(第一部分 机器学习基础)
第01章 机器学习概览
第02章 一个完整的机器学习项目(上)
第02章 一个完整的机器学习项目(下)
第03章 分类
第04章 训练模型
第05章 支持向量机
第06章 决策树
第07章 集成学习和随机森林
第08章 降维
(第二部分 神经网络和深度学习)
第9章 启动和运行TensorFlow
第10章 人工神经网络
第11章 训练深度神经网络(上)
第11章 训练深度神经网络(下)
第12章 设备和服务器上的分布式 TensorFlow
第13章 卷积神经网络
第14章 循环神经网络
第15章 自编码器
第16章 强化学习(上)
第16章 强化学习(下)
第 10 章介绍了人工神经网络,并训练了我们的第一个深度神经网络。 但它是一个非常浅的 DNN,只有两个隐藏层。 如果你需要解决非常复杂的问题,例如检测高分辨率图像中的数百种类型的对象,该怎么办? 你可能需要训练更深的 DNN,也许有 10 层,每层包含数百个神经元,通过数十万个连接相连。 这可不像公园散步那么简单:
- 首先,你将面临棘手的梯度消失问题(或相关的梯度爆炸问题),这会影响深度神经网络,并使较低层难以训练。
- 其次,对于如此庞大的网络,训练将非常缓慢。
- 第三,具有数百万参数的模型将会有严重的过拟合训练集的风险。
在本章中,我们将依次讨论这些问题,并提出解决问题的技巧。 我们将从解释梯度消失问题开始,并探讨解决这个问题的一些最流行的解决方案。 接下来我们将看看各种优化器,与普通梯度下降相比,它们可以加速大型模型的训练。 最后,我们将浏览一些流行的大型神经网络正则化技术。
使用这些工具,你将能够训练非常深的网络:欢迎来到深度学习的世界!
梯度消失/爆炸问题
正如我们在第 10 章中所讨论的那样,反向传播算法的工作原理是从输出层到输入层,传播误差的梯度。 一旦该算法已经计算了网络中每个参数的损失函数的梯度,它就通过梯度下降使用这些梯度来更新每个参数。
不幸的是,随着算法进展到较低层,梯度往往变得越来越小。 结果,梯度下降更新使得低层连接权重实际上保持不变,并且训练永远不会收敛到良好的解决方案。 这被称为梯度消失问题。 在某些情况下,可能会发生相反的情况:梯度可能变得越来越大,许多层得到了非常大的权重更新,算法发散。这是梯度爆炸的问题,在循环神经网络中最为常见(见第 14 章)。 更一般地说,深度神经网络受梯度不稳定之苦; 不同的层次可能以非常不同的学习速率。
虽然这种现象已经经过了相当长的一段时间的实验观察(这是造成深度神经网络大部分时间都被抛弃的原因之一),但直到 2010 年左右,人们才有了明显的进步。 Xavier Glorot 和 Yoshua Bengio 发表的题为《Understanding the Difficulty of Training Deep Feedforward Neural Networks》的论文发现了一些疑问,包括流行的 sigmoid 激活函数和当时最受欢迎的权重初始化技术的组合,即随机初始化时使用平均值为 0,标准差为 1 的正态分布。简而言之,他们表明,用这个激活函数和这个初始化方案,每层输出的方差远大于其输入的方差。网络正向,每层的方差持续增加,直到激活函数在顶层饱和。这实际上是因为logistic函数的平均值为 0.5 而不是 0(双曲正切函数的平均值为 0,表现略好于深层网络中的logistic函数)。
看一下logistic 激活函数(参见图 11-1),可以看到当输入变大(负或正)时,函数饱和在 0 或 1,导数非常接近 0。因此,当反向传播开始时, 它几乎没有梯度通过网络传播回来,而且由于反向传播通过顶层向下传递,所以存在的小梯度不断地被稀释,因此较低层确实没有任何东西可用。

Glorot 和 Bengio 在他们的论文中提出了一种显著缓解这个问题的方法。 我们需要信号在两个方向上正确地流动:在进行预测时是正向的,在反向传播梯度时是反向的。 我们不希望信号消失,也不希望它爆炸并饱和。 为了使信号正确流动,作者认为,我们需要每层输出的方差等于其输入的方差。(这里有一个比喻:如果将麦克风放大器的旋钮设置得太接近于零,人们听不到声音,但是如果将麦克风放大器设置得太大,声音就会饱和,人们就会听不懂你在说什么。 现在想象一下这样一个放大器的链条:它们都需要正确设置,以便在链条的末端响亮而清晰地发出声音。 你的声音必须以每个放大器的振幅相同的幅度出来。)而且我们也需要梯度在相反方向上流过一层之前和之后有相同的方差(如果您对数学细节感兴趣,请查阅论文)。实际上不可能保证两者都是一样的,除非这个层具有相同数量的输入和输出连接,但是他们提出了一个很好的折衷办法,在实践中证明这个折中办法非常好:随机初始化连接权重必须如公式 11-1 所描述的那样。其中n_inputs和n_outputs是权重正在被初始化的层(也称为扇入和扇出)的输入和输出连接的数量。 这种初始化策略通常被称为Xavier初始化(在作者的名字之后),或者有时是 Glorot 初始化。

当输入连接的数量大致等于输出连接的数量时,可以得到更简单的等式
或
我们在第 10 章中使用了这个简化的策略。
使用 Xavier 初始化策略可以大大加快训练速度,这是导致深度学习目前取得成功的技巧之一。 最近的一些论文针对不同的激活函数提供了类似的策略,如表 11-1 所示。 ReLU 激活函数(及其变体,包括简称 ELU 激活)的初始化策略有时称为 He 初始化(根据作者姓氏)。

默认情况下,fully_connected()函数(在第 10 章中介绍)使用 Xavier 初始化(具有均匀分布)。你可以通过使用如下所示的variance_scaling_initializer()函数来将其更改为 He 初始化:
he_init = tf.contrib.layers.variance_scaling_initializer()
hidden1 = fully_connected(X, n_hidden1, weights_initializer=he_init, scope="h1")
注意:本书使用
tensorflow.contrib.layers.fully_connected()而不是tf.layers.dense()(本章编写时不存在)。 现在最好使用tf.layers.dense(),因为contrib模块中的任何内容可能会更改或删除,恕不另行通知。dense()函数几乎与fully_connected()函数完全相同。 与本章有关的主要差异是:
几个参数被重新命名:范围变成名字,activation_fn变成激活(类似地,_fn后缀从诸如normalizer_fn之类的其他参数中移除),weights_initializer变成kernel_initializer等等。默认激活现在是None,而不是tf.nn.relu。 它不支持tensorflow.contrib.framework.arg_scope()(稍后在第 11 章中介绍)。 它不支持正则化的参数(稍后在第 11 章介绍)。
he_init = tf.contrib.layers.variance_scaling_initializer()
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu,
kernel_initializer=he_init, name="hidden1")
He 初始化只考虑了扇入,而不是像 Xavier 初始化那样扇入和扇出之间的平均值。 这也是variance_scaling_initializer()函数的默认值,但您可以通过设置参数mode ="FAN_AVG"来更改它。
非饱和激活函数
Glorot 和 Bengio 在 2010 年的论文中的一个见解是,消失/爆炸的梯度问题部分是由于激活函数的选择不好造成的。 在那之前,大多数人都认为,如果大自然选择在生物神经元中使用 sigmoid 激活函数,它们必定是一个很好的选择。 但事实证明,其他激活函数在深度神经网络中表现得更好,特别是 ReLU 激活函数,主要是因为它对正值不会饱和(也因为它的计算速度很快)。
不幸的是,ReLU激活功能并不完美。 它有一个被称为 “ReLU 死区” 的问题:在训练过程中,一些神经元有效地死亡,意味着它们停止输出 0 以外的任何东西。在某些情况下,你可能会发现你网络的一半神经元已经死亡,特别是如果你使用大学习率。 在训练期间,如果神经元的权重得到更新,使得神经元输入的加权和为负,则它将开始输出 0 。当这种情况发生时,由于当输入为负时,ReLU函数的梯度为0,神经元不可能恢复生机。
为了解决这个问题,你可能需要使用 ReLU 函数的一个变体,比如 leaky ReLU。这个函数定义为LeakyReLUα(z)= max(αz,z)(见图 11-2)。超参数α定义了函数“leaks”的程度:它是z < 0时函数的斜率,通常设置为 0.01。这个小斜坡确保 leaky ReLU 永不死亡;他们可能会长期昏迷,但他们有机会最终醒来。最近的一篇论文比较了几种 ReLU 激活功能的变体,其中一个结论是 leaky Relu 总是优于严格的 ReLU 激活函数。事实上,设定α= 0.2(巨大 leak)似乎导致比α= 0.01(小 leak)更好的性能。他们还评估了随机化 leaky ReLU(RReLU),其中α在训练期间在给定范围内随机挑选,并在测试期间固定为平均值。它表现相当好,似乎是一个正则项(减少训练集的过拟合风险)。最后,他们还评估了参数 leaky ReLU(PReLU),其中α被授权在训练期间被学习(而不是超参数,它变成可以像任何其他参数一样被反向传播修改的参数)。据报道这在大型图像数据集上的表现强于 ReLU,但是对于较小的数据集,其具有过度拟合训练集的风险。

最后,Djork-Arné Clevert 等人在 2015 年的一篇论文中提出了一种称为指数线性单元(exponential linear unit,ELU)的新的激活函数,在他们的实验中表现优于所有的 ReLU 变体:训练时间减少,神经网络在测试集上表现的更好。 如图 11-3 所示,公式 11-2 给出了它的定义。

它看起来很像 ReLU 函数,但有一些区别,主要区别在于:
- 首先它在
z < 0时取负值,这使得该单元的平均输出接近于 0。这有助于减轻梯度消失问题,如前所述。 超参数α定义为当z是一个大的负数时,ELU 函数接近的值。它通常设置为 1,但是如果你愿意,你可以像调整其他超参数一样调整它。 - 其次,它对
z < 0有一个非零的梯度,避免了神经元死亡的问题。 - 第三,函数在任何地方都是平滑的,包括
z = 0左右,这有助于加速梯度下降,因为它不会弹回z = 0的左侧和右侧。
ELU 激活函数的主要缺点是计算速度慢于 ReLU 及其变体(由于使用指数函数),但是在训练过程中,这是通过更快的收敛速度来补偿的。 然而,在测试时间,ELU 网络将比 ReLU 网络慢。
提示:
那么你应该使用哪个激活函数来处理深层神经网络的隐藏层? 虽然你的里程会有所不同,一般 ELU > leaky ReLU(及其变体)> ReLU > tanh > sigmoid。 如果您关心运行时性能,那么您可能喜欢 leaky ReLU超过ELU。 如果你不想调整另一个超参数,你可以使用前面提到的默认的α值(leaky ReLU 为 0.01,ELU 为 1)。 如果您有充足的时间和计算能力,您可以使用交叉验证来评估其他激活函数,特别是如果您的神经网络过拟合,则为RReLU; 如果您拥有庞大的训练数据集,则为 PReLU。
TensorFlow 提供了一个可以用来建立神经网络的elu()函数。 调用fully_connected()函数时,只需设置activation_fn参数即可:
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.elu, name="hidden1")
TensorFlow 没有针对 leaky ReLU 的预定义函数,但是很容易定义:
def leaky_relu(z, name=None):
return tf.maximum(0.01 * z, z, name=name)
hidden1 = tf.layers.dense(X, n_hidden1, activation=leaky_relu, name="hidden1")
批量标准化
尽管使用 He初始化和 ELU(或任何 ReLU 变体)可以显著减少训练开始阶段的梯度消失/爆炸问题,但不保证在训练期间问题不会回来。
在 2015 年的一篇论文中,Sergey Ioffe 和 Christian Szegedy 提出了一种称为批量标准化(Batch Normalization,BN)的技术来解决梯度消失/爆炸问题,每层输入的分布在训练期间改变的问题,更普遍的问题是当前一层的参数改变,每层输入的分布会在训练过程中发生变化(他们称之为内部协变量偏移问题)。
该技术包括在每层的激活函数之前在模型中添加操作,简单地对输入进行zero-centering和规范化,然后每层使用两个新参数(一个用于尺度变换,另一个用于偏移)对结果进行尺度变换和偏移。 换句话说,这个操作可以让模型学习到每层输入值的最佳尺度和平均值。
为了对输入进行归零和归一化,算法需要估计输入的均值和标准差。 它通过评估当前小批量输入的均值和标准差(因此命名为“批量标准化”)来实现。 整个操作在公式 11-3 中。
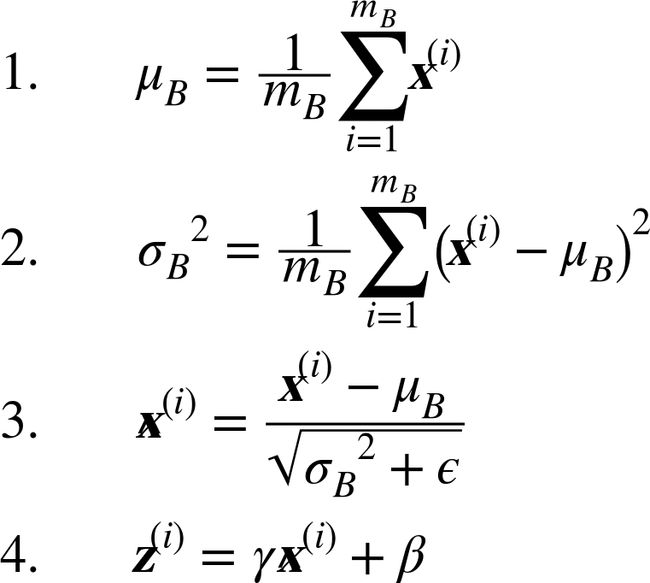
μB是整个小批量B的经验均值
σB是经验标准差,也是来评估整个小批量的。
mB是小批量中的实例数量。
Xi是以为零中心和标准化的输入。
γ是层的缩放参数。
β是层的便宜参数(偏移量)
ϵ是一个很小的数字,以避免被零除(通常为
10 ^ -3)。 这被称为平滑项(拉布拉斯平滑,Laplace Smoothing)。z(i) 是BN操作的输出:它是输入的缩放和移位版本。
在测试时,没有小批量计算经验均值和标准差,所以您只需使用整个训练集的均值和标准差。 这些通常在训练期间使用移动平均值进行有效计算。 因此,总的来说,每个批次标准化的层次都学习了四个参数:γ(缩放度),β(偏移),μ(平均值)和σ(标准差)。
作者证明,这项技术大大改善了他们试验的所有深度神经网络。梯度消失问题大大减少了,他们可以使用饱和激活函数,如 tanh 甚至逻辑激活函数。网络对权重初始化也不那么敏感。他们能够使用更大的学习率,显著加快了学习过程。具体地,他们指出,“应用于最先进的图像分类模型,批标准减少了 14 倍的训练步骤实现了相同的精度,以显著的优势击败了原始模型。[...] 使用批量标准化的网络集合,我们改进了 ImageNet 分类上的最佳公布结果:达到4.9% 的前5个验证错误(和 4.8% 的测试错误),超出了人类评估者的准确性。批量标准化也像一个正则化项一样,减少了对其他正则化技术的需求(如本章稍后描述的 dropout).
然而,批量标准化的确会增加模型的复杂性(尽管它不需要对输入数据进行标准化,因为第一个隐藏层会照顾到这一点,只要它是批量标准化的)。 此外,还存在运行时间的损失:由于每层所需的额外计算,神经网络的预测速度较慢。 所以,如果你需要预测闪电般快速,你可能想要检查普通ELU + He初始化执行之前如何执行批量标准化。
注意:
您可能会发现,训练起初相当缓慢,而梯度下降正在寻找每层的最佳缩放和偏移量,一旦找到恰当值,就会加速。
使用 TensorFlow 实现批量标准化
TensorFlow 提供了一个batch_normalization()函数,它简单地对输入进行居中和标准化,但是您必须自己计算平均值和标准差(基于训练期间的小批量数据或测试过程中的完整数据集) 作为这个函数的参数,并且还必须处理缩放和偏移量参数的创建(并将它们传递给此函数)。 这是可行的,但不是最方便的方法。 相反,你应该使用batch_norm()函数,它为你处理所有这些。 您可以直接调用它,或者告诉fully_connected()函数使用它,如下面的代码所示:
注意:本书使用tensorflow.contrib.layers.batch_norm()而不是tf.layers.batch_normalization()(本章写作时不存在)。 现在最好使用tf.layers.batch_normalization(),因为contrib模块中的任何内容都可能会改变或被删除,恕不另行通知。 我们现在不使用batch_norm()函数作为fully_connected()函数的正则化参数,而是使用batch_normalization(),并明确地创建一个不同的层。 参数有些不同,特别是:
-
decay更名为momentum -
is_training被重命名为training -
updates_collections被删除:批量标准化所需的更新操作被添加到UPDATE_OPS集合中,并且您需要在训练期间明确地运行这些操作(请参阅下面的执行阶段) - 我们不需要指定
scale = True,因为这是默认值。
还要注意,为了在每个隐藏层激活函数之前运行批量标准化,我们手动应用 RELU 激活函数,在批量规范层之后。注意:由于tf.layers.dense()函数与本书中使用的tf.contrib.layers.arg_scope()不兼容,我们现在使用 python 的functools.partial()函数。 它可以很容易地创建一个my_dense_layer()函数,只需调用tf.layers.dense(),并自动设置所需的参数(除非在调用my_dense_layer()时覆盖它们)。 如您所见,代码保持非常相似。
import tensorflow as tf
n_inputs = 28 * 28
n_hidden1 = 300
n_hidden2 = 100
n_outputs = 10
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
training = tf.placeholder_with_default(False, shape=(), name='training')
hidden1 = tf.layers.dense(X, n_hidden1, name="hidden1")
bn1 = tf.layers.batch_normalization(hidden1, training=training, momentum=0.9)
bn1_act = tf.nn.elu(bn1)
hidden2 = tf.layers.dense(bn1_act, n_hidden2, name="hidden2")
bn2 = tf.layers.batch_normalization(hidden2, training=training, momentum=0.9)
bn2_act = tf.nn.elu(bn2)
logits_before_bn = tf.layers.dense(bn2_act, n_outputs, name="outputs")
logits = tf.layers.batch_normalization(logits_before_bn, training=training,
momentum=0.9)
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
training = tf.placeholder_with_default(False, shape=(), name='training')
为了避免一遍又一遍重复相同的参数,我们可以使用 Python 的partial()函数:
from functools import partial
my_batch_norm_layer = partial(tf.layers.batch_normalization,
training=training, momentum=0.9)
hidden1 = tf.layers.dense(X, n_hidden1, name="hidden1")
bn1 = my_batch_norm_layer(hidden1)
bn1_act = tf.nn.elu(bn1)
hidden2 = tf.layers.dense(bn1_act, n_hidden2, name="hidden2")
bn2 = my_batch_norm_layer(hidden2)
bn2_act = tf.nn.elu(bn2)
logits_before_bn = tf.layers.dense(bn2_act, n_outputs, name="outputs")
logits = my_batch_norm_layer(logits_before_bn)
完整代码
from functools import partial
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
if __name__ == '__main__':
n_inputs = 28 * 28
n_hidden1 = 300
n_hidden2 = 100
n_outputs = 10
mnist = input_data.read_data_sets("/tmp/data/")
batch_norm_momentum = 0.9
learning_rate = 0.01
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name = 'X')
y = tf.placeholder(tf.int64, shape=None, name = 'y')
training = tf.placeholder_with_default(False, shape=(), name = 'training')#给Batch norm加一个placeholder
with tf.name_scope("dnn"):
he_init = tf.contrib.layers.variance_scaling_initializer()
#对权重的初始化
my_batch_norm_layer = partial(
tf.layers.batch_normalization,
training = training,
momentum = batch_norm_momentum
)
my_dense_layer = partial(
tf.layers.dense,
kernel_initializer = he_init
)
hidden1 = my_dense_layer(X ,n_hidden1 ,name = 'hidden1')
bn1 = tf.nn.elu(my_batch_norm_layer(hidden1))
hidden2 = my_dense_layer(bn1, n_hidden2, name = 'hidden2')
bn2 = tf.nn.elu(my_batch_norm_layer(hidden2))
logists_before_bn = my_dense_layer(bn2, n_outputs, name = 'outputs')
logists = my_batch_norm_layer(logists_before_bn)
with tf.name_scope('loss'):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels = y, logits= logists)
loss = tf.reduce_mean(xentropy, name = 'loss')
with tf.name_scope('train'):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logists, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
init = tf.global_variables_initializer()
saver = tf.train.Saver()
n_epoches = 20
batch_size = 200
# 注意:由于我们使用的是 tf.layers.batch_normalization() 而不是 tf.contrib.layers.batch_norm()(如本书所述),
# 所以我们需要明确运行批量规范化所需的额外更新操作(sess.run([ training_op,extra_update_ops], ...)。
extra_update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.Session() as sess:
init.run()
for epoch in range(n_epoches):
for iteraton in range(mnist.train.num_examples//batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run([training_op,extra_update_ops],
feed_dict={training:True, X:X_batch, y:y_batch})
accuracy_val = accuracy.eval(feed_dict= {X:mnist.test.images,
y:mnist.test.labels})
print(epoch, 'Test accuracy:', accuracy_val)

什么!? 这对 MNIST 来说不是一个很好的准确性。 当然,如果你训练的时间越长,准确性就越好,但是由于这样一个浅的网络,批量范数和 ELU 不太可能产生非常积极的影响:它们大部分都是为了更深的网络而发光。请注意,您还可以训练操作取决于更新操作:
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
extra_update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(extra_update_ops):
training_op = optimizer.minimize(loss)
这样,你只需要在训练过程中评估training_op,TensorFlow也会自动运行更新操作:
sess.run(training_op, feed_dict={training: True, X: X_batch, y: y_batch})
梯度裁剪
减少梯度爆炸问题的一种常用技术是在反向传播过程中简单地剪切梯度,使它们不超过某个阈值(这对于递归神经网络是非常有用的;参见第 14 章)。 这就是所谓的梯度裁剪。一般来说,人们更喜欢批量标准化,但了解梯度裁剪以及如何实现它仍然是有用的。
在 TensorFlow 中,优化器的minimize()函数负责计算梯度并应用它们,所以您必须首先调用优化器的compute_gradients()方法,然后使用clip_by_value()函数创建一个裁剪梯度的操作,最后 创建一个操作来使用优化器的apply_gradients()方法应用裁剪梯度:
threshold = 1.0
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
grads_and_vars = optimizer.compute_gradients(loss)
capped_gvs = [(tf.clip_by_value(grad, -threshold, threshold), var)
for grad, var in grads_and_vars]
training_op = optimizer.apply_gradients(capped_gvs)
像往常一样,您将在每个训练阶段运行这个training_op。 它将计算梯度,将它们裁剪到 -1.0 和 1.0 之间,并应用它们。 threhold是您可以调整的超参数。
复用预训练层
从零开始训练一个非常大的 DNN 通常不是一个好主意,相反,您应该总是尝试找到一个现有的神经网络来完成与您正在尝试解决的任务类似的任务,然后复用这个网络的较低层:这就是所谓的迁移学习。这不仅会大大加快训练速度,还将需要更少的训练数据。
例如,假设您可以访问经过训练的 DNN,将图片分为 100 个不同的类别,包括动物,植物,车辆和日常物品。 您现在想要训练一个 DNN 来对特定类型的车辆进行分类。 这些任务非常相似,因此您应该尝试重新使用第一个网络的一部分(请参见图 11-4)。

如果新任务的输入图像与原始任务中使用的输入图像的大小不一致,则必须添加预处理步骤以将其大小调整为原始模型的预期大小。 更一般地说,如果输入具有类似的低级层次的特征,则迁移学习将很好地工作。
复用 TensorFlow 模型
如果原始模型使用 TensorFlow 进行训练,则可以简单地将其恢复并在新任务上进行训练:
[...] # construct the original model
with tf.Session() as sess:
saver.restore(sess, "./my_model_final.ckpt")
# continue training the model...
完整代码:
n_inputs = 28 * 28 # MNIST
n_hidden1 = 300
n_hidden2 = 50
n_hidden3 = 50
n_hidden4 = 50
n_outputs = 10
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu, name="hidden1")
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu, name="hidden2")
hidden3 = tf.layers.dense(hidden2, n_hidden3, activation=tf.nn.relu, name="hidden3")
hidden4 = tf.layers.dense(hidden3, n_hidden4, activation=tf.nn.relu, name="hidden4")
hidden5 = tf.layers.dense(hidden4, n_hidden5, activation=tf.nn.relu, name="hidden5")
logits = tf.layers.dense(hidden5, n_outputs, name="outputs")
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name="accuracy")
learning_rate = 0.01
threshold = 1.0
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
grads_and_vars = optimizer.compute_gradients(loss)
capped_gvs = [(tf.clip_by_value(grad, -threshold, threshold), var)
for grad, var in grads_and_vars]
training_op = optimizer.apply_gradients(capped_gvs)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess, "./my_model_final.ckpt")
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
accuracy_val = accuracy.eval(feed_dict={X: mnist.test.images,
y: mnist.test.labels})
print(epoch, "Test accuracy:", accuracy_val)
save_path = saver.save(sess, "./my_new_model_final.ckpt")
但是,一般情况下,您只需要重新使用原始模型的一部分(就像我们将要讨论的那样)。 一个简单的解决方案是将Saver配置为仅恢复原始模型中的一部分变量。 例如,下面的代码只恢复隐藏层1,2和3:
n_inputs = 28 * 28 # MNIST
n_hidden1 = 300 # reused
n_hidden2 = 50 # reused
n_hidden3 = 50 # reused
n_hidden4 = 20 # new!
n_outputs = 10 # new!
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu, name="hidden1") # reused
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu, name="hidden2") # reused
hidden3 = tf.layers.dense(hidden2, n_hidden3, activation=tf.nn.relu, name="hidden3") # reused
hidden4 = tf.layers.dense(hidden3, n_hidden4, activation=tf.nn.relu, name="hidden4") # new!
logits = tf.layers.dense(hidden4, n_outputs, name="outputs") # new!
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name="accuracy")
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
[...] # build new model with the same definition as before for hidden layers 1-3
reuse_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES,
scope="hidden[123]") # regular expression
reuse_vars_dict = dict([(var.op.name, var) for var in reuse_vars])
restore_saver = tf.train.Saver(reuse_vars_dict) # to restore layers 1-3
init = tf.global_variables_initializer()
saver = tf.train.Saver()
with tf.Session() as sess:
init.run()
restore_saver.restore(sess, "./my_model_final.ckpt")
for epoch in range(n_epochs): # not shown in the book
for iteration in range(mnist.train.num_examples // batch_size): # not shown
X_batch, y_batch = mnist.train.next_batch(batch_size) # not shown
sess.run(training_op, feed_dict={X: X_batch, y: y_batch}) # not shown
accuracy_val = accuracy.eval(feed_dict={X: mnist.test.images, # not shown
y: mnist.test.labels}) # not shown
print(epoch, "Test accuracy:", accuracy_val) # not shown
save_path = saver.save(sess, "./my_new_model_final.ckpt")
首先我们建立新的模型,确保复制原始模型的隐藏层 1 到 3。我们还创建一个节点来初始化所有变量。 然后我们得到刚刚用trainable = True(这是默认值)创建的所有变量的列表,我们只保留那些范围与正则表达式hidden [123]相匹配的变量(即,我们得到所有可训练的隐藏层 1 到 3 中的变量)。 接下来,我们创建一个字典,将原始模型中每个变量的名称映射到新模型中的名称(通常需要保持完全相同的名称)。 然后,我们创建一个Saver,它将只恢复这些变量,并且创建另一个Saver来保存整个新模型,而不仅仅是第 1 层到第 3 层。然后,我们开始一个会话并初始化模型中的所有变量,然后从原始模型的层 1 到 3中恢复变量值。最后,我们在新任务上训练模型并保存。
任务越相似,您可以重复使用的层越多(从较低层开始)。 对于非常相似的任务,您可以尝试保留所有隐藏的层,只替换输出层。
复用来自其它框架的模型
如果模型是使用其他框架进行训练的,则需要手动加载权重(例如,如果使用 Theano 训练,则使用 Theano 代码),然后将它们分配给相应的变量。 这可能是相当乏味的。 例如,下面的代码显示了如何复制使用另一个框架训练的模型的第一个隐藏层的权重和偏置:
original_w = [...] # Load the weights from the other framework
original_b = [...] # Load the biases from the other framework
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
hidden1 = fully_connected(X, n_hidden1, scope="hidden1")
[...] # # Build the rest of the model
# Get a handle on the variables created by fully_connected()
with tf.variable_scope("", default_name="", reuse=True): # root scope
hidden1_weights = tf.get_variable("hidden1/weights")
hidden1_biases = tf.get_variable("hidden1/biases")
# Create nodes to assign arbitrary values to the weights and biases
original_weights = tf.placeholder(tf.float32, shape=(n_inputs, n_hidden1))
original_biases = tf.placeholder(tf.float32, shape=(n_hidden1))
assign_hidden1_weights = tf.assign(hidden1_weights, original_weights)
assign_hidden1_biases = tf.assign(hidden1_biases, original_biases)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
sess.run(assign_hidden1_weights, feed_dict={original_weights: original_w})
sess.run(assign_hidden1_biases, feed_dict={original_biases: original_b})
[...] # Train the model on your new task
冻结较低层
第一个 DNN 的较低层可能已经学会了检测图片中的低级特征,这将在两个图像分类任务中有用,因此您可以按照原样重新使用这些层。 在训练新的 DNN 时,“冻结”权重通常是一个好主意:如果较低层权重是固定的,那么较高层权重将更容易训练(因为他们不需要学习一个移动的目标)。 要在训练期间冻结较低层,最简单的解决方案是给优化器列出要训练的变量,不包括来自较低层的变量:
train_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES,
scope="hidden[34]|outputs")
training_op = optimizer.minimize(loss, var_list=train_vars)
第一行获得隐藏层 3 和 4 以及输出层中所有可训练变量的列表。 这留下了隐藏层 1 和 2 中的变量。接下来,我们将这个受限制的可列表变量列表提供给optimizer的minimize()函数。现在,层 1 和层 2 被冻结:在训练过程中不会发生变化(通常称为冻结层)。
缓存冻结层
由于冻结层不会改变,因此可以为每个训练实例缓存最上面的冻结层的输出。 由于训练贯穿整个数据集很多次,这将给你一个巨大的速度提升,因为每个训练实例只需要经过一次冻结层(而不是每个迭代一次)。 例如,你可以先运行整个训练集(假设你有足够的内存):
hidden2_outputs = sess.run(hidden2, feed_dict={X: X_train})
然后在训练过程中,不再对训练实例建立批次,而是从隐藏层2的输出建立批次,并将它们提供给训练操作:
import numpy as np
n_epochs = 100
n_batches = 500
for epoch in range(n_epochs):
shuffled_idx = rnd.permutation(len(hidden2_outputs))
hidden2_batches = np.array_split(hidden2_outputs[shuffled_idx], n_batches)
y_batches = np.array_split(y_train[shuffled_idx], n_batches)
for hidden2_batch, y_batch in
zip(hidden2_batches, y_batches):
sess.run(training_op, feed_dict={hidden2: hidden2_batch, y: y_batch})
最后一行运行先前定义的训练操作(冻结层 1 和 2),并从第二个隐藏层(以及该批次的目标)为其输出一批输出。 因为我们给 TensorFlow 隐藏层 2 的输出,所以它不会去评估它(或者它所依赖的任何节点)。
调整,删除或替换较高层
原始模型的输出层通常应该被替换,因为对于新的任务来说,最有可能没有用处,甚至可能没有适合新任务的输出数量。
类似地,原始模型的较高隐藏层不太可能像较低层一样有用,因为对于新任务来说最有用的高层特征可能与对原始任务最有用的高层特征明显不同。 你需要找到正确的层数来复用。
尝试先冻结所有复制的层,然后训练模型并查看它是如何执行的。 然后尝试解冻一个或两个较高隐藏层,让反向传播调整它们,看看性能是否提高。 您拥有的训练数据越多,您可以解冻的层数就越多。
如果仍然无法获得良好的性能,并且您的训练数据很少,请尝试删除顶部的隐藏层,并再次冻结所有剩余的隐藏层。 您可以迭代,直到找到正确的层数重复使用。 如果您有足够的训练数据,您可以尝试替换顶部的隐藏层,而不是丢掉它们,甚至可以添加更多的隐藏层。
Model Zoos
你在哪里可以找到一个类似于你想要解决的任务训练的神经网络? 首先看看显然是在你自己的模型目录。 这是保存所有模型并组织它们的一个很好的理由,以便您以后可以轻松地检索它们。 另一个选择是在模型动物园中搜索。 许多人为了各种不同的任务而训练机器学习模型,并且善意地向公众发布预训练模型。
TensorFlow 在 https://github.com/tensorflow/models 中有自己的模型动物园。 特别是,它包含了大多数最先进的图像分类网络,如 VGG,Inception 和 ResNet(参见第 13 章,检查model/slim目录),包括代码,预训练模型和 工具来下载流行的图像数据集。
另一个流行的模型动物园是 Caffe 模型动物园。 它还包含许多在各种数据集(例如,ImageNet,Places 数据库,CIFAR10 等)上训练的计算机视觉模型(例如,LeNet,AlexNet,ZFNet,GoogLeNet,VGGNet,开始)。 Saumitro Dasgupta 写了一个转换器,可以在 https://github.com/ethereon/caffetensorflow。
无监督的预训练
假设你想要解决一个复杂的任务,你没有太多的标记的训练数据,但不幸的是,你不能找到一个类似的任务训练模型。 不要失去希望! 首先,你当然应该尝试收集更多的有标签的训练数据,但是如果这太难或太昂贵,你仍然可以进行无监督的训练(见图 11-5)。 也就是说,如果你有很多未标记的训练数据,你可以尝试逐层训练层,从最低层开始,然后上升,使用无监督的特征检测算法,如限制玻尔兹曼机(RBM;见附录 E)或自动编码器(见第 15 章)。 每个层都被训练成先前训练过的层的输出(除了被训练的层之外的所有层都被冻结)。 一旦所有层都以这种方式进行了训练,就可以使用监督式学习(即反向传播)对网络进行微调。

这是一个相当漫长而乏味的过程,但通常运作良好。 实际上,这是 Geoffrey Hinton 和他的团队在 2006 年使用的技术,导致了神经网络的复兴和深度学习的成功。 直到 2010 年,无监督预训练(通常使用 RBM)是深度网络的标准,只有在梯度消失问题得到缓解之后,纯训练 DNN 才更为普遍。 然而,当您有一个复杂的任务需要解决时,无监督训练(现在通常使用自动编码器而不是 RBM)仍然是一个很好的选择,没有类似的模型可以重复使用,而且标记的训练数据很少,但是大量的未标记的训练数据。(另一个选择是提出一个监督的任务,您可以轻松地收集大量标记的训练数据,然后使用迁移学习,如前所述。 例如,如果要训练一个模型来识别图片中的朋友,你可以在互联网上下载数百万张脸并训练一个分类器来检测两张脸是否相同,然后使用此分类器将新图片与你朋友的每张照片做比较。)
在辅助任务上预训练
最后一种选择是在辅助任务上训练第一个神经网络,您可以轻松获取或生成标记的训练数据,然后重新使用该网络的较低层来完成您的实际任务。 第一个神经网络的较低层将学习可能被第二个神经网络重复使用的特征检测器。
例如,如果你想建立一个识别面孔的系统,你可能只有几个人的照片 - 显然不足以训练一个好的分类器。 收集每个人的数百张照片将是不实际的。 但是,您可以在互联网上收集大量随机人员的照片,并训练第一个神经网络来检测两张不同的照片是否属于同一个人。 这样的网络将学习面部优秀的特征检测器,所以重复使用它的较低层将允许你使用很少的训练数据来训练一个好的面部分类器。
收集没有标签的训练样本通常是相当便宜的,但标注它们却相当昂贵。 在这种情况下,一种常见的技术是将所有训练样例标记为“好”,然后通过破坏好的训练样例产生许多新的训练样例,并将这些样例标记为“坏”。然后,您可以训练第一个神经网络 将实例分类为好或不好。 例如,您可以下载数百万个句子,将其标记为“好”,然后在每个句子中随机更改一个单词,并将结果语句标记为“不好”。如果神经网络可以告诉“The dog sleeps”是好的句子,但“The dog they”是坏的,它可能知道相当多的语言。 重用其较低层可能有助于许多语言处理任务。
另一种方法是训练第一个网络为每个训练实例输出一个分数,并使用一个损失函数确保一个好的实例的分数大于一个坏实例的分数至少一定的边际。 这被称为最大边际学习.
(第一部分 机器学习基础)
第01章 机器学习概览
第02章 一个完整的机器学习项目(上)
第02章 一个完整的机器学习项目(下)
第03章 分类
第04章 训练模型
第05章 支持向量机
第06章 决策树
第07章 集成学习和随机森林
第08章 降维
(第二部分 神经网络和深度学习)
第9章 启动和运行TensorFlow
第10章 人工神经网络
第11章 训练深度神经网络(上)
第11章 训练深度神经网络(下)
第12章 设备和服务器上的分布式 TensorFlow
第13章 卷积神经网络
第14章 循环神经网络
第15章 自编码器
第16章 强化学习(上)
第16章 强化学习(下)