python3爬虫实战二:股票信息抓取及存储
参考:http://python.jobbole.com/88350/?utm_source=blog.jobbole.com&utm_medium=relatedPosts#article-comment
任务:
1. 从东方财富网获取所有的上海股票的代码信息
2.对获得代码信息通过百度股市通网站对其进行解析抓取股票名称及交易信息
3.对所抓取的信息存储到txt文件或者mongodb数据库内
准备工作:
1.第三方库、requests、BeautifulSoup、re 、mongodb(可选)、Pool(可选)
2.第三方软件 MongoDB、Robo 3T(可选)
语言:python3.5
前提说明:
网站选取规则:股票信息应该存在静态的html页面,非js加载,不然直接提取不出
如何查看是否为静态加载,我们只需要打开网页源码,查询即可。如下所示
第一步:打开股票代码查询的网址(http://quote.eastmoney.com/stocklist.html#sz)
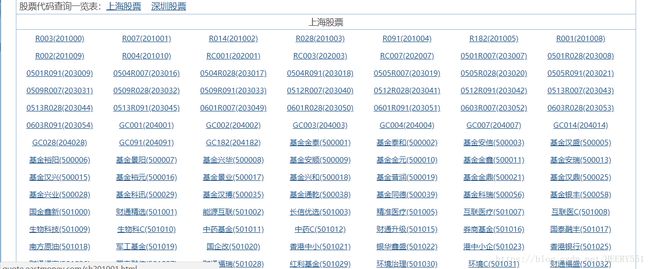
随便打开一个,比如我们打开第一个即R003(201000), 进入后网址变为 http://quote.eastmoney.com/sh201000.html
进入网址后,任意空白位置右击鼠标点击查看网页源代码,并在源代码中按Ctrl+F查询我们需要的股票信息,这里我们输入2.000 很明显我们没有找到我们所需要的股票信息。所以这个网址的股票信息并非静态加载。所以选择其他可通过静态网址加载的股票信息网址

通过查询,我们获取了静态加载股票交易信息的网址,即百度股市通,如图所示

该网址可以直接显示股票交易信息。所以这就是我们所需要的静态网址。我们还需要分析两个网址的关系,即对原理进行分析。
原理分析
我们通过分析百度股市通网址可知,每次只需要获取股票的代码即可,每次网址变化均是对应代码的的改变,
如:我们上述图片(中药c)代码为:sh501012 对应的网址是 https://gupiao.baidu.com/stock/sh501012.html
即每次只需更换股票代码, https://gupiao.baidu.com/stock/+(股票代码)+.html
而刚好我们可以通过通过东方财富网:http://quote.eastmoney.com/stocklist.html#sz 获取各个股票的代码,只需要把代码提取出来再放到百度股市通内网址即可获取每只股票的交易信息了。 那么我们就可以开始进行信息的抓取了。
一、从东方财富网获取所有的上海股票的代码信息
(1) 对网页进行访问,获取html信息
import requests
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'}
root_url = "http://quote.eastmoney.com/stocklist.html"
response = requests.get(root_url,headers = headers)
if response.status_code == 200:
response.encoding = response.apparent_encoding # 编码采用网页本身的编码
print(response.text)
else:
print('未能打开网页......')运行程序,则打印出html网页信息如下
(2) 对网页进行解析,获取我们所需要的全部股票代码
可以直接进入东方财富网,对其中的某个代码右击检查查看(如图一所示),所对应信息,也可以查看刚才我们打印的html网页,往下可查看到(如图二所示)
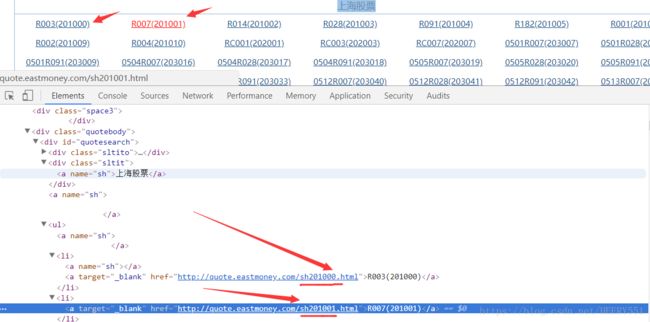
图一

图二
分析可知,我们所需要的全部股票代码就是类似sh201000的一串字符,这些字符存在于 div id="quotesearch" 的li 下 ,可循环获取所有li下的内容,再提取出其a下的链接href,然后再正则匹配出这些字符串,具体实现代码如下所示
import re
from bs4 import BeautifulSoup
html = response.text # 其中html就是我们刚才获取的html网页
stock_id_list =[]
soup = BeautifulSoup(html,'lxml')
stock_list = soup.find('div',id='quotesearch')
items = stock_list.find_all('li')
for item in items:
url = item.a['href']
id = re.findall(r'/(s[h|z]\d{6}).html',url)[0] # 由于观察股票代码特点,我们知道都是sh+6位数字 或者sz+6位数字
stock_id_list.append(id)
print(stock_id_list) # 获取所有的股票代码构建的列表由于股票代码具有一定的规律性,根据规律,可通过正则表达式提取出所需要的股票代码,打印结果为

由此可见,我们已经将所有股票的代码提出来,接下来就是对每个股票交易信息进行提取了
二、对获得代码信息通过百度股市通网站对其进行解析抓取股票名称及交易信息
(1)随机抽取几个我们刚才获取的股票代码带入百度股市通网址内,查看各种可能情况。
第一种情况:选取第一个股票代码,![]() ,其股票代码为sh201000,即为网址:https://gupiao.baidu.com/stock/sh201000.html
,其股票代码为sh201000,即为网址:https://gupiao.baidu.com/stock/sh201000.html

可知第一个股票信息已经休市,即只有股票名字与关市价格,无其他交易信息了。那么这样的股票我们只需要提取其名字及关市价格就行了。
第二种情况:打开一个股票信息,抽取的是 ![]() ,其代码信息是sh203007,但是访问 其链接:https://gupiao.baidu.com/stock/sh203007.html,打开为空网页,即为404错误,此时这种情况我们不需要,则跳过。
,其代码信息是sh203007,但是访问 其链接:https://gupiao.baidu.com/stock/sh203007.html,打开为空网页,即为404错误,此时这种情况我们不需要,则跳过。
第三种情况:打开下一个股票信息,随机抽取的是 ![]() ,其股票代码是 sh501012 所以只需要访问 链接:https://gupiao.baidu.com/stock/sh501012.html ,访问后可获取到我们的信息,打开检查,如图所示:
,其股票代码是 sh501012 所以只需要访问 链接:https://gupiao.baidu.com/stock/sh501012.html ,访问后可获取到我们的信息,打开检查,如图所示:

可知,这只股票不仅包含我们需要的股票名称与关市价格,还有其他的交易信息,分析其所在的位置,我们可以通过BeautifulSoup将这些信息解析出来。
所以:我们会出现三种情况,其中对于第一种情况,我们可以直接提取其股票名称与关市价格,第二种情况,我们可以直接丢弃不看,第三种情况即包含所有我们想要的信息。因此,我们则可以解析我们的股票详细信息了。
(2)解析具体股票网页信息
我们以![]() ,其代码为sh501012 ,链接为:https://gupiao.baidu.com/stock/sh501012.html 为例解析。
,其代码为sh501012 ,链接为:https://gupiao.baidu.com/stock/sh501012.html 为例解析。
可以先构建一个字典,存储所有我们需要的信息,组成键值对,其中有股票名称,股票价格,最高,最低等信息。所有信息都存储在div class=‘stock-bets’内部。
股票名称在其a class=‘bets-name’下列表第一项的文本信息,关市价格在div class=‘price’下列表第一项的strong下的文本内。而其他交易信息的键均存储在‘dt’文本内,值存储在‘dd’文本内。具体解析代码如下
detail="https://gupiao.baidu.com/stock/"
url = detail+"sh501012"+'.html'
response = requests.get(url,headers = headers)
if response.status_code == 200:
response.encoding = response.apparent_encoding
stock_html=response.text
else:
print('未能打开网页......')
items_dict = {}
soup = BeautifulSoup(stock_html,'lxml')
items = soup.find('div',class_='stock-bets')
stock_name = items.find_all('a',class_='bets-name')[0].text
close_price = items.find_all('div',class_='price')[0].strong.text
items_dict.update({'股票名称': stock_name.split()[0]})
items_dict.update({'股票价格':close_price})
keys = items.find_all('dt')
values = items.find_all('dd')
for index in range(len(keys)):
dict_key = keys[index].text
dict_value = values[index].text
items_dict[dict_key]=dict_value
print(items_dict)运行上述代码只是实现了一个股票信息的交易信息的抓取,其返回的结果是一个包含各项信息的字典形式的内容,结果如下图示
![]()
由此我们即获得了我们需要的交易信息,只要我们把我们之前获取的所有股票代码循环带入解析,即可获取所有的股票信息。
三、对所抓取的信息存储到txt文件或者mongodb数据库内
(1) 存储到txt文件
上述解析只是针对了其中一只股票的解析,其中返回的只是一个字典结果,如果循环所有股票即解析出所有结果并进行存储即可。相关代码如下
import os
result = items_dict
with open(os.getcwd()+'/股票信息抓取.txt','a',encoding='utf-8') as f:
f.write(str(result)+'\n')那么我们就可以将字典形式的结果存储到txt文件内,这个文件名为股票信息的抓取.txt, 内容即为字典形式的结果。该文件在程序的同级目录下。
打开txt文件,显示结果如下【注意这里的不只是一只股票的结果,是循环所有股票的综合结果,具体循环见后全部程序】

(2)存储到Mongodb数据库内
首先确认已经安装了MongoDB数据库,以及其可视化Robo 3T 软件。
如果存在,则可进行下面操作,代码如下
import pymongo
client = pymongo.MongoClient('localhost') # 连接本地的monogdb服务器
db = client['baidu_stock'] # 设置数据库名称
MONGO_TABLE = 'stock' # 设置该数据库collection名称
result=items.dict
try:
if db[MONGO_TABLE].insert(result):
print('存储到Mongodb成功...')
except:
print('存储有误.....')循环运行所有股票信息,打开mongodb可视化Robo 3T 可以得到下图的结果

到此 ,这个抓取存储股票信息的小项目就已经结束,纵观下来,这里还只是抓取的是静态网页信息,难度不大,适合爬虫新手上手练习,巩固相关的知识,这里用到了mongodb存储,其实也不会难,只需要配置后存储即可。那么,继续加油吧!有错误可以交流指正,大家相互进步,也才学爬虫不久。
全部程序:
#!/usr/bin/env python3
# -*- coding: UTF-8 -*-
# 第一步 通过 http://quote.eastmoney.com/stocklist.html 网址获取 股票代码
# 第二步 通过 ’https://gupiao.baidu.com/stock/'+股票代码+’.html‘ 进入具体
# 网页进行提取股票具体信息
import pymongo
import requests,re,os
from bs4 import BeautifulSoup
from multiprocessing import Pool
client = pymongo.MongoClient('localhost')
db = client['baidu_stock']
MONGO_TABLE = 'stock'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'}
# 获取网页的html网页信息
def get_html(url):
response = requests.get(url,headers = headers)
if response.status_code == 200:
#response.encoding = 'UTF-8'
response.encoding = response.apparent_encoding # 编码采用网页本身的编码
return response.text
else:
print('未能打开网页......')
# 获取所有股票的代码
def get_Stock_id(html):
stock_id_list =[]
soup = BeautifulSoup(html,'lxml')
stock_list = soup.find('div',id='quotesearch')
#return stock_list
items = stock_list.find_all('li')
#return items
for item in items:
url = item.a['href']
id = re.findall(r'/(s[h|z]\d{6}).html',url)[0]
stock_id_list.append(id)
return stock_id_list
# 解析某只股票的交易信息
def parser_stock_html(stock_html):
items_dict = {}
soup = BeautifulSoup(stock_html,'lxml')
items = soup.find('div',class_='stock-bets')
stock_name = items.find_all('a',class_='bets-name')[0].text
close_price = items.find_all('div',class_='price')[0].strong.text
items_dict.update({'股票名称': stock_name.split()[0]})
items_dict.update({'股票价格':close_price})
#item_keys = items.find_all('div',class_='bets-col-8')
keys = items.find_all('dt')
values = items.find_all('dd')
for index in range(len(keys)):
dict_key = keys[index].text
dict_value = values[index].text
items_dict[dict_key]=dict_value
return items_dict
# 对所有股票进行循环,并且将每只股票信息都存储到Mongodb数据库及txt文件内
def get_stock_dict(id_list,detail_url):
length = len(id_list)
count = 1
for id in id_list:
detail_stock_url = detail_url +id+'.html'
#print(detail_stock_url)
stock_html = get_html(detail_stock_url)
try:
if stock_html =="":
continue
result = parser_stock_html(stock_html)
print('正在爬取第' + str(count) + '条股票信息......' + '')
print(r"当前进度: {:.2f}%".format(count * 100 / length), end="")
print(result)
save_result_to_text(result)
save_to_mongon(result)
except:
print('正在爬取第' + str(count) + '条股票信息......' + '')
print(r"当前进度: {:.2f}%".format(count * 100 / length), end=" ")
print('但是该股票信息网页未能打开......\n')
print('\n')
count+=1# 将每只股票信息存储到txt文件内
def save_result_to_text(result):
with open(os.getcwd()+'/股票信息抓取.txt','a',encoding='utf-8') as f:
f.write(str(result)+'\n')
# 将每只股票信息均存储到mongodb数据库内
def save_to_mongon(result):
try:
if db[MONGO_TABLE].insert(result):
print('存储到Mongodb成功...')
except:
print('存储有误.....')
def main():
root_url = "http://quote.eastmoney.com/stocklist.html"
detail_url = "https://gupiao.baidu.com/stock/"
stock_html = get_html(root_url) # 获取股票代码网页的html信息
id_list = get_Stock_id(stock_html) # 从股票代码网页获取全部的代码id号
get_stock_dict(id_list,detail_url)
if __name__ == '__main__':
pool = Pool() # 引入进程池
pool.Process(main())运行全部程序,运行结果可显示如下图所示
