tensorflow实现正则化 来避免训练过拟合
- L1 和 L2 正则化
- 用tf.contrib.layers.l1_regularizer
- 用dropout做正则化
- Max-norm 正则化
L1 和 L2 正则化
对神经网络中之后连接权重做限制,比如对只有一个隐层的神经网络做L1正则:
reset_graph()
n_inputs = 28 * 28 # MNIST
n_hidden1 = 300
n_outputs = 10
learning_rate = 0.01
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu, name="hidden1")
logits = tf.layers.dense(hidden1, n_outputs, name="outputs")
W1 = tf.get_default_graph().get_tensor_by_name("hidden1/kernel:0")
W2 = tf.get_default_graph().get_tensor_by_name("outputs/kernel:0")
scale = 0.001 # l1正则化参数
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y,
logits=logits)
base_loss = tf.reduce_mean(xentropy, name="avg_xentropy")
reg_loss = tf.reduce_sum(tf.abs(W1)) + tf.reduce_sum(tf.abs(W2))
loss = tf.add(base_loss, scale * reg_loss, name="loss")
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits,y,1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name="accuracy")
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
init = tf.global_variables_initializer()
saver = tf.train.Saver()训练:
n_epochs = 20
batch_size = 200
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op, feed_dict={X:X_batch, y:y_batch})
accuracy_val = accuracy.eval(feed_dict={X:mnist.test.images,
y: mnist.test.labels})
print(epoch, "Test accuracy:", accuracy_val)
save_path = saver.save(sess,"./my_model_fianl.ckpt")输出:
0 Test accuracy: 0.8348
1 Test accuracy: 0.8709
2 Test accuracy: 0.8824
3 Test accuracy: 0.8911
4 Test accuracy: 0.8952
5 Test accuracy: 0.8984
6 Test accuracy: 0.9022
7 Test accuracy: 0.9024
8 Test accuracy: 0.9046
9 Test accuracy: 0.906
10 Test accuracy: 0.9063
11 Test accuracy: 0.9074
12 Test accuracy: 0.9083
13 Test accuracy: 0.9073
14 Test accuracy: 0.9066
15 Test accuracy: 0.9077
16 Test accuracy: 0.9065
17 Test accuracy: 0.907
18 Test accuracy: 0.9068
19 Test accuracy: 0.9067用tf.contrib.layers.l1_regularizer
添加正则项到每个层中,用partial来做:
reset_graph()
n_inputs = 28 * 28 # MNIST
n_hidden1 = 300
n_hidden2 = 50
n_outputs = 10
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
scale = 0.001
from functools import partial构建自己的神经网络,用l1做默认的正则化:
收集正则化损失tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
my_dense_layer = partial(tf.layers.dense,activation=tf.nn.relu,
kernel_regularizer=tf.contrib.layers.l1_regularizer(scale))
with tf.name_scope("dnn"):
hidden1 = my_dense_layer(X, n_hidden1, name="hidden1")
hidden2 = my_dense_layer(hidden1, n_hidden2,name="hidden2")
logits = my_dense_layer(hidden2, n_outputs,activation=None,name="outputs")
# 把正则化损失加上
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y,logits=logits)
base_loss = tf.reduce_mean(xentropy,name="avg_xentropy")
#收集正则化损失
reg_loss = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
# tf.add_n: Adds all input tensors element-wise.
# 参数inputs: A list of `Tensor` objects, each with same shape and type.
loss = tf.add_n([base_loss] + reg_loss,name="loss")
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct,tf.float32),name="accuracy")
learning_rate = 0.01
with tf.name_scope("train"):
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
training_op = optimizer.minimize(loss)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
n_epochs = 20
batch_size = 200
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op, feed_dict={X:X_batch,y:y_batch})
accuracy_val = accuracy.eval(feed_dict={X:mnist.test.images,
y:mnist.test.labels})
print(epoch, "Test accuracy:", accuracy_val)
save_path = saver.save(sess,"./my_model+final.ckpt")
输出:
0 Test accuracy: 0.8331
1 Test accuracy: 0.8789
2 Test accuracy: 0.892
3 Test accuracy: 0.9008
4 Test accuracy: 0.9061
5 Test accuracy: 0.91
6 Test accuracy: 0.9119
7 Test accuracy: 0.915
8 Test accuracy: 0.915
9 Test accuracy: 0.9181
10 Test accuracy: 0.9178
11 Test accuracy: 0.9187
12 Test accuracy: 0.9181
13 Test accuracy: 0.9198
14 Test accuracy: 0.9188
15 Test accuracy: 0.9194
16 Test accuracy: 0.9183
17 Test accuracy: 0.917
18 Test accuracy: 0.9179
19 Test accuracy: 0.9178
用dropout做正则化
思想:在每一个training step,每一个神经元都有一个概率 p p 表示这个神经元暂时被“退学”,也就是梯度不会在这里更新,丢失掉这个神经元,但是在下一次training step又会有概率 1−p 1 − p 被激活。
理解dropout:在每一次training step过后,都会形成一个新的神经网络,因为每一次都有不同的神经元被丢弃,那全部可能的神经网络是 2N 2 N ,这里 N N 等于被drop的神经元个数,所以出现同一个神经网络概率极小,假设training step=10000,那就等于我们训练个10000个不同的神经网络,他们之间彼此不同却又相似(共享许多权重参数),所以dropout可以看做是每一个小的神经网络的集成。
注: p=0.5 p = 0.5 时,在测试(testing)过程中,一个神经元将连接到训练期间输入神经元数量的两倍(平均),因为一半神经元丢掉了,为了补偿,我们需要在训练后将每个神经元的输入连接权乘以0.5。所以一般在训练结束后,我们需要将每个输入连接权乘以概率 (1−p) ( 1 − p ) ,或者,我们可以将每个神经元的输出除以概率 (1−p) ( 1 − p ) 。
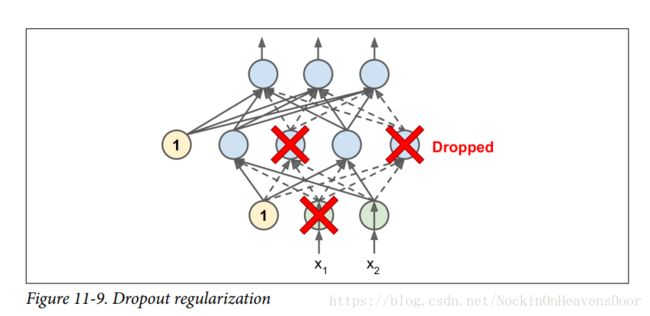
代码:
reset_graph()
X = tf.placeholder(tf.float32,shape=(None,n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
#作为函数的参数training
training = tf.placeholder_with_default(False, shape=(),name="training")
dropout_rate = 0.5
# training设为了变量参数
X_drop = tf.layers.dropout(X, dropout_rate, training=training)
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X_drop, n_hidden1, activation=tf.nn.relu,
name="hidden1")
hidden1_drop = tf.layers.dropout(hidden1, dropout_rate, training=training)
hidden2 = tf.layers.dense(hidden1_drop, n_hidden2, activation=tf.nn.relu,
name="hidden2")
hidden2_drop = tf.layers.dropout(hidden2, dropout_rate, training=training)
logits = tf.layers.dense(hidden2_drop, n_outputs, activation=None, name="outputs")
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y,logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
with tf.name_scope("train"):
optimizer = tf.train.MomentumOptimizer(learning_rate,momentum=0.9)
training_op = optimizer.minimize(loss)
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits,y,1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32), name="accuracy")
init = tf.global_variables_initializer()
saver = tf.train.Saver()
n_epochs = 20
batch_size = 50
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op,feed_dict={X:X_batch, y:y_batch})
acc_test = accuracy.eval(feed_dict={X:mnist.test.images,y:mnist.test.labels})
print(epoch, "Test accuracy:",acc_test)
save_path = saver.save(sess, "./my_model+final.ckpt")输出:
0 Test accuracy: 0.9551
1 Test accuracy: 0.9682
2 Test accuracy: 0.9725
3 Test accuracy: 0.9766
4 Test accuracy: 0.9777
5 Test accuracy: 0.9768
6 Test accuracy: 0.9785
7 Test accuracy: 0.9772
8 Test accuracy: 0.9781
9 Test accuracy: 0.9804
10 Test accuracy: 0.9798
11 Test accuracy: 0.9794
12 Test accuracy: 0.9796
13 Test accuracy: 0.981
14 Test accuracy: 0.9808
15 Test accuracy: 0.9808
16 Test accuracy: 0.981
17 Test accuracy: 0.9809
18 Test accuracy: 0.9815
19 Test accuracy: 0.9821
Max-norm 正则化
对每一个神经元,限制它的输入连接权 ∥w∥≤r ‖ w ‖ ≤ r , r r 是max-norm的一个超参数。
实现:每次training step之后计算权重 w w 的2-范数。然后限制被破坏则执行更新 w←wr (∥w∥2 ) w ← w r ( ‖ w ‖ 2 ) .
tensorflow实现:
threshold = 1.0
#axes=1,对每行向量最大范数为1
clipped_weights = tf.clip_by_norm(weights,clip_norm=threshold, axes=1)
clip_weights = tf.assign(weights, clipped_weights)完整:
reset_graph()
n_inputs = 28 * 28
n_hidden1 = 300
n_hidden2 = 50
n_outputs = 10
learning_rate = 0.01
momentum = 0.9
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu, name="hidden1")
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation= tf.nn.relu, name="hidden2")
logits = tf.layers.dense(hidden2,n_outputs, name="outputs")
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
with tf.name_scope("train"):
optimizer = tf.train.MomentumOptimizer(learning_rate,momentum)
training_op = optimizer.minimize(loss)
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits,y,1)
accuracy = tf.reduce_mean(tf.cast(correct,tf.float32))
#接下来得到第一隐层的权重,然后`clip_by_norm()`用修剪权重,之后赋给权值变量;
threshold = 1.0
weights = tf.get_default_graph().get_tensor_by_name("hidden1/kernel:0")
clipped_weights = tf.clip_by_norm(weights,clip_norm=threshold, axes=1)
clip_weights = tf.assign(weights, clipped_weights)
weights2 = tf.get_default_graph().get_tensor_by_name("hidden2/kernel:0")
clipped_weights2 = tf.clip_by_norm(weights2, clip_norm=threshold, axes=1)
clip_weights2 = tf.assign(weights2, clipped_weights2)
init = tf.global_variables_initializer()
saver = tf.train.Saver()
n_epochs = 20
batch_size = 50
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op,feed_dict={X:X_batch, y:y_batch})
clip_weights.eval()
clip_weights2.eval()
acc_test = accuracy.eval(feed_dict={X:mnist.test.images,
y:mnist.test.labels})
print(epoch, "Test accuracy:", acc_test)
save_path = saver.save(sess,"./my_model_final.ckpt")用函数包装max-norm:
def max_norm_regularizer(threshold, axes=1, name="max_norm",
collections="max_norm"):
def max_norm(weights):
clipped = tf.clip_by_norm(weights, clip_norm=threshold, axes=axes)
clipped_weights = tf.assign(weights, clipped, name=name)
tf.add_to_collection(collections,clipped_weights)
return None # 不用加入最后的损失中,所以返回none
return max_norm在每轮训练之后执行修剪操作:
reset_graph()
n_inputs = 28 * 28
n_hidden1 = 300
n_hidden2 = 50
n_outputs = 10
learning_rate = 0.01
momentum = 0.9
X = tf.placeholder(tf.float32,shape=(None, n_inputs), name="X")
y = tf.placeholder(tf.int64, shape=(None), name="y")
max_norm_reg = max_norm_regularizer(threshold=1.0)
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu,
kernel_regularizer=max_norm_reg,name="hidden1")
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu,
kernel_regularizer=max_norm_reg,name="hidden2")
logits = tf.layers.dense(hidden2, n_outputs, name="outputs")
max_norm_reg = max_norm_regularizer(threshold=1.0)
with tf.name_scope("dnn"):
hidden1 = tf.layers.dense(X, n_hidden1, activation=tf.nn.relu,
kernel_regularizer=max_norm_reg,name="hidden1")
hidden2 = tf.layers.dense(hidden1, n_hidden2, activation=tf.nn.relu,
kernel_regularizer=max_norm_reg,name="hidden2")
logits = tf.layers.dense(hidden2, n_outputs, name="outputs")
with tf.name_scope("loss"):
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits)
loss = tf.reduce_mean(xentropy, name="loss")
with tf.name_scope("train"):
optimizer = tf.train.MomentumOptimizer(learning_rate,momentum)
training_op = optimizer.minimize(loss)
with tf.name_scope("eval"):
correct = tf.nn.in_top_k(logits, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
init = tf.global_variables_initializer()
saver = tf.train.Saver()
n_epochs = 20
batch_size = 50
# must run the weights clipping operations after each training operation
clip_all_weights = tf.get_collection("max_norm")
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for iteration in range(mnist.train.num_examples // batch_size):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op , feed_dict={X:X_batch,y:y_batch})
# 每一个训练都需要执行修剪操作
sess.run(clip_all_weights)
acc_test = accuracy.eval(feed_dict={X:mnist.test.images, y:mnist.test.labels})
print(epoch, "Test accuracy:", acc_test)
save_path = saver.save(sess,"./my_model_final.ckpt")
结果:0 Test accuracy: 0.9497
1 Test accuracy: 0.9673
2 Test accuracy: 0.9699
3 Test accuracy: 0.9755
4 Test accuracy: 0.976
5 Test accuracy: 0.9756
6 Test accuracy: 0.972
7 Test accuracy: 0.9796
8 Test accuracy: 0.98
9 Test accuracy: 0.9778
10 Test accuracy: 0.9801
11 Test accuracy: 0.9781
12 Test accuracy: 0.9802
13 Test accuracy: 0.98
14 Test accuracy: 0.9803
15 Test accuracy: 0.9804
16 Test accuracy: 0.9803
17 Test accuracy: 0.9801
18 Test accuracy: 0.9813
19 Test accuracy: 0.9806
参考:《hands-on ML & Tensorflow》