CentOS7搭建hadoop完全分布式集群
集群节点信息
master 192.168.120.10
slave1 192.168.120.11
slave2 192.168.120.12
slave3 192.168.120.13
使用到的资源
Centos7
hadoop-2.7.7
jdk8_201
Xshell6
Xftp6
Virtualbox
日志文件email_log.txt
以上所述资源均已上传至百度云盘共享,可自行获取
链接:https://pan.baidu.com/s/1iD32P1Q4wtXA36eC9JH0OQ
提取码:z71l
复制这段内容后打开百度网盘手机App,操作更方便哦
集群搭建步骤:
进入并查看网卡文件,修改ifcfg-enp0s3和ifcfg-enp0s8网卡文件中的“ONBOOT=no”为“ONBOOT=yes”,设置网卡随虚拟机启动而开启,否则无法连接外网,修改后输入命令“reboot”重启虚拟机


输入命令“yum update”更新一下系统

输入命令“yum install net-tools vim”,安装net-tools和vim工具,以便后续查看IP地址和文本编辑操作

输入命令“ifconfig -a”查看ip地址,记录IP信息:192.168.120.10,后续远程连接虚拟机需要使用
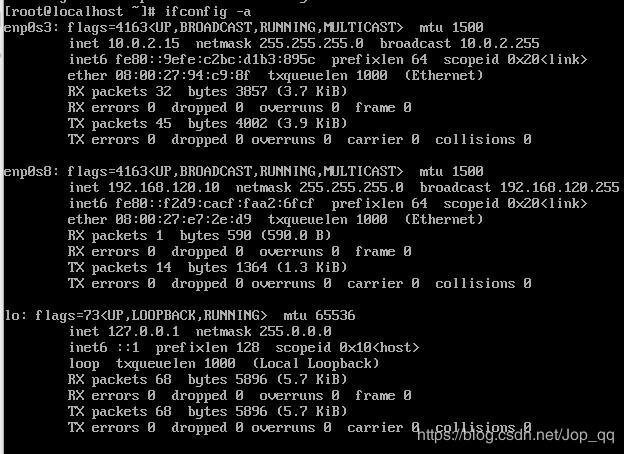
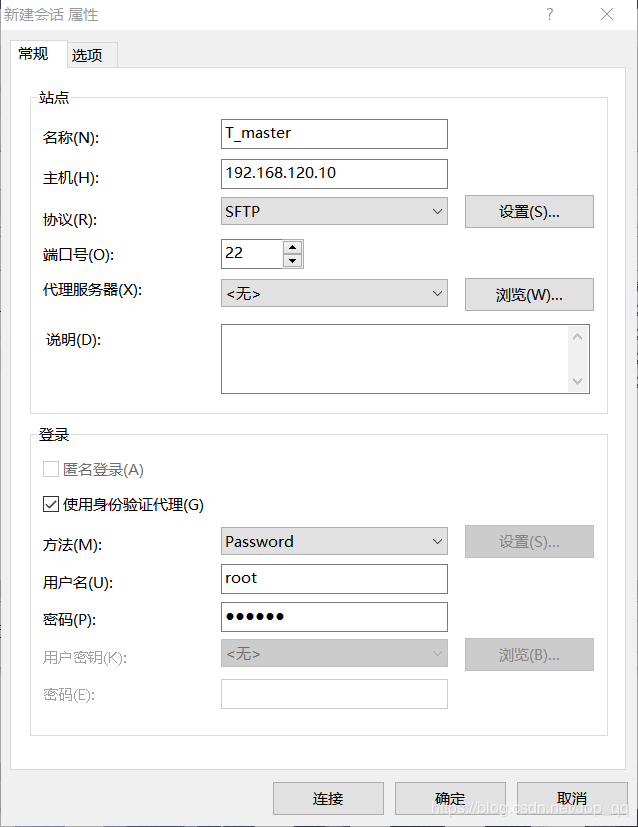
使用Xshell远程连接工具连接master虚拟机,点击“新建”创建虚拟机连接,输入刚刚获取的ip信息

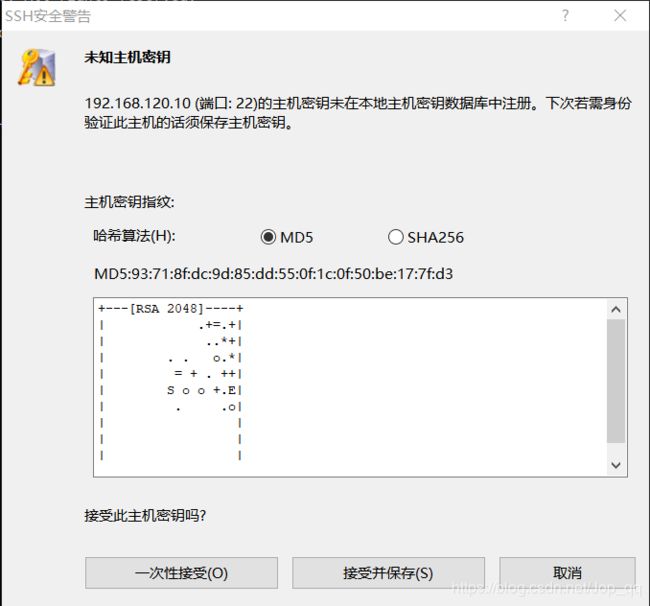
点击左侧列表中的“用户身份验证”,输入虚拟机的用户名和登录密码,然后点击“连接”

选择“接受并保存”
成功连接界面如下

同样,使用Xftp工具远程连接虚拟机,用于本地文件上传到虚拟机文件系统
直接拖拽文件即可实现文件传输,此处将hadoop、jdk安装文件以及测试日志email_log.txt文本文件传输到虚拟机的/opt目录下

进入/opt目录,查看接收的文件,并解压jdk文件

查看解压后的文件,并修改文件名为jdk8

修改java环境配置,保存后输入命令“source ~/.bashrc”令环境配置生效

输入命令“java -version”查看java版本信息,若显示则说明环境配置成功

解压hadoop文件在/opt目录下
![]()
查看并修改解压后的文件名为hadoop

输入命令“cd /opt/hadoop/etc/hadoop”,进入hadoop配置文件目录
修改core-site.xml文件,修改内容如下
fs.defaultFS
hdfs://master:8020
hadoop.tmp.dir
/opt/hadoop_tmp
修改hadoop-env.sh文件,找到JAVA_HOME所在行,修改为jdk安装路径

修改hdfs-site.xml文件,修改内容如下
dfs.namenode.name.dir
file:///opt/hadoop_tmp/hdfs/name
dfs.datanode.data.dir
file:///opt/hadoop_tmp/hdfs/data
dfs.namenode.secondary.http-address
master:50090
dfs.replication
3
修改mapred-site.xml文件,由于mapred-site.xml文件是通过复制mapred-site.xml.template文件得到的
输入命令“cp mapred-site.xml.template mapred-site.xml”即可
修改内容如下
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19888
修改yarn-site.xml文件,修改内容如下
yarn.resourcemanager.hostname
master
yarn.resourcemanager.address
${yarn.resourcemanager.hostname}:8032
yarn.resourcemanager.scheduler.address
${yarn.resourcemanager.hostname}:8030
yarn.resourcemanager.webapp.address
${yarn.resourcemanager.hostname}:8088
yarn.resourcemanager.webapp.https.address
${yarn.resourcemanager.hostname}:8090
yarn.resourcemanager.resource-tracker.address
${yarn.resourcemanager.hostname}:8031
yarn.resourcemanager.admin.address
${yarn.resourcemanager.hostname}:8033
yarn.nodemanager.local-dirs
/opt/hadoop_tmp/yarn/local
yarn.log-aggregation-enable
true
yarn.nodemanager.remote-app-log-dir
/opt/hadoop_tmp/logs
yarn.log.server.url
http://master:19888/jobhistory/logs/
URL for job history server
yarn.nodemanager.vmem-check-enabled
false
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.nodemanager.resource.memory-mb
2048
yarn.scheduler.minimum-allocation-mb
512
yarn.scheduler.maximum-allocation-mb
4096
mapreduce.map.memory.mb
2048
mapreduce.reduce.memory.mb
2048
yarn.nodemanager.resource.cpu-vcores
1
修改yarn-env.sh文件,找到被注释的JAVA_HOME所在行,在下方添加JAVA_HOME路径
![]()
修改slaves文件,修改为如下内容,删除原有的localhost

修改/etc/hosts文件中的IP地址映射,修改内容如下
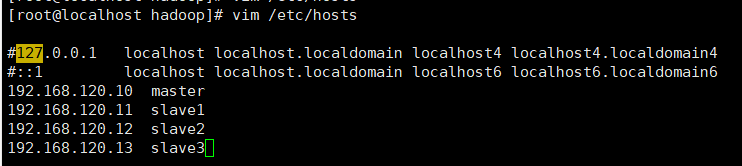
完成以上操作,输入命令“shutdown now”关闭虚拟机,重复以下操作复制出三个子节点虚拟机



启动所有虚拟机,并使用Xshell远程登录所有虚拟机
修改机器名,所有节点都需要改成相应的节点名
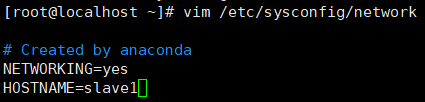
所有虚拟机均执行命令“vim /etc/hostname”,清空原有内容,添加相应主机名字master、slave1、slave2、slave3
修改后输入命令“reboot”重启所有虚拟机,令修改的配置生效,输入命令“ping slave1”测试是否机器名是否修改成功
按Ctrl+C终止ping命令执行

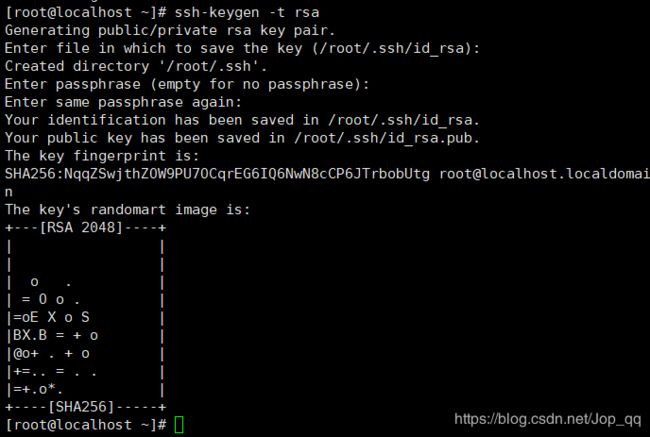
在主节点master上输入命令“ssh-keygen -t rsa”产生公钥与私钥对
依次执行以下命令将主节点master的公钥复制到子节点虚拟机上
ssh-copy-id -i /root/.ssh/id_rsa.pub master
ssh-copy-id -i /root/.ssh/id_rsa.pub slave1
ssh-copy-id -i /root/.ssh/id_rsa.pub slave2
ssh-copy-id -i /root/.ssh/id_rsa.pub slave3
依次验证SSH是否能够免密登录子节点虚拟机

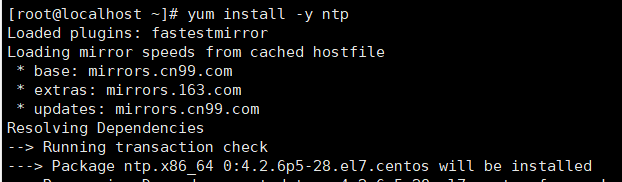
所有虚拟机均输入命令“yum install -y ntp”,下载NTP服务用于同步时间
在主节点master输入命令“vim /etc/ntp.conf”打开/etc/ntp.conf文件,注释掉以server开头的行,并添加如下所示内容:

restrict 192.168.0.0 mask 255.255.255.0 nomodify notrap
server 127.127.1.0
fudge 127.127.1.0 stratum 10
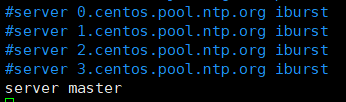
在三个子节点分别输入命令“vim /etc/ntp.conf”打开/etc/ntp.conf文件,注释掉以server开头的行,并添加内容“server master”
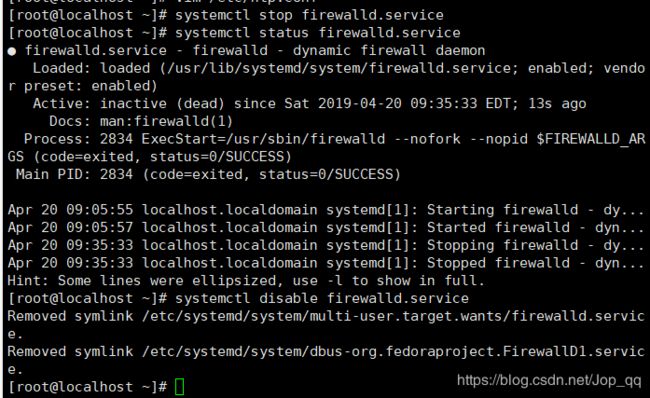
所有虚拟机均永久关闭防火墙
执行关闭命令:
systemctl stop firewalld.service
再次执行查看防火墙命令:
systemctl status firewalld.service
执行开机禁用防火墙自启命令 :
systemctl disable firewalld.service
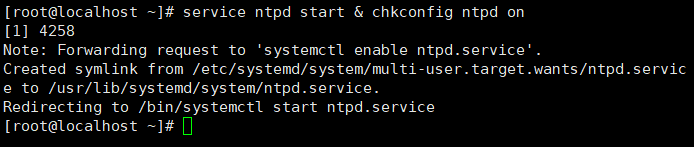
在主节点master执行命令“service ntpd start & chkconfig ntpd on”,如下所示说明成功
service ntpd start & chkconfig ntpd on
在子节点上均执行一遍命令“ntpdate master”,出现如下信息说明时间同步时间成功
ntpdate master

在子节点分别执行命令“service ntpd start & chkconfig ntpd on”,即可永久启动NTP服务
service ntpd start & chkconfig ntpd on

所有虚拟机均执行命令“vim /etc/profile”配置HADOOP_HOME环境变量,修改后执行命令“source /etc/profile”令配置生效,在末尾添加配置内容如下
export HADOOP_HOME=/opt/hadoop
export PATH=$HADOOP_HOME/bin:$PATH:/opt/jdk8/bin
所有虚拟机进入/opt中新建文件夹hadoop_tmp

以下操作均只在主节点master上执行即可
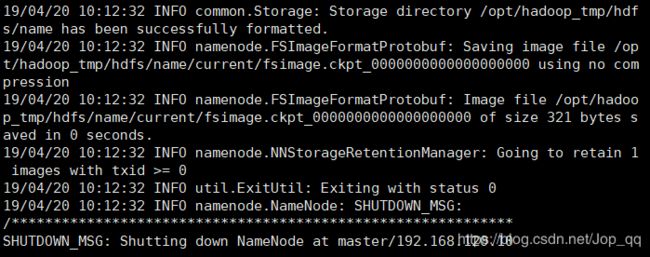
格式化namenode
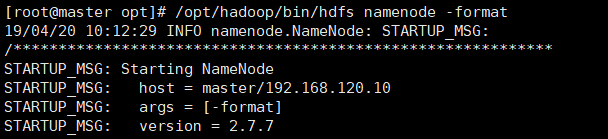
显示如下信息说明格式化成功
启动HDFS和YARN相关服务

启动日志相关服务

查看主节点master的进程信息
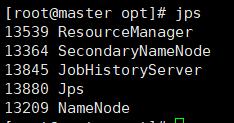
查看子节点的进程信息(在子节点虚拟机执行)

在本地文件夹找到该路径下的hosts文件,修改IP映射文件添加如下内容,以便本地浏览器能够打开hadoop资源监控网站


在浏览器输入网址http://master:50070



在浏览器输入网址http://master:8088


在浏览器输入网址http://master:19888

通过命令行方式查看HDFS信息,输入命令“/opt/hadoop/bin/hdfs dfsadmin -report”即可,如下显示

在hdfs文件系统中新建input文件夹,用于存放测试日志文件email_log.txt
输入命令
/opt/hadoop/bin/hdfs dfs -mkdir /input
 上传在/opt目录下的email_log.txt文件到HDFS文件系统中的input目录下
上传在/opt目录下的email_log.txt文件到HDFS文件系统中的input目录下
执行命令
/opt/hadoop/bin/hdfs dfs -put /opt/email_log.txt /input/

任务一:统计用户登录次数
使用hadoop jar命令提交MapReduce任务,命令如下
/opt/hadoop/bin/hadoop jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /input/email_log.txt /output
执行过程

执行成功结果


执行命令查看部分统计结果
/opt/hadoop/bin/hdfs dfs -tail /output/part-r-00000
 任务作业的详细信息
任务作业的详细信息

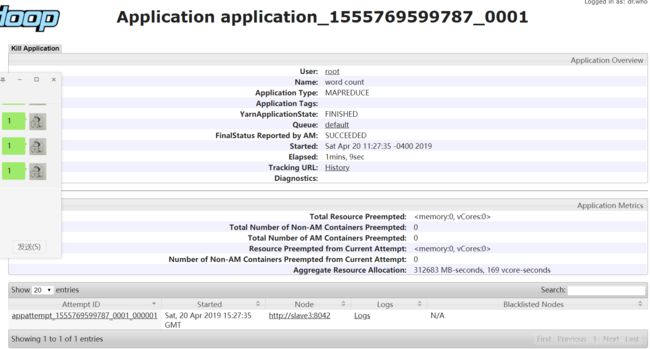
任务二:管理多个MapReduce任务
以执行多个估算PI值的任务管理为例
执行命令
示例作业1:估算PI值
/opt/hadoop/bin/hadoop jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar pi 30 5000
示例作业2:统计用户登录次数
/opt/hadoop/bin/hadoop jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /input/email_log.txt /temp/output_1
上述两个任务执行时,查看集群计算资源的使用情况:
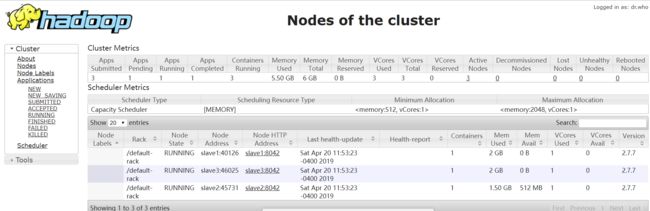
查看执行时,集群上的作业列表

查看作业1的当前状态
选择界面上的选项“Kill Application”,并在弹出的新对话框中,单击“确定”

查看被中断的任务详细信息