人脸方向学习(十):Face Detection-MobileNet_SSD解读
整理的人脸系列学习经验:包括人脸检测、人脸关键点检测、人脸优选、人脸对齐、人脸特征提取五个过程总结,有需要的可以参考,仅供学习,请勿盗用。https://blog.csdn.net/TheDayIn_CSDN/article/details/93199307
MobileNet_SSD解读
论文地址:https://arxiv.org/pdf/1704.04861.pdf
Mobilenet地址:https://github.com/shicai/MobileNet-Caffe
MobileNet_SSD地址:https://github.com/chuanqi305/MobileNet-SSD
思路
做人脸检测和红外人脸检测方案时,准备训练SSD人脸检测模型,采用chuanqi305里面的代码,从XML生成LMDB数据并训练检测模型,效果还可以,在移动端设备上300ms左右耗时。下面是网络以及调用mobilenetv2网络结构介绍,后续给出实验数据。
一、论文简介
mobileNets是为移动和嵌入式设备提出的高效模型。MobileNets基于流线型架构(streamlined),使用深度可分离卷积(depthwise separable convolutions,即Xception变体结构)来构建轻量级深度神经网络。论文介绍了两个简单的全局超参数,可有效的在延迟和准确率之间做折中。这些超参数允许我们依据约束条件选择合适大小的模型。论文测试在多个参数量下做了广泛的实验,并在ImageNet分类任务上与其他先进模型做了对比,显示了强大的性能。
1、mobilenet主要是为了适用于移动端而提出的一种轻量级深度网络模型。
主要使用了深度可分离卷积Depthwise Separable Convolution将标准卷积核进行分解计算,减少了计算量 。

2、引入了两个超参数来减少参数量和计算量
宽度乘数α主要用于减少channels,即即输入层的channels个数M,变成αM,输出层的channels个数N变成了αN, 所以引入宽度乘数后的总的计算量是:

分辨率乘数ρ主要用于降低图片的分辨率,即作用在feature map 上 ,所以引入分辨率乘数后的总的计算量为:

3、标准卷积核相比计算量比率

4、深度可分离卷积是将一个标准的卷积核分成深度卷积核和1x1的点卷积核。
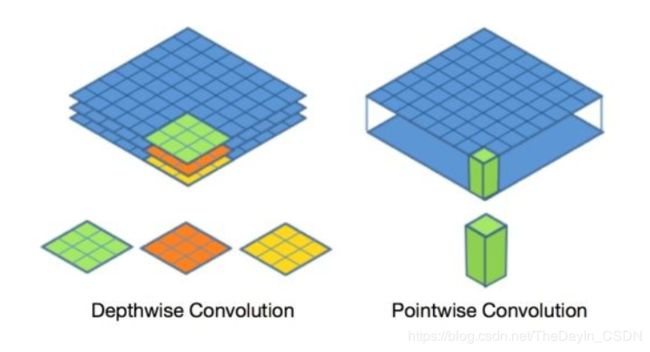
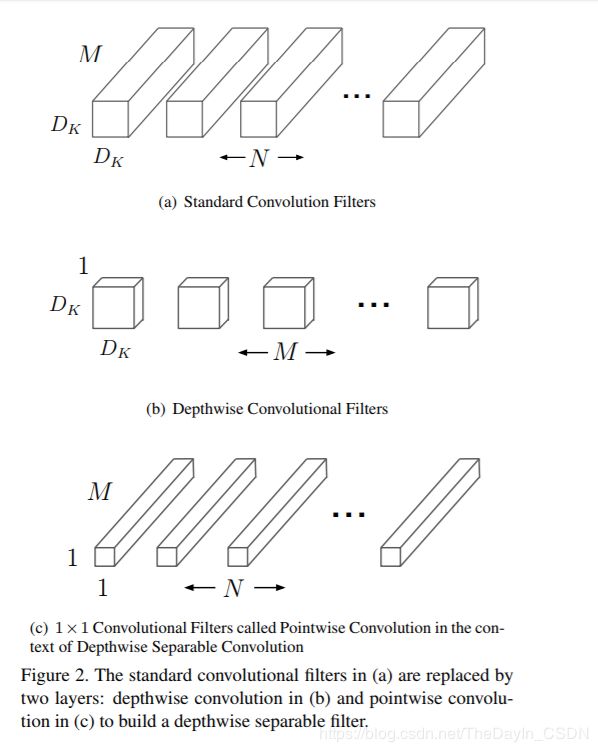
5、mobilenet共28层(深度卷积和点卷积单独算一层),每层后边都跟有batchnorm层 和relu层 。

6、网络结构
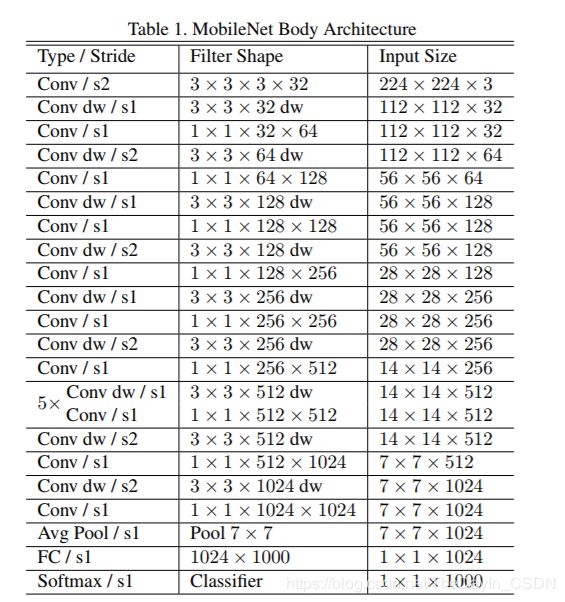
7、网络结构可视化
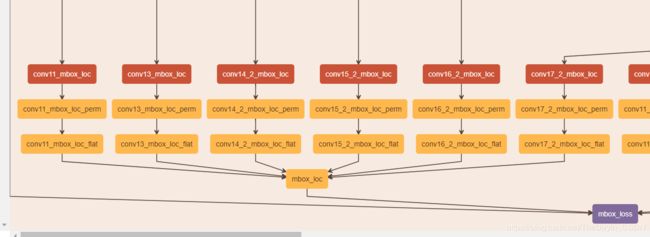
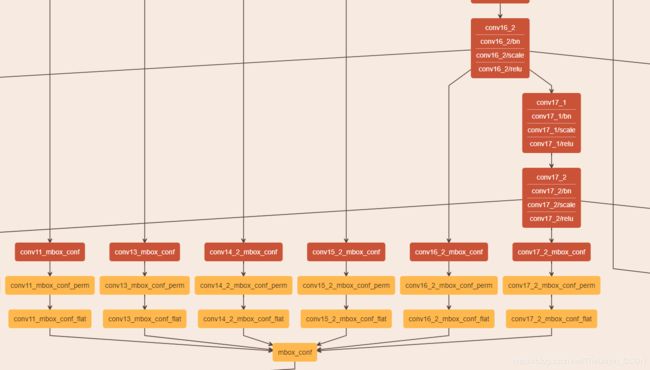
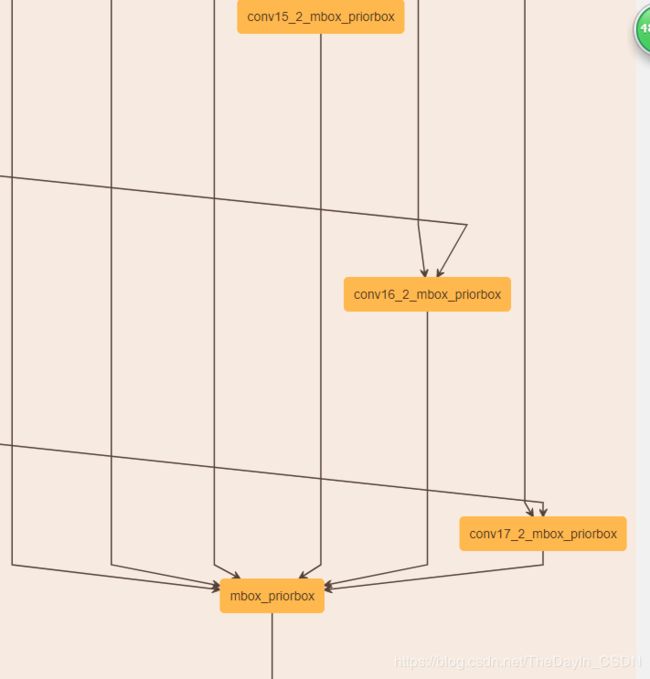
1)conv13是骨干网络的最后一层,作者仿照VGG-SSD的结构,在Mobilenet的conv13后面添加了8个卷积层,然后总共抽取6层用作检测。 提取默认框的6层为conv11, conv13, conv14_2, conv15_2, conv16_2, conv17_2,该6层feature map 每个cell产生的默认框个数分别为3,6,6,6,6,6。也就是说在那6层的后边接的用于坐标回归的3*3的卷积核(层名为conv11_mbox_loc……)的输出个数(num output)分别为12,24,24,24,24,24,24。
2)conv11_mbox_conf后面那6层后边接的用于类别得分的3*3卷积核(层名为conv11_mbox_conf……)的输出个数为3*21(类别为21类,3个默认框) = 63,126, 126, 126, 126, 126。这里假如是人脸加测,则为2类。
3)输出
mbox_loc:回归出的人脸框位置
mbox_loss:分类回归总的loss函数
mbox_conf:人脸分类置信度
mbox_priorbox:NMS过滤最大人脸框。
8、实验结果
1)因子
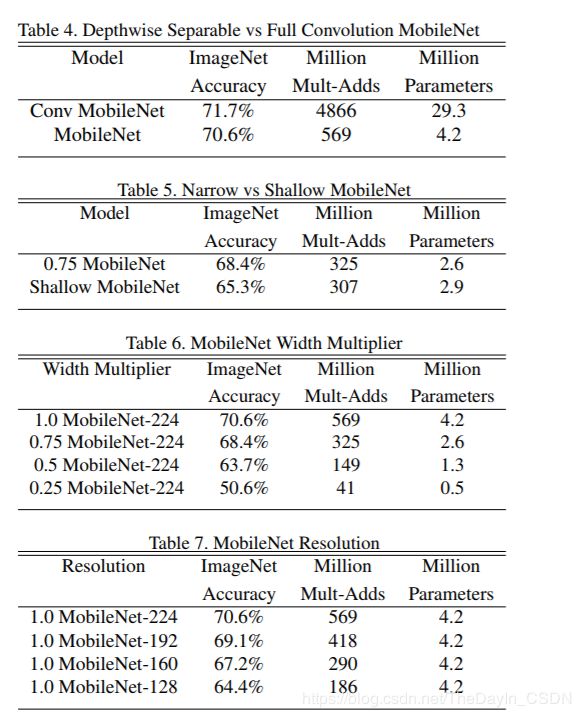
table4:使用深度分类卷积的MobileNet与使用标准卷积的MobileNet之间对比
table5:将MobileNet中的5层14×14×512的深度可分离卷积去除实验结果对比
table6:单个宽度因子对计算精度的影响
table7:分辨率因子对计算精度的影响
2)性能对比
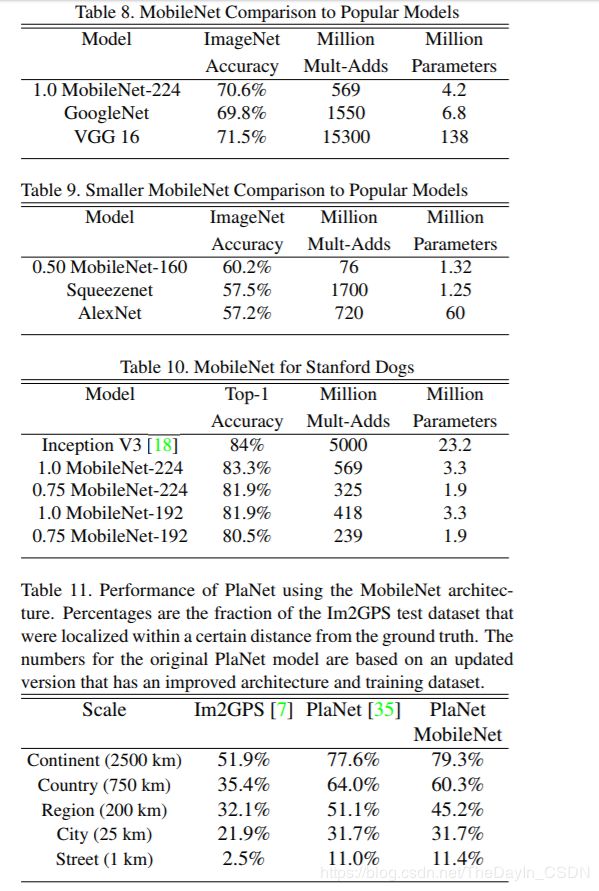
table8:将完整的MobileNet与原始的GoogleNet和VGG16对比,MobileNet与VGG16有相似的精度,参数量和计算量减少了2个数量级。
table9:MobileNet的宽度因子α=0.5,分辨率设置为160×160的缩小模型与其他模型对比结果,相比于AlexNet在计算量和参数量上都降低一个数量级,对比同为小型网络的Squeezenet,计算量少了2个数量级,在参数量类似的情况下,精度高了3%。
table10:Stanford Dogs dataset的表现,MobileNet在计算量和参数量降低一个数量级的同时几乎保持相同的精度。
table11:PlaNet是做大规模地理分类任务,我们使用MobileNet的框架重新设计了PlaNet,基于Inception V3架构的PlaNet有5200万参数和574亿的mult-adds,而基于MobileNet的PlaNet只有1300万参数(300个是主体参数,1000万是最后分类层参数)和58万的mult-adds,相比之下,只是性能稍微受损,但还是比原Im2GPS效果好多了。
9、相关资源
Mobilenet-SSD的Caffe系列实现
https://blog.csdn.net/jesse_mx/article/details/78680055
caffe-MobileNet-ssd环境搭建及训练自己的数据集模型
https://blog.csdn.net/cs_fang_dn/article/details/78790790
用caffe-ssd框架MobileNet网络训练自己的数据集
https://blog.csdn.net/renhanchi/article/details/78423343
基于ubuntu14.04的Mobilenet_SSD环境搭建
https://blog.csdn.net/chenjiehua123456789/article/details/78683551
caffe-MobileNet-ssd环境搭建及训练自己的数据集模型
https://blog.csdn.net/cs_fang_dn/article/details/78790790
树莓派3B+英特尔神经计算棒进行高速目标检测
https://cloud.tencent.com/developer/article/1079212
深度学习 + OpenCV,Python实现实时目标检测
https://www.aliyun.com/jiaocheng/516658.html
github资源:
Caffe for SSD:https://github.com/weiliu89/caffe/tree/ssd
MobileNet-SSD:https://github.com/chuanqi305/MobileNet-SSD