《手Q Android线程死锁监控与自动化分析实践》
一、问题背景
手Q每个版本上线以后研发同学都会收到各种问题反馈。在跟进手Q内部用户反馈的问题时,发现多例问题,其表象和原因如下:
1、问题表象:“未读不消失”、“图片不展示”、“菊花一直在转” 。。。
2、问题原因:死锁导致的功能不可用。
这类由死锁造成的功能不可用的问题,具有表象简单但影响非常严重的特点。一般用户在遇到这类问题后,除了采取杀掉进程重启的策略,没有其他办法继续使用应用。由此可见,死锁问题对产品的影响是巨大的,那么有没有有效的方法能够监控Android应用的死锁呢?
首先想到的是使用代码规范来避免死锁的发生。手Q有250多个业务模块,400w+行代码,这么多业务代码交叉调用,仅通过代码规范,很难避免死锁发生。
然后想到的是CodeDog的代码工具扫描。与CodeDog同事沟通后,发现Converity静态扫描无法识别嵌套调用使用锁的情况,而锁的嵌套调用是死锁发生场景中一个比较常见的场景。显然通过代码的静态扫描没法解决问题。
既然现成的代码扫描工具无法完全解决问题,只能硬着头皮试着自己造轮子来监控Android线程的死锁问题。
下面将详细介绍这套Android线程卡死监控系统。(注意这里用的词是“卡死”而不是死锁。死锁只是线程卡死原因中比较重要的分类,除了死锁还有许多其他问题造成线程的卡死。)
二、方案详述
2.1整体方案概述
下面是手Q自建Android线程卡死监控的整体方案:
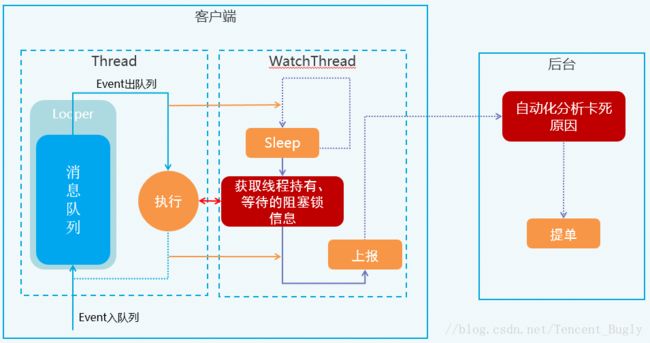
Android线程监控整体方案分为两部分:客户端与后台。
1、客户端:由监控线程(WatchThread)与被监控线程(Thread)组成。
客户端线程的监控的核心主要利用线程的Looper方法,监控线程监控从被监控线程消息队列取出的消息的执行。当监控线程发现一个出队列的消息在一定时间(3分钟,可以自己设定)没有执行完成,则可认定被监控的线程发生卡死。这时,由监控线程获取线程持有、等待的阻塞锁信息,将这些信息上报到后台,客户端部分便完成了使命。
2、后台:由自动化分析工具,分析线程卡死的原因。原因分析完成以后,就可以进行提单,然后再跟进每个卡死问题的解决。
整个方案的关键是上图中两个标红的部分:客户端上报线程卡死的关键信息,后台自动化分析卡死原因。下面将详细介绍这两部的实现。
2.2 客户端上报
2.2.1卡死信息
Android线程卡死监控中客户端上报线程卡死的关键信息,那么哪些信息是关键信息呢?答案很明显:线程信息与线程持有、等待锁的信息。
在如何获取这两类信息之前,先来分析一下Java中锁的分类与特点。
Java中锁的分类有自旋锁、可重入锁、阻塞锁等等分类,其中能够造成线程卡死的锁,只有阻塞锁。对于阻塞锁有如下三种:

根据这三种锁是否有线程等待方和线程持有方,为了达到分析线程卡死的目标,需要获取如下信息:
1、对于sychronized锁:需要获取其持有线程和等待线程。
2、对于LockSupport锁:需要获取其持有线程和等待线程。
3、对于Object锁:需要获取其等待线程。
那么接下来的重点就是如何获取线程的信息与锁的信息上报。
2.2.2 上报方案1:抓取java堆栈—不可行
首先想到的方案是:抓取java的堆栈进行上报。下面是抓取的java堆栈与其对应的代码:

上图中右的代码中121行已经获取了sychornized锁,但是左边的java堆栈中并没有展示对应锁的信息,故使用抓取java堆栈的方式不可行。
既然使用Java抓取堆栈信息不可行,有没有其他方案呢?答案:有。
2.2.3上报方案2:抓取系统Traces.txt——可行
既然抓取java的堆栈行不通,只能寻求其他解决方案。突然想到,Android在发生ANR时有一套系统机制:
1、Android应用发生ANR时,系统会发出SIGQUIT信号给发生ANR进程。
2、系统信号捕捉线程触发输出/data/anr/traces.txt文件,记录问题产生虚拟机、线程堆栈相关信息。
3、这个trace文件中包含了线程信息和锁的信息,借助这个trace文件可以分析卡死的原因。
由此,如果利用这个系统原有的机制,自己在线程卡死时候触发traces文件的形成进行上报,便可以把线程卡死的关键进行进行上报。本监控方案便是利用系统机制进行卡死信息的抓取:
1、当监控线程发现被监控线程卡死时,主动向系统发送SIGQUIT信号。
2、等待/data/anr/traces.txt文件生成。
3、文件生成以后进行上报。
4、当然,这里也有少数Trace文件生成失败的情况,但是,对于手Q大盘监控可忽略。
既然方案可行,就需要分析利用系统机制抓取的信息(所有线程信息、线程堆栈中锁的信息)是否满足需求。下面是一个利用系统机制继续抓取的例子:

右图代码中的synchonized锁信息已经在左边系统dump的堆栈中,由此可见,可以利用这个堆栈进行卡死分析。那是否利用这些信息就足够进行线程卡死原因的分析了呢?
天下永远没有这么便宜的晚餐。
2.2.4上报难点:Traces中没有LockSupport锁的持有者信息
通过分析上报的Traces文件与抓取锁信息对比,sychornized、object锁的信息得到解决,但是LockSupport锁的信息竟然缺少了持有线程。利用系统机制抓取的堆栈,可以获取锁的信息如下表所示:

下面是LockSupport锁无法获取持有线程信息的一个例子:
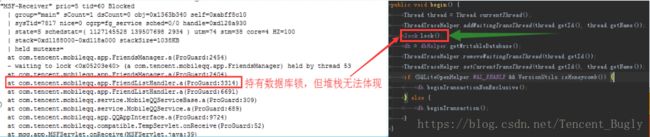
右图的代码在执行lock.lock()之后,线程已经获取了LockSupport锁,但是从左边的系统堆栈中却没有这个锁的信息。
这将是后续进行自动化分析的一个难点问题。那么有没有什么解决方案?通过深入分析手Q的代码,找到了答案。
2.2.5 解决方案:主动记录LockSupport锁的线程信息
解决问题的思路,先人工分析所有上报trace文件,需找关键特征:
1、找到发生死锁时系统dump堆栈的关键特征。
2、人工对卡死问题聚类分析,发现卡死堆栈中locksupport锁的问题全部为数据库问题。
3、再分析手Q的数据库相关代码,发现数据库事务LockSupport锁的入口统一,能够记录获取、等待获取的线程信息。
在上面的分析结论中,为了解决LockSupport没有持有线程信息这个难点,利用发现问题统一、程序代码入口统一的特点,采取下面这一招:
在系统dump的Trace文件中人工记录LockSupport锁信息。
解决方案:在数据库相关的代码中添加如下记录代码。
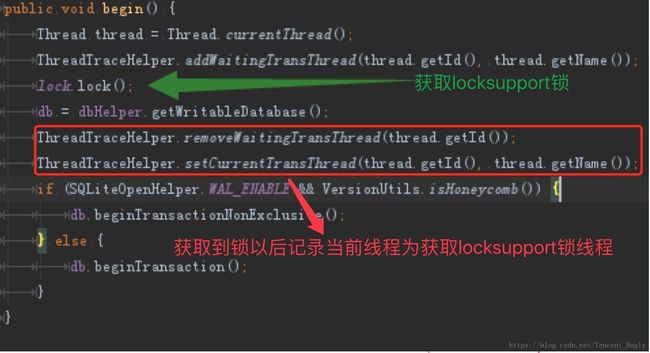
上述代码中,将等待获取LockSupport锁线程记录到等待列表中,获取LockSupport锁以后从等待列表中移除,并记录当前线程(记录当前线程id、name信息)为LockSupport锁的持有线程,当前线程释放LockSupport锁以后再将记录清空。
有了上述记录的LockSupport锁线程信息,只要在卡死形成的traces文件最后添加这些信息,然后再进行上报,这样就解决了没有LockSupport锁持有线程信息的问题。
在traces文件最后一行添加的具体如下图所示:

当然,为了方便后续的问题分析,在trace文件最后一行还添加了其他一些信息,如:被卡死线程的名称、系统版本号、发生时间等等。
目前,客户端已经解决了线程卡死以后上报信息不完整的问题,那么,接下来的重点就是要识别这些卡死的原因,下面章节将详细道来。
2.3 服务端识别
2.3.1识别方案:关键信息上报,自动化分析
服务端识别方案可概述为:关键信息上报,自动化分析。
关键信息上报这是自动化分析的前提。在详述自动化分析方案之前,首先回顾一下到目前为止已经获取到的信息。
1、Traces.txt:所有线程信息、系统dump锁信息(synchonized、Object、LockSupport)。
2、主动记录的LockSupport锁信息(持有线程)。
3、主动识别到被卡死线程。
有了这三个关键的信息,接下来就是进行线程卡死的自动化分析,下面是自动化卡死分析的完整方案:

上图的整体识别方案,详细步骤说明如下:
1、客户端将主动记录的LockSupport锁信息、被卡死线程信息等添加到系统dump的trace文件最后一行进行上报。
2、服务端进行自动化分析时,首先进行预处理:LockSupport锁等待线程信息预处理、线程堆栈proguard还原。
3、从trace文件中提取所有线程持有、等待的锁信息,记录到每个线程中。
4、提取trace文件最后一行记录的LockSupport锁持有线程,从第3步分析的所有线程中找到该线程,并在线程持有锁中加入LockSupport锁。
5、接下来从trace文件最后一行提取出被卡死线程,从被卡死的线程开始分析。
6、被卡死线程是否有等待锁,如果无,则判定为非死锁,进入第12步进行卡死原因分析。
7、如果有等待锁,找到该等待锁的持有线程。
8、该持有线程是否有等待锁,如果无,则判定为非死锁,进入第12步进行卡死原因分析。
9、如果有等待锁,判断该线程是否已经在遍历列表中。
10、如果已经中遍历列表中,判断是否存在锁列表循环,如果是,则判定为死锁。
11、如果没有中遍历列表中,将该线程加入遍历列表中,进入第7步进行循环。
12、非死锁原因分析。目前分为:网络、文件IO、HashMap、系统IPC、抓栈、GC、数据库、ProcessManager、PB、后续扩展。
完成上述自动化分析以后,输出线程卡死问题列表。对于什么是死锁,下面将举例说明。
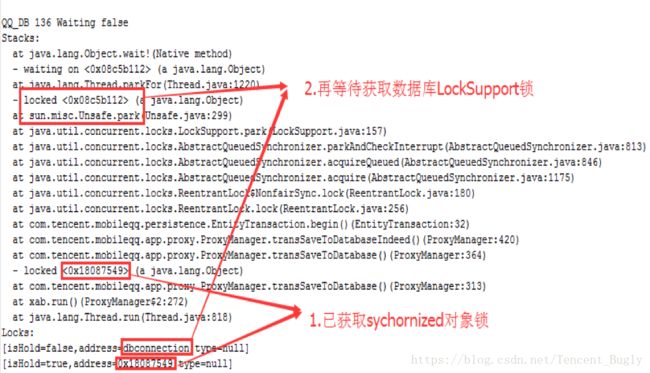
2.3.2 死锁举例:两个线程互相等待对方已获取的锁导致死锁
首先,看发生死锁的两个线程堆栈:
1、 MSF-Receiver线程堆栈:

MSF-Receiver线程已经获取数据库LockSupport锁,等待获取0x18087549锁。
2、QQ_DB线程堆栈:
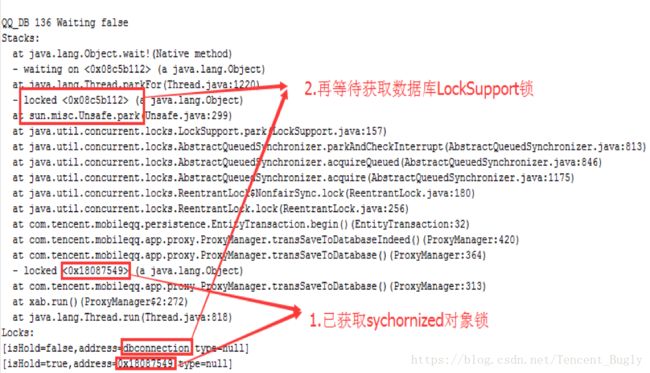
QQ_DB线程已经获取0x18087549锁,等待获取数据库LockSupport锁。
将两个线程获取与等待获取的锁做成一个列表,如下表所示:

从上表可看出:MSF-Receiver线程与QQ_DB线程互相等待对方已获取的锁,他们之间存在锁列表环,判定为死锁。
从这个死锁的列子发现,要做自动化分析死锁,只要能够找到线程之间存在锁列表循环就可以判定为死锁。那么自动化分析是否如想象中那么容易呢?其实不然,在自动化分析过程中,遇到了几个难点问题。
2.3.3 识别难点1:LockSupport等待锁的阻塞地址不同
在自动化分析过程中,发现如下问题:
1、系统dump的线程堆栈中有等待数据库事务的LockSupport锁对象信息。
2、但是同一个LockSupport锁,不同线程阻塞时的对象地址不同。
上面两点是什么意思?还是按照惯例,先看两个线程堆栈:

手Q代码中所有数据库操作,都由同一个LockSupport锁来控制。但是,从上面的系统堆栈来看,Recent_Handler线程阻塞的LockSupport锁对象地址为0x43810d48,而QQ_SUB线程阻塞的LockSupport锁对象地址为0x41fcb538。
由此可见,对于同一个LockSupport锁,不同线程阻塞时的对象地址不同。要进行自动化分析,如果对于同一个锁必须要识别为同一个对象,可是上述堆栈表现却不能完成这个任务。怎么解决?
2.3.4 解决方案: 提取特征,判定为同一个锁
1、LockSupport锁提供调度线程阻塞与唤醒功能。
2、不同线程都与各自LockSupport锁的许可关联,所以造成了不同线程阻塞对象地址不同。
既然这个问题是由于LockSupport锁的实现原理决定,那么是否有解决方案呢?答案是:有。
如果有办法能够让这些不同的地址都指向同一个地址,只要能够做到这件事情,那么问题就迎刃而解。具体的解决方案的分析思路如下:
1、既然阻塞的LockSupport锁对象地址是不同的,那么是否可以寻找系统堆栈中LockSupport锁对象之前的有没有什么共同特征呢?
2、分析所有dump的堆栈后发现,在系统堆栈的LockSupport锁对象之前,有相同的函数调用,可以提取这些关键的字符串,将其统一特征进行归类。
3、在进行自动化分析时,只要发现系统堆栈中有这个字符串特征,便在当前分析线程锁列表中,加入一个人为构造的地址相同的LockSupport锁。
具体构造如下:
上图中提取了字符串“SQLiteConnectionPool.waitForConnection”为等待LockSupport锁的共同特征,在线程的等待锁中加入同一个“dbconnection”锁。
这样就解决了阻塞在同一个LockSupport锁,不同线程阻塞时的对象地址不同的难点。
2.3.5 识别难点2:非死锁问题
对于非死锁问题,人工分析所有上报后,发现卡死原因分类较多,大致可分为:
1、网络、文件IO、HashMap、系统IPC、抓栈、GC、数据库、ProcessManager、PB
2、后续仍然可扩展分类。
对于非死锁问题的判定,这里提出基于堆栈关键词匹配来判定问题分类的方案。
首先,预设堆栈关键字与问题分类对应关系,如:Scoket等。
其次,对未识别的类别的堆栈聚类,人工分析top问题找出关键字符串进行扩展。
再次,完善堆栈关键字与问题类别对应关系。
下表示展示了目前已归纳总结出的卡死问题与对应判定关键字。

重点案例: HashMap卡死
在分析系统dump时,发现多线程访问HashMap会造成卡死,具体卡死原因如下:
1、HashMap在插入元素过多需要进行Resize步骤
2、Resize步骤包括扩容与ReHash
3、ReHash在并发的情况下可能会形成链表环
4、访问HashMap链表环这个位置时造成卡死
解决方案:
1、保证同一时间只有单个线程访问HashMap
2、多线程场景使用ConcurrentHashMap
三、卡死监控与自动化效果
卡死自动化分析后,会输出卡死问题概览列表。以11月7号为例,手Q自动化分析的线程卡死以后,输出以下列卡死问题概览:
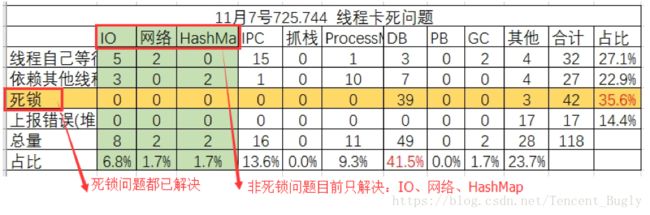
通过以上问题概览,可以看到每类卡死问题的个数与占比,方便问题总结。在这些问题中:
1、死锁问题占比最高,达到35.6%,已经全部解决。
2、其他非死锁问题:
已经解决:IO、HashMap、网络调用。
暂未解决:IPC、ProcessManager、PB、抓栈、GC、文件IO等。
通过几个版本的监控与问题的解决,取得了良好的效果,如下所示:

1、MSF线程卡死率0.3%降低到0.1%,公用线程卡死率0.51%降低到0.18%。
2、730一灰APM使用公用线程造成卡死问题严重,及时发现并推进解决。
总的来说,通过线程卡死的监控与自动化分析,以及对发现卡死问题的及时解决,手Q线程卡死率逐版本下降,卡死问题得到有效控制。
四、后续规划
目前线程卡死监控任然有一些需要完善的地方:
1、目前还是需要中自动化分析问题后进行人工提单。后续需要做到自动化提单。
2、未完全记录LockSupport锁持有信息,目前只是记录数据库,对于其他使用LockSupport锁没有监控。后续采用Hook LockSupport锁的方案,记录完整信息,完善死锁监控问题定位能力。
如果您觉得我们的内容还不错,就请转发到朋友圈,和小伙伴一起分享吧~
