VC++学习——2
目录
编译器生成默认构造函数的情况
函数重载
this指针
子类调用父类的自定义构造函数
三种继承方式及三种访问权限
友元
多重继承
多态
函数的覆盖、隐藏、重载
引用
类的设计习惯及头文件重复包含的解决
C文件操作
C/C++标准库函数数字与字符串之间转换
C++文件操作
1、编译器生成默认构造函数的情况
三种情况:
- 如果类有虚拟成员函数或虚基类时
- 如果类的基类有构造函数(可以是自定义的构造函数,或者是编译器提供的默认构造函数)
- 类中所有非静态的对象数据成员,他们所属的类中有构造函数(可以是自定义的构造函数,或者是编译器提供的默认构造函数)
2、函数重载
- 重载的条件:
函数的参数类型、参数个数不同
函数的返回值类型可以不同 - 如下例子不能构成函数重载
void output()
int output()
////////////////////////////
void output(int a,int b=5)
void output(int a)
3、this指针
- 一个类的所有成员调用的成员函数都属于一个代码段,那么成员函数怎么区分不同对象的数据成员呢?
this指针解决了这个问题,成员函数有一个隐含的参数接收了对象的地址被this指针所获取,等同于this=&pt
this指针只能在类的函数中使用,可以访问所有访问权限的成员变量
4、子类调用父类的自定义构造函数
class Father
{
public:
Father(int a,int b)
{
cout<<"Father Constructor"<在构造函数的参数列表后面使用:也可以初始化成员变量,使用逗号隔开,如果多继承,也可以用逗号隔开分别调用多个父类的构造函数
5、三种继承方式及三种访问权限
- private,public,protected方法的访问范围.(public继承下)
private: 只能由该类中的函数、其友元函数访问,不能被任何其他访问,该类的对象也不能访问.
protected: 可以被该类中的函数、子类的函数、以及其友元函数访问,但不能被该类的对象访问
public: 可以被该类中的函数、子类的函数、其友元函数访问,也可以由该类的对象访问
注:友元函数包括两种:设为友元的全局函数,设为友元类中的成员函数 - 默认集成方式:private
- public继承基类
基类的成员在派生类仍以原来的访问权限出现在派生类中 - protected继承基类
基类的成员public和protected成员在派生类中变成了protected - private继承基类
基类的成员在派生类中变成了private
| A类(基类) | B类(A的派生类) | C类(B的派生类) | |
|---|---|---|---|
| 公有继承 | 公有成员 | 公有成员 | 公有成员 |
| 公有继承 | 私有成员 | (无) | (无) |
| 公有继承 | 保护成员 | 保护成员 | 保护成员 |
| 私有继承 | 公有成员 | 私有成员 | (无) |
| 私有继承 | 私有成员 | (无) | (无) |
| 私有继承 | 保护成员 | 私有成员 | (无) |
| 保护继承 | 公有成员 | 保护成员 | 保护成员 |
| 保护继承 | 私有成员 | (无) | (无) |
| 保护继承 | 保护成员 | 保护成员 | 保护成员 |
6、友元
有些情况下,允许特定的非成员函数访问一个类的私有成员,同时仍阻止一般的访问,这是很方便做到的。例如被重载的操作符,如输入或输出操作符,经常需要访问类的私有数据成员。
友元(frend)机制允许一个类将对其非公有成员的访问权授予指定的函数或者类,友元的声明以friend开始,它只能出现在类定义的内部,友元声明可以出现在类中的任何地方:友元不是授予友元关系的那个类的成员,所以它们不受其声明出现部分的访问控制影响。通常,将友元声明成组地放在类定义的开始或结尾是个好主意。
- 友元函数
友元函数是指某些虽然不是类成员函数却能够访问类的所有成员的函数。类授予它的友元特别的访问权,这样该友元函数就能访问到类中的所有成员。
#include
using namespace std;
class A
{
public:
friend void set_show(int x, A &a); //该函数是友元函数的声明
private:
int data;
};
void set_show(int x, A &a) //友元函数定义,为了访问类A中的成员
{
a.data = x;
cout << a.data << endl;
}
int main(void)
{
class A a;
set_show(1, a);
return 0;
}
- 友元类
友元类的所有成员函数都是另一个类的友元函数,都可以访问另一个类中的隐藏信息(包括私有成员和保护成员)。当希望一个类可以存取另一个类的私有成员时,可以将该类声明为另一类的友元类。
关于友元类的注意事项:
(1) 友元关系不能被继承。
(2) 友元关系是单向的,不具有交换性。若类B是类A的友元,类A不一定是类B的友元,要看在类中是否有相应的声明。
(3) 友元关系不具有传递性。若类B是类A的友元,类C是B的友元,类C不一定是类A的友元,同样要看类中是否有相应的申明。
#include
using namespace std;
class A
{
public:
friend class C; //这是友元类的声明
private:
int data;
};
class C //友元类定义,为了访问类A中的成员
{
public:
void set_show(int x, A &a) { a.data = x; cout< - 友元成员函数
使类B中的成员函数成为类A的友元函数,这样类B的该成员函数就可以访问类A的所有成员了。
当用到友元成员函数时,需注意友元声明和友元定义之间的相互依赖,在该例子中,类B必须先定义,否则类A就不能将一个B的函数指定为友元。然而,只有在定义了类A之后,才能定义类B的该成员函数。更一般的讲,必须先定义包含成员函数的类,才能将成员函数设为友元。另一方面,不必预先声明类和非成员函数来将它们设为友元。
友元小结:
在需要允许某些特定的非成员函数访问一个类的私有成员(及受保护成员),而同时仍阻止一般的访问的情况下,友元是可用的。
优点:
可以灵活地实现需要访问若干类的私有或受保护的成员才能完成的任务;
便于与其他不支持类概念的语言(如C语言、汇编等)进行混合编程;
通过使用友元函数重载可以更自然地使用C++语言的IO流库。
缺点:
一个类将对其非公有成员的访问权限授予其他函数或者类,会破坏该类的封装性,降低该类的可靠性和可维护性。
回到目录
7、多重继承
- 多重继承的初始化会按照基类表中的顺序进行初始化
- 多重继承的析构按照基类表中的顺序反向调用析构函数
回到目录
8、多态
- 使用虚函数实现多态
class duotaiBase
{
public:
void out()
{
cout<<"Base out"<out();
return 0;
}
结果:

分析: C++是强类型语言,在编译阶段进行了自动类型转换,将duotaiChild对象转换为duotaiBase对象,所以调用的就是基类的out函数
- 使用虚函数实现多态,virtual关键字的申明的函数就是虚函数
修改上述代码
class duotaiBase
{
public:
virtual void out()
{
cout<<"Base out"<out();
return 0;
}
结果:
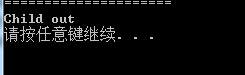
分析: 之前说过virtual关键字可以放在前面,也可以放在中间,使用虚函数的时候会采用迟邦定(late binding)技术,运行时确定调用哪个函数,这种能力就叫做C++的多态性。没有采用虚函数的叫做早期绑定(early binding)技术。
- 纯虚函数
class chunxv
{
public:
virtual void out()=0;
};
含有纯虚函数的类叫做抽象类,不能实例化(声明对象),只是作为基类为派生类服务。抽象类的派生类必须完全实现基类的纯虚函数,否则派生类也变成了抽象类,不能实例化。
- 多态是由虚函数实现的,不是纯虚函数实现的
- 派生类虚函数的参数名、返回值、参数列表必须与基类的完全相同
回到目录
9、函数的覆盖、隐藏、重载
- 覆盖
构成覆盖的条件:
基类函数必须是虚函数
发生覆盖的两个函数要分别在基类和派生类中
函数的参数名和参数列表完全相同 - 隐藏
派生类具有与基类同名的函数
区别于覆盖:没有virtual
区别于重载:在不同类中,重载必须在同一个类中
只要派生类和基类的某一个函数名相同但参数列表不同,那么不管该函数有没有virtual关键字,派生类函数都将隐藏基类的函数 - 区分覆盖和隐藏
首先重载一定是发正在同一类中的。然后覆盖一定是发生在基类和派生类之间,且函数完全相同,而且是虚函数,其他的情况就是隐藏。
回到目录
10、引用
- 必须在声明时初始化
- 引用一旦初始化就代表一块特定的内存,再也无法代表其他内存
- 引用的地址就是所引用的变量或对象的地址
- 指针的地址所指向的内存内容是一个地址(所保存的地址)
- 适用场景:参数传递过程中使用到实参所指向的内存,防止传值时造成赋值占用较大内存
int a=10;
bool b=true;
int &c=a;
bool &d=b;
cout<回到目录
11、类的设计习惯及头文件重复包含的解决
- 头文件放类的定义及成员函数的声明
- 源文件放成员函数的实现
- 包含main函数的源文件中只需包含各类的头文件,编译器会自动到实现了该类的成员函数的源文件中寻找类的实现
- 防止重复包含头文件
使用宏
#ifndef xxxx
#define xxxx
......
......
......
#endif
回到目录
12、C文件操作
C语言文件操作是利用FILE结构体进行的
-
打开
FILE * fopen(const char * filename,const char * mode)
//filename文件名,mode打开模式
| 文件打开模式 | 意义 |
| r | 只读,若文件不存在或不能找到,函数调用失败,返回NULL |
| w | 只写,如果文件存在,则它的内容将被清空(相当于删除原文件,创建一个空的新文件),若文件不存在,则创建一个空文件 |
| a | 以“追加”的方式打开文件,若文件不存在,则创建文件;若文件存在,则在文件末尾写入数据,原数据保留 |
| r+ | 以“读写”方式打开文件,文件必须存在,否则打开失败,删除原有数据 |
| w+ | “写入/更新”相当于‘w’和‘r+’,文件不存在则创建文件;存在清空原有内容 |
| a+ | “追加/更新”,相当于‘a’和‘r+’,可以读也可以追加,文件不存在时创建文件;文件存在时追加写入 |
总结: r,r+,分别为读和读写,都无法创建文件;
w,w+,分别为写和读写,可以创建文件,但清除原来内容;
只有a,a+能进行追加写入,分别为追加和追加读写,可以创建文件。
在w模式下,fwrite会覆盖原位置的数据
在a模式下,fwrite不会覆盖原位置数据,但是会在文件末尾追加要写入的数据,及时当前文件指针不在末尾。
所以说文件所有的操作都是按照模式的风格来进行的
-
写入
size_t fwrite(const void * buffer,size_t size,size_t count,FILE * stream);
//buffer要写入的数据,size以字节为单位的数据项大小,count数据项的个数,stream文件
//size_t是unsigned int类型
-
文件指针定位
int fseek(FILE * stream,long offset,int origin);
//offset偏移量,origin文件指针的起始位置
//SEEK_CUR当前位置,SEEK_END结尾处,SEEK_SET开始处
-
文件的关闭
fclose(FILE * stream);
-
读取
size_t fread(void * buffer,size_t size,size_t count,FILE * stream);
//buffer指向内存中缓冲区的指针,其他参数与fwrite相同
注意: 要在buffer的读取的内容后一位加上字符串终止符’\0’有三种方法分别为:1.也可以在写入文件时在数据最后一位加上终止符’\0’,这样读取文件的时候会将该终止符读进来;2.也可以使用memset函数对缓冲区进行初始化void memset(void * s,int c,unsigned int n);//c初始化的字符,用整数代替;n字符串的前n位进行初始化,memset(buffer,0,strlen(buffer));3.获取文件长度len,构造缓冲区大小为len+1,最后一位设为’\0’。
-
获取文件长度
将文件指针移到文件末尾,调用ftell函数获得当前位置与文件开始位置之间的便宜字节数
long ftell(FILE * stream);
具体操作如下:
FILE * pFile=fopen("test.txt","r");
fseek(pFile,0,SEEK_END);
int len=ftell(pFile);
-
fflush函数
跟写入有关,读会直接读到指定的缓冲区。
-
C语言对文件的操作使用了缓冲文件系统
系统自动的为每个正在使用的文件在内存中开辟了一块缓冲区域,写入数据时会先送到内存缓冲区,待缓冲区满、调用fflush函数、文件关闭时,就会将缓冲区的数据送到磁盘上的文件中。
同理读数据时,先将数据读入内存缓冲区,待缓冲区满,再讲数据从该缓冲区送到程序的数据区。
注意: 读操作用r或r+模式打开的文件指针,写操作用w或w+模式打开的文件指针,追加操作用a或a+模式打开的文件指针,不然会发生fflush后fread不到新内容的情况。
-
rewind函数
rewind(FILE * stream);//跳到文件开始处
-
C对文件操作的注意事项
字符串终止符
文件指针的位置
-
二进制文件和文本
windows下enter是 /r/n,unix下是/n,mac下是/r。
当文件已文本模式打开时,会将ASCII码0X0A(十进制10)的换行符转换为’\r\n’写入文件中。当以二进制模式打开时,就只会讲’\n’写入文件中。
以二进制模式打开文件时,只需在模式中加字符’b’即可,例如,“rb”,“wb”,“rb+”,“wb+”,“ab”,“ab+”
由于文本方式和二进制方式在读取和写入文件时有差异,所以在读取和写入文件时要保持一致
-
Intel的机器采用小端存储数据,little endian
回到目录
13、C/C++标准库函数数字与字符串之间转换
1.int/float to string/array:
C语言提供了几个标准库函数,可以将任意类型(整型、长整型、浮点型等)的数字转换为字符串,下面列举了各函数的方法及其说明。
● itoa():将整型值转换为字符串。
● ltoa():将长整型值转换为字符串。
● ultoa():将无符号长整型值转换为字符串。
● gcvt():将浮点型数转换为字符串,取四舍五入。
● ecvt():将双精度浮点型值转换为字符串,转换结果中不包含十进制小数点。
● fcvt():指定位数为转换精度,其余同ecvt()。
char*itoa(int value,char*string,int radix);
char *ltoa(long value,char *string,int radix)
char *ultoa(unsigned long value, char *string, int radix);
除此外,还可以使用sprintf系列函数把数字转换成字符串,其比itoa()系列函数运行速度慢
gcvt()函数:
头文件:#include
定义函数:
char *gcvt(double number, size_t ndigits, char *buf);
//number待转换数,ndigits有效位个数,buf存储字符串
//返回值为buf地址
#include
main(){
double a = 123.45;
double b = -1234.56;
char *ptr;
int decpt, sign;
gcvt(a, 5, ptr);
printf("a value=%s\n", ptr);
ptr = gcvt(b, 6, ptr);
printf("b value=%s\n", ptr);
}
结果:
a value=123.45
b value=-1234.56
ecvt()函数:
功 能:将双精度浮点型数转换为字符串,转换结果中不包括十进制小数点。
用 法:
char *ecvt(double value, int ndigit, int *decpt, int *sign);
//value待转化数,ndigit有效位个数,*decpt小数点所在位数(从左数第decpt位后加入小数点)
//*sign正负号,0表示整数,1表示负数
//返回值指向生成的字符串
详细解释:ecvt函数把一个双精度浮点数转换成一个字符串。value参数是要转换的浮点数。这个函数存储最多ndigit个数字值作为一个字符串,并添加一个空数字符(’\0’),如果value中的数字个数超过ndigit,低位数字被舍入。如果少于ndigit个数字,该字符串用0填充。
只有数字才存储在该字符串中,小数点位置和value符号在调用之后从decpt和sign获取。decpt参数指出给出小数点位置的整数值, 它是从该字符串的开头位置计算的。0或负数指出小数点在第一个数字的左边。sign参数指出一个指出转换的数的符号的整数。如果该整数为0,这个数为正数,否则为负数。
fcvt()函数
函数名:fcvt
功 能:把一个浮点数转换为字符串
char *fcvt(double value, int ndigit, int *decpt, int *sign);
//ndigit表示小数点后面的位数,其余与ecvt函数参数相同
#include
#include
#include
int main(void)
{
char *string;
double value;
int dec, sign;
int ndig = 10;
//clrscr();
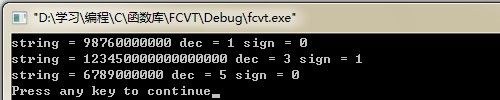
value = 9.876;
string = fcvt(value, ndig, &dec, &sign);
printf("string = %s dec = %d sign = %d\n", string, dec, sign);
value = -123.45;
ndig= 15;
string = fcvt(value,ndig,&dec,&sign);
printf("string = %s dec = %d sign = %d\n", string, dec, sign);
value = 0.6789e5; /* scientific notation */
ndig = 5;
string = fcvt(value,ndig,&dec,&sign);
printf("string = %s dec = %d sign = %d\n", string, dec, sign);
return 0;
}
结果:
2. string/array to int/float
C/C++语言提供了几个标准库函数,可以将字符串转换为任意类型(整型、长整型、浮点型等)。
● atof():将字符串转换为双精度浮点型值。
● atoi():将字符串转换为整型值。
● atol():将字符串转换为长整型值。
● strtod():将字符串转换为双精度浮点型值,并报告不能被转换的所有剩余数字。
● strtol():将字符串转换为长整值,并报告不能被转换的所有剩余数字。
● strtoul():将字符串转换为无符号长整型值,并报告不能被转换的所有剩余数字。
double atof(const char *nptr);
int atoi(const char *nptr);
long atol(const char *nptr);
double strtod(const char *nptr,char **endptr);
函数说明
strtod()会扫描参数nptr字符串,跳过前面的空格字符,直到遇上数字或正负符号才开始做转换,到出现非数字或字符串结束时(’\0’)才结束转换,并将结果返回。若endptr不为NULL,则会将遇到不合条件而终止的nptr中的字符指针由endptr传回。参数nptr字符串可包含正负号、小数点或E(e)来表示指数部分。如123.456或123e-2。
long int strtol(const char *nptr,char **endptr,int base);
unsigned long strtoul(const char *nptr,char **endptr,int base);
回到目录
14、C++文件操作
#include
ofstream //文件写操作 内存写入存储设备
ifstream //文件读操作,存储设备读区到内存中
fstream //读写操作,对打开的文件可进行读写操作
查看源码构造函数如下:
ofstream(const char * szName,int nMode=ios::out,int nProt=(int)ios_base::_Openprot);
//nMode打开文件方式,nProt打开文件属性
ifstream(const char * szName,int nMode=ios::in,int nProt=(int)ios_base::_Openprot);
//nMode打开文件方式,nProt打开文件属性
一般在使用时只填写第一个参数,需要指定文件打开方式或属性,使用fstream类
fstream(const char * szName,int nMode=ios::in|ios::out,int nProt=(int)ios_base::_Openprot);
//nMode打开文件方式,nProt打开文件属性
- 打开文件方式
ios::in 为输入(读)而打开文件
ios::out 为输出(写)而打开文件
ios::ate 初始位置:文件尾
ios::app 所有输出附加在文件末尾
ios::trunc 如果文件已存在则先删除该文件
ios::binary 二进制方式
- 文件保护机制
0 普通文件,打开操作
1 只读文件
2 隐含文件
4 系统文件 - ios::app和ios::ate区别
| 文件流 | ios::app | ios::ate | ||
| 打开方式 | 结果 | 打开方式 | 结果 | |
| ofstream (默认是ios::in | ios::trunc) |
ios::app或ios::app|ios::out | 如果没有文件,生成空文件; 如果有文件,在文件尾追加 |
ios::ate或ios::ate|ios::out | 如果没有文件,生成空文件; 如果有文件,清空该文件 |
| ios::app|ios::in | 不管有没有文件,都是失败 | ios::ate|ios::in | 如果没有文件,打开失败; 如果有文件,定位到文件尾,可以写文件,但是不能读文件 |
|
| Ifstream (默认是ios::in) |
ios::app或ios::app|ios::out | 不管有没有文件,都是失败 | ios::ate或ios::ate|ios::out | 如果没有文件,打开失败; 如果有文件,定位到文件尾,但是不能写文件 |
| ios::app|ios::in | ? | ios::ate|ios::in | ? | |
| fstream (默认是ios::in | ios::out) |
ios::app|ios::out | 如果没有文件,创建文件; 如果有文件,在文件尾追加 |
ios::ate|ios::out | 如果没有文件,创建文件; 如果有,清空文件 |
| ios::app|ios::in | 如果没有文件,失败 | ios::ate|ios::in | 如果没有文件,失败 | |
| N/A | N/A | ios::ate|ios::out|ios::in | 如果没有文件,打开失败, 如果有文件,定位到文件尾 |
|
| 总结 | ios::app不能和ios::in相配合,但可以和ios::out配合,打开输入流 | ios::ate可以和ios::in配合,此时定位到文件尾; 如果没有ios::in相配合而只是同ios::out配合,那么将清空原文件; |
||
| 区别 | app会在每次写操作之前都把写指针置于文件末尾, | 而ate模式则只在打开时才将写指针置于文件末尾。在文件操作过程中,可以通过seekp等操作移动指针位置。 | ||
| 例子: 多个线程或者进程对一个文件写的时候,假如文件原来的内容是abc |
以ios::app: 第一个线程(进程)往里面写了个d,第二个线程(进程)写了个e的话,结果是abcde |
以ios:ate: 后面写的会覆盖前面一个写的,第一个线程(进程)往里面写了个d,第二个线程(进程)写了个e的话,结果为abce |
||
- 打开文件
//fstream类中的open函数,ofstream,ifstream,fstream类对象都可以调用这个函数
void __CLR_OR_THIS_CALL open(const wchar_t *_Filename,
ios_base::openmode _Mode = ios_base::in | ios_base::out,
int _Prot = (int)ios_base::_Openprot);
//默认打开方式是in和out
- 关闭文件
成员函数close - 是否打开
bool __CLR_OR_THIS_CALL is_open() const;
- 文本模式下的读写
ofstream out("test.txt");
if(out.is_open())
{
out<<"hello";//运算符重载<<,输出
}
out.close();
ifstream in("test.txt");
char buffer[256];
if(in.is_open())
{
while(!in.eof())
{
in.getline(buffer,100);//使用getline读取一行,尽量避免使用cin,无法控制输出缓冲区
cout<- 一些其他成员函数
除了eof()以外,还有一些验证流的状态的成员函数(所有都返回bool型返回值):
bad()
如果在读写过程中出错,返回 true 。例如:当我们要对一个不是打开为写状态的文件进行写入时,或者我们要写入的设备没有剩余空间的时候。
fail()
除了与bad() 同样的情况下会返回 true 以外,加上格式错误时也返回true ,例如当想要读入一个整数,而获得了一个字母的时候。
eof()
如果读文件到达文件末尾,返回true。
good()
这是最通用的:如果调用以上任何一个函数返回true 的话,此函数返回 false 。
要想重置以上成员函数所检查的状态标志,你可以使用成员函数clear(),没有参数。
获得和设置流指针(get and put stream pointers)
所有输入/输出流对象(i/o streams objects)都有至少一个流指针:
ifstream, 类似istream, 有一个被称为get pointer的指针,指向下一个将被读取的元素。
ofstream, 类似 ostream, 有一个指针 put pointer ,指向写入下一个元素的位置。
fstream, 类似 iostream, 同时继承了get 和 put
我们可以通过使用以下成员函数来读出或配置这些指向流中读写位置的流指针:
tellg() 和 tellp()
这两个成员函数不用传入参数,返回pos_type 类型的值(根据ANSI-C++ 标准) ,就是一个整数,代表当前get 流指针的位置 (用tellg) 或 put 流指针的位置(用tellp).
seekg() 和seekp()
这对函数分别用来改变流指针get 和put的位置。两个函数都被重载为两种不同的原型:
seekg ( pos_type position );
seekp ( pos_type position );
使用这个原型,流指针被改变为指向从文件开始计算的一个绝对位置。要求传入的参数类型与函数 tellg 和tellp 的返回值类型相同。
seekg ( off_type offset, seekdir direction );
seekp ( off_type offset, seekdir direction );
使用这个原型可以指定由参数direction决定的一个具体的指针开始计算的一个位移(offset)。它可以是:
ios::beg 从流开始位置计算的位移
ios::cur 从流指针当前位置开始计算的位移
ios::end 从流末尾处开始计算的位移
流指针 get 和 put 的值对文本文件(text file)和二进制文件(binary file)的计算方法都是不同的,因为文本模式的文件中某些特殊字符可能被修改。由于这个原因,建议对以文本文件模式打开的文件总是使用seekg 和 seekp的第一种原型,而且不要对tellg 或 tellp 的返回值进行修改。对二进制文件,你可以任意使用这些函数,应该不会有任何意外的行为产生。
以下例子使用这些函数来获得一个二进制文件的大小
// obtaining file size
#include
#include
const char * filename = "test.txt";
int main () {
long l,m;
ifstream in(filename, ios::in|ios::binary);
l = in.tellg();
in.seekg (0, ios::end);
m = in.tellg();
in.close();
cout << "size of " << filename;
cout << " is " << (m-l) << " bytes.\n";
return 0;
}
//结果:
size of example.txt is 40 bytes.
- 二进制文件
在二进制文件中,使用<< 和>>,以及函数(如getline)来操作符输入和输出数据,没有什么实际意义,虽然它们是符合语法的。
文件流包括两个为顺序读写数据特殊设计的成员函数:write 和 read。第一个函数 (write) 是ostream 的一个成员函数,都是被ofstream所继承。而read 是istream 的一个成员函数,被ifstream 所继承。类 fstream 的对象同时拥有这两个函数。它们的原型是:
write ( char * buffer, streamsize size );
read ( char * buffer, streamsize size );
这里 buffer 是一块内存的地址,用来存储或读出数据。参数size 是一个整数值,表示要从缓存(buffer)中读出或写入的字符数。
// reading binary file
#include
#include
const char * filename = "test.txt";
int main () {
char * buffer;
long size;
ifstream in (filename, ios::in|ios::binary|ios::ate);
size = in.tellg();
in.seekg (0, ios::beg);
buffer = new char [size];
in.read (buffer, size);
in.close();
cout << "the complete file is in a buffer";
delete[] buffer;
return 0;
}
//运行结果:
The complete file is in a buffer
- 缓存和同步(Buffers and Synchronization)
当我们对文件流进行操作的时候,它们与一个streambuf 类型的缓存(buffer)联系在一起。这个缓存(buffer)实际是一块内存空间,作为流(stream)和物理文件的媒介。例如,对于一个输出流, 每次成员函数put (写一个单个字符)被调用,这个字符不是直接被写入该输出流所对应的物理文件中的,而是首先被插入到该流的缓存(buffer)中。
当缓存被排放出来(flush)时,它里面的所有数据或者被写入物理媒质中(如果是一个输出流的话),或者简单的被抹掉(如果是一个输入流的话)。这个过程称为同步(synchronization),它会在以下任一情况下发生:
当文件被关闭时: 在文件被关闭之前,所有还没有被完全写出或读取的缓存都将被同步。
当缓存buffer 满时:缓存Buffers 有一定的空间限制。当缓存满时,它会被自动同步。
控制符明确指明:当遇到流中某些特定的控制符时,同步会发生。这些控制符包括:flush 和endl。
out<明确调用函数sync(): 调用成员函数sync() (无参数)可以引发立即同步。这个函数返回一个int 值,等于-1 表示流没有联系的缓存或操作失败。
ifstream用sync()清空缓冲区
ofstrem用flush()向硬件写入
回到目录