When Will You Arrive Estimating Travel Time Based on Deep Neural Networks
1. 背景
这是一篇发表在2018AAAI上面的文章,其目的是通过对历史车辆轨迹的学习,然后用于预测车辆的通勤时间(Travel Time Estimation),也就是给定一条路径,然后预测从起点到终点所需要的时间。
在先前的论文中,对于一条路径travel time的预测主要有两种方式:Individual vs. Collective,也就是单独预测和整体预测。所谓单独预测就是将整个路径划分为若干个连续片段,并且预测每个部分的travel time,最后将所有的travel time相加作为整个路径的travel time。而整体预测则是直接预测整个travel time 不再进行分割。单独预测的优点在于能够准确的预测每个部分的travel time,但缺点在于不能够处理复杂的交通情况,例如包含十字路口、红绿灯、转向操作等;同时也不能很好的考虑到各个片段之间在空间和时间上的依赖关系。整体预测的缺点在于数据的稀疏性,因为预测路径越长,到后面轨迹点越少(对于这句话我也不是特别理解,原文如下:)。
However, as the length of a path increases, the number of trajectories traveling on the path decreases, which reduces the confidence of the travel time (derived from few drivers), pointing out that longer path is harder to estimate. Moreover, in many cases, there is no trajectory passing the entire path
因此,作者在这篇论文中选择的是将这两种方法结合起来。
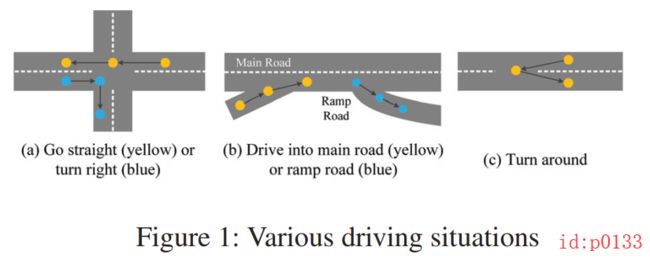
接着,如图p0133(a)所示,在现实情况中每个轨迹的都可能伴随着不同的情况(直行、转弯、转向等)。而想要直接地来提取这些特征显然是困难的。同时,这些空间上的特征分布还伴随着时间上的变换。以图p0133(b)为例,在高峰时期,从主路上的速度快而辅路上的速度慢,因此从辅路进入主路耗时较多,从主路进入辅路耗时较少;而在非高峰时段,进入主路的时间会相对减少。其实还可以举出另外一个例子,在上下班高峰期和非高峰期,通过同一段路程的时间肯定是不一样的。
从作者的分析的确可以看出,这种轨迹数据的确在空间和时间上确实有着不同的特征分布,符合时空数据的特征。因此看到这儿,论文的所提出的模型中自然就是少不了CNN和RNN这两大利器了。可是该怎么通过CNN来刻画轨迹点空间上的特征呢?同样的,时序特征又该怎么用上(或者说套上)RNN呢? 我们知道,在以往的人流(订单需求)预测模型中,大多数都是进行网格划分,然后将轨迹点(需求量)映射到网格中,然后进行CNN处理。可是,在面对这种“点”与“点”之间有着序列关系的情况中显然是不能是这样。
2. 网络模型
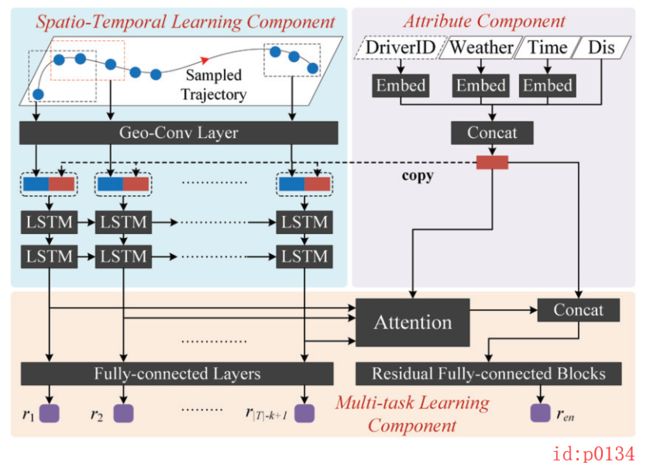
整个网络结构如下图p1034所示,主要包括三个部分:主要部分(Spatio-Temporal Learning Component)以及两个部分(Attribute Component 和 Multi-task Learning Component)。
2.1 数据处理及问题定义
-
数据处理:
首先,将原始的GPS数据(以时间频率采样)重新以距离进行采样,相邻两个点之间的距离大约在200-400米。这样做的原因是为了避免这样一个问题:模型最终学到的映射只是通过简单的统计轨迹点的个数,然后乘以时间频率就得出了总的travel time,以至于无法预测新样本。最终,对于每个样本来说都是一串以距离采样的轨迹点序列( T = { p 1 , ⋯ , p T } T=\{p_1,\cdots,p_{T}\} T={p1,⋯,pT});其中对于每个轨迹点包含的信息有:维度( p i . l a t p_i.lat pi.lat)、经度( p i . l n g p_i.lng pi.lng)和时间戳( p i . t s p_i.ts pi.ts),而对于一个样本来说,包含的信息有:天气编号(weatherID)、司机编号(driver ID)、周编号(weekID)和时间编号(timeID)。
注:时间戳是指一个时间片(1天划分为1440个时间片,一分钟为一个时间片)
-
问题定义:
根据给定起点与终点(以及相关的external factors),然后预测整个所需的travel time。
2.2 Attribute Component
这部分主要是用来拟合一些额外的需要注意的因素,包括:天气编号(weatherID)、司机编号(driver ID)、周编号(weekID)和时间编号(timeID),如图p0135所示。同时,由于以上这4种类型的原始数据都是categorical value;因此,在处理的时候加入了Embedding方法,即每个类型值都将从 v ∈ [ V ] v\in[V] v∈[V]被映射为 R E × 1 R^{E\times 1} RE×1。
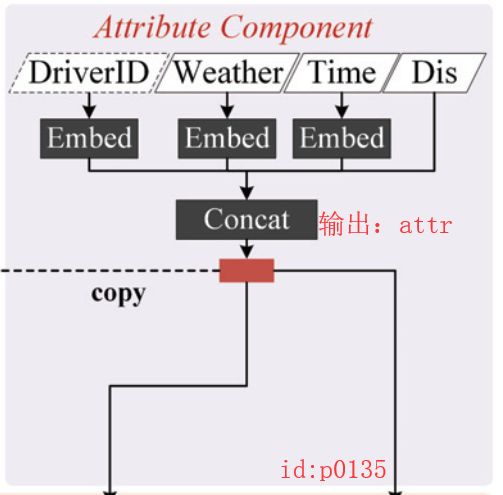
同时,这部分还加入了另外一个比较重要的因素:起始地和目的地之间的距离 Δ d p a → p b \Delta d_{p_a\rightarrow p_b} Δdpa→pb。其计算规则为将 a , b a,b a,b两点之间所有的distance gap相加:
Δ d p a → p b = ∑ i = a b − 1 D i s ( p i , p i + 1 ) \Delta d_{p_a\rightarrow p_b}=\sum_{i=a}^{b-1}Dis(p_i,p_{i+1}) Δdpa→pb=i=a∑b−1Dis(pi,pi+1)
最后,将各个部分的进行concatenate作为整个Attribute Component模块的输出,即向量 a t t r attr attr为输出。
2.3 Spatio-Temporal Component
这一部分作为整个网络模型的核心,主要分为两个部分如图p0136所示:Geo-Conv Layer和Recurrent Layer。很明显,这两部分分别用来刻画数据空间上和时间上的特征分布。

-
Geo-Conv Layer
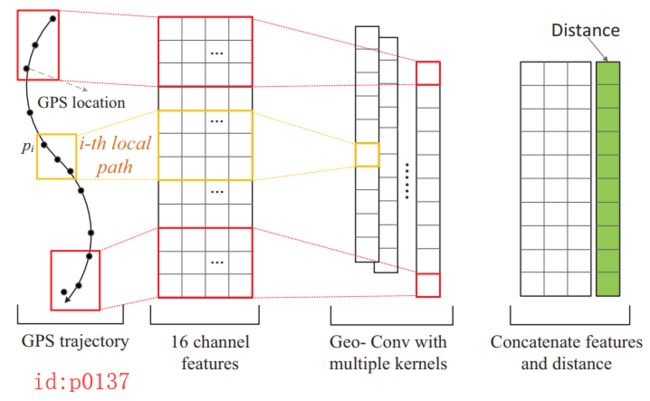
如图p0137所示,该部分首先将一段包含有 T T T个点的轨迹坐标,经过一个非线性变换将每个点都映射成一个16维的向量。例 如:原始轨迹有12个点,也就是shape为
[12,2]经过非线性变换后loc_i的shape为:[12,16].
l o c i = t a n h ( W l o c ⋅ [ p i . l a t ∘ p i . l n g ] ) , l o c i ∈ R 16 , l o c ∈ R ∣ T ∣ × 16 loc_i=tanh(W_{loc} \cdot[p_i.lat\circ p_i.lng]),loc_i\in R^{16}\;,loc\in R^{|T|\times 16} loci=tanh(Wloc⋅[pi.lat∘pi.lng]),loci∈R16,loc∈R∣T∣×16
注:这儿不管是 ∣ T ∣ × 16 |T|\times 16 ∣T∣×16还是 16 × ∣ T ∣ 16\times|T| 16×∣T∣本质上都是一样的,此处为了能更好的与插图对应,本文选择了后者。接着,对得到的多通道特征 l o c loc loc进行卷积处理,其卷积核的的尺寸为 W c o n v ∈ R k × 16 W_{conv}\in R^{k\times 16} Wconv∈Rk×16;也就是说,通过一次卷积操作后将得到一个向量,即图p0137中第三个部分中的一列 l o c c o n v loc^{conv} locconv。此时,对于向量 l o c c o n v loc^{conv} locconv中的第 i i i个值 l o c i c o n v loc_i^{conv} lociconv,完全可以看作是对于第 i i i个local path(sub-sequence) 的空间特征提取(即点 p i → p i + k − 1 p_i\rightarrow p_{i+k-1} pi→pi+k−1)。在经过 c c c个卷积核的处理并concatenate后,便得到了维度为 R ( ∣ T ∣ − k + 1 ) × c R^{(|T|-k+1)\times c} R(∣T∣−k+1)×c的特征图。最后,在得到的特征图右边再拼接上一列新的向量(图p0137右边绿色部分)作为整个Geo-Conv Layer部分的输出。其中新向量的每个元素都表示对应卷积部分的local path的距离之和,即第 i i i个元素的值为 ∑ j = i + 1 i + k − 1 D i s ( p j − 1 , p j ) \sum_{j=i+1}^{i+k-1}Dis(p_{j-1},p_j) ∑j=i+1i+k−1Dis(pj−1,pj)。至此,便得到了维度为 R ( ∣ T ∣ − k + 1 ) × ( c + 1 ) R^{(|T|-k+1)\times (c+1)} R(∣T∣−k+1)×(c+1)的特征图 l o c f loc^f locf。
-
Recurrent Layer
再经过Geo-Conv Layer层的处理后,可以认为 l o c f loc^f locf抓住了所有local paths在空间上的特征分布,但是这些local paths之间还存在的时序上的依赖关系。因此,下一步将通过RNN来对具有序列关系的local path(图p0137左二中的每一行向量表示一个时刻,即序列长度为 ∣ T ∣ − k + 1 |T|-k+1 ∣T∣−k+1)进行特征提取。同时,作者发现在每个时刻的输入中加入Attribute Component部分得到的特征向量 a t t r attr attr能够得到一个更好效果。因此,对于每个时刻的输入都拼接了向量 a t t r attr attr(图p0136中的红色部分)。
因此,在通过两层LSTM的特征提取后将得到 ∣ T ∣ − k + 1 |T|-k+1 ∣T∣−k+1个特征向量,即 { h 1 , h 2 , ⋯ , h ∣ T ∣ − k + 1 } \{h_1,h_2,\cdots,h_{|T|-k+1}\} {h1,h2,⋯,h∣T∣−k+1}。
2.4 Multi-task Learning Component
在通过对原始GPS轨迹序列的空间和时序特征提取后,接下来的就是多任务学习部分。这部分的作用是融合前面的两个部分以及预测最终的travel time。前面我们说到,不管是用单独预测的方法还是整体预测的方法,都不能规避各自的缺点,因此作者选择了结合两种方法各自的优点。在训练的时候同时用这两种方法做预测,而待模型训练好之后就只用整体预测这一个部分。
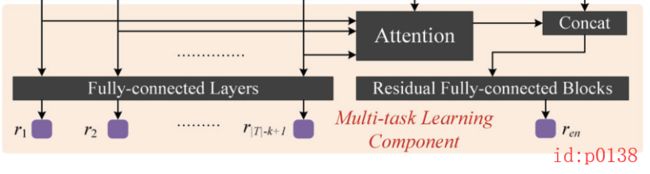
如图p0138所示,左边部分为每个local path( r 1 , r 2 , ⋯ r ∣ T ∣ − k + 1 r_1,r_2,\cdots r_{|T|-k+1} r1,r2,⋯r∣T∣−k+1)的单独travel time预测,右边则是整体的travel time预测。
-
Estimate the local paths
首先,对于单独预测部分来说,其输入为双层LSTM输出后的 ∣ T ∣ − k + 1 |T|-k+1 ∣T∣−k+1个特征向量, { h 1 , h 2 , ⋯ , h ∣ T ∣ − k + 1 } \{h_1,h_2,\cdots,h_{|T|-k+1}\} {h1,h2,⋯,h∣T∣−k+1}。其中, h i h_i hi表示的就是每个local path( p i → p i + 1 , ⋯ , → p i + k − 1 p_i \rightarrow p_{i+1} ,\cdots,\rightarrow p_{i+k-1} pi→pi+1,⋯,→pi+k−1)所对应的时空特征。然后,通过一个简单的两层全连接网络(神经元个数分别为64,1)将这 ∣ T ∣ − k + 1 |T|-k+1 ∣T∣−k+1个向量分别映射为预测单个local path时间的标量 r i r_i ri。
-
Estimate the entire path
其次,对于整体预测来说需要注意的是:①整个预测路径的长度是不一样的,也就是说对于每个样本来说 ∣ T ∣ − k + 1 |T|-k+1 ∣T∣−k+1都是不一样的,即local path的数量不一样,因此需要将其转变为一个固定长度;②通常来说,造成预测整个travel time不够的准确的原因主要来自某些local path,比如说一个包含有多个交叉路口、信号灯等等的local path很容易导致交通拥堵而增加travel time,因此需要将注意力更多的集中在这些因素上。故,在论文中,作者通过引入注意力机制来实现这两个目的。在经过注意力机制的融合后,得到的结果为:
h a t t = ∑ i = 1 ∣ T ∣ − k + 1 α i ⋅ h i h_{att}=\sum_{i=1}^{|T|-k+1}\alpha_i\cdot h_i hatt=i=1∑∣T∣−k+1αi⋅hi
其中, α i \alpha_i αi表示每个local path所分别对应的注意力权重值。其主要是通过 a t t r attr attr部分和 { h i } \{h_i\} {hi}计算而来的,规则如下:
z i = < σ a t t r , h i > α i = e z i ∑ j e z j \begin{aligned} z_i&=<\sigma_{attr},h_i>\\[1ex] \alpha_i&=\frac{e^{z_i}}{\sum_je^{z_j}} \end{aligned} ziαi=<σattr,hi>=∑jezjezi
其中, < ⋅ > <\cdot> <⋅>表示内积, σ a t t \sigma_{att} σatt表示非线性映射,将 a t t att att映射成与 h i h_i hi同维度,也就是一个全连接再非线性。最后,将经过Attention处理后的输出 h a t t h_{att} hatt同 a t t r attr attr拼接起来作为残差全连接部分的输入(尽管这个拼接文中没有描述,但是从网络示意图和源码可以看出),如图p0139所示,其输出结果为 r e n r_{en} ren

2.5 Model Training
在整个模型的训练过程中,两个部分的预测均采用了MAPE(即预测值减去真实值的再除以真实值的绝对值)作为损失函数:
L l o c a l = 1 ∣ T ∣ − k + 1 ∑ i = 1 ∣ T ∣ − k + 1 ∣ r i − ( p i + k − 1 . t s − p i . t s ) p i + k − 1 . t s − p i . t s + ϵ ∣ L e n = ∣ r e n − ( p T . t s − p 1 . t s ) ∣ p ∣ T ∣ . t s − p 1 . t s \begin{aligned} L_{local}&=\frac{1}{|T|-k+1}\sum_{i=1}^{|T|-k+1}\left|\frac{r_i-(p_{i+k-1}.ts-p_i.ts)}{p_{i+k-1}.ts-p_i.ts+\epsilon}\right|\\[2ex] L_{en}&=\frac{|r_{en}-(p_{T}.ts-p_1.ts)|}{p_{|T|}.ts-p_1.ts} \end{aligned} LlocalLen=∣T∣−k+11i=1∑∣T∣−k+1∣∣∣∣pi+k−1.ts−pi.ts+ϵri−(pi+k−1.ts−pi.ts)∣∣∣∣=p∣T∣.ts−p1.ts∣ren−(pT.ts−p1.ts)∣
其中, ϵ \epsilon ϵ为平滑系数,防止分母为0,论文中设为了10
最终,将两个部分的线性组合作为整体的损失函数:
L o s s s = β ⋅ L l o c a l + ( 1 − β ) ⋅ L e n Losss = \beta\cdot L_{local}+(1-\beta)\cdot L_{en} Losss=β⋅Llocal+(1−β)⋅Len
3. 总结
通过对整个网络模型的分析总结我们可以发现,对于这种类”轨迹点“的数据(也就是随时间变化的坐标点),我们都可以把他看作是NLP中的一句话来进行建模处理。例如这篇论文中,作者首先将所有的二维坐标点都映射成一个个16维的向量,然后先用CNN做空间上的特征提取,然后通过RNN做时间上的特征提取。仔细想想,这一个个的16维的向量,不就相当于一句话转变成的词向量矩阵吗?一句话中的每一个词就相当于这儿的每一个坐标点(轨迹点)。所以,还是得佩服这种灵活处理数据的能力,要理解时空数据的本质。
参考
带注意力机制的Seq2Seq翻译模型
浅谈Attention注意力机制及其实现
浅谈残差网络(Residual Network)
