Hive-函数篇
引言
Hive是基于hadoop的数据仓库工具,能够将一张结构化的数据文件映射为一张数据库表。以便于在Hive中通过类似于传统sql(Hive中我们叫hql)做数据分析等工作。Hive默认计算模型是MapperReduce,将hql转换成MR任务进行计算;在Hive中还有Hive on Spark的模式,这里仅做了解。本文主要是在工作中使用Hive的时候,对一些用到的函数进行记录,以便后续查阅,也供其他同学们参考及互相交流知识。
函数
1、first_value():取分组排序后,当前行的第一个值。
常用于:首次消费门店,首次消费类字段
last_value():取分组排序后,当前行的最后一个值
常用于:最近消费门店,最近消费类字段
- 数据准备
shop_order.txt
001,耐克,2019-06-01
002,安踏,2019-06-01
003,李宁,2019-06-02
001,阿迪达斯,2019-06-03
001,李宁,2019-06-05
002,耐克,2019-06-05
003,耐克,2019-06-05
004,乔丹,2019-06-05- hive建表
create table shop_order(
zvip string,
shopname string,
orderdate string
) row format delimited fields terminated by ',';
我这里在测试的时候,将orderdate的数据类型设置为date,但在做查询的时候报错:Underlying error: Primitve type DATE not supported in Value Boundary expression;暂把orderdate类型设置为string类型,仅做了个简单的建表。- 导入数据
hive -e "load data local inpath 'shop_order.txt' into table shop_order"- hql执行函数示例
执行语句1:
select zvip, --会员编号
orderdate,--订单时间
shopname,--门店名称
row_number() over(partition by zvip order by orderdate asc), --开窗函数对分组进行排序
first_value(shopname) over(partition by zvip order by orderdate),-- 首次消费门店,取第一个值
last_value(shopname) over(partition by zvip order by orderdate) -- 最近消费门店,取最后一个值
from shop_order;
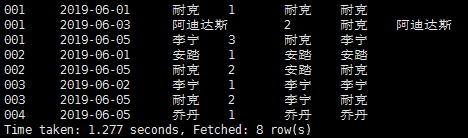
结果:
结果分析:可以看到last_value()中的值都不相同,通过查度娘发现last_value()默认统计范围是 rows between unbounded preceding and current row;对语句进行改造。
执行语句2:
select zvip, --会员编号
orderdate,--订单时间
shopname,--门店名称
row_number() over(partition by zvip order by orderdate asc), --开窗函数对分组进行排序
first_value(shopname) over(partition by zvip order by orderdate),-- 首次消费门店,取第一个值
last_value(shopname) over(partition by zvip order by orderdate rows between unbounded preceding and unbounded following) -- 最近消费门店,取最后一个值
from shop_order;
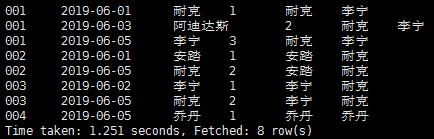
结果:
去掉时间:
结果分析:可以看到添加rows between unbounded preceding and unbounded following后,返回结果接近需要的结果(会员的首次消费门店、最近消费门店),但是此处存在重复记录;可通过group by 语句去重。改造结果如下:
执行语句3:
select zvip,fv,lv from(
select zvip, --会员编号
orderdate,--订单时间
shopname,--门店名称
row_number() over(partition by zvip order by orderdate asc), --开窗函数对分组进行排序
first_value(shopname) over(partition by zvip order by orderdate) fv,-- 首次消费门店,取第一个值
last_value(shopname) over(partition by zvip order by orderdate rows between unbounded preceding and unbounded following) lv -- 最近消费门店,取最后一个值
from shop_order) x
group by zvip,fv,lv;
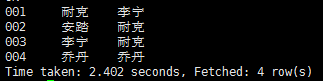
结果:
结果分析:通过group by去重得出预期结果,但其中会生成2个job,执行时间也相对增加了。

2、collect_set():列转行函数,将相同key,同一列不同value的值转成一行并去重,返回数组格式数据;
collect_list():列转行函数,将相同key,同一列不同value的值转成一行不去重,返回数组格式数据;
- 数据准备
shop_order.txt
001,耐克,2019-06-01
002,安踏,2019-06-01
003,李宁,2019-06-02
001,阿迪达斯,2019-06-03
001,李宁,2019-06-05
002,耐克,2019-06-05
002,安踏,2019-06-08 (新增一条记录)
003,耐克,2019-06-05
004,乔丹,2019-06-05
【其他步骤同上】- hql执行函数示例
执行语句1:
select zvip,collect_set(shopname) from shop_order group by zvip;
结果:
结果分析:通过collect_set()是对shopname值进行了去重的。
执行语句2:
select zvip,collect_list(shopname) from shop_order group by zvip;
结果:
结果分析:通过collect_list()可知在002会员中shopname的“安踏”出现了两次。如果有开发经验的人可以知道set和list的区别,就很容易区分这两个函数了。


3、explode(列表数据):行转列函数,单独使用的时候仅能返回一列的列表中的数据。
lateral view explode(列表数据):lateral view 与explode配合使用,能返回其他字段结果的罗列数据。
示例数据:
示例1(explode):
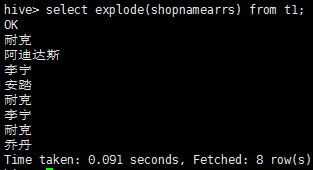
select explode(shopnamearrs) from t1;
这样执行只能得到shopname结果,如果想知道zvip却无法如此操作:
select zvip,explode(shopnamearrs) from t1;
报错:UDTF's are not supported outside the SELECT clause, nor nested in expressions
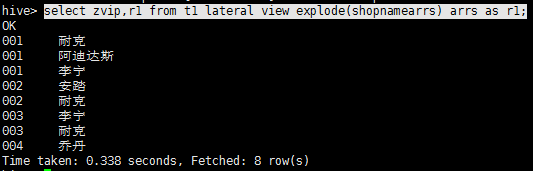
示例2(lateral view explode):
select zvip,r1 from t1 lateral view explode(shopnamearrs) arrs as r1;


4、concat(str1,str2,str3...):用于将多个函数连接成一个字符串,如果连接中有NULL值,则返回NULL。
示例1:
select concat(zvip,',',shopname) from shop_order;
示例2:
select concat(zvip,',',shopname,NULL) from shop_order;


5、concat_ws(separator,str1,str2,…) :concat()的特殊形式,第一个参数是其他参数的分隔符,分隔符的位置放在要连接的两个字符之间。分隔符可以是一个字符串。如果分隔符为NULL,则结果返回NULL。如果分隔字符有NULL值,则返回实际拼接结果。
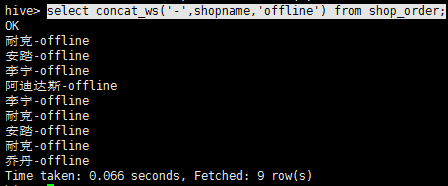
示例1:
select concat_ws('-',shopname,'offline') from shop_order;
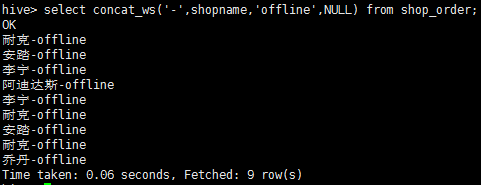
示例2:
select concat_ws('-',shopname,'offline',NULL) from shop_order;
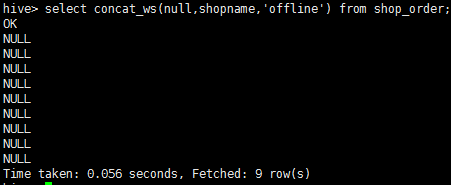
示例3:
select concat_ws(null,shopname,'offline') from shop_order;
6、unix_timestamp()、unix_timestamp(STRING date)、unix_timestamp(STRING date,STRING pattern)
返回本地时间当前时间搓,date默认格式 yyyy-MM-dd hh:mm:ss,可通过pattern设置时间格式。
示例1:
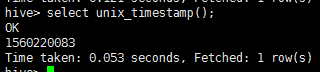
select unix_timestamp();
示例2:
select unix_timestamp('2019-06-11 10:10:10');
示例3:
select unix_timestamp('20190611','yyyyMMdd');


7、from_unixtime(BIGINT unixtime[,STRING format]) 将时间搓秒数转换成UTC时间
示例:
select from_unixtime(unix_timestamp('20190611' ,'yyyymmdd'), 'yyyy-mm-dd');

8、to_date(string date) :返回时间字符串日期部分
示例:
select to_date("1993-01-01 00:12:12");

9、CAST(
cast (null as string)
10、get_json_object(string jsonstr,String parseAtt) :用来解析json字符串的一个字段。
示例:
select get_json_object('{"zvip":"001","shopname":"李宁","orderDate":"2019-06-11"}','$.zvip'),
get_json_object('{"zvip":"001","shopname":"李宁","orderDate":"2019-06-11"}','$.shopname'),
get_json_object('{"zvip":"001","shopname":"李宁","orderDate":"2019-06-11"}','$.orderDate');

11、json_tuple(string jsonstr,string str1,string str2,...):用来解析Json字符串的多个字段。
示例:
select b.zvip,b.shopname,b.orderDate from t1 lateral view json_tuple('{"zvip":"001","shopname":"李宁","orderDate":"2019-06-11"}','zvip','shopname','orderDate') b as zvip,shopname,orderDate;
这里仅做了一个json字符串的示例,json_tuple()和get_json_object()这两个函数常用于解析埋点数据上,一般会将json格式的字符串数据存在表中,通过获取表的字段去解析。

12、 COALESCE(T v1, T v2, …) :返回第一个非NULL值,如果全部为NULL,则返回NULL。 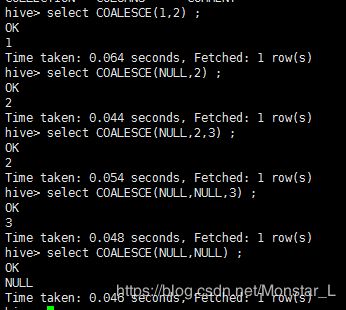
13、datediff(string enddate,string startdate) 返回endDate和startDate相差的天数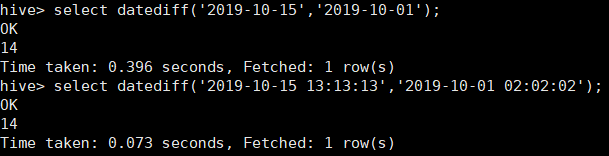

初步验证了下,datediff函数只是简单天相减,与小时无关。