Disruptor并发框架完全入门
版本:3.4.2
前言:Disruptor拥有开飞机般的速度,单线程里每秒处理600w订单,业务逻辑处理器完全是运行在内存中的,是基于事件源驱动的。Disruptor作为一个高性能的异步处理框架,其为啥这么快?这也是我为啥尝试去学习它的原因。
Disruptor的使用
1. 建立一个Event类来承载数据,通过事件绑定数据的方式进行数据传递(在Disruptor中可以看作Event就是Data)
2. 建立一个Event工厂类,用来创建Event类的实例对象
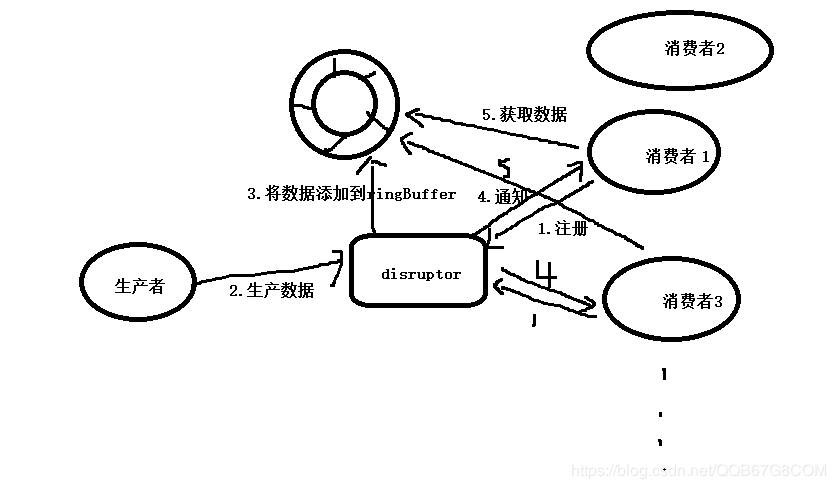
3. 创建一个监听事件类,用于处理数据(监听事件类可看作为消费者,disruptor看作观察者,将消费者注册到观察者身上,一旦发生数据变动,观察者立即通知所有相关的消费者)
4. 环形缓冲区为Disruptor的真正核心,通过将消费者注册到disruptor中,生产者生产数据被disruptor保存到ringBuffer中,然后将数据当前的序列号通知给所有相关的消费者,消费者拿到相关的序列号,通过底层的取模运算找到要找的数据在环上的位置,然后直接到ringBuffer中读取数据。
代码来源官方文档:https://lmax-exchange.github.io/disruptor/
PS:代码后续附带其它详细解析
package disruptor;
/**
* @Description: 在disruptor中,Event代表数据,定义携带数据的事件
* @Author: ljj
* @CreateDate: 2019/5/10 16:29
* @UpdateUser: ljj
* @UpdateDate: 2019/5/10 16:29
* @UpdateRemark: 修改内容
* @Version: 1.0
*/
public class LongEvent {
private long value;
public void set(long value) {
this.value = value;
}
public long get(){
return value;
}
}
package disruptor;
import com.lmax.disruptor.EventFactory;
/**
* @author ljj
* @description 通过一个工厂来生产数据(Event)
* @date 2019/5/10
*/
public class LongEventFactory implements EventFactory {
@Override
public LongEvent newInstance() {
return new LongEvent();
}
}
package disruptor;
import com.lmax.disruptor.EventHandler;
/**
* @author ljj
* @description 在定义了Event之后我们需要创建一个消费者来处理这些事件,也是一个事件处理器
* @date 2019/5/10
*/
public class LongEventHandler implements EventHandler {
private String clientName;
LongEventHandler(String clientName){
this.clientName = clientName;
}
//事件监听,类似观察者模式
@Override
public void onEvent(LongEvent event, long sequence, boolean endOfBatch) throws Exception {
// System.out.println(this.clientName + event.get());//向Client推送消息
event.get();
}
}
package disruptor;
import com.lmax.disruptor.RingBuffer;
import java.nio.ByteBuffer;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @author ljj
* @description
* @date 2019/5/10
*/
public class LongEventProducer {
private final RingBuffer ringBuffer;
public LongEventProducer(RingBuffer ringBuffer) {
this.ringBuffer = ringBuffer;
}
//发布事件
public void onData(ByteBuffer bb){
long sequence = ringBuffer.next(); //1.获取下一个序列
try {
LongEvent event = ringBuffer.get(sequence); //2.获取disruptor的sequence
event.set(bb.getLong(0)); //3.设置事件Context
}finally {
ringBuffer.publish(sequence); //4.发布事件
}
}
}
package disruptor;
import com.lmax.disruptor.EventTranslatorOneArg;
import com.lmax.disruptor.RingBuffer;
import java.nio.ByteBuffer;
/**
* @author ljj
* @description 在disruptor3.0版本中。添加了一个更丰富的lambda风格的API,
* 通过将这种复杂性封装在ringBuffer(环形缓冲区)来帮助开发人员,因此post-3.0
* 之后发布消息可以通过Event Publisher(事件发布者)或者Event Translator(事件转换器)
* 来进行事件发布
* 优点:这种方法的优点就是可以将转换程序代码放置到单独的类,并且可以轻松的进行单元测试Disruptor
* 提供类许多不同的接口(EventTranslator、EventTranslatorOneArg、EventTranslatorTwoArg等),
* 可以实现这些接口来提供Translator,作为Translator方法的参数通过对ringBuffer进行调用传递给
* Translator。
* @date 2019/5/10
*/
public class LongEventProducerWithTranslator {
private final RingBuffer ringBuffer;
public LongEventProducerWithTranslator(RingBuffer ringBuffer) {
this.ringBuffer = ringBuffer;
}
private static final EventTranslatorOneArg TRANSLATOR =
new EventTranslatorOneArg() {
@Override
public void translateTo(LongEvent event, long sequence, ByteBuffer bb) {
event.set(bb.get(0));
}
};
public void onData(ByteBuffer bb){
ringBuffer.publishEvent(TRANSLATOR, bb);
}
}
package disruptor;
import com.lmax.disruptor.SleepingWaitStrategy;
import com.lmax.disruptor.YieldingWaitStrategy;
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.dsl.ProducerType;
import com.lmax.disruptor.util.DaemonThreadFactory;
import java.nio.ByteBuffer;
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @author ljj
* @description
* @date 2019/5/10
*/
public class LongEventMain {
public static void main(String[] args) throws Exception
{
//1.为这次Event创建一个Factory
LongEventFactory factory = new LongEventFactory();
//指定环形缓冲区的大小,必须为2的幂次方,因此底层会通过取模运算来确定位置,2的幂次方性能会更好
int bufferSize = 1024;
/**
*
* BlockingWaitStrategy 是最低效的策略,但其对CPU的消耗最小并且在各种不同部署环境中能提供更加一致的性能表现
* WaitStrategy BLOCKING_WAIT = new BlockingWaitStrategy();
* SleepingWaitStrategy 的性能表现跟BlockingWaitStrategy差不多,对CPU的消耗也类似,但其对生产者线程的影响最小,适合用于异步日志类似的场景
* WaitStrategy SLEEPING_WAIT = new SleepingWaitStrategy();
* YieldingWaitStrategy 的性能是最好的,适合用于低延迟的系统。在要求极高性能且事件处理线数小于CPU逻辑核心数的场景中,推荐使用此策略;例如,CPU开启超线程的特性
* WaitStrategy YIELDING_WAIT = new YieldingWaitStrategy();
*/
//2.创建disruptor
//第一个参数为工厂对象,用于创建LongEvent,LongEvent承载着消费的数据
//第二个参数为环形缓冲区大小
//第三个参数为线程工厂
//第四个参数SINGLE(单个生产者)和MULTI(多个生产者)
//第五个参数定义一种关于生成和消费的策略
// Disruptor disruptor = new Disruptor<>(factory, bufferSize, DaemonThreadFactory.INSTANCE);
Disruptor disruptor = new Disruptor<>(factory, bufferSize, new DisruptorThreadFactory(), ProducerType.SINGLE,new SleepingWaitStrategy());
//JDK1.8的Lambdas写法
// Disruptor disruptor = new Disruptor<>(LongEvent::new, bufferSize, new DisruptorThreadFactory(), ProducerType.SINGLE,new YieldingWaitStrategy());
//3.连接handler,也就是注册消费者(监听器,类似于观察者模式)
for (int i=1; i <10; i++){ //100w个Client
disruptor.handleEventsWith(new LongEventHandler("Client"+i+":"));
}
//JDK1.8的Lambdas写法
// disruptor.handleEventsWith((event, sequence, endOfBatch) -> System.out.println("Event: " + event.get()));
//4.Start the Disruptor, starts all threads running
disruptor.start();
//5.从Disruptor获取用于事件发布的环形缓冲区(ringBuffer).
RingBuffer ringBuffer = disruptor.getRingBuffer();
//6.自定义并创建一个事件提供者对象用来发布事件
LongEventProducer producer = new LongEventProducer(ringBuffer);
//7.创建一个数据缓冲区用来缓存需要发布的数据
ByteBuffer bb = ByteBuffer.allocate(8);
long start = System.currentTimeMillis();
for (long l = 0; l < 6000000; l++)
{
//8.向缓冲区添加需要发布的数据
bb.putLong(0, l);
//9.发布数据
producer.onData(bb);//9-1
//JDK1.8的两种Lambda写法
// ringBuffer.publishEvent((event, sequence, buffer) -> event.set(buffer.getLong(0)), bb);//9-2
//这将创建一个捕获Lambda,这意味着在将Lambda传递给publishEvent()调用时,需要实例化一个对象来保存
//变量bb。这将创建额外的(不必要的垃圾),因此,如果需要low GC压力,那么传递参数给Lambda的调用应该是首选的
// ringBuffer.publishEvent((event, sequence) -> event.set(bb.getLong(0)));//9-3
// TimeUnit.SECONDS.sleep(1);
}
//10.关闭disruptor,方法会阻塞,直到所有的Event都被处理完毕
disruptor.shutdown();
System.out.println("耗时:"+(Long)(System.currentTimeMillis()-start) + "ms");
}
//线程工厂,为了保证创建出来的线程都具有相同的特性,譬如是否为守护进程,优先级设置等
public static class DisruptorThreadFactory implements ThreadFactory {
private static final AtomicInteger poolnum = new AtomicInteger(1);//线程数目
private final ThreadGroup group;
private final AtomicInteger threadnum = new AtomicInteger(1);//线程数目
private final String namePrefix;//为每个创建的线程添加前缀
DisruptorThreadFactory(){
SecurityManager sm = System.getSecurityManager();
//取得线程组
group = (sm != null) ? sm.getThreadGroup() : Thread.currentThread().getThreadGroup();
namePrefix = "pool-" + poolnum.getAndIncrement() + "-thread-";
}
@Override
public Thread newThread(Runnable r) {
//创建线程,设置线程组和线程名
Thread t = new Thread(group, r, namePrefix + threadnum.getAndIncrement(),0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}
}
上述代码简图:
核心概念官方原文:https://github.com/LMAX-Exchange/disruptor/wiki/Introduction
介绍
理解Disruptor是什么的最好方法是将它与目前很好理解和非常相似的东西进行比较。在Disruptor的情况下,这将是Java的BlockingQueue。像队列一样,Disruptor的目的是在同一进程内的线程之间移动数据(例如消息或事件)。但是,Disruptor提供了一些将其与队列区分开来的关键功能。他们是:
- 具有消费者依赖关系图的消费者多播事件。
- 为事件预先分配内存。
- 可选择无锁。
核心概念
在我们理解Disruptor如何工作之前,定义一些将在整个文档和代码中使用的术语是值得的。对于那些倾向于DDD的人来说,将其视为Disruptor域的普遍存在的语言。
1. RingBuffer:环形缓冲区通常被认为是Disruptor的主要组件,但是从3.0开始,环形缓冲区只负责存储和更新流经Disruptor的数据(Event)。对于一些高级的用例,可以完全由用户替换。
2. Sequence:Disruptor使用Sequence(序列)作为一种方法来识别特定组件的位置。每个消费者(EventProcessor)都像Disruptor本身一样维护一个序列。大多数并发代码依赖于这些序列值的移动,因此序列支持当前AtomicLong的许多特性。实际上,这两个值之间唯一真正的区别是序列包含额外的功能,以防止Sequence和其他值之间的错误共享。
3. Sequencer:Sequencer是Disruptor的真正核心。该接口的两种实现(单生产者、多生产者)实现了所有用于在生产者和消费者之间快速、正确传递数据的并发算法。
4. Sequence Barrier:由Sequencer生成,包含对来自Sequencer和任何依赖消费者的序列的主已发布Sequence的引用。它包含逻辑,以确定是否有任何事件可供使用者处理。
5. Wait Strategy:等待策略决定了消费者将如何等待Event被生产者放置到Disruptor中。
6. Event:从生产者传递给消费者的数据单位。事件没有特定的代码表示,因为它完全由用户定义。(代表数据)
7. EventProcessor:用于处理Disruptor事件的主事件循环,并拥有使用者Sequence的所有权。有一个名为BatchEventProcessor的表示,它包含事件循环的有效实现,并将调用EventHandler接口的一个已提供的实现。
8. EventHandler:由用户实现并代表Disruptor的消费者的接口。(代表消费者)
9. Producer:这是调用Disruptor来排队事件的用户代码。这个概念在代码中也没有表示。
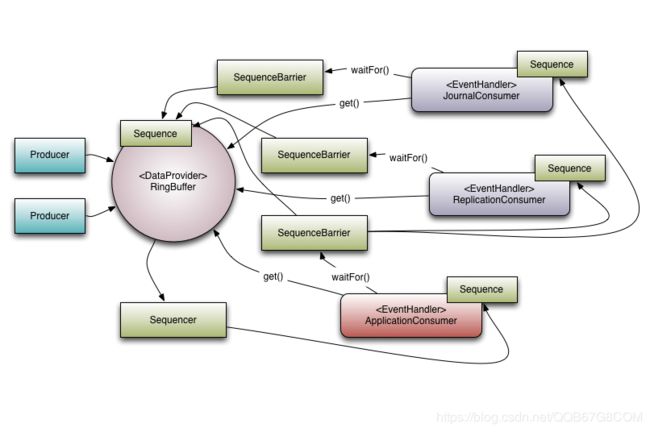
图1 :Disruptor与一群依赖的Consumer
Multicast Events(多路广播事件)
这是排队者和Disruptor之间最大的行为差异。当多个消费者监听同一个Disruptor时,所有事件都发布给所有消费者,而队列中只有一个事件将发送给一个消费者。DIsruptor的行为旨在用于需要对相同数据进行独立的多个并行操作的情况。来自LMAX的规范示例中,我们有三个操作:日志记录(将输入数据写入持久日志文件)、复制(将输入数据发送到另一台机器以确保有数据的远程副本)和业务逻辑(真正的处理工作)。Executor-style事件处理也可以使用WorkerPool,通过同时处理不同的事件来发现伸缩性。请注意,它被固定在现有的Disruptor类之上,并且没有得到相同的一流支持,因此它可能不是实现特定目标的最有效方法。
查看图1,可以看到有3个事件处理程序(JournalConsumer、ReplicationConsumer和ApplicationConsumer)在监听Disruptor,每个Event Handler都将接收Disruptor中可用的所有消息(顺序相同)。这允许这些使用者的工作可以并行进行。
Consumer Dependency Graph(消费者依赖图)
为了支持并行处理行为的实际应用,有必要支持消费者之间的协调。返回参考上述示例,必须防止业务逻辑消费者在日记和复制消费者完成其任务之前取得进展。我们称这个概念为Gating(门控),或者更准确地说,这种行为的超集特征称为Gating。Gating发生在两个地方。首先,我们需要确保生产者不会超过消费者。这是通过调用RingBuffer.addGatingConsumers()将相关的使用者添加到Disruptor来处理的。其次,先前提到的情况是通过从必须首先完成其处理的组件构造包含序列的SequenceBarrier来实现的。
参考图1,有3个消费者正在收听来自Ring Buffer的事件。此示例中有一个依赖关系图。ApplicationConsumer依赖于JournalConsumer和ReplicationConsumer。这意味着JournalConsumer和ReplicationConsumer可以彼此并行自由运行。从ApplicationConsumer的SequenceBarrier到JournalConsumer和ReplicationConsumer的序列的连接可以看到依赖关系。值得注意的是Sequencer与下游消费者之间的关系。它的一个作用是确保发布不包装Ring Buffer。要做到这一点,下游消费者中没有一个可能具有低于环形缓冲区序列的序列,而不是环形缓冲区的大小。但是,使用依赖关系图可以进行有趣的优化。由于ApplicationConsumers Sequence保证小于或等于JournalConsumer和ReplicationConsumer(这是该依赖关系所确保的),因此Sequencer只需要查看ApplicationConsumer的Sequence。在更一般的意义上,Sequencer只需要知道作为依赖关系树中叶节点的使用者的序列。
Event Preallocation(事件预分配)
Disruptor的目标之一是在低延迟环境中使用。在低延迟系统中,必须减少或移除内存分配。在基于Java的系统中,目的是减少由于垃圾收集导致的数量停滞(在低延迟C / C ++系统中,由于存在于内存分配器上的争用,大量内存分配也存在问题)。
为了支持这一点,用户可以预先分配Disruptor中事件所需的存储空间。在构造期间,EventFactory由用户提供,并将在Disruptor的Ring Buffer中为每个条目调用。将新数据发布到Disruptor时,API将允许用户获取构造的对象,以便他们可以调用方法或更新该存储对象上的字段。Disruptor保证这些操作只要正确实现就是并发安全的。
Optionally Lock-free(可选择无锁)
低延迟期望推动的另一个关键实现细节是广泛使用无锁算法来实现Disruptor。所有内存可见性和正确性保证都是使用内存屏障和/或比较和交换操作实现的。只有一个用例需要实际锁定并且在BlockingWaitStrategy中。这仅仅是为了使用条件,以便在等待新事件到达时停放消耗线程。许多低延迟系统将使用忙等待来避免使用条件可能引起的抖动,但是在系统繁忙等待操作的数量中可能导致性能显着下降,尤其是在CPU资源严重受限的情况下。例如,虚拟化环境中的Web服务器。
如何使用Disruptor DSL简化环形缓冲区的设置
并行事件处理程序
首先使用环形缓冲区的所需配置创建向导:
Disruptor disruptor =
new Disruptor(ValueEvent.EVENT_FACTORY, EXECUTOR,
new SingleThreadedClaimStrategy(RING_SIZE),
new SleepingWaitStrategy());
请注意,我们传入一个Executor实例,该实例将用于在自己的线程中执行事件处理程序。
然后我们添加将并行处理事件的事件处理程序:
disruptor.handleEventsWith(handler1, handler2, handler3, handler4);
最后启动事件处理程序线程并检索配置的RingBuffer:
RingBuffer ringBuffer = disruptor.start();
然后,生产者可以使用RingBuffer的nextEvent并正常发布函数,以将事件添加到环形缓冲区。
依赖
处理程序之间的依赖关系可以通过将它们链接在一起来在Disruptor中表达,例如:
disruptor.handleEventsWith(handler1).then(handler2, handler3, handler4);
在这种情况下,处理程序1必须首先处理事件,处理程序2,3和4在此之后并行处理它们。也可以创建依赖链,以确保每个处理程序按顺序处理事件:
disruptor.handleEventsWith(handler1).then(handler2).then(handler3).then(handler4);
还可以创建多个链:
disruptor.handleEventsWith(handler1).then(handler2);
disruptor.handleEventsWith(handler3).then(handler4);
使用自定义EventProcessors
Disruptor最常见的用法是提供一个EventHandler并让Disruptor自动创建一个BatchEventProcessor实例。在BatchEventProcessor的行为不合适的情况下,可以使用其他类型的EventProcessor作为依赖关系链的一部分。
要设置自定义事件处理器以处理来自环形缓冲区的事件:
RingBuffer ringBuffer = disruptor.getRingBuffer();
SequenceBarrier barrier = ringBuffer.newBarrier();
final MyEventProcessor customProcessor = new MyEventProcessor(ringBuffer, barrier);
disruptor.handleEventsWith(processor);
disruptor.start();
当调用start()方法时,Disruptor将执行自定义处理器。然后在BatchEventHandler之前要求自定义处理器处理事件:
disruptor.after(customProcessor).handleEventsWith(anEventHandler);
或者,要要求BatchEventHandler在自定义处理器之前处理事件,可以从Disruptor创建SequenceBarrier:
SequenceBarrier barrier = disruptor.after(batchEventHandler1, batchEventHandler2).asBarrier();
final MyEventProcessor customProcessor = new MyEventProcessor(ringBuffer, barrier);
发布Event
Disruptor提供了一种方便的方法,可以将事件发布到环形缓冲区更简单 - publishEvent(EventTranslator)。例如,发布者可以写成:
public class MyPublisher implements EventTranslator, Runnable {
private Object computedValue;
private Disruptor disruptor;
public MyPublisher(Disruptor disruptor)
{
this.disruptor = disruptor;
}
public void run()
{
while (true)
{
computedValue = doLongRunningComputation();
disruptor.publishEvent(this);
}
}
public void translateTo(MyEvent event, long sequence)
{
event.setComputedValue(computedValue);
}
private Object doLongRunningComputation()
{
...
}
}
其它常见问题
您是否放松了一致性模型以获得性能?
不,当序列发布时,对事件的所有更改都会立即提供给RingBuffer的EventProcessors。这是低延迟性能的关键。
条目是否以严格的FIFO方式交换?
是的,所有条目都基于claim sequence以严格的FIFO方式进行交换。
如何安排一个Disruptor与多个消费者,以便每个事件只被消费一次?
答:有两种方法,第一种是使用WorkerPool。第二个是使用下面描述的’条带’EventHandler方法。
如果我们有4个处理程序并为每个处理程序分配一个序数(0到3),那么消费者只需要使用序列号和消费者数量进行模运算,并将其与其序数值进行比较。
public final class MyHandler implements EventHandler
{
private final long ordinal;
private final long numberOfConsumers;
public MyHandler(final long ordinal, final long numberOfConsumers)
{
this.ordinal = ordinal;
this.numberOfConsumers = numberOfConsumers;
}
public void onEvent(final ValueEvent entry, final long sequence, final boolean onEndOfBatch)
{
if ((sequence % numberOfConsumers) == ordinal)
{
// Process the event
}
}
}
有些人会问,如果一个消费者在交易上花费的时间太长,它会阻止所有排队的消息。从技术上讲,这是可能的,但必须考虑到批量效应然后开始,从而为后面的人节省成本。使用这种方法,并发成本非常低,您甚至可以发现即使是小型停顿也比基于队列的替代方案成本更低。
我应该用什么尺寸制作环形缓冲区?
对于非常高的性能,环形缓冲区及其内容应该适合L3 CPU高速缓存,以便在线程之间进行交换。如果环形缓冲区用于重放场景,例如市场数据或网络恢复,则它可能更大,并且具有来自缓存未命中的明显性能影响。