2019DTCC大会分享:分布式数据库全局读一致性

作者简介:李海翔,网名“那海蓝蓝”,腾讯金融云数据库技术专家。中国人民大学信息学院工程硕士企业导师。著有《数据库事务处理的艺术:事务管理和并发访问控制》、《数据库查询优化器的艺术:原理解析与SQL性能优化》、《大数据管理》,广受好评。
分享正文:2019年5月8日,腾讯TDSQL团队为中国数据库技术大会DTCC带来了腾讯最新的数据库核心技术:TDSQL原创的全局读一致性技术。
腾讯专家工程师李海翔在DTCC上做了主题为“腾讯TDSQL全局读一致性”的技术内容分享。本次分享,基于数据库事务处理的核心技术并发访问控制技术和分布式系统CAP理论中的一致性,TDSQL原创性提出了全面地解决读一致性的算法,是的分布式事务的一致性和分布式系统的一致性统一在一起。
如下是本次分享的主要内容,从如下八个角度全面分享了全局一致性的前世今生、光辉未来。
数据库的事务处理技术,解决了什么问题?
分布式事务型数据库,出现了什么新问题?--读半已提交数据异常
业界是怎么解决读半已提交数据异常问题的?
分布式事务型数据库,解决了读半已提交数据异常,就一劳永逸了吗?
TDSQL的事务处理模型
什么是全局一致性?
TDSQL是怎么解决各种数据异常的?
展望未来
数据库是一个高并发系统,所有的操作,通过事务的语义加以约束。而事务的语义,表现为事务的四个特性,ACID。而一个数据库系统,其最核心的技术,就是事务处理技术,为了保障ACID,数据库使用了多种复杂技术,其中,核心技术的核心是并发访问控制算法。
事务处理技术,有两个初衷:一是数据正确性,二是并发高效率。
数据库的操作,把SQL语句的语义简化后,只有读操作和写操作两种。并发操作,就是读写操作的并发,组合后分为四种:读读、读写、写读、写写。其中,读写、写读、写写三种会产生多种“数据异常现象”。常见的数据异常如图1,发生了这些数据异常,就不能保证上述的数据准确性。
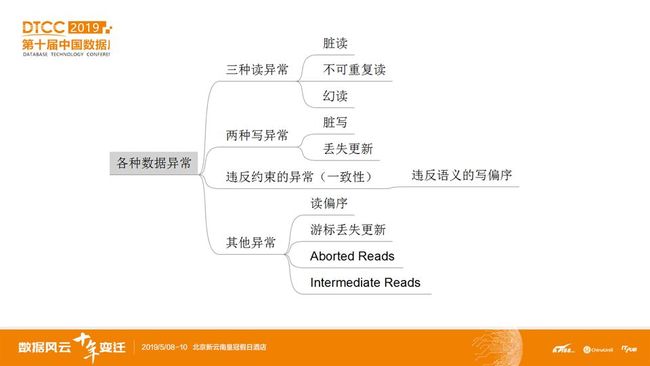
图1 事务型数据库系统的常见数据异常
这么多数据异常(图1列出11种),会带来什么问题呢?其表现,是在数据项上,出现了逻辑上不应该出现的“不一致性”现象。说不一致,抽象难理解,看不出其危害,所以我们用“脏读数据异常”举个简单例子:
一个骗子T2转帐1000元给事务T1,事务T1检查自己的账户,入账了1000元,然后事务T1把一件衣服卖给了骗子T2,之后骗子T2拿到衣服后回滚了转账1000元的操作,然后逃之夭夭了。事务T1既没有拿到钱还丢失了衣服,损失很大。所以要避免这样的异常发生。
所以,数据库的事务处理机制,就是要避免商业交易(并发的交互行为)出现各种使交易任何一方受损的事情发生。
于是,事务型数据库提出了多种并发访问控制算法(如图2)和其他相关技术,确保商业交易正常。用数据库的术语讲,就是确保ACID四个特性。图2中的多种算法,在单机事务隔离级别的可串行化隔离级别,能够确保图1中的各种数据异常不会发生。(小问题,请思考:分布式事务型数据库中的并发访问控制算法,能否确保图1中的各种数据异常不会发生呢?)

图2 事务型数据库的常见并发访问控制算法
二 、分布式事务型数据库,出现了什么新问题?--读半已提交数据异常
在金融支付等业务场景中,对账业务,是支付体系中最重要的一环,也是保证交易、资金安全的最后一道防线。涉及金融的业务,一定要对账。
使用数据库做对账,如图3,有两个物理的节点,Na和Nb分别有两个账户X和Y(X和Y也代表账户余额),现在第一个写事务,要从X账户向Y账户转账10元,当此写事务在Na节点完成提交,但Nb节点尚没有提交(如网络延迟发生、或Nb节点负载重尚没有能执行事务的提交操作)。此时,另外一个分布式事务读事务要做对账操作,其在Na节点读到了已经提交的“X-10”的值,而在Nb节点读到的是“Y”(未提交的不能读),则总账为“X-10+Y”,这个就是数据不一致,因为总账目少了10元钱。数据库系统据不能容忍这种事情发生。

图3 分布式事务型数据库的读半已提交数据异常
对于任何一个分布式事务型数据库,如果基于封锁并发访问机制实现并发事务的可串行化调度,是不会存在这里所讨论的问题的。其原因在于:一旦Na节点写完毕数据,则表明Nb节点至少在Y账户这个数据项上施加了写锁,而新的对账读事务是不能读取Y数据项的值的,其只能等待,因此不会发生对账不平的问题。腾讯TDSQL就是这样的,换句话说,没有实现可串行化的数据库,大概率会存在读半已提交数据异常(小问题,请思考:为什么这里说大概率呢?答案参见图4中的2次读算法)。
但是,如果纯粹使用封锁并发访问控制机制实现可串行化,事务处理的并发度降低,分布式数据库的事务处理吞吐量就会底,这违背了事务处理技术的另外一个初衷:高效。所以类似TDSQL的分布式数据库,用户通常不使用可串行化隔离级别,原因就在于想要使得数据库高效。而如OceanBase、Oracle等数据库,干脆没有实现可串行化隔离级别,而是直接把出现数据异常的危险抛给了用户。
现在,我们再来讨论一下,TDSQL会不会出现“读半已提交数据异常”?
TDSQL除了支持可串行化隔离级别外,还支持可重复读(RR)、读已提交(RC),但这2个隔离级别,同另外一种并发访问控制算法、MVCC技术紧密绑定,绑定的原因,是为了提高并发度,使得读写、写读操作互不影响。就是在MVCC机制下,TDSQL出现了“读半已提交数据异常”,为什么呢?
因为前述“在Nb节点读到的是“Y”(未提交的不能读)”就是Y的旧版本,而不是未提交的新版本,这是MVCC机制决定的(小问题,请思考:是不是所有使用MVCC技术的,都得小心是不是存在“读半已提交数据异常”啦?是哈,得小心+小心。要不然,账目不平可就解释不清楚了)。
其实,业界目前没有特别好的解决方式。如图4,典型的解法如下5类:
第一种:全局事务管理器架构。典型的例子如PostgreSQL-XC,其存在一个全局的事务处理节点,用于解决整个分布式系统分为内的所有事务冲突,这样需要把各个子节点的事务相关信息都发送给全局唯一的事务处理节点,不光通信量大,而且存在单点瓶颈,限制了事务的处理能力。
第二种:TDSQL以封锁机制实现全局可串行化。前述已经分析过,不再赘述。
第三种:物理时钟,全序排序事务降低并发度。典型的例子如著名的Spanner。Spanner彻底地解决了所有数据异常,这是通过实现所有以事务为单位的事件全序排序来完成的。换句话说,实现了线性一致性和事务的可串行化隔离。但是,Spanner以Truetime机制全序排序事务的方式,降低了并发度,导致其分布式事务的吞吐量很低,效率甚至低于基于封锁的并发访问控制下的可串行化实现(即:以线性一致性串起了事务一致性,所以理论上看,Spanner每秒数百个的事务的吞吐量使得效率低到了极限)。
第四种:混合时间戳机制,实习局部偏序排序。典型的例子如仿Spanner的CockroachDB,通过SSI实现了可串行化解决了事务类型的数据异常,但是不能解决全局读一致性的问题(需要全局排序才能解决全局读一致性问题,但混合时钟机制做不到全局有序)。另外,如果选择非可串行化隔离级别,则和Spanner一样,还是可能会出现“读半已提交数据异常”。
第五种:特定的解决机制--两次读机制。2次读机制,源自学术界《Scalable atomic visibility with ramp transactions》这篇paper。其核心思想,是在Na和Nb节点第一次分别读到“X-10”和“Y”这两个版本后,通过特定算法识别这两个数据不是出于一个一致的点,所以重新去Nb节点再读一次,这时,因为一段时间过去了,Nb节点大概率完成提交,读到的数据很可能是“Y+10”,因而可以保持对账不出现差错(X-10+Y+10=X+Y,账目保持平衡)。但是,两次读延迟了事务的执行,降低了整个事务的吞吐量;更重要的是,这种解决问题的方式,只针对“读半已提交数据异常” (小问题,请思考:如果有新的数据异常,还需要读2次数据吗?)。
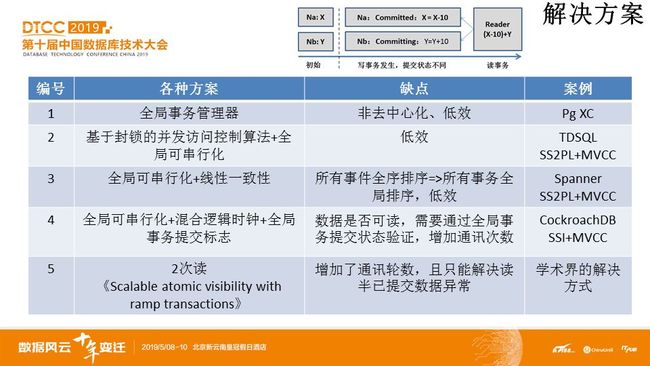
图4 数据库界对“读半已提交数据异常”主流的解法
如标题所言,分布式事务型数据库,解决了如图1和图3提及的各种数据异常之后,是不是就完美了呢?答案是否定的。
一波未平一波又起。
很不幸,图5有给出了新的数据异常。在《Distributed snapshot isolation: global transactions pay globally, local transactions pay locally》这篇Paper中,称之为“Cross数据异常”。
图5列出两类分布式系统下的数据异常,,其中第一类本质上就是“读半已提交数据异常”,而第二种“Cross数据异常”,其发生的背景,依然可以放到金融对账的业务背景中来理解。请看图5右子图部分,有两个物理节点,分别执行了本地事务和分布式事务。事务s和t是本地事务,修改了不同的数据项;事务x和事务y是两个分布式事务,都在读取数据;两个分布式数据读取数据被本地事务影响,读到了不一致的数据,事务x读到的是(a0,b1),事务y读到的是(b0,a1),而数据的一致状态要么是(a0,b0)要么是(a1,b1)。从业务的角度看,事务x和事务y都发起对账,结果对出来的结果不仅不同而且还是一个临时状态对应的结果,这就是数据异常,对账业务不能容忍此类事情发生。
数据库内核层,解决这样的数据异常,通常的方式,是通过建立事务之间的读写依赖关系图,从中看是否有环存在,如果有则表明数据异常出现,因而需要打破环,即回滚其中某个事务,避免问题出现(小问题,请思考:会不会还有新的数据异常呢?数据异常如果也层出不穷该怎么办?)。

图5 新的数据异常—Cross异常图
先来分享一下TDSQL的事务处理框架,这个框架,可以用图2来做大的知识背景。
首先,TDSQL第一代的事务处理模型,采取了图2中的基于封锁的并发访问控制协议和MVCC并发访问控制协议,混合解决并发冲突问题。所以图6中给出的SS2PL整体就是封锁的并发访问控制协议,然后用2PC技术来实现提交阶段的原子写操作。这是整体架构。
在具体实现冲突解决的时候,需要结合MVCC和隔离级别,来解决各种数据异常。这就要区分写写冲突、读写冲突和写读冲突三种具体的情况。
写写冲突,通常依靠封锁机制。原理较为简单,不再赘述。
读写冲突和写读冲突,则借助MVCC来避免锁造成的延迟事务执行的问题,使得后者能继续继续,提高了并发度,所以主流的数据库基本上都实现了MVCC机制。

图6 TDSQL第一代分布式事务处理架构图
其次,TDSQL第二代的事务处理模型,新支持了图7基于OCC(乐观并发访问控制技术)和DTS(动态调整时间戳的并发访问控制技术)的技术,使得TDSQL的分布式事务处理能力产生了质的飞跃(OCC使得并发度提高,DTS使得并发访问控制算法去中心化),分布式事务处理性能提升数倍,并减少了对中心化时间戳节点的依赖,在分布式事务处理的去中心化的道路上,迈出一大步。
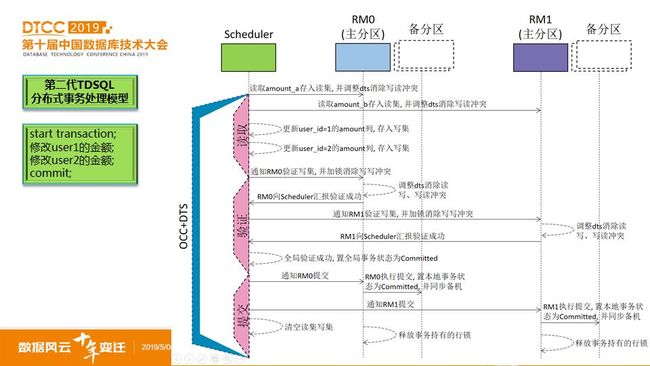
图7 TDSQL第二代分布式事务处理架构图
还记得标题四中的小问题不?小问题,请思考:会不会还有新的数据异常呢?数据异常如果也层出不穷该怎么办?
现在,我们正面来谈谈,什么是全局读一致。目的就是一劳永逸的解决各种数据异常。
在单机数据库时代,数据库理论中有个“可串行化”技术,对应到了隔离级别中的可串行化隔离级别,因为理论上把所有事务都排序,消除了并发,因而不会再有数据异常产生。
但是,在分布式数据库时代,为了提高效率不想使用全局事务管理器限制并发,就采用了去中心化的架构设计分布式数据库;不想使用有额外成本的原子钟等,但又得解决各种数据异常,因此“可串行化”就不够用了(“可串行化”的本质就是在排序)。
再加上,分布式系统,存在各种不确定性,如网络发生分区、瞬间闪断、延时等,使得发生在分布式系统内的读和写事件反序(与发生的顺序相反)到达某个节点,这就又为分布式数据库识别事件之间的先后逻辑关系带来困难。为了规避这些问题带来的“逻辑认识上的困扰”,分布式系统中提出各种“一致性”,如线性一致性、因果一致性、单调写、写后读等各种问题(这些问题参见图8左子图)。
因此,分布式事务型数据库其核心要解决的问题就是:同时满足2个一致。一是分布式读一致性,二是分布式事务一致性。我们把这两种一致性,称为“全局一致性”(注意不是全局读一致性哦)。
分布式读一致性(即全局读一致性),从外部用户的视角,观察数据库内部发生的事件产生的结果之间的顺序要与事件发生的实际顺序保持一致,不能A事件先于B事件发生,但先不到B事件的结果后才可能看到A事件的影响。这意味着,需要对实际发生的事件进行排序。
而对于分布式事务型数据库,是从数据库内核层的角度,保证并发的事务之间,能造成数据异常的情况(读写依赖关系图形成了环)下部分事务被回滚或阻止其发生。及确保事务的可串行化。
如上两者都被保证的情况下,数据异常可被杜绝。Spanner就是从分布式读一致性中的线性一致性出发,约束了事务使之串行提交而保证无数据异常的,这好比用一根竹签先后串起了两种一致性需求(但效率因事务提交需要等待而低下),确保所有的事件全序排序杜绝任何异常。
但是,正式提出一个问题:大问题,请思考:有没有高效的方式确保全局一致性?
答案是:有。请看下一节,TDSQL的解决技术。
注意本文的概念变化:标题是全局读一致性,这是引子;但到本节发展成为了全局一致性;概念的变迁,有其内在的因素,请多体会哦。

图8 全局一致性图
让我们回顾一下TDSQL的发展史,TDSQL2017年推出分布式事务处理技术,2018年推出全时态数据库系统。在全时态数据库技术中,提出一个“全态数据可见性判断算法”。
这个算法,初衷意在解决“分布式事务型数据库中,全态数据在任何时间点上怎么能够读到一致的数据”这样的问题(算法参考腾迅论文《Efficient time-interval data extraction in MVCC-based RDBMS》)。但是,以这个算法为基础,还可以做到全局一致性。更多技术,请参考VLDB 2019,腾讯论文《A Lightweight and Efficient Temporal Database Management System in TDSQL》。
如图9左上子图所示:
初始时刻t0:r11、r21、r31三个初始的数据项分布式在不同的物理节点上,此时这三个数据项处于一个“一致的”状态。
t1时刻:r11被修改为r12,此时之后,r12、r21、r31三个数据项处于一个“一致的”状态;虚线表示了他们处于一致状态。
t2时刻:r21、r31同时被同一个事务修改,分别变为了r22、r32,所以事务提交后,r12、r22、r32这三个数据项处于一个“一致的”状态。
其他时刻依次类推。
不支持全时态的数据库,只有当前态,所以DML类操作,只读取最新数据即可。
支持了全时态的数据库,需要从历史上任何一个点出发,找出这个出发点对应的处于一致性状态的数据。所以怎么标识哪些数据的所有值(当前值、历史值)和事务之间的关系,是全时态数据库当初解决的一个问题。
现在,有了如上这个基础,做到全局一致性,就容易了很多。所用技术如图9右子图部分。
写写冲突封锁机制互斥:对于前面我们提到的写写冲突,还是依靠封锁机制解决,避免丢失更新等数据异常发生。
MVCC从新版本到旧版本:基于MVCC,可以使得读写和写读冲突并发执行,提高了事务处理的效率,不然数据库系统性能一塌糊涂不可使用。另外,使用MVCC,读区版本的顺序是有讲究的,从最新版本开始读就要求构造版本链的时候版本由新到旧。
局部节点处于Prepared状态:在MVCC背景下,修改可见性判断算法,当数据在2PC阶段所有节点同意提交后,正常情况下事务就一定能够提交(系统故障发生后可被恢复),这时,数据即对满足快照的事务可见。
全局事务Committed状态:设立全局事务提交状态,当协调器在2PC阶段所有节点同意提交后,即可设置事务状态的全局标志为Committed(注意不是Prepared),然后通知子节点设置各自状态为Prepared的。只有全局提交标志为Committed,事务读取到的数据才是合法数据,可参考如图8中的左下子图部分,表示了分布式父子事务之间状态导致可见性的关系。如上2点,避免了前述的读半已提交数据异常。
异步、批量设置本地事务状态:协调器上全局事务状态信息,异步地发给涉及的各个子节点,完成子节点上原子事务状态的Committed化。这点是性能优化的问题。
全局逻辑时钟(非跨城/洲分布):使用全局逻辑时钟,为事务建立全局一致的快照,即用SI技术(快照技术),确保全局读一致性。
冲突可串行化:协调器同时判断是否存在冲突环,以解决Cross类型的数据异常。(小问题,请思考:还有没有别的办法解决cross异常?)
如此,TDSQL实现了全局一致性,即达到了外部强一致性和事务一致性的统一。这里介绍了主干流程,为了提高效率,TDSQL又做了很多优化点,以提高事务的吞吐量。

图9 TDSQL全时态数据库的核心技术—全态数据可见性判断算法
但是,再次正式提出一个问题:大问题,请思考:有没有更高效的方式确保全局一致性?
TDSQL一直走在探索分布式事务处理的道路上,走过的路充满挑战(图10)。团队同时享受到了战胜挑战带来的“不可言而此处无声胜有声的与我心有戚戚焉”乐趣。
前进的途中,TDSQL携手中国人民大学教育部数据工程和知识工程重点实验室,采用动态时间戳解决事务冲突并去中心化全局时间戳依赖、用data-drive技术减少事务冲突、用细粒度减少事务冲突等,实现分布式事务处理能力,提升TDSQL分布式事务处理的效率。期待有机会就这些技术进行分享。

图10 TDSQL分布式事务、分布式一致性处理技术展望
特别感谢中国人民大学教育部数据工程和知识工程重点实验室,与腾讯TDSQL携手,共同研发了本文分享的技术。
