们的基本模型和包含段落级别信息的模型。
The initialization of the decoder’s hidden state differentiates our basic model and the model that incorporates paragraph-level information.
- 基础模型用了句子状态做初始化
- 段落模型使用了句子状态和段落状态共同做初始化
Encoder
两个模型都引用了注意力机制,但段落信息只在段落编码的时候被应用了。
使用双向LSTM编码 t t 时刻的输入。
为了在解码的时候得到注意力系数 ct c t ,我们需要得到有上下文依赖的令牌表示 bt=[bt→,bt←] b t = [ b t → , b t ← ] ,然后求 bt b t 在 (t=1,…,|x|) ( t = 1 , … , | x | ) 的平均值,
我的理解 ct c t 是每一个 t t 时刻,对 bi b i 求加权平均。
而这个加权系数 ai,t a i , t 由双向LSTM的评分函数和Softmax正则化求得:
为了初始化解码器的隐藏状态,需要把Bi-LSTM的隐藏状态结合起来 s=[b|x|→,b1←] s = [ b | x | → , b 1 ← ]
Paragraph encoder
段落级别的编码器和句子级别一样,当句子过长时我们给一个阈值 L L ,截断超过长度的句子。如果用 z z 来表示段落,那么用另一个LSTM来编码 z z :
同样的段落编码器的输出 s′ s ′ :
s′=[d|z|→,d1←] s ′ = [ d | z | → , d 1 ← ] **
Train and Inference
给定句子和问题的输入对 S={(x(i),y(i))}Si=1 S = { ( x ( i ) , y ( i ) ) } i = 1 S
模型的训练目标是最小化负的极大似然函数
在训练中出现较少的单词将被替换成UNK
但是编码时会大量输出UNK,因此对编码时期的UNK 做积极的处理。文章采用了简单替换的方式,用当前时刻,输入句子中注意力分数最高的词替换。
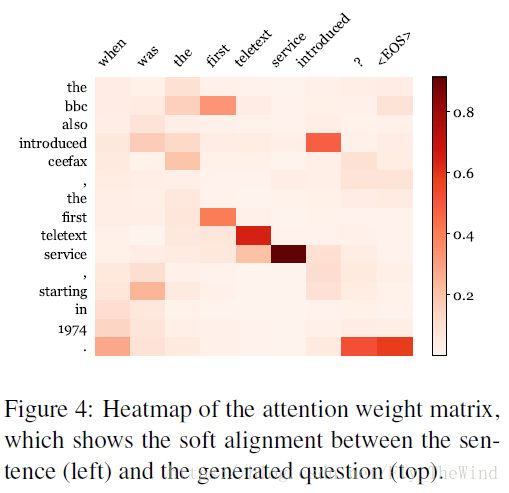
We see that the key words in the output (“introduced”, “teletext”, etc.) aligns well with those in the input sentence.
仔细想想这样的想法蛮有意思的。当这个词在词表中出现概率低(不出现)时即意味着这个词是这个句子的特征词,可以很好的代表这个句子的一部分特点,此时用这个词去替换UNK真是一个聪明的想法。
Experiment
Data
文章数据集用的是斯坦福的SQuAD。
同时实验建立了一个约束:
训练的句子和问题对至少有一个非停用词是相同的。最后
实验结果
与Baseline比较结果:

输入分别为句子答案来自:句子级别、段落、以及全文或者需要用到世界知识