【Spark实战】慕课网日志分析(二):数据二次清洗之日志解析
笔记目录:
【Spark实战】慕课网日志分析(一):数据初步清洗
【Spark实战】慕课网日志分析(二):数据二次清洗之日志解析
【Spark实战】慕课网日志分析(三):清理后数据的存储、统计和入库
【Spark实战】慕课网日志分析(四):将数据清洗的作业提交到YARN上运行
【Spark实战】慕课网日志分析(五):将数据统计和入库的作业提交到YARN上运行
项目需求:
- 统计最受欢迎的课程/手记的Top N访问次数
- 按地市统计最受欢迎的Top N课程 – 根据ip地址提取出城市信息
- 按流量统计最受欢迎的Top N课程
输入:访问时间、访问url、耗费的流量、访问ip
输出:url、cmsType(video/article)、cmsId、流量、ip、城市信息、访问时间、天
第一步:读取数据
新建一个类SparkStatCleanJob.scala,先打印10条记录看看:
object SparkStatCleanJob {
def main(args: Array[String]) {
val spark = SparkSession.builder().appName("SparkStatCleanJob")
.config("spark.sql.parquet.compression.codec","gzip")
.master("local[2]").getOrCreate()
val accessRDD = spark.sparkContext.textFile("./access.log")
accessRDD.take(10).foreach(println)
spark.stop
}
}

第二步:实现日志转换工具类,完成RDD到DF的转换
1.实现日志转换的工具类:AccessConvertUtil.scala
package com.imooc.log
import org.apache.spark.sql.Row
import org.apache.spark.sql.types.{LongType, StringType, StructField, StructType}
/**
* 访问日志转换(输入==>输出)工具类
*/
object AccessConvertUtil {
//定义的输出的字段
val struct = StructType(
Array(
StructField("url",StringType),
StructField("cmsType",StringType),
StructField("cmsId",LongType),
StructField("traffic",LongType),
StructField("ip",StringType),
StructField("city",StringType),
StructField("time",StringType),
StructField("day",StringType)
)
)
/**
* 根据输入的每一行信息转换成输出的样式
* @param log 输入的每一行记录信息
*/
def parseLog(log:String) = {
try{
val splits = log.split("\t")
val url = splits(1)
val traffic = splits(2).toLong
val ip = splits(3)
val domain = "http://www.imooc.com/" //去掉这一段固定的字符串
val cms = url.substring(url.indexOf(domain) + domain.length)
val cmsTypeId = cms.split("/")
var cmsType = ""
var cmsId = 0l
if(cmsTypeId.length > 1) { //判空,因为不一定存在
cmsType = cmsTypeId(0)
cmsId = cmsTypeId(1).toLong
}
// val city = IpUtils.getCity(ip)
val city = ""
val time = splits(0)
val day = time.substring(0,10).replaceAll("-","") //去掉横杠
//这个row里面的字段要和struct中的字段对应上
Row(url, cmsType, cmsId, traffic, ip, city, time, day)
} catch {
case e:Exception => Row(0)
}
}
}
2.SparkStatCleanJob.scala中调用上述转换工具类并打印输出
object SparkStatCleanJob {
...
accessRDD.take(10).foreach(println)
//RDD ==> DF的转换
val accessDF = spark.createDataFrame(accessRDD.map(x => AccessConvertUtil.parseLog(x)),
AccessConvertUtil.struct) //1
accessDF.printSchema()
accessDF.show(false)
spark.stop
}
}
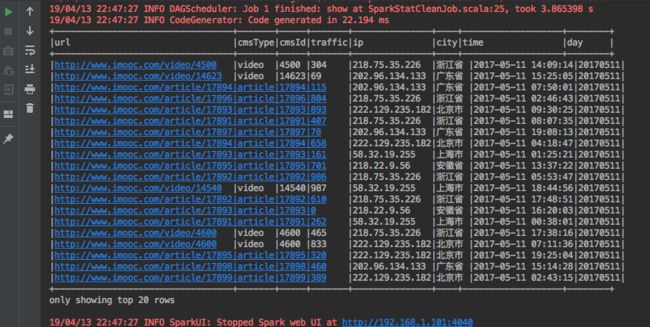
输出结果:
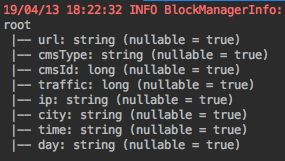
注意:city字段直接赋值空字符串,city字段的信息是空的。
第三步:ip地址解析
- 克隆github上面的项目:ipdatabase
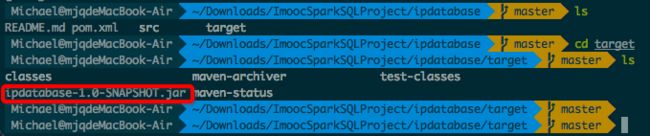
git clone https://github.com/wzhe06/ipdatabase.git - 进入项目文件夹,编译github上面的项目,得到jar包
mvn clean package -DskipTests
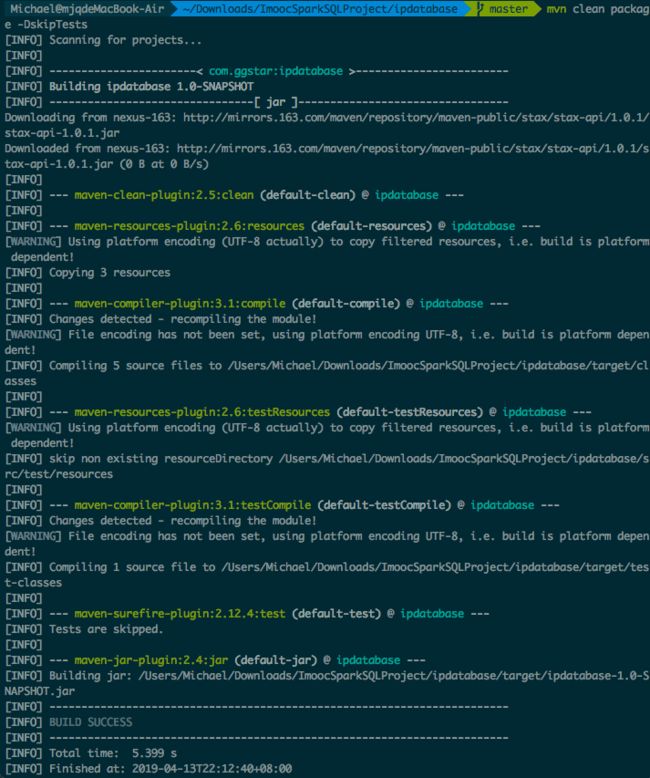
编译出来的jar包文件名为 ipdatabase-1.0-SNAPSHOT.jar
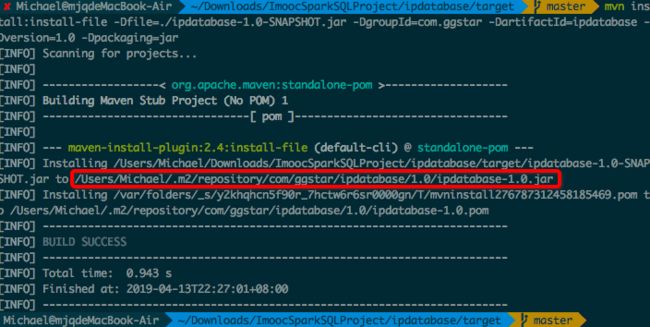
- 安装jar包到自己的maven仓库
mvn install:install-file -Dfile=./ipdatabase-1.0-SNAPSHOT.jar -DgroupId=com.ggstar -DartifactId=ipdatabase -Dversion=1.0 -Dpackaging=jar
4.实现ip地址解析工具类IpUtils:
package com.imooc.log
import com.ggstar.util.ip.IpHelper
/**
* IP解析工具类
*/
object IpUtils {
def getCity(ip:String) = {
IpHelper.findRegionByIp(ip)
}
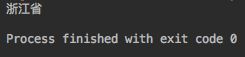
def main(args: Array[String]) {
println(getCity("218.75.35.226"))
}
}
右键测试效果:
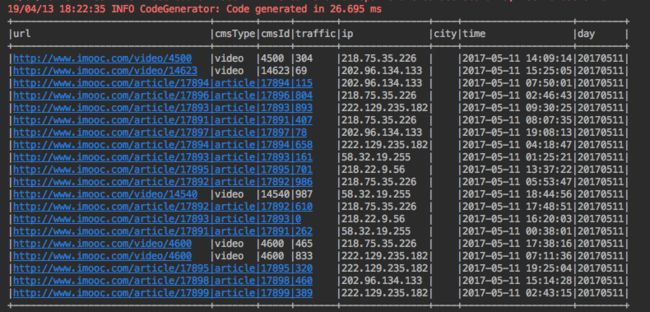
- AccessConvertUtil.scala中调用我们的IpUtils工具类
...
val city = IpUtils.getCity(ip)
...
最终结果: