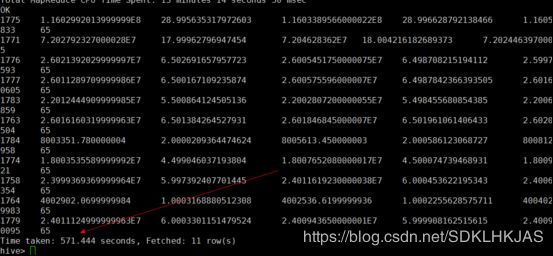
impala 和hive查询性能简单对比
Sqoop 一亿级数据导入测试
用SQOOP从oracel 中把数据倒入到hive中做测试
首先表是这样的
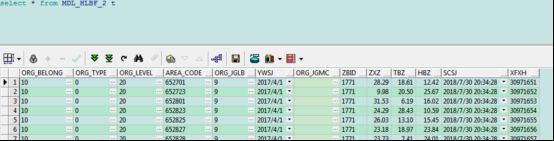
服务器资源

Sqoop 导入脚本
sqoop import --hive-import \
--connect jdbc:oracle:thin:@10.32.3.4:1521/orcl \
--username xjcs \
--password xjcs \
--table MDL_HLBF_2 \
--split-by XFXH \
--hive-table MDL_HLBF_2 \
--null-string '2' \
--null-non-string '3 ' \
--fields-terminated-by '\t' \
--create-hive-table \
--lines-terminated-by '\n' \
--delete-target-dir \
--hive-overwrite \
-m 5 ;
通过shell
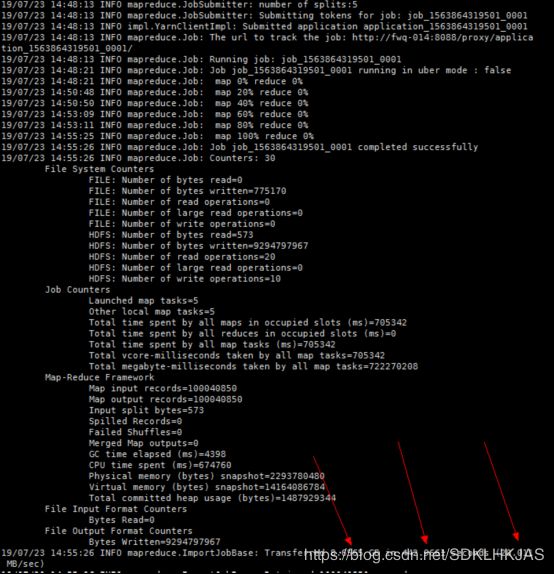
可以发现一亿条数据,12个维度,8.6个G 迁移时间在7分钟
然后在再HDFS上看
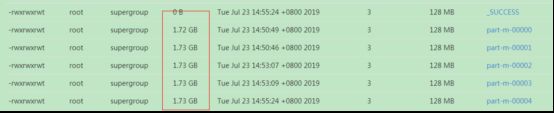
可以看到很均匀
通过hive查看
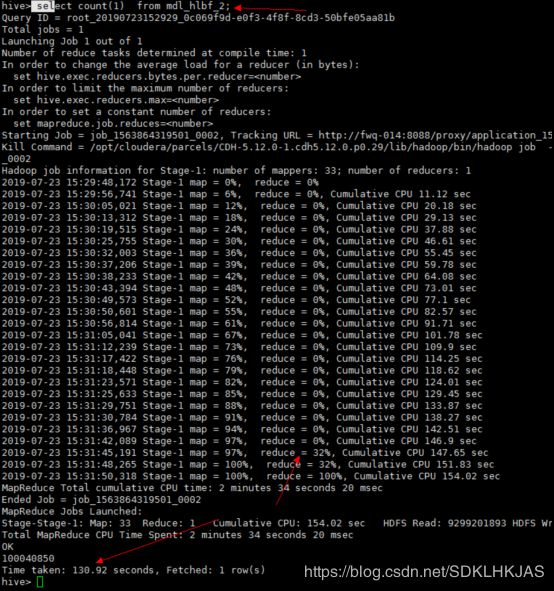
用hive统计行数用时大概2分钟
再次运行
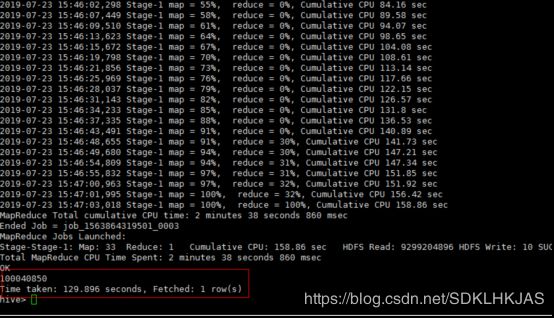
查询时间基本没变!1
再来看下impala查询的速度
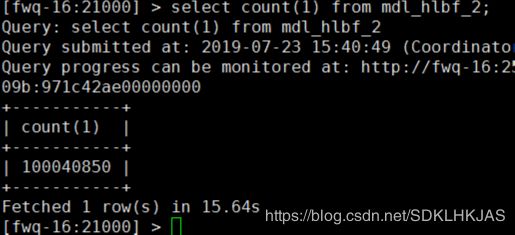
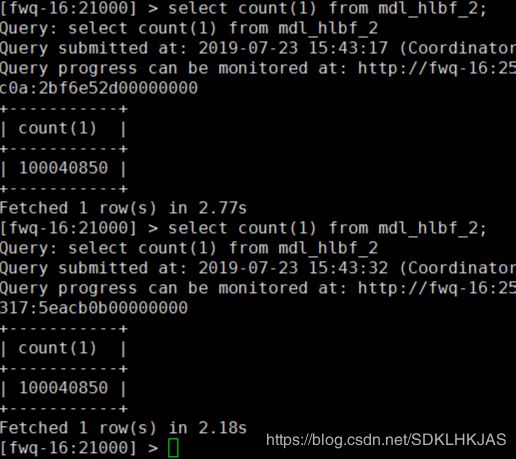
第一次仅仅用了15秒 效率真高 再运行就非常快了3秒不到
再查询一个求和求平均的
SELECT a.ZBID,
sum(a.ZXZ) ZXZSUM, avg(a.ZXZ) ZXZAVG ,
substring(a.AREA_CODE,1,2) AREA_CODE from MDL_hlbf_2 a
where a.ZBID in ('1771', '1763', '1764', '1776', '1777','1774','1775')
and a.YWSJ>='2017-01-01' and a.YWSJ<='2018-12-31'
group by a.ZBID,substring(a.AREA_CODE,1,2);
先看下Hive中执行的结果
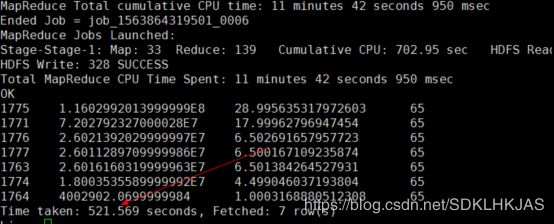
用了近9分钟
再来看下impala中执行的结果
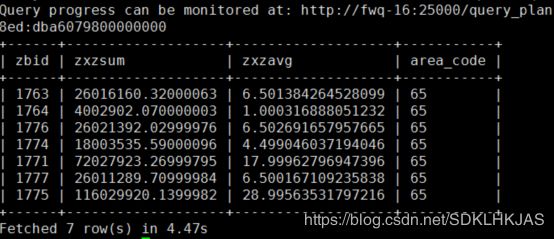
由于迭代查询 效率非常的高
再次加
SELECT a.ZBID,
sum(a.ZXZ) ZXZSUM, avg(a.ZXZ) ZXZAVG ,sum(a.tbz) tbzsum,avg(a.tbz) tbzavg,sum(a.hbz) hbzsum,avg(a.hbz) hbzavg,
substring(a.AREA_CODE,1,2) AREA_CODE from MDL_hlbf_2 a
where a.ZBID in ('1771', '1763', '1764', '1776', '1777','1774','1775','1758','1783','1784','1779')
and a.YWSJ>='2015-01-01' and a.YWSJ<='2019-12-31'
group by a.ZBID,substring(a.AREA_CODE,1,2);
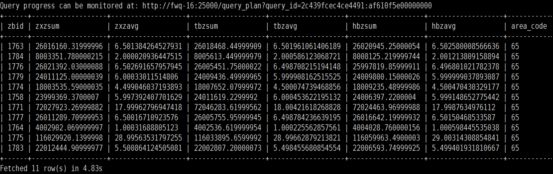
效率不受影响
再看Hive