爬虫——基于RedisSpider分布式爬取网易新闻:代理池,ua池,selenium加载动态数据,分布式
总结:
先编写普通工程代码再改写。
selenium使用
1、在爬虫文件中,用selenium创建浏览器对象,
2、然后改写下载中间件的process_response方法,通过该方法对下载中间件获取的页面响应内容进行更改,更改成浏览器对象去模拟浏览器获取全部页面之后的内容。
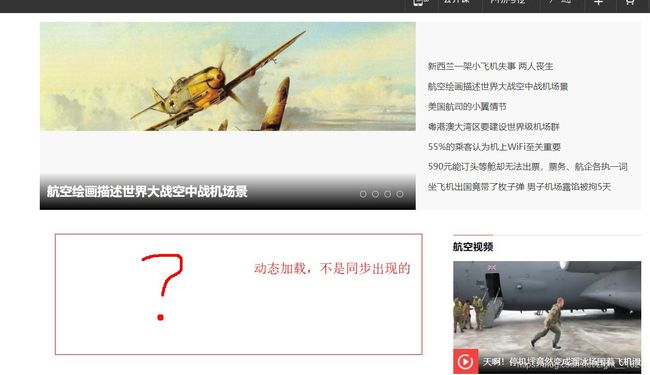
3、进一步发现页面下拉的时候数据还会不断加载,因此在让浏览器再执行一段js代码移动到浏览器底部。
4、settings里中间件去掉注释,发挥作用
代理池和ua池都是在中间件过程修改,注意自定义类需要继承的类。
改写成分布式
更改继承类class WangyiproSpider(RedisSpider):注释掉start_url 添加redis_key =‘wangyi’
注意settings配置和上一篇一致,启动方式也一致
完整代码:
wangyipro.py
import scrapy
import re
from selenium import webdriver
from wangyi.items import WangyiItem
from scrapy_redis.spiders import RedisSpider
class WangyiproSpider(RedisSpider):
name = 'wangyipro'
# allowed_domains = ['www.wangyi.com']
# start_urls = ['https://news.163.com/']
redis_key ='wangyi'
def __init__(self):
# selenium 实例化一个浏览器,爬虫开始时创建,结束时关闭
self.bro=webdriver.Chrome(executable_path='C:/Users/GHL/Desktop/分析/firstdemo/chromedriver')
def close(self,spider):
print('爬虫结束')
self.bro.quit()
def parse(self, response):
# 写了个循环取标签 国内,国际,军事,航空
lis=response.xpath('//div[@class="ns_area list"]/ul/li')
# indexs=[3,4,6,7]
indexs=[3]
li_list=[]
for index in indexs:
li_list.append(lis[index])
# 获取标签链接和文字
for li in li_list:
url=li.xpath('./a/@href').extract_first()
title=li.xpath('./a/text()').extract_first()
# print(url+':'+title) 测试下
# 拿到url之后再次发起请求获取页面数据
yield scrapy.Request(url=url,callback=self.parseSecond,meta={'title':title})
def parseSecond(self,response):
print(response.body)
div_li= response.xpath('//div[contains(@class,"data_row news_article clearfix")]')
# print(len(div_li)) 68
# div_list = response.xpath('//div[@class="data_row news_article clearfix"]')
# print(len(div_list)) 不知道怎么回事就是不行
# 测试下
# print(len(div_list))-----0 ?页面数据是动态加载的,
# 浏览器发送请求可以获取,那需要用selenium实例化一个浏览器对象
# 实例化对象发送请求,获取数据之后,改写中间件下载器的response方法,更改response的页面数据
for div in div_li:
head=div.xpath('.//div[@class="news_title"]/h3/a/text()').extract_first()
url=div.xpath('.//div[@class="news_title"]/h3/a/@href').extract_first()
# imgurl=div.xpath('./a/img/@src') selector
imgurl = div.xpath('./a/img/@src').extract_first()
tags=div.xpath('.//div[@class="news_tag"]//text()').extract()
new_tags=[re.sub('\s','',tag) for tag in tags]
tags = ",".join(new_tags)
# print(head,url,imgurl,tags)
title = response.meta['title']
item = WangyiItem()
item['head'] = head
item['url'] = url
item['imgurl'] = imgurl
item['tags'] = tags
item['title'] = title
yield scrapy.Request(url=url, callback=self.getContent, meta={'item': item})
def getContent(self,response):
item = response.meta['item']
content_list = response.xpath('//div[@class="post_text"]/p/text()').extract()
content = ''.join(content_list)
item['content'] = content
yield item
中间件
from scrapy import signals
import time
from scrapy.http import HtmlResponse
from scrapy.contrib.downloadermiddleware.useragent import UserAgentMiddleware
import random
class WangyiDownloaderMiddleware(object):
# selenium的使用
def process_request(self, request, spider):
# request 响应对象对应的请求对象
# response 响应对象
# spider 爬虫类的实例
if request.url in ['http://news.163.com/domestic/', 'http://news.163.com/world/', 'http://war.163.com/',
'http://news.163.com/air/']:
spider.bro.get(url=request.url)
# 页面下拉到底部,等5秒钟动态数据加载完
js = 'window.scrollTo(0,document.body.scrollHeight)'
spider.bro.execute_script(js)
time.sleep(5)
page_text = spider.bro.page_source
# print(page_text) # 这一步是正确的可以获取到所有的页面数据
# 返回新的响应对象
return HtmlResponse(url=spider.bro.current_url, body=page_text, encoding='utf-8', request=request)
else:
return response
# UA池
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 "
"(KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 "
"(KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 "
"(KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 "
"(KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 "
"(KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 "
"(KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
class RandomUserAgent(UserAgentMiddleware):
def process_request(self, request, spider):
ua = random.choice(user_agent_list)
request.headers.setdefault('User-Agent', ua)
# 代理池
class Proxy(object):
def process_request(self, request, spider):
# 对拦截到请求的url进行判断(协议头到底是http还是https)
# request.url返回值:http://www.xxx.com
h = request.url.split(':')[0] # 请求的协议头
if h == 'https':
ip = random.choice(PROXY_https)
request.meta['proxy'] = 'https://' + ip
else:
ip = random.choice(PROXY_http)
request.meta['proxy'] = 'http://' + ip
PROXY_http = [
'151.106.8.236:8820',
'46.167.206.116:8985',
'113.160.145.185:8955'
]
PROXY_https = [
'111.198.154.116:9030'
]
items.py
import scrapy
class WangyiItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
head = scrapy.Field()
url = scrapy.Field()
imgurl = scrapy.Field()
tags = scrapy.Field()
title = scrapy.Field()
content = scrapy.Field()
settings.py
BOT_NAME = 'wangyi'
SPIDER_MODULES = ['wangyi.spiders']
NEWSPIDER_MODULE = 'wangyi.spiders'
# USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'wangyi (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
DOWNLOADER_MIDDLEWARES = {
'wangyi.middlewares.WangyiDownloaderMiddleware': 543,
'wangyi.middlewares.RandomUserAgent':542,
# 'wangyi.middlewares.Proxy':541 注释掉了网上找的代理ip连不上
}
ITEM_PIPELINES = {
# 'wangyi.pipelines.WangyiPipeline': 300,使用redis执行分布式时需注释掉
'scrapy_redis.pipelines.RedisPipeline':400
}
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 使用scrapy_redis组件的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 是否允许暂停,某台机器出现故障时会从暂停之前的位置开始
SCHEDULER_PERSIST = True
# 配置redis服务器,爬虫文件在其他电脑上运行。
REDIS_PORT = 6379
学习:
https://www.cnblogs.com/foremostxl/p/10098086.html