Spark学习-数据关联问题
这篇文章主要记录spark高级数据分析书中,关于记录关联问题的代码的剖析。
其全部代码如下:
miaofudeMacBook-Pro:code miaofu$ git clone https://github.com/sryza/aas.git
Cloning into 'aas'...
remote: Counting objects: 2490, done.
remote: Compressing objects: 100% (17/17), done.
remote: Total 2490 (delta 4), reused 0 (delta 0), pack-reused 2473
Receiving objects: 100% (2490/2490), 477.02 KiB | 149.00 KiB/s, done.
Resolving deltas: 100% (695/695), done.
Checking connectivity... done.
miaofudeMacBook-Pro:code miaofu$ cd aas/
.git/ .travis.yml README.md ch03-recommender/ ch05-kmeans/ ch07-graph/ ch09-risk/ ch11-neuro/ pom.xml
.gitignore LICENSE ch02-intro/ ch04-rdf/ ch06-lsa/ ch08-geotime/ ch10-genomics/ common/ simplesparkproject/
miaofudeMacBook-Pro:code miaofu$ cd aas/
.git/ .travis.yml README.md ch03-recommender/ ch05-kmeans/ ch07-graph/ ch09-risk/ ch11-neuro/ pom.xml
.gitignore LICENSE ch02-intro/ ch04-rdf/ ch06-lsa/ ch08-geotime/ ch10-genomics/ common/ simplesparkproject/
miaofudeMacBook-Pro:code miaofu$ cd aas/
miaofudeMacBook-Pro:aas miaofu$ ls
LICENSE ch03-recommender ch06-lsa ch09-risk common
README.md ch04-rdf ch07-graph ch10-genomics pom.xml
ch02-intro ch05-kmeans ch08-geotime ch11-neuro simplesparkproject
miaofudeMacBook-Pro:aas miaofu$ vi ch02-intro/
pom.xml src/
miaofudeMacBook-Pro:aas miaofu$ vi ch02-intro/src/main/scala/com/cloudera/datascience/intro/RunIntro.scala
.....
ct.filter(s => s.score >= 4.0).
map(s => s.md.matched).countByValue().foreach(println)
ct.filter(s => s.score >= 2.0).
map(s => s.md.matched).countByValue().foreach(println)
}
def statsWithMissing(rdd: RDD[Array[Double]]): Array[NAStatCounter] = {
val nastats = rdd.mapPartitions((iter: Iterator[Array[Double]]) => {
val nas: Array[NAStatCounter] = iter.next().map(d => NAStatCounter(d))
iter.foreach(arr => {
nas.zip(arr).foreach { case (n, d) => n.add(d) }
})
Iterator(nas)
})
nastats.reduce((n1, n2) => {
n1.zip(n2).map { case (a, b) => a.merge(b) }
})
}
}
class NAStatCounter extends Serializable {
val stats: StatCounter = new StatCounter()
var missing: Long = 0
def add(x: Double): NAStatCounter = {
if (x.isNaN) {
missing += 1
} else {
stats.merge(x)
}
this
}
def merge(other: NAStatCounter): NAStatCounter = {
stats.merge(other.stats)
missing += other.missing
this
}
override def toString: String = {
"stats: " + stats.toString + " NaN: " + missing
}
}
object NAStatCounter extends Serializable {
def apply(x: Double) = new NAStatCounter().add(x)
}
(1)然后先分析类
import org.apache.spark.util.StatCounter
class NAStatCounter extends Serializable {
val stats: StatCounter = new StatCounter()
var missing: Long = 0
def add(x: Double): NAStatCounter = {
if (x.isNaN) {
missing += 1
} else {
stats.merge(x)
}
this
}
def merge(other: NAStatCounter): NAStatCounter = {
stats.merge(other.stats)
missing += other.missing
this
}
override def toString: String = {
"stats: " + stats.toString + " NaN: " + missing
}
}
object NAStatCounter extends Serializable {
def apply(x: Double) = new NAStatCounter().add(x)
}注意这里定义了一个scala的类,该类是继承了StatCounter,这个类是spark定义的用于描述统计量的类 。而这个继承类在其基础上,包括了解决NaN的情况。值得注意的是NanStatCounter自身重新定义了merge。这个类在StatCounter也有定义,该函数,是通过增量式的方法重新计算描述统计量的值。该函数的返回值,是StatCounter这个类本身。这一点是因为在后面作者要对所有的记录RDD每一个记录使用mapPartitions函数,为什么使用这个函数,后面在详细叙述。当前我们注意到其实stats也有merge,这个merger是StatCounter定义的实现增量式计算描述统计量的函数。为了一探究竟,我们可以打开这个类的定义文件(https://github.com/apache/spark/blob/v2.0.0/core/src/main/scala/org/apache/spark/util/StatCounter.scala):
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.util
/**
* A class for tracking the statistics of a set of numbers (count, mean and variance) in a
* numerically robust way. Includes support for merging two StatCounters. Based on Welford
* and Chan's [[http://en.wikipedia.org/wiki/Algorithms_for_calculating_variance algorithms]]
* for running variance.
*
* @constructor Initialize the StatCounter with the given values.
*/
class StatCounter(values: TraversableOnce[Double]) extends Serializable {
private var n: Long = 0 // Running count of our values
private var mu: Double = 0 // Running mean of our values
private var m2: Double = 0 // Running variance numerator (sum of (x - mean)^2)
private var maxValue: Double = Double.NegativeInfinity // Running max of our values
private var minValue: Double = Double.PositiveInfinity // Running min of our values
merge(values)
/** Initialize the StatCounter with no values. */
def this() = this(Nil)
/** Add a value into this StatCounter, updating the internal statistics. */
def merge(value: Double): StatCounter = {
val delta = value - mu
n += 1
mu += delta / n
m2 += delta * (value - mu)
maxValue = math.max(maxValue, value)
minValue = math.min(minValue, value)
this
}
/** Add multiple values into this StatCounter, updating the internal statistics. */
def merge(values: TraversableOnce[Double]): StatCounter = {
values.foreach(v => merge(v))
this
}
/** Merge another StatCounter into this one, adding up the internal statistics. */
def merge(other: StatCounter): StatCounter = {
if (other == this) {
merge(other.copy()) // Avoid overwriting fields in a weird order
} else {
if (n == 0) {
mu = other.mu
m2 = other.m2
n = other.n
maxValue = other.maxValue
minValue = other.minValue
} else if (other.n != 0) {
val delta = other.mu - mu
if (other.n * 10 < n) {
mu = mu + (delta * other.n) / (n + other.n)
} else if (n * 10 < other.n) {
mu = other.mu - (delta * n) / (n + other.n)
} else {
mu = (mu * n + other.mu * other.n) / (n + other.n)
}
m2 += other.m2 + (delta * delta * n * other.n) / (n + other.n)
n += other.n
maxValue = math.max(maxValue, other.maxValue)
minValue = math.min(minValue, other.minValue)
}
this
}
}
/** Clone this StatCounter */
def copy(): StatCounter = {
val other = new StatCounter
other.n = n
other.mu = mu
other.m2 = m2
other.maxValue = maxValue
other.minValue = minValue
other
}
def count: Long = n
def mean: Double = mu
def sum: Double = n * mu
def max: Double = maxValue
def min: Double = minValue
/** Return the variance of the values. */
def variance: Double = {
if (n == 0) {
Double.NaN
} else {
m2 / n
}
}
/**
* Return the sample variance, which corrects for bias in estimating the variance by dividing
* by N-1 instead of N.
*/
def sampleVariance: Double = {
if (n <= 1) {
Double.NaN
} else {
m2 / (n - 1)
}
}
/** Return the standard deviation of the values. */
def stdev: Double = math.sqrt(variance)
/**
* Return the sample standard deviation of the values, which corrects for bias in estimating the
* variance by dividing by N-1 instead of N.
*/
def sampleStdev: Double = math.sqrt(sampleVariance)
override def toString: String = {
"(count: %d, mean: %f, stdev: %f, max: %f, min: %f)".format(count, mean, stdev, max, min)
}
}
object StatCounter {
/** Build a StatCounter from a list of values. */
def apply(values: TraversableOnce[Double]): StatCounter = new StatCounter(values)
/** Build a StatCounter from a list of values passed as variable-length arguments. */
def apply(values: Double*): StatCounter = new StatCounter(values)
}通过对这个函数的研究,也帮助了了解了scala类定义的一些技巧。首先是定义了private变量,存储核心重要属性,然后初始化,然后定义了三个merge函数,充分发扬了类的多态性。定义一个copy自身的方法。另外就是定义了一系列的函数变量,最后定义了toString方法获取函数的目前的状态。最后使用了object半生对象。
(2)使用RDD算子,统一处理
import org.apache.spark.rdd.RDD
def statsWithMissing(rdd: RDD[Array[Double]]): Array[NAStatCounter] = {
val nastats = rdd.mapPartitions((iter: Iterator[Array[Double]]) => {
val nas: Array[NAStatCounter] = iter.next().map(d => NAStatCounter(d))
iter.foreach(arr => {
nas.zip(arr).foreach { case (n, d) => n.add(d) }
})
Iterator(nas)
})
nastats.reduce((n1, n2) => {
n1.zip(n2).map { case (a, b) => a.merge(b) }
})
}
}首先第一句是mapPartitions的一个操作,输出为nanstats,输入是rdd变量。mapPartitions的参数一个函数,这个函数的输入是Iterator[Arrays[Double]],输出则是Iterator[Array[NAStatCounter]]。至于如何实现从我们自己定义的函数,到最终我们的目标。中间的过程都是通过Spark分布式实现的。也就是mapPartitions的这个接口,参见下图。写到这里,我们将可以理解了为什么说Spark是一个分布式的编程框架了。
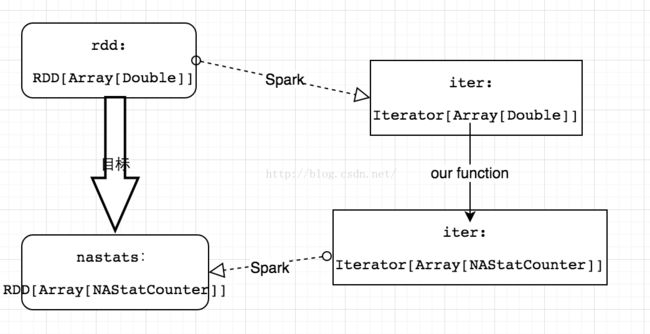
既然说到了mapPartitions这个函数,我们就探索一下这个函数的细节。
mapPartitions
def mapPartitions[U](f: (Iterator[T]) => Iterator[U], preservesPartitioning: Boolean = false)(implicit arg0: ClassTag[U]): RDD[U]
该函数和map函数类似,只不过映射函数的参数由RDD中的每一个元素变成了RDD中每一个分区的迭代器。如果在映射的过程中需要频繁创建额外的对象,使用mapPartitions要比map高效的过。
比如,将RDD中的所有数据通过JDBC连接写入数据库,如果使用map函数,可能要为每一个元素都创建一个connection,这样开销很大,如果使用mapPartitions,那么只需要针对每一个分区建立一个connection。
参数preservesPartitioning表示是否保留父RDD的partitioner分区信息。
举一个例子:
var rdd1= sc.makeRDD(1 to 5,2)
//rdd1有两个分区
scala>var rdd3= rdd1.mapPartitions{ x =>{
|var result=List[Int]()
|var i=0
|while(x.hasNext){
| i+= x.next()
|}
| result.::(i).iterator
|}}
rdd3: org.apache.spark.rdd.RDD[Int]=MapPartitionsRDD[84] at mapPartitions at :23
//rdd3将rdd1中每个分区中的数值累加
scala> rdd3.collect
res65:Array[Int]=Array(3,12)
scala> rdd3.partitions.size
res66:Int=2
mapValues(function)
原RDD中的Key保持不变,与新的Value一起组成新的RDD中的元素。因此,该函数只适用于元素为KV对的RDD
scala> val a = sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", " eagle"), 2)
a: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[0] at parallelize at :21
scala>
scala> val b = a.map(x => (x.length, x))
b: org.apache.spark.rdd.RDD[(Int, String)] = MapPartitionsRDD[1] at map at :23
scala>
scala> b.mapValues("x" + _ + "x").collect
res0: Array[(Int, String)] = Array((3,xdogx), (5,xtigerx), (4,xlionx), (3,xcatx), (7,xpantherx), (6,x eaglex)) //"x" + _ + "x"等同于everyInput =>"x" + everyInput + "x"
//结果
Array(
(3,xdogx),
(5,xtigerx),
(4,xlionx),
(3,xcatx),
(7,xpantherx),
(5,xeaglex)
)
flatMap(function)
与map类似,区别是原RDD中的元素经map处理后只能生成一个元素,而原RDD中的元素经flatmap处理后可生成多个元素
scala> val a = sc.parallelize(1 to 4, 2)
a: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at :27
scala> a
res0: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at :27
scala> val b = a.flatMap(x => 1 to x)//每个元素扩展
b: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[1] at flatMap at :29
scala> b
res1: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[1] at flatMap at :29
scala> b.collect
res2: Array[Int] = Array(1, 1, 2, 1, 2, 3, 1, 2, 3, 4)
scala>
紧接着我们来分析源代码的第二句话:
nastats.reduce((n1, n2) => {
n1.zip(n2).map { case (a, b) => a.merge(b) }
})这句话关键是reduce,这个Spark函数接口,还记得nastats是一个RDD[Array[NAStatCounter]]类型的变量,是mapPartitions函数的输出。如何对nastats是一个RDD[Array[NAStatCounter]]类型的变量,进一步的对所有结果进行聚合,最终得到我们想要的Array[NAStatCounter]的结果,便是reduce的工作,其实就是一个简单的聚合。
reduce函数:
输入是一个处理RDD记录中两个记录,输出则是一个聚合的记录。对于这里其实就是对于两个Array[NAStatCounter]进行聚合,得到描述统计量Array[NAStatCounter]。
首先是对于连个Array[NAStatCounter]类型的变量n1,n2做一个zip的映射,此时Array[NAStatCounter]*Array[NAStatCounter]=》(zip)Array[NAStatCounter,NAStatCounter]。然后使用map算子,对于每一个(NAStatCounter,NAStatCounter)聚合成merge,返回一个NAStatCounter。这里其实就是为什么NAStatCounter类定义的merge里返回this的原因。注意这里的zip,map都是在本地操作的,都是scala自带的函数接口,与Spark无关的。在外面的reduce是Spark计算的。本地计算的结果要经过序列,压缩,网络传输,解压,反序列化到master节点。给出最终的结果。这也就是为什么NAStatCounter的定义要extend Serializable。