实时人脸特征检测——模型部分
问题定位:给定框出的人脸像素矩阵,判断对应图片的性别、表情
即给定inputs和labels,我们这一步所需的仅仅是模型建构及调优
Abstract:
1. 什么是卷积
2. 模型架构——Xception以及其由来
3. 模型性能
4. 细节优化工具及原理,选择原因
5. 为实时性做的工作
一、首先,什么是卷积,卷积一词来源于数学,其定义f卷积g就是对所有满足条件a+b=n条件下f(a)*g(b)的和,而CNN中的卷积实际上是对应位置相乘再相加,也就相当于上式a=b,事实上,只要我们把卷积核旋转180°(也就是说我们看到的卷积核是旋转后的),就完成了这个转化,而且很显然,这对结果没有丝毫影响。
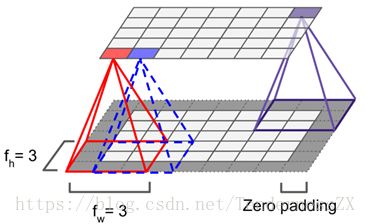
如上图,框(卷积核)框的位置数值和框中数值对应相乘相加即为输出层的一个元素。这只是在二维空间上,而我们的彩色图片都是在三维空间的,其实方法也类似,只不过框变成了立体的。

其做的工作也是框起来的位置相乘相加,这作为输出里一层中的一个元素,而我们看到输出不只一层,这是不同个卷积核作用完结果堆叠在一起得到的(卷积此处只简单介绍到这里,想深入了解的同学推荐吴恩达深度学习视频中CNN部分以及hand on machine learning英文教材对应章节)。
二、对于模型的选择,我们使用的是Google2016年最新的模型Xception,其实Inception模型的极致版,首先简单介绍一下Inception的由来:我们知道,通常的卷积是同时进行跨通道相关性和平面相关性特征的提取,而Inception的提出者认为跨通道相关性和平面相关性应该充分解耦而不是同时提取,他们是这么做的:用1*1卷积提取跨通道相关性,将结果分为多分,每份单独提取其空间特征(注意此处也是空间,不是平面,也就是说没有做到完全解耦,这也就引出了后面Xception的构想),以下是Inception主体模块的简化版:

将输入分为多份,分别进行1*1卷积,1*1卷积加上3*3卷积,平均池化(池化这里不作为重点)加上3*3卷积以及1*1卷积加上5*5卷积(因为步长为1,5*5可以分成两个3*3的叠加)。以上是较常见的Inception模块,即1*1卷积后分别进行更高不同尺寸的卷积,我们考虑一种特例,1*1卷积后全部为同尺寸卷积,如下:

这种结构等同于如下:
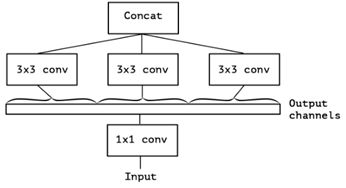
即先统一做1*1卷积,然后分为三份,每份再做不同的3*3卷积。这样,问题就来了:为什么是三份,也就是说,份数是一个超参,增加份数会不会取得更好的结果?还有就是Inception之前的构想是要将跨通道相关性和平面相关性解耦,而现在显然解耦不够充分,这就引出了Xception——extreme inception模型,它的构想是:跨通道相关性和平面相关性应当完全解耦,而这一构想和原本实现的深度可分离卷积不谋而合,基于这,Xception很容易就实现了,如下是它的初版模型:

仅仅是构想肯定不能令人信服,那在实际表现上如何呢?
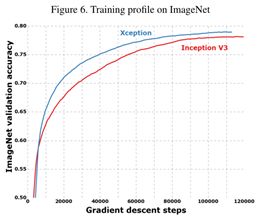
三、Xception作者在公认的计算机视觉大赛上的一千种图像分类数据上给出了Xception和它的“父亲”——Inception的比较:
以及在更大规模的多标签图片数据集JFT上的测试
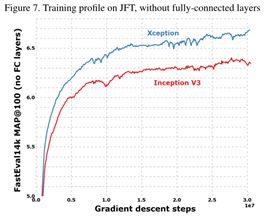
很明显,Xception表现更为出色,尤其是在规模更大的数据集上。注意!!!此处的比较是基于两者优化器等相同参数规模相当前提下的结果,也就是Xception不是通过增加模型容量来使结果准确,而是它对参数的利用率更高!
四、在模型自身优化部分,由于篇幅关系不详细说明,简单介绍一下,Xception增加了残差项来防止退化和加速训练过程,知道其原理这一点会很容易理解(其实残差网络有点差分放大器的意思)

然后就是用了非饱和激活函数Relu
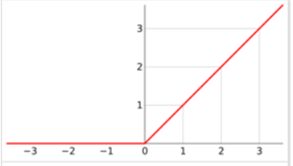
为什么用激活函数?是因为防止一味的线性操作叠加而使加深网络没有意义(因为一堆线性叠加理论上用一个线性就能将所有线性表示),为什么用非饱和激活函数是因为要减少梯度衰减,这里又涉及到了BP的知识了,简单来说就是模型参数更新是通过梯度下降的方式进行,也就是说参数都要减去最终差分项对此参数偏导的一部分,而偏导的计算是基于链式求导法则,就是说一处的偏导是前面很多项乘积,这样只要大于1的项比少于1的项多很多就会造成梯度爆炸,参数爆炸式更新,不收敛,如果少很多就会造成梯度衰减,就是说前面层参数变更会很小甚至得不到训练,而当利用饱和激活函数如sigmoid函数时,当x很大或很小时,偏导接近0,累乘结果接近0,导致梯度衰减

然后就是正则化,正则化是为了防止模型过拟合,为什么会发生过拟合?

过拟合其实就是模型的你和能力太强,以至于成了“记忆力”,表现在图像上就是微小的变动导致y很大的变动。也就是对于y=ax+b来说a小就会防止上述情况,也就是参数要控制值不能太大,对应的有l1、l2正则(就是把参数矩阵的1范式/2范式乘系数加到差分项上去,因为差分项是要降低的项,所以参数矩阵1/2范式也会控制住,一定程度上制约过拟合现象),dropout、增加是数据和early stop等,原理不一一说明了,在此我们用的是l2正则和early stop结合。然后在优化器上采用的是adam优化器,其实动量优化器和RMS优化器的结合产物,一般情况下效果都较其他优化器速度快,想深入了解以上的推荐hand on machine learning一书。
五、然后就是总结一下我们为达到实时性做的工作,首先,我们目标是处理视频中每帧像素的数据,也就是说预测速度要控制在毫秒量级,而一般的CNN、DNN模型很容易达到秒的量级(那不是视频,是ppt了有木有!),考虑到模型预测快慢最直接的影响因素其实就是参数个数,为降低参数量,我们做的工作如下:1.把模型最后的全连接层改为全局平均池化,之前的全连接是将最后一层输出的maps(例如width*height*depth)拉成一条线(1*1*(width*height*depth))然后对应输出类别(本例中表情分类为7)二者做一个全连接,也就是二者相乘才是其中的参数量,这显然很庞大,尤其是当全连接层不止一层的时候,我们在此采用的全局平均池化没有任何参数,只是把对应的depth层每层的平均值输出,逼迫模型去学习全局的东西,虽然效果上不会比全连接层有什么提升,但是也不会太差,最重要的是速度明显加快了,速度和准确度的一次balance。2.激活函数使用relu,relu前面有提到过,非饱和函数,它另一个优点就是快,因为relu就是max(a,b)相当高效。
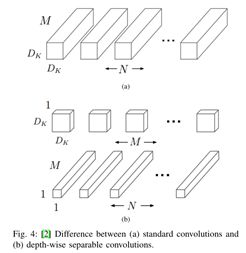
3.利用深度可分离卷积,我们知道,一般的卷积核是一个width*height*depth的参数量,而深度可分离卷积则是一个width*height*1和一个1*1*depth的加和,一个加和一个乘积,数量可想而知,而且卷积个数其实是很多的,所以一定程度上也做到了参数量减少。
未完待续。。。