pySaprk,pycharm编写spark的python脚本,远程上传执行和本地模式执行
上次,我们用scala来编写来spark,这次我们用python来写spark脚本,我们在上篇博客中说过,spark的版本是2.2.0,scala的版本是2.1.x,这样我们在集群中,由于spark的版本,没有办法使用pySpark wordcount.py 来执行脚本,只能使用spark submit wordcount.py来执行脚本,在Linux环境是这样执行的,但是我们写脚本,可以直接在Linux上vim,也可以使用pyCharm或是IDEA,其实pyCharm和IDEA使用的效果是一样的,这里我们就主要讲解下如何使用PyCharm来编写好代码,远程放到Linux主机执行和在Pycharm中本地执行的两种方法。
在讲解两种方法之前,先说明一下我本地的pyCharm不管是运行环境还是远程到Linux主机,用的都是Linux上的解释器进行运行代码的,如果不知道怎么远程配置,可以看下我的博客:https://blog.csdn.net/Jameslvt/article/details/81559459,pycharm远程配置,下面是我本地解释器的截图:

一、本地pyCharm开发,远程上到到Linux配置
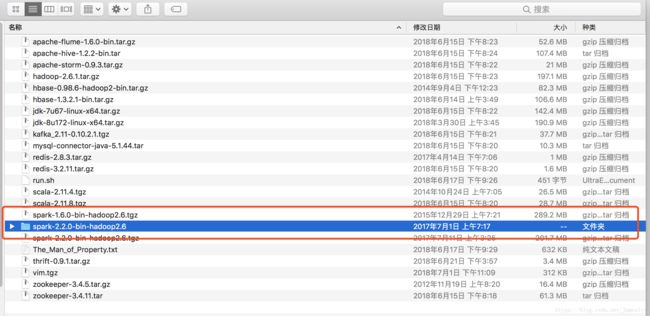
由于我们是在本地开发,并没有Linux环境里面的spark环境和hadoop环境,所以我们需要配置一点东西,首先我们把spark安装包解压到本地,如下:由于我这里是mac,大家解压到D,E盘自己知道的地方即可,为什么要解压这个,因为这个文件夹里面有python文件,python文件下还有两个压缩包py4j-some-version.zip和pyspark.zip,之后会用到
 然后我们来配置pyCharm
然后我们来配置pyCharm
随便打开一个project,pycharm右上角“run”三角形的左边有一个configurition,打开它。

打开后,我们需要做下面三步,
 1、随便加一个python的运行config,填上名称
1、随便加一个python的运行config,填上名称
2、随便选择一个类

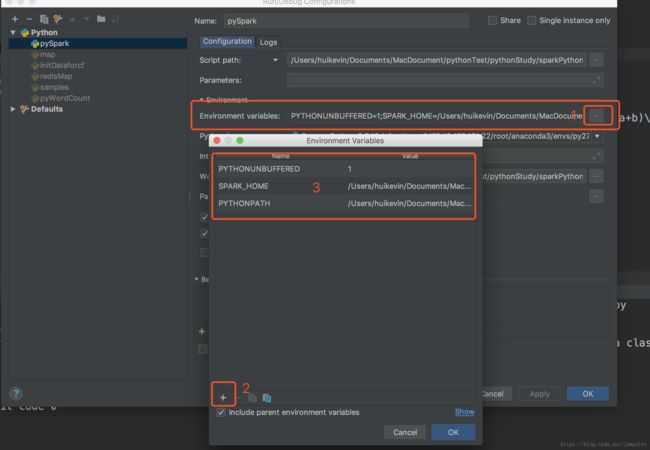
3.这一步比较重要,添加变量,切记不能有空格,出现框框,点击+,输入两个name,一个是SPARK_HOME,另外一个是PYTHONPATH,设置它们的values,SPARK_HOME的value是安装文件夹spark-2.2.0-bin-hadoop2.6的绝对路径,PYTHONPATH的value是该绝对路径+/python,例如我的SPARK_HOME的value是/Applications/spark/spark-2.2.0-bin-hadoop2.6,那么我的PYTHONPATH的value是/Applications/spark/spark-2.1.1-bin-hadoop2.7/python 。设置好了保存。
接下来这一步也比较关键:在perferences中的project structure中点击右边的“add content root”,添加py4j-some-version.zip和pyspark.zip的路径(这两个文件都在Spark中的python文件夹下)

添加好了以后,会在工程里出现两个包:

这样,接下来我们写代码from pyspark import SparkContext,SparkConf 就不会报错了,当我们配置了远程以后,代码会自动上传到远程主机Linux主机,这时候,我们需要在Linux主机进行spark环境变量的配置,也就是修改环境变量:加上sparkhome和python的,其实这里不加python行不行,我没有尝试,大家可以尝试一下,因为我用到anaconda,必须引入这个环境变量,所以大家可以尝试一下,改完记得source一下,生效

环境变量配置完毕,我们可以直接到我们上传的代码那里直接执行代码:
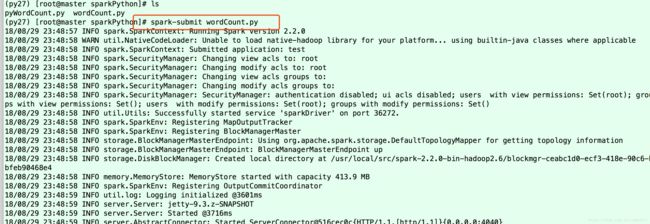
那么远程Linux主机的介绍就到这里,接下来我们说一下在宿主机pyCharm调试
二、在pyCharm或IDEA中调试
这个调试关键是要用到远程的解释器,就是下面这个配置:

我的一切运行都是基于这个配置,要是想直接在本地的控制台调试,只需在代码中加入两个包,也就是我们第一个里面导入的两个包,但是这两个包是Linux环境下的位置,因为我们用的是Linux下的解释器,用远程执行方式的好处就是本地不需要配置那么多复杂的环境量,导致本地乱七八糟的。

然后直接运行即可。
另外,如果大家觉得我这个麻烦,可以看看这篇文章配置:
https://note.youdao.com/share/?id=fb511e558fae98fe6ca2f81d7a55316a&type=note#/