在改革深度学习、抛弃反向传播的道路上我们不仅看到了 Geoffrey Hinton 的努力。近日,《终极算法》一书作者,华盛顿大学计算机科学教授 Pedro Domingos 也提出了自己的方法——离散优化。
神经分类的原始方法是学习单层模型,比如感知机(Rosenblatt, 1958)。但是,将这些方法扩展至多层比较困难,因为硬阈值单元(hard-threshold unit)无法通过梯度下降进行训练,这类单元在几乎所有情况下导数都为 0,且在原点处非连续。因此,研究社区转向带有软激活函数(如 Sigmoid、ReLU)的多层网络,这样梯度可以通过反向传播进行高效计算(Rumelhart et al., 1986)。
该方法获得了巨大成功,使研究者使用数百层来训练网络,学得的模型在大量任务上取得非常高的准确率,效果超越之前的所有方法。但是,随着网络变得更深、更宽,出现了一种趋势:使用硬阈值激活函数进行量化,实现二元或低精度推断,可以大幅降低现代深层网络的能耗和计算时间。除量化以外,硬阈值单元的输出规模独立(或者不敏感)于输入规模,这可以缓解梯度消失和爆炸问题,帮助避免使用反向传播进行低精度训练时出现的一些反常现象(Li et al., 2017)。避免这些问题对开发可用于更复杂任务的大型深层网络系统至关重要。
出于以上原因,我们研究使用硬阈值单元学习深层神经网络的高效技术。我们观察到硬阈值单元输出离散值,这表明组合优化(combinatorial optimization)可能提供训练这些网络的有效方法,因此本论文提出了一种学习深层硬阈值网络的框架。通过为每个隐藏层激活函数指定离散目标集,该网络可分解成多个独立的感知机,每个感知机可以根据输入和目标轻松进行训练。学习深层硬阈值网络的难点在于设置目标,使每个感知机(包括输出单元)要解决的问题是线性可分的,从而达到目标。我们证明使用我们的混合凸组合优化框架可以学得这样的网络。
基于这一框架,随后我们开发了递归算法,一个可行的目标传播(FTPROP),用来学习深度硬阈值网络。由于这是一个离散优化问题,我们开发了启发法以设置基于每层损失函数的目标。FTPROP 的小批量处理版本可用于解释和证明经常使用的直通的评估器(straight-through estimator/Hinton, 2012; Bengio et al., 2013),现在这可被视为带有每层损失函数和目标启发法的一个特定选择的 FTPROP 实例。最后,我们开发了一个全新的每层损失函数,它能提升深度硬阈值网络的学习能力。我们实际展示了我们的算法在 CIFAR10 的直通评估器为两个卷积网路所带来的提升,以及在 ImageNet 上为带有多个硬阈值激活函数类型的 AlexNet 和 ResNet-18 所带来的提升。

图 1:在设置了一个深层硬阈值网络的隐藏层目标 T1 之后,该网络分解成独立的感知机,进而可通过标准方法被学习。
可行的目标传播
前面部分的开放性问题是如何设置隐藏层的优化目标。一般来说,对整个网络一次性生成优秀的、可行的(feasible)优化目标是十分困难的。相反,在一个层级上单次只提供一个优化目标却十分简单。在反向传播中,因为神经网络最后一层的优化目标是给定的,所以算法会从输出层开始,然后令误差沿着反向传播,这种反向传播就成功地为前面层级设定了优化目标。此外,因为获取优化的先验知识是非常困难的,那么如果某层级的目标对于一个给定的网络架构是可行的,我们就可以有一个简单的替代方案。该方案为层级 d 设置一个优化目标,然后优化前面层级已有的权重(即 j<=d 的层级权重)以检查该目标是不是可行。因为在优化层级时的权重和设置其上游目标(即其输入)时的目标相同,我们称之为诱导可行性(induce feasibility),即一种设置目标值的自然方法,它会选择减少层级损失 Ld 的优化目标。
然而,因为优化目标是离散的,目标空间就显得十分巨大且不平滑,它也不能保证在实际执行优化时能同时降低损失。因此启发式方法(heuristics)是很有必要的,我们会在本论文的下一部分详细解释这种启发式方法。d 层优化目标的可行性能通过递归地更新层级 d 的权重而确定,并根据 d-1 层的目标给出 d 层的优化目标。
这一递归过程会继续进行,直到传播到输入层,而其中的可行性(即线性可分型)能通过给定优化目标和数据集输入后优化层级的权重而简单地确定。层级 d 的优化目标能够基于从递归和层级 d-1 的输出而获得的信息增益中得到更新。我们称这种递归算法为可行的目标传播(FTPROP)。该算法的伪代码已经展示在算法 1 中。FTPROP 是一种目标传播 (LeCun, 1986; 1987; Lee et al., 2015),它使用离散型替代连续型而优化设置的目标。FTPROP 同样和 RDIS (Friesen & Domingos, 2015) 高度相关,该优化方法是基于 SAT 求解器的强大非凸优化算法,它会递归地选择和设置变量的自己以分解潜在的问题为简单的子问题。但 RDIS 仅适用于连续问题,但 RDIS 的思想可以通过和积定理(sum-product theorem/Friesen & Domingos, 2016)泛化到离散变量优化中。

当然,现代深层网络在给定数据集上不总是具备可行的目标设置。例如,卷积层的权重矩阵上有大量结构,这使得层输入对目标是线性可分的概率降低。此外,保证可行性通常会使模型与训练数据产生过拟合,降低泛化性能。因此,我们应该放松可行性方面的要求。
此外,使用小批量处理而不是全批处理训练有很多好处,包括改善泛化差距(参见 LeCun et al. 2012 或 Keskar et al. 2016),减少内存使用,利用数据增强的能力,以及为其设计的工具(比如 GPU)的流行。幸运的是,把 FTPROP 转化为一个小批量算法并放宽可行性需求非常简单。尤其是,由于不过度使用任何一个小批量处理非常重要,FTPROP 的小批量版本 (i) 每次只使用一个小批量的数据更新每一层的权重和目标;(ii) 只在每一层的权重上采取一个小的梯度下降步,而不是全部优化;(iii) 设置与更新当前层的权重并行的下游层的目标,因为权重不会改变太多; (iv) 删除对可行性的所有检查。我们把这一算法称作 FTPROP-MB,并在附录 A 算法 2 中展示了其伪代码。
FTPROP-MB 非常类似于基于反向传播的方法,通过标准库即可轻松执行它。

算法 2. MINI-BATCH 可行目标传播

图 2:(a)-(c)显示了不同层的损失函数(蓝线)及其导数(红色虚线)。(d)显示量化 ReLU 激活函数(蓝线),它是阶梯函数的总和,对应饱和的合页损失导数(红色虚线)总和,逼近这个总和的软合页损失性能最佳(黄色虚线)。
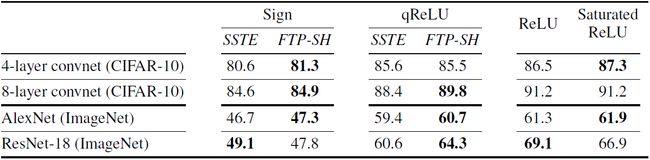
表 1. 在 CIFAR 10 或 ImageNet 上进行符号、qReLU 和全精度激活函数训练时,各种网络的 Top-1 准确度。硬阈值激活函数由 FTPROP-MB、逐层软合页损失函数(FTP-SH)与饱和直通估计(SSTE)训练。粗体显示了表现最好的激活函数
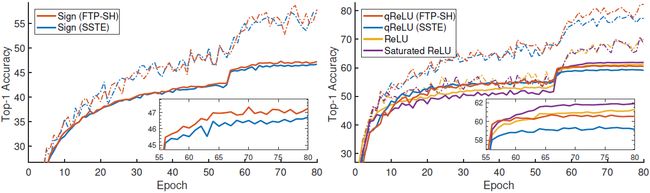
图 3. 不同激活函数的 alexNet 在 imageNet 上的 Top-1 训练(虚线)与测试(实线)准确度。小图显示了最后 25 个 epoch 的测试准确度。在两个大图中带有软合页损失(FTP-SH,红色)的 FTPROP-MB 要比饱和直通估计(SSTE,蓝色)要好。左图显示了带有标志激活的网络。右图展示了新方法(FTP-SH)使用 2-bit 量化 ReLU(qReLU)训练的表现与全精度 ReLU 几乎相同。有趣的是,在这里饱和 ReLU 的表现超过了标准 ReLU。
论文:Deep Learning as a Mixed Convex-Combinatorial Optimization Problem

论文链接:https://arxiv.org/abs/1710.11573
随着神经网络变得越来越深,越来越宽,具有硬阈值激活的学习网络对于网络量化正变得越来越重要,还可以显著减少时间和能量的需求,用于构建高度集成的神经网络系统,这些系统通常会有不可微的组件,确保能避免梯度消失与爆炸以进行有效学习。然而,由于梯度下降不适用于硬阈值函数,我们尚不清楚如何以有原则的方式学习它们。
在本论文中,我们通过观察发现硬阈值隐藏单元的设置目标以最小化损失是一个离散的优化问题,这正好是问题的解决方式。离散优化的目标是找到一系列目标,使得每个单元,包括输出内容都有线性可分的解。因此,网络被分解成一个个感知机,它们可以用标准的凸方法来学习。基于这个方式,我们开发了一种用于学习深度硬阈值网络的递归小批量算法,包括流行但难以解释的直通估计(straight-through estimator)函数作为范例。实验证明,对比直通估计函数,新的算法可以提升多种网络的分类准确度,其中包括 ImageNet 上的 AlexNet、ResNet-18。![]()