最近在学习ML,前前后后大概有一个月了吧。基于之前看到的一篇非常赞的文章,叫做[Machine Learning in a Week](https://medium.com/learning-new-stuff/machine-learning-in-a-week-a0da25d59850#.c0rh73hlc)。当然实际执行下来,惭愧的学了一个月才算是勉强完成。好在最终效果还算可以。
- 本次项目的目的:
首先还是阐述一下项目的背景。某房地产网站上,通常会有两种用户,房产经纪人和真实买家。房产经纪人浏览的主要动机是套取网站上的房源信息,而作为网站方,又不希望经纪人套取这些信息。那么,这里有一个比较大胆的假设,经纪人的浏览行为是否会与普通用户不同呢?如果是,那么理论上,我们可以通过分析用户行为就判断出哪些用户是经纪人,从而不给他们展示房源的核心信息(如门牌号),而给其他一些真实买家展示这些必要的核心信息。最后啰嗦一句,网站的现状是为了防范少数作恶的经纪人,房源的关键信息不会给任何人看。
更准确的说,如果我们定义A(经纪人)为我们预测经纪人的准确率的话,我们希望A>80%。这样我们就可以给算法判断为不是经纪人的这些人开放这些保密信息了。
- 关于数据:
本次获取的数据只包括用户浏览列表页和详情页的数据。假设是,经纪人通常会只看不买或者只卖不看(在网站上,买=预约看房的操作)。而经纪人的标签数据来源于坐席的反馈,所以实际数据中只可能有更多的经纪人没有被标出,而标出的应该都是经纪人。
- 其他局限性:
由于本次毕竟是以练习为主,主要定性的分析一下可行性,数据的量级也有限,只有3500条左右。
1. 数据时间维度为1个月。其中包含了春节时间,该时间段内用户的浏览行为较为异常,所以预测的假设可能在泛化时遭遇困难,获取更多的数据可以有效解决该问题。
2. 有效经纪人数据太少,被打了经纪人标签的数据占比只有3.31%,也就是少于120条。
3. 由于本次数据只是单纯的使用时间做了限制(2月15日-3月15日),所以很多3月15日新来的用户可能来不急形成很多访问数据,这部分数据的缺失可能会影响整体的预测。
4. 出于保密需要,本次实验的数据只随机取了总数据集的一部分,随机获取本身可能存在一些分布偏差。
项目背景和目的就此交待完毕,首先说一下最终的结果。结果是,使用svc算法是的经纪人的预测成功率在63%-87%之间浮动(均值为72%左右),预测为非经纪人的买家占总用户数量约为45%,基本达到了可用的要求。下面是具体的实现细节。
# 第一步:清洗数据
获取到用户的ID和各项行为后,首先是清洗数据,基本是利用Numpy的Dataframe的各种操作进行数据清洗和汇总。最终目的是把同一个用户的行为整合在一行里面。
从csv文件获取数据的代码:
```
agent_df = pd.DataFrame.from_csv("listanddetailraw.csv")
```
清洗完存储为csv文件的代码:
```
agent_df.to_csv('datacleaned0318.csv')
```
逐项清洗的代码大概长这个样子的。
```
for ncount in arange:
userStr = all_user.loc[ncount]
areaNo = 0
for ncount2 in arange:
if all_user2.loc[ncount2] == userStr:
print("matched user2",ncount,"with",ncount2)
areaNo += agent_df.listArea.loc[ncount2]
agent_df.listArea0.loc[ncount] = areaNo
print("areaNo",areaNo,"check",agent_df.listArea0.loc[ncount],"on count",ncount)
budgetNo = 0
for ncount3 in arange:
if all_user3.loc[ncount3] == userStr:
print("matched user3",ncount,"with",ncount3)
budgetNo += agent_df.listBudget.loc[ncount3]
agent_df.listBudget0.loc[ncount] = budgetNo
print("budgetNo",budgetNo,"check",agent_df.listBudget0.loc[ncount],"on count",ncount)
roomNo = 0
for ncount4 in arange:
if all_user4.loc[ncount4] == userStr:
print("matched user4",ncount,"with",ncount4)
roomNo += agent_df.listRoom.loc[ncount4]
agent_df.listRoom0.loc[ncount] = roomNo
print("roomNo",roomNo,"check",agent_df.listRoom0.loc[ncount],"on count",ncount)
sqNo = 0
for ncount5 in arange:
if all_user5.loc[ncount5] == userStr:
print("matched user5",ncount,"with",ncount5)
sqNo += agent_df.listSquare.loc[ncount5]
agent_df.listSquare0.loc[ncount] = sqNo
print("sqNo",sqNo,"check",agent_df.listSquare0.loc[ncount],"on count",ncount)
ageNo = 0
for ncount6 in arange:
if all_user6.loc[ncount6] == userStr:
print("matched user6",ncount,"with",ncount6)
ageNo += agent_df.listAge.loc[ncount6]
agent_df.listAge0.loc[ncount] = ageNo
print("ageNo",ageNo,"check",agent_df.listAge0.loc[ncount],"on count",ncount)
tagNo = 0
for ncount7 in arange:
if all_user7.loc[ncount7] == userStr:
print("matched user7",ncount,"with",ncount7)
tagNo += agent_df.listTag.loc[ncount7]
agent_df.listTag0.loc[ncount] = tagNo
print("tagNo",tagNo,"check",agent_df.listTag0.loc[ncount],"on count",ncount)
detailNo = 0
for ncount8 in arange:
if all_user8.loc[ncount8] == userStr:
print("matched user8",ncount,"with",ncount8)
detailNo += agent_df.detail.loc[ncount8]
agent_df.detail0.loc[ncount] = detailNo
print("detailNo",detailNo,"check",agent_df.detail0.loc[ncount],"on count",ncount)
apMo = 0
for ncount9 in arange:
if all_user9.loc[ncount9] == userStr:
print("matched user9",ncount,"with",ncount9)
apMo += agent_df.appointment.loc[ncount9]
agent_df.appointment0.loc[ncount] = apMo
print("apMo",apMo,"check",agent_df.appointment0.loc[ncount],"on count",ncount)
for ncountAg in arange:
if all_agent.loc[ncountAg] == userStr:
print("agent",ncount,"with",ncountAg)
agent_df.tag.loc[ncount] = 1
print(agent_df)
```
之后,处于分类算法对原始数据Normalize的需要,我将列表页的访问次数处以20,将详情页的访问次数处以10,这是因为访问列表页的概率比详情页的更大,而访问详情页的概率大概是预约看房的10倍,所以将它们缩小以方便计算。列中的数据含义分别是:
- listPV0 = 列表页访问次数(Normalized:除以10)
- listArea = 列表页使用区域筛选的次数
- listBudget = 列表页使用预算筛选的次数
- listRoom = 列表页使用户型筛选的次数
- listAge = 列表页使用房龄筛选的次数
- listTag = 列表页使用标签筛选的次数
- detail0 = 房源详情页的访问次数(Normalized:除以20)
- appointment0 = 预约看房的次数
- tag = {0=买家 1=经纪人}
# 第二步:选择算法
如何选择算法解决分类问题呢?
## 选择算法之前
选择算法之前首先应该做几件事情:
1. 收集数据,处理数据
2. 提出一些理论上合理的假设
3. 概览自己的数据集
只有在做完以上几步之后,才能对将要被处理的数据有一个大概的认识。基于这些认识才能权衡利弊来进行算法的选择。
## 基于效果选择
首先上一张来自scikit-learn的图,基本上能用得到的分类算法都包括在下面了。每种算法包含了真对常见的3种数据分布的最佳表现
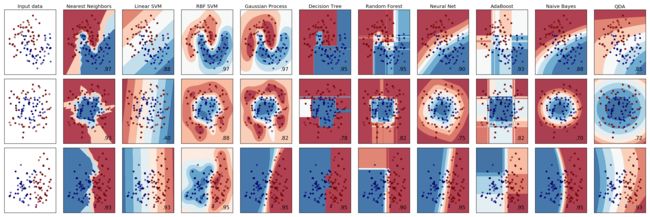
图片原地址:http://scikit-learn.org/stable/auto_examples/classification/plot_classifier_comparison.html#sphx-glr-auto-examples-classification-plot-classifier-comparison-py
这个链接中同时包含了所有函数的简单实现,如果实在不知道用哪种函数,全都Copy跑一遍试试也是可以的,反正成本也不高。
从这张图其实已经非常直观的可以看出每个算法真对典型的数量级的时候的表现了,我们再从左到右的简单啰嗦一下:
1. KNN(Nearest Neighbors):KNN基本可以描述复杂的点分布,但是很容易Overfitting(如图)。当然KNN很好调整,而且很快。应当作为首选尝试的算法。
2. Linear SVM:由于是线性计算,所以很难准确的反映出来数据分布的细节。一般来说不考虑使用。
3. RBF SVM:RBF向量机可以强大的描述数据分布的细节,如果你的数据集维度很多,存在着自己也说不清楚的一些复杂逻辑,RBF将是很好的一个选择。而且,他还很快。如果你不指望不停的观察预测结果,只是想机器帮你神奇的找到数据集中的规律并且正确分类的话,直接使用RBF SVM是一个很好的选项,可以节省大量时间。值得注意的问题是,在泛化的时候,你可能面临已经Overfitting的窘境(就像上面图片中的那种结果),此时你需要调节gamma与c。
4. Gaussian Process:相比SVM来说,前两种数据集效果比SVM略好,最后一种数据集效果绝对好于SVM,如果数据维度较多,数据趋势不明显,可以考虑Gaussian Process(分类器名称:GPC)。不过他的缺点也很明显,就是慢。所以在Scikit-learn官网上并不推荐使用Gaussian Process。另外,由于Gaussian Process没有预先可以调节weighted label的参数,鉴于我们本次的数据集特征,所以直接放弃使用GPC。(尝试了输出的结果经纪人准确率为0)
5. Decision Tree:如图,决策树由于是懒算法,所以生成的结论往往在泛化的时候会有明显的问题。如第二组数据集明显具有圆形的数据特征,但是DT的结果实在是不忍直视。如果真的要考虑使用决策树,建议直接用随机森林或者AdaBoost。(如果决策树真的有什么独特优势的话,也许是快吧)
6. Random Forest:加强版的决策树,仍然存在一些过拟合的问题。
7. Neural Net:不多说,强大的神经网络明显是所有算法中效果最好的。不过!,scikit默认的MLPClassifier貌似比较弱(也有可能我的用法不对),反正貌似不是真对分类问题而诞生的方法,所以真对我们这种0和1的数据量严重不均衡的情况,MLP与GPC一样给出了0经纪人的预测。我们有理由相信通过进一步调整数据集也许可以让MLP和GPC得出更好的效果,不过本次由于没有class_weight之类的参数所以暂时放弃使用。
8. AdaBoost:Lazy版本的决策树加强版,具体与随机森林的区别可以参考scikit的官方文档,讲解的很详细。
9. Naive Bayes:官方文档建议文字相关的分类才使用NB,不过我还是在我的分类项目中尝试了一下。可以说,NB真的效果不错,可以非常好的反映出数据的特征。新版的NB甚至加入了设置不同class的优先级的Prior字段。不过NB可调的参数不多,总体上来说适合拿到数据后无脑先来一发试试效果。
10. QDA:研究不多,看着效果也一般,此处略过。
## 基于成本总和考虑
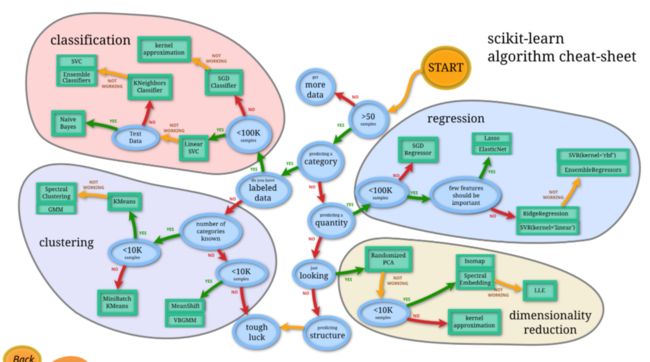
总体上来说,scikit-learn的这张图已经是出于成本总和考虑的结果了。按照箭头一直走,总的来说就是会优先选择成本较低的算法,如果可以解决问题最好,如果不行再考虑成本更高的算法。
总体来说,本次由于数据量集还是比较小的(3500个sample),所以并没有太考虑成本的问题,我基本上是把所有的础算法都尝试了一遍。最后发现效果最好的还是SVC。所以,本质上还是相信官方文档的图会节省很多时间。
# 第三步:参数调整
SVC算法中,首先我主要调整class_weight参数,因为经纪人数据太少,如果不调整权重,基本上会把所有用户都判断为买家,因为这样的准确率最高(使用默认参数可以达到96%左右的准确率)。但是这样经纪人的判断准确率就几乎为0了。所以,经过尝试,将经纪人的权重调整为45:1,我管它叫“宁可错杀45个买家,也不放过一个经纪人”。调整后果然经纪人的准确率上升到了接近80%,但同时买家的准确率只有46%左右了(因为把大量的买家判断成了经纪人)。
实际在1422个测试集中,判断了781人为经纪人。我们仍然可以将关键的房源信息开放给剩下的700人使用,因为毕竟80%的经纪人已经被过滤掉了。
最后,由于担心从120条仅有的经纪人信息中得出抽象模型而带来的Overfitting的结果,进一步调整了C参数。(科普一下:SVC方法中,C参数默认为1,C越小,结果的决策边界越平滑,越能避免Overfitting的情况)
```
clf = SVC(kernel="rbf" , class_weight= {1: 45}, degree=3,gamma="auto", C=0.63).fit(X_train, y_train) #63-87(72)/48-38(45) #6.7fits the correct number for 32 agents for rbf
```
# 心得
1. 通过这个项目在分类问题上实验了几乎所有sklearn中的基本方法,对所有方法大概有了一个了解。
2. 实际解决一个问题对于学习ML来说还是非常有帮助的。不但能够有目的的继续进行学习,同时也可以给自己更多的动力,毕竟可以看到有价值的产出和结果还是跟自己使用假数据做实验很不一样。
任何问题欢迎留言讨论与提问。笔者也仍在持续学习中,随时欢迎交流。