ceph osdmap crush 分析
1 maps 更新
1.1 更新规则

Because cluster map changes may be frequent, as in a very large system where OSDs failures and recoveries are the norm, updates are distributed as incremental maps(增量更新): small messages describing the differences between two successive epochs. In most cases, such updates simply state that one or more OSDs have failed or recovered, although in general they may include status changes for many devices, and multiple updates may be bundled together to describe the difference between distant map epochs.
由于RADOS集群坑内包含成千上万的设备,简单的广播Map更新消息到每个节点是不实际的.
- map增量更新,只描述变化信息,通常是一个或多个节点错误或恢复
- 间隔比较长的map,将多个跟新捆绑.一次更新
- 将压力转移到OSD间通信,OSD和client通讯,OSD自己相互更新map
一个OSD与其他Peer联系时都会共享和更新Map
心跳消息会周期的交换以检测异常保证更新快速扩散,对于一个有n个OSD的集群,用到的时间为O(logn)。
所有的RADOS消息(包括从客户端发起的消息,以及从其他OSD发起的消息)都携带了发送端的map epoch,以保证所有更新操作都能够在最新的版本上保持一致。如果一个客户端因为使用了一个过期的map,发送一个IO到一个错误的OSD,OSD会回复一个适当的增量,客户端再重新发送这个请求到正确的OSD。这就避免了主动共享map到客户端,客户端会在与Cluster联系的时候更新。大部分时候,他们都会在不影响当前操作的时候学到更新,让接下来的IO能够准确的定位。
解析 Ceph : OSD , OSDMap 和 PG, PGMap
http://www.wzxue.com/ceph-osd-and-pg/
Monitor 作为Ceph的 Metada Server 维护了集群的信息,它包括了6个 Map,分别是 MONMap,OSDMap,PGMap,LogMap,AuthMap,MDSMap。其中 PGMap 和 OSDMap 是最重要的两张Map.
这时它们的通信就会附带上 OSDMap 的 epoch
Ceph 通过管理多个版本的 OSDMap 来避免集群状态的同步,这使得 Ceph 丝毫不会畏惧在数千个 OSD 规模的节点变更导致集群可能出现的状态同步。
1.2 OSDmap过程
- 新osd启动
因此该 OSD 会向 Monitor 申请加入,Monitor 再验证其信息后会将其加入 OSDMap 并标记为IN,并且将其放在 Pending Proposal 中会在下一次 Monitor “讨论”中提出,OSD 在得到 Monitor 的回复信息后发现自己仍然没在 OSDMap 中会继续尝试申请加入,接下来 Monitor 会发起一个 Proposal ,申请将这个 OSD 加入 OSDMap 并且标记为 UP 。然后按照 Paxos 的流程,从 proposal->accept->commit 到最后达成一致,OSD 最后成功加入 OSDMap 。当新的 OSD 获得最新 OSDMap 发现它已经在其中时。这时,OSD 才真正开始建立与其他OSD的连接,Monitor 接下来会开始给他分配PG。 - osd down
这个 OSD 所有的 PG 都会处于 Degraded 状态。然后等待管理员的当一个 OSD 因为意外 crash 时,其他与该 OSD 保持 Heartbeat 的 OSD 都会发现该 OSD 无法连接,在汇报给 Monitor 后,该 OSD 会被临时性标记为 OUT,所有位于该 OSD 上的 Primary PG 都会将 Primary 角色交给其他 OSD(Monitor 维护了每个Pool中的所有 PG 信息.下一步决策
2 Ceph OSDMap 机制浅析
http://www.xsky.com/tec/ceph-osdmap/

SDMap 机制主要包括如下3个方面:
- Monitor 监控 OSDMap 数据,包括 Pool 集合,副本数,PG 数量,OSD 集合和 OSD 状态。
- OSD 向 Monitor 汇报自身状态,以及监控和汇报 Peer OSD 的状态。
- OSD 监控分配到其上的 PG , 包括新建 PG , 迁移 PG , 删除 PG 。
在整个 OSDMap 机制中,OSD充分信任 Monitor, 认为其维护的 OSDMap 数据绝对正确,OSD 对 PG 采取的所有动作都基于 OSDMap 数据,也就是说 Monitor 指挥 OSD 如何进行 PG 分布
3 PG Map

3.1 PG 自己维护,恢复,迁移
从上面的描述中我们可以了解到 Monitor 掌握了整个集群的 OSD 状态和 PG 状态,每个PG都是一部分 Object 的拥有者,维护 Object 的信息也每个 PG 的责任,Monitor 不会掌握 Object Level 的信息。因此每个PG都需要维护 PG 的状态来保证 Object 的一致性。但是每个 PG 的数据和相关故障恢复、迁移所必须的记录都是由每个 PG 自己维护,也就是存在于每个 PG 所在的 OSD 上。
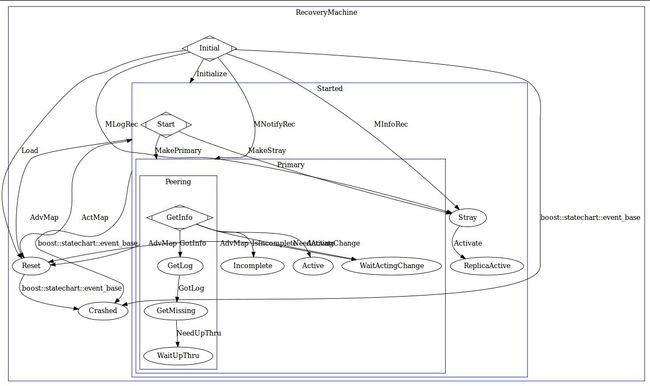
PGMap 是由 Monitor 维护的所有 PG 的状态,每个 OSD 都会掌握自己所拥有的 PG 状态,PG 迁移需要 Monitor 作出决定然后反映到 PGMap 上,相关 OSD 会得到通知去改变其 PG 状态。在一个新的 OSD 启动并加入 OSDMap 后,Monitor 会通知这个OSD需要创建和维护的 PG ,当存在多个副本时,PG 的 Primary OSD 会主动与 Replicated 角色的 PG 通信并且沟通 PG 的状态,其中包括 PG 的最近历史记录。通常来说,新的 OSD 会得到其他 PG 的全部数据然后逐渐达成一致,或者 OSD 已经存在该 PG 信息,那么 Primary PG 会比较该 PG 的历史记录然后达成 PG 的信息的一致。这个过程称为 Peering ,它是一个由 Primary PG OSD 发起的“讨论”,多个同样掌握这个 PG 的 OSD 相互之间比较 PG 信息和历史来最终协商达成一致。
在 Ceph 中,PG 存在多达十多种状态和数十种事件的状态机去处理 PG 可能面临的异常
写得不错的文章
Ceph:pg peering过程分析
https://www.ustack.com/blog/ceph%EF%BC%8Dpg-peering/?print=yes
4 放置组计算
放置组,根据通过对象名的hash值
pgid = (r, hash(o)&m)
o对象名,r负载份数,m位掩码 &按位与, pgid放置组号
m = 2^k−1, number of placement groups 放置组个数
CRUSH是稳定的
当一个(或多个)设备加入或离开集群,放置组原来的存储位置不变; CRUSH只转移足够的数据来保持数据均匀分布.
Ceph的Monitor集群会计算每个PG所对应的OSD,并将这个信息保存在Cluster Map中
该OSD收到写请求的时候先检查比对Client的自己的epoch,如果一致则查找pg_id对应的active OSD list
OSDMap 机制和 CRUSH 算法一起构成了 Ceph 分布式架构的基石。
Monitor 作为Ceph的 Metada Server 维护了集群的信息,它包括了6个 Map,分别是 MONMap,OSDMap,PGMap,LogMap,AuthMap,MDSMap。其中 PGMap 和 OSDMap 是最重要的两张Map
Monitor集群内部通过Paxos协议来维护Cluster Map的数据一致性。实现上Monitor采用了Lease机制简化Paxos协议,这种简化协议仅允许系统中只有一个Monitor能够进行写入,这个Monitor称为Leader。初始时所有的Monitor先选举出一个Leader,该Leader将协调其他Monitor的Cluster Map的更新。每隔固定周期Leader向其他Monitor发放Lease,持有Lease的Monitor才能够对外提供读服务(否则认为该Monitor上的数据已经过时,不能提供读服务)。
Monitor集群不会主动去检测OSD的状态,OSD也不会定期向Monitor汇报状态,OSD状态报告主要是通过下面三种方式:1)Client在读取某个OSD内容时发现OSD宕机,并报告给Monitor集群;2)OSD在给其他OSD同步数据或者交换心跳信息时发现OSD宕机,报告给Monitor集群;3)新上线或者恢复的OSD主动向Monitor集群报道自己新的状态。这样设计的原因在于Ceph需要支持PB级的数据存储,系统中可能有成千上万的OSD,正常情况下并不需要这些检测网络信息,保证Monitor集群最小化有利于系统的扩展性。同样Cluster Map的增量变化大部分情况也不是由Monitor集群直接同步给各个OSD,而是各个OSD中相互同步最新的Cluster Map信息。

rados分布算法在2.4节已经讲过了,map更新logn次便可以更新完毕.
当集群增多,设备故障就好更加频发,更新次数就好增加.因为map更新和交互只发生在共享相同PG的OSD间,上限正比于单个OSD接收上的副本个数.
In simulations under near-worst case propagation circumstances with regular map updates, we found that update duplicates approach a steady state even with exponential cluster scaling. In this experiment, the monitors share each map update with a single random OSD, who then shares it with its peers. In Figure 3 we vary the cluster size x and the number of PGs on each OSD (which corresponds to the number of peers it has) and measure the number of duplicate map updates received for every new one (y).Update duplication approaches a constant level—less than 20% of μ—even as the cluster size scales exponentially, implying a fixed map distribution overhead.
We consider a worst case scenario in which the only OSD chatter are pings for failure detection, which means that, generally speaking,OSDs learn about map updates (and the changes known by their peers) as slowly as possible. Limiting map distribution overhead thus relies only on throttling the map update frequency, which the monitor cluster already does as a matter of course.
5 论文
论文列表
https://tobegit3hub1.gitbooks.io/ceph_from_scratch/content/architecture/papers.html
6 OSD个数
RAM内存
元数据服务器和监视器必须可以尽快地提供它们的数据,所以他们应该有足够的内存,至少每进程 1GB 。 OSD 的日常运行不需要那么多内存(如每进程 500MB )差不多了;然而在恢复期间它们占用内存比较大(如每进程每 TB 数据需要约 1GB 内存)。通常内存越多越好。
根据经验, 1TB 的存储空间大约需要 1GB 内存。
另外每个 OSD 守护进程占用一个驱动器。
7 CRUSH 算法
Ceph剖析:数据分布之CRUSH算法与一致性Hash
http://blog.csdn.net/xingkong_678/article/details/51530836
bucket类型
bucket分为4种类型
一般bucket,正常的bucket和错误的bucket互不影响
CRUSH源码分析
http://way4ever.com/?p=123
假设我组建一套存储系统,有3个机架(host),每个机架上有4台主机(host),每个主机上有2个磁盘(device),则一共有24个磁盘。预计的扩展方式是添加主机或者添加机架。

我们的bucket有三种: root、rack、host。root包含的item是rack,root的结构是straw。rack包含的item是host,rack的结构是tree。host包括的item是device,host的结构式uniform。这是因为每个host包括的device的数量和权重是一定的,不会改变,因此要为host选择uniform结构,这样计算速度最快。
CRUSH详解
https://tobegit3hub1.gitbooks.io/ceph_from_scratch/content/architecture/crush.htmlhttp://way4ever.com/?p=122
一个robust解决方案是把数据随机分布到存储设备上,这个方法能够保证负载均衡,保证新旧数据混合在一起。但是简单HASH分布不能有效处理设备数量的变化,导致大量数据迁移。ceph开发了CRUSH(Controoled Replication Under Scalable Hashing),一种伪随机数据分布算法,它能够在层级结构的存储集群中有效的分布对象的副本。CRUSH实现了一种伪随机(确定性)的函数,它的参数是object id或object group id,并返回一组存储设备(用于保存object副本)。CRUSH需要cluster map(描述存储集群的层级结构)、和副本分布策略(rule)。
处理设备变化,减少数据迁移
CRUSH有两个关键优点:
1) 任何组件都可以独立计算出每个object所在的位置(去中心化)。
2) 只需要很少的元数据(cluster map),只要当删除添加设备时,这些元数据才需要改变。
集群结构变化
当集群架构发生变化后情况就比较复杂了,例如在集群中添加节点或者删除节点。在添加的数据进行移动时,CRUSH的mapping过程所使用的按决策树中层次权重算法比理论上的优化算法∆w /w更有效。在每个层次中,当一个香港子树的权重改变分布后,一些数据对象也必须跟着从下降的权重移动到上升的权重。由于集群架构中每个节点上伪随机位置决策是相互独立的,所以数据会统一重新分布在该点下面,并且无须获取重新map后的叶子节点在权重上的改变。仅仅更高层次的位置发送变化时,相关数据才会重新分布。这样的影响在图3的二进制层次结构中展示了出来。

8 RGW和Block

9 对象存储的优点
面向对象存储14个优点,你知不知道?
http://www.chinastor.com/a/jishu/0R42a42011.html
面向对象存储所需要知道的十四大问题
1. 存储成本与数据价值一致
2. 较RADI更好地数据可用性
3. 性能呈现集群性
当新服务器运行在额外增添的对象存储集群设备上,性能就可以突破瓶颈实现进程和I/O大规模并行读写。这一点特别适合于多媒体文件存储和读取。
4. 提供无限容量和可扩展性
面向对象存储系统中,没有目录层次结构(树),对象的存储位置可以存储在不同的目录路径中易变检索。这就使得对象存储系统可以精准到每个字节,而且不受文件(对象)数量、文件大小和文件系统容量的限制。
5. 内置归档和规范
6. 文件系统无法实现的元数据利用
面向对象存储系统可以不需要文件名、日期和其他文件属性就可以查找文件。他们还可以使用元数据应用服务水平协议(SLA),路由协议,备灾和灾难恢复,备份和数据删除删除以及自动存储管理。这些是文件系统所不能解决的问题。
7. 无需备份
8. 自动负载平衡
9. 常规移植
10. 无需硬件锁定
根据存档和法规要求,存储的数据需要保持数年。技术更新的成本和复杂性是一个需要考虑的重要因素,特别是连接到昂贵的专有硬件平台系统,这种因素更加需要予以重视。部署只有软件的对象存储系统而无需考虑底层硬件,允许用户选择使用任何一种商业服务器技术和无中断升级(当新硬件被推出的时候)。
11. 更高的磁盘利用率
12. 高可用性和灾难恢复
13. 化繁为简
14. 新旧互不干扰
在学习CRUSH之前,需要了解以下的内容。
CRUSH算法接受的参数包括cluster map,也就是硬盘分布的逻辑位置,例如这有多少个机房、多少个机柜、硬盘是如何分布的等等。cluster map是类似树的多层结果,子节点是真正存储数据的device,每个device都有id和权重,中间节点是bucket,bucket有多种类型用于不同的查询算法,例如一个机柜一个机架一个机房就是bucket。
另一个参数是placement rules,它指定了一份数据有多少备份,数据的分布有什么限制条件,例如同一份数据不能放在同一个机柜里等的功能。每个rule就是一系列操作,take操作就是就是选一个bucket,select操作就是选择n个类型是t的项,emit操作就是提交最后的返回结果。select要考虑的东西主要包括是否冲突、是否有失败和负载问题。
算法的还有一个输入是整数x,输出则是一个包含n个目标的列表R,例如三备份的话输出可能是[1, 3, 5]。
http://blog.csdn.net/XingKong_678/article/details/51526627
Uniform: 这种桶用完全相同的权重汇聚设备。例如,公司采购或淘汰硬件时,一般都有相同的物理配置(如批发)。当存储设备权重都相同时,你可以用 uniform 桶类型,它允许 CRUSH 按常数把副本映射到 uniform 桶。权重不统一时,你应该采用其它算法。
适用于很少增加删除设备的场景
增加机器后所有数据需要重新分布
List: 这种桶把它们的内容汇聚为链表。它基于 RUSH P 算法,一个列表就是一个自然、直观的扩张集群:对象会按一定概率被重定位到最新的设备、或者像从前一样仍保留在较老的设备上。结果是优化了新条目加入桶时的数据迁移。然而,如果从链表的中间或末尾删除了一些条目,将会导致大量没必要的挪动。所以这种桶适合永不或极少缩减的场景。
增加机器时移动的数据是最优的
– 和UniformBucket不同不需要重新分布数据
– 只需要从原先的机器上迁移数据到新机器
• 减少机器时需要数据重新分布
Tree: 它用一种二进制搜索树,在桶包含大量条目时比 list 桶更高效。它基于 RUSH R 算法, tree 桶把归置时间减少到了 O(log n) ,这使得它们更适合管理更大规模的设备或嵌套桶。
Straw: list 和 tree 桶用分而治之策略,给特定条目一定优先级(如位于链表开头的条目)、或避开对整个子树上所有条目的考虑。这样提升了副本归置进程的性能,但是也导致了重新组织时的次优结果,如增加、拆除、或重设某条目的权重。 straw 桶类型允许所有条目模拟拉稻草的过程公平地相互“竞争”副本归置。
增加删除机器时的数据移动量都是最优的
CRUSH Maps
CRUSH 图主要有 4 个主要段落。
1. 设备 由任意对象存储设备组成,即对应一个 ceph-osd 进程的存储器。 Ceph 配置文件里的每个 OSD 都应该有一个设备。
2. 桶类型: 定义了 CRUSH 分级结构里要用的桶类型( types ),桶由逐级汇聚的存储位置(如行、机柜、机箱、主机等等)及其权重组成。
3. 桶例程: 定义了桶类型后,还必须声明主机的桶类型、以及规划的其它故障域。
4. 规则: 由选择桶的方法组成。
10 map管理
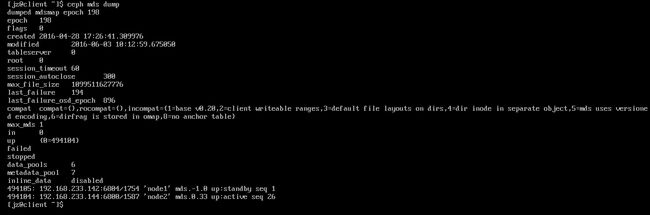
Montior Map: 包含集群的 fsid 、位置、名字、地址和端口,也包括当前版本、创建时间、最近修改时间。要查看监视器图,用 ceph mon dump 命令。

OSD Map: 包含集群 fsid 、创建时间、最近修改时间、存储池列表、副本数量、归置组数量、 OSD 列表及其状态(如 up 、 in )。要查看OSD运行图,用 ceph osd dump 命令

。
PG Map::** 包含归置组版本、其时间戳、最新的 OSD 运行图版本、占满率、以及各归置组详情,像归置组 ID 、 up set 、 acting set 、 PG 状态(如 active+clean ),和各存储池的数据使用情况统计。
CRUSH Map::** 包含存储设备列表、故障域树状结构(如设备、主机、机架、行、房间、等等)、和存储数据时如何利用此树状结构的规则。要查看 CRUSH 规则,执行 ceph osd getcrushmap -o {filename} 命令;然后用 crushtool -d {comp-crushmap-filename} -o {decomp-crushmap-filename} 反编译;然后就可以用 cat 或编辑器查看了。
MDS Map: 包含当前 MDS 图的版本、创建时间、最近修改时间,还包含了存储元数据的存储池、元数据服务器列表、还有哪些元数据服务器是 up 且 in 的。要查看 MDS 图,执行 ceph mds dump 。
map
11 参考
Ceph集群在系统扩容时触发rebalance的机制分析
http://my.oschina.net/linuxhunter/blog/637737