数据挖掘下的一般步骤与套路
目录
- 1. 前言
- 2. 一般步骤
- Step 1: 明确问题的类型
- Step 2: 数据准备
- 第一步: 时间窗口(Time Window)
- 第二步: 特征工程
- 第三步: 变量评价和筛选
- 第四步: 数据处理(Optial)
- Step 3: 模型训练
- 样本切分
- 模型参数调优
- 不同模型的比较
- Step 4: 模型评估
- KS 和 AUC
- 模型过拟合
- 模型回溯
1. 前言
数据挖掘是当下十分火热的一个职业,几乎各行各业都需要这方面的人才。博主是刚从事数据挖掘工作的一枚小白,此专栏用来记录学习数据挖掘的点点滴滴,希望有助于和我一样小白选手快速入门和避坑,同时欢迎大神指出博文中的错误。
根据博主目前已经参加过的几个建模项目,以及向公司大牛们的请教,愈发发现数据建模工作存在着一些固定的套路,学会这些套路有助于新手更快更好地完成数据挖掘的项目,并能让你在数据挖掘道路上走得更远。
在开始数据建模工作之前,博主其实看了蛮多关于数据挖掘的书籍,以为自己可以 hold 这个职位。但是,真正从事数据建模工作后,可以说只能用 “纸上谈兵” 来形容自己,我甚至搞不清楚在数据建模分为几个阶段,要先做什么后做什么,模型原理更是一知半解。随着自我的学习以及大佬们的指教,慢慢懂得数据挖掘工作一般步骤与套路,熟记这些建模的步骤与讨论,能让你明确当前任务是什么,下一步任务又是什么,每一步任务中应该注意的一些问题。
2. 一般步骤
Step 1: 明确问题的类型
机器学习中最常见的两类问题是有监督学习和无监督学习,关于其概念这里不做非常详细的解释,百度上有很好的博客解释这个概念,后续会有专门一篇博客讲解有监督学习和无监督学习的相关概念,以及都有哪些模型属于有监督学习,哪些模型属于无监督学习,请参考 有监督学习和无监督学习。
首先,需要明确的是需要解决的问题是属于哪一类问题,是有监督学习下的分类问题还是回归问题?还是无监督学习下的聚类问题等。接下来,需要先确定模型的 Target (即 y y y ),也就是你最终想要预测的东西是什么。
本篇博客以最常见的二分类问题,讲述一下建模的一般步骤。
Step 2: 数据准备
在明确了我们需要解决的问题属于哪一类问题之后,我们就可以基本确定使用哪些模型来解决这个问题。既然模型已经确定了,那么我们下一步就需要准备相应的数据来让模型进行训练。
第一步: 时间窗口(Time Window)
首先需要确定数据的时间窗口,我们并不需要拿全部的数据进行模型训练,只需要挑选某些月份的数据来预测下一个月的结果(或者下一天),在进行时间窗口的选择,需要注意哪些月份的数据存在异常,避免模型开发进入到后期阶段,才被别人指出所选择时间窗口的数据在业务上存在着明显的异常,这样就就显得非常尴尬了。
在确定了时间窗口之后,我们需要确定 In-Time 和 Out-of-Time(OOT) ,以及 Validation(val,也可以看作是 oot2) 数据集。这里以 20181001 ~ 20190430 作为我们模型的时间窗口,那么 In-Time 数据集时间窗口可以选用 20181001~20190228,OOT 数据集的时间窗口为 20190301 ~ 20190331,Validation 数据集的时间窗口可以选用 20190401 ~ 20190430。
这里只是初步拟定各个数据集下的时间窗口,在后边变量创建完之后,还需要回过头来填写各个时间窗口下数据集的详细信息(数据量、Target Rate 等),保持一个良好的记录习惯,能让你在初步完成模型开发任务之后,能够很好地回溯整个过程以及发现其中的不足。
第二步: 特征工程
各个时间窗口被确定下来之后,接下来就是创建模型所需要的变量。创建模型的变量也是有迹可循的,一般是常规套路+头脑风暴。
常规套路指的是,通过全方面能描述对象的变量。以用户是否会购买网站会员为例,我们可以将所要创建的变量分为几个大类:
- 用户自身属性(年龄、性别、职业、省份等)
- 用户行为信息(登陆次数、页面停留时长、登陆时间、是否查看过会员页面等)
- 产品信息(产品类型、产品使用时长等)
- 历史信息(历史购买会员次数、上次购买会员的时间等)
- 其他(天气、是否是周末、这个月的第几天等)
根据实际不同的问题,所归纳出来的大类也是不同,但是规则是能通过这些大类的变量能够将对象全面描述出来,并对适当的变量进行向下拆分。此外你可能还需要构建一些衍生变量,衍生变量的创建一般可以通过 RFM(Recency、Frequency、Monetary)、WOE 等方面来构建:
- 时间变量® : 近三天、近一周、近1个月、近3个月、近6个月、近12个月 等
- (频)率变量(F) : 接通率、覆盖率、查看率 等
- 大小变量(M) : 次数(sum)、最大值(max)、最小值(min)、平均值(avg) 等
- 编码变量(WOE) : 金额为连续型变量,可以通过 WOE 编码转换为类别变量,将其映射为 大、中、小 金额段。
头脑风暴则指的是,跳出一般的套路之外,构建一些脑洞大开的变量,这些变量应在业务上就有着非常重要的可能性,并期盼这些变量能够在模型中起到好的效果。
第三步: 变量评价和筛选
变量的工作完成后,需要来评价你所创建的变量效果如何,通常有以下几个手段来进行评价:
- Profiling : 通过查看变量下的 Target Rate(目标响应率),来检验该变量是否具有区分度。有时单变量的分析并不能让你直观地看出该变量与 Target 的关系,这时你需要多变量的交叉分析,即固定某一个变量的类型,查看其他变量与 Target 的关系。
- EDD : 通过 EDD 查看变量整体的表现,可以有效地避免在创建变量时出现人为的错误,还可以检测变量中出现的异常值。常见的 EDD 指标包括: TYPE、VALUE_COUNT、NOMISS、MISS、UNIQUE、MEAN、STD、MIN/TOP1、P1/TOP2、P2/TOP3、P10/TOP4、P25/TOP5、MEDIAN、P75/BOT5、P90/BOT4、P95/BOT3、P99/BOT2、MAX/BOT1。
- 相关性分析 : 有很大可能创建出来的变量中,部分变量存在很强的相关性。对于某些模型你可能并不需要进行变量的相关性分析,例如 LightGBM、XGBoost 等 boosting 算法,但是对于 LR(Logistic Regression)模型,相关性分析确实比不可少的。通过相关性分析,可以减少变量的共线性问题,这也是特征选择中最常见的筛变量的手段,可以通过相关性矩阵( correlation matrics) 来查看该变量与哪些变量具有相关性,其相关系数如何。
- VIF(多重共线性) : 变量之间可能存在多重共线性问题,即一个变量可能与多个变量有关系。比如 v1 变量与 v2~v10 的相关系数值为 value2 ~ value10,你可以将 v1 的 VIF 值理解为 value2 ~ value10 的总和,但其实 VIF 值并不是简简单单的加减,而是有其内在的一套计算逻辑的。一般 VIF <= 2 表示变量的多重共线性不强,但其实 5 ≤ \leq ≤ VIF ≤ \leq ≤ 10 也是可选的,也是需要具体问题具体分析。
- IV 值 : 变量的 iv 值是通过对该变量进行 WOE 变量,评价每个分区内 Target 响应率。一般 iv ≤ \leq ≤ 0.02 就表明该变量在模型中并不会其中很大的作用。
- Missing Rate : 缺失值会对某些模型造成很大的影响,对于缺失率的选择需要根据具体情况具体分析。一般该变量的 Target Rate 还不错,其 Missing Rate 一般取 80% 左右;如果变量的 Target Rate 比较低,Missing Rate 一般取 95% 。对于通过缺失率来进行变量的筛选比较灵活,没有什么特别固定的筛选方法,需要结合变量的变现具体分析。
- FI(Feature Importance,特征重要性) : 评价一个变量在模型中是否重要,可以用过一些集算法来得到,比如 LightGBM 和 XGBoost。比如你有100 个变量,可以先通过 XGBoost 训练得到各变量的 FI,再取 FI 前 Top20 的变量分析其相关性、VIF、IV 等。
- L1(lasso) : 通过 Lasso 训练可以得出变量的一个稀疏矩阵,不重要变量的系数经过训练后得到结果会是 0 ,如果你有 100 个变量经过 Lasso 训练后,可能其中有 40个变量的系数为 0,那么你就可以跳出 60个变量出来。当然,L1 并不是很好用。
- RFE(递归特征消除) : Scikit-Learn 提供了 RFE 包,同时还提供了 RFECV ,通过交叉验证来对特征进行排序。
我们最终的期望是,通过尽可能少的变量来训练模型,并且能让模型达到较好的预测精度。
第四步: 数据处理(Optial)
完成第三步工作之后,有些模型需要对数据进行一定的正则化处理,这一步是可选的,因为有些模型并不需要。常见的正则化操作有以下几种,且 Scikit-Learn 中也提供了相应的包来使用:
| 方法 | 功能 | 简介 |
|---|---|---|
| StandardScaler | 标准化 | 均值-标准差化数据标准化 |
| MaxMinScaler | 标准化 | 极值化法数据标准化 |
| Normalizer | 归一化 | 行记录单位化 |
| Binaizer | 二值化 | 连续变量离散化 |
| OneHotEncoder | 分类编码 | 将定性数据编码为定量数据 |
| Imputer | 缺失值填补 | 缺失值插补 |
| PolynomialFeatures | 多项式变换 | 多项式数据变换 |
Step 3: 模型训练
样本切分
为了提高模型的准确度和泛化能力,需要对 In-Time 数据集进行切分。
- 训练数据(training dataset) : 用于训练模型,IS(In-Sample)
- 验证数据(validation dataset) : 数据对象与训练集相同,用于模型效果评估和调优,OOS(Out-of-Sample)
- 测试数据(test dataset): 数据对象与训练集相同,仅用于模型效果评估
模型参数调优
模型训练的结果与参数的设置也存在很大的关系,合适的参数才能让模型得出接近于最好的效果。如果每次通过人工手动调整模型参数,会花费大量的时间,幸好 Scikit-Learn 提供了 GridSearch(网格搜索),可以一次性设置参数的范围,模型会自动这些参数依次带入模型中进行训练,并得出每组参数组合下的结果,简直就是一神器。
有兴趣的同学可以参考: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html
不同模型的比较
正常来说,不同模型应该分开训练和调优,但是 Scikit-Learn 中也提供了 Pipeline 来一次训练多个模型,并得出不同模型下的预测结果,从而将不同模型一次性进行对比。
有兴趣的同学,可以参考: https://scikit-learn.org/stable/modules/generated/sklearn.pipeline.Pipeline.html
值得一提的是,在 SparkML 中也有 Pipeline 组件,非常好用。但是目前自己在真实建模项目中,还没有用到。
Step 4: 模型评估
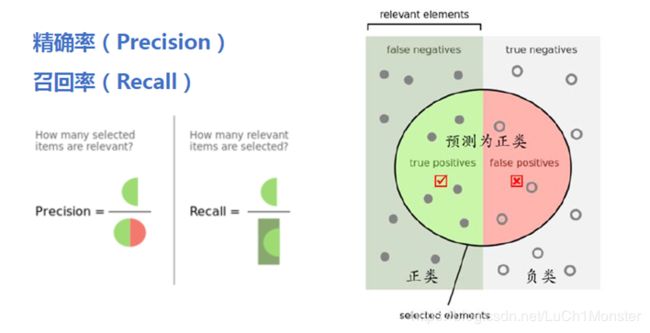
- 召回率(Recall) :样本中的正例有多少被预测准确了,预测对的正例数占真正的正例数的比率,TP / (TP+FN)
- 精准率(Precision) :针对预测结果而言,预测为正的样本有多少是真正的正样本,预测正确的正例数占预测为正例总量的比率, TP / (TP+FP)
- 准确率(Accuracy) :Accuracy=(TP+TN) / (TP+FP+TN+FN)

KS 和 AUC
- AUC(Area Under the ROC Curve) : AUC 值一般在 0.5 到 1之间,值越大模型效果越好。AUC=0.5 表示模型的预测能力与随机结果没有差别。
- KS(Kolmogorov-Smirnov) : KS 表示模型将正负样本区分开来的能力。值越大表示模型的预测能力越好。一般来讲,KS ≥ \ge ≥ 2 即可认为模型有较好的预测准确性。
模型过拟合
模型过拟合在模型开发中很常见,可以采取一些手段和方法来避免过拟合:
- 丰富样本
- 减少选取特征的数量
- 模型参数调优
模型回溯
当完成最终模型的开发,你需要填写如下的表格,作为模型开发的文档。
- SetUp 分析
| 月份 | 总样本 | 正样本 | 目标响应率 |
|---|---|---|---|
| 2018-10 | |||
| 2018-11 | |||
| 2018-12 | |||
| 2019-01 | |||
| 总计 |
- 变量评估
| var_name | 变量说明 | coef(变量的系数) | std err(变量的方差) | z | P>|z| |
[95.0% Conf. Int.] | missrate | IV | VIF | FI | category |
|---|---|---|---|---|---|---|---|---|---|---|---|
- 模型效果图
最后应该模型效果图包括分别在 In-Time(train 和 test) 和OOT 的预测表现。

-
模型变量在 train、test 和 oot 的表现(图)
-
重要变量的 WOE 和 IV 值(图)
-
woe 分 bin 后的矩阵表
-
变量 EDD 结果
-
数据字典